

Map集合
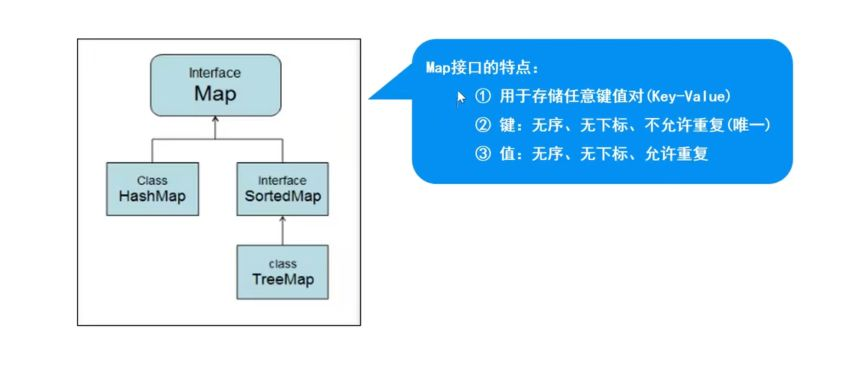
Map父接口:
特点:存储一对数据(key-value),无序,无下标,键不可重复,值可重复。
方法:V put(K key,V value) //将对象存入到集合中,关联键值。key重复则覆盖原值。
Object get(Object key) //根据键获取对应的值
Set<K> keySet() //返回所有key。
Collection<V> values() //返回包含所有值的Colletion集合
Set<Map.Entry<K,V>> entrySet() //键值匹配的Set集合
package com.java.leetcode.collection; import java.util.HashMap; import java.util.Map; import java.util.Set; /* Map接口的使用 特点;存储键值对;键不能重复,值可以重复;无序 */ public class HMap01 { public static void main(String[] args) { Map map = new HashMap(); map.put("apple","苹果"); map.put("peach","桃"); map.put("pear","梨"); map.put("plum","李子"); map.put("pear","李子");//重复的key。后面的value会取代之前的value System.out.println(map.toString());//{plum=李子, apple=苹果, pear=李子, peach=桃} 无序的 //删除 map.remove("pear"); //删除键为pear的数据 System.out.println("删除之后:"+map); /* 遍历;1.使用keySet()方法 Set<K> keySet() //返回所有key。 */ System.out.println("*****keySet()遍历Map*****"); Set<String> keySet = map.keySet(); //对set集合可用增强for或者迭代器遍历 for(String s : keySet){ System.out.println(s +"---"+map.get(s));// Object get(Object key) //根据键获取对应的值 } /* 使用entrySet方法 Set<Map.Entry<K,V>> entrySet() //键值匹配的Set集合 */ System.out.println("*****entrySet()遍历Map*****"); Set<Map.Entry<String,String>> entries = map.entrySet(); //可用增强for,迭代器进行遍历 for(Map.Entry<String,String> entry : entries){ System.out.println(entry.getKey()+"---"+entry.getValue()); } //entrySet()方法效率高于keySet() //判断 System.out.println("是否存在键为pear?"+map.containsKey("pear")); System.out.println("是否存在值为桃?"+map.containsValue("桃")); } }
运行结果:

HashMap:
基于哈希表的Map接口的实现。此实现提供所有可选的映射操作,并允许使用null键和null值。
构造方法:
HashMap() 构造一个具有默认初始容量(16)和默认加载因子(0.75)的空HahMap //加载因子0.75:假如现在容量为100,当数据元素超过75的时候,就开始扩容。
.....
package com.java.leetcode.collection; import java.util.HashMap; import java.util.Map; import java.util.Set; /* HashMap的使用 存储结构:哈希表(数组+链表) 在JDK1.8之后为数组+链表+红黑树 */ public class HMap02 { public static void main(String[] args) { HashMap<Student,String> hashMap = new HashMap<Student,String>(); Student s1 = new Student("张三","男"); Student s2 = new Student("李四","男"); Student s3 = new Student("小芳","女"); hashMap.put(s1,"北京");//将Student作为key;地址作为value hashMap.put(s2,"上海"); hashMap.put(s3,"深圳"); hashMap.put(s3,"南京"); //重复的key。后面的value会覆盖前面的value System.out.println(hashMap); hashMap.put(new Student("小芳","女"),"杭州"); //??通过new Student的方式。将key值一样的数据成功添加。 System.out.println(hashMap);//通过new Student的方式,要想key已经存在的不能添加只能覆盖。需要重写equals和hashcode.直接快捷键 //删除 hashMap.remove(s1); System.out.println("删除之后:"+hashMap); //遍历 System.out.println("*****keySet()遍历Map*****"); Set<Student> set = hashMap.keySet(); for(Student s : set){ System.out.println(s+"---"+hashMap.get(s)); } System.out.println("*****entrySet()遍历Map*****"); Set<Map.Entry<Student,String>> entries = hashMap.entrySet(); for(Map.Entry<Student,String> entry : entries){ System.out.println(entry.getKey()+"---"+entry.getValue()); } //判断...啥的不写了 } }
运行结果:

源码分析:
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16 默认初始容量大小:1左移四位
static final int MAXIMUM_CAPACITY = 1 << 30; // 数组最大容量大小:1^30
static final float DEFAULT_LOAD_FACTOR = 0.75f; //默认加载因子:0.75
static final int TREEIFY_THRESHOLD = 8; //JDK1.8之后加入。是从链表转成树的阈值。调整成红黑树
static final int UNTREEIFY_THRESHOLD = 6; //当长度降到6时,就转回链表
static final int MIN_TREEIFY_CAPACITY = 64; //最小的数组容量大小。当链表长度大于8,并且集合元素个数大于等于64时,调整为红黑树
transient Node<K,V>[] table; //哈希表中的数组
transient int size; //元素个数
HashMap<Student,String> hashMap = new HashMap<Student,String>(); //刚创建时,还没有添加元素。table=null size = 0;
hashMap.put(s1,"北京"); //使用put方法添加第一个元素时。
public V put(K key, V value) { return putVal(hash(key), key, value, false, true); }
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
//哈希值
final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) { Node<K,V>[] tab; Node<K,V> p; int n, i; if ((tab = table) == null || (n = tab.length) == 0) //此时table为null, n = (tab = resize()).length; //n=16,此时一个元素都还没有 if ((p = tab[i = (n - 1) & hash]) == null) tab[i] = newNode(hash, key, value, null);//用newNode方法将元素加进数组,根据hash判断位置 else { Node<K,V> e; K k; if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) e = p; else if (p instanceof TreeNode) e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value); else { for (int binCount = 0; ; ++binCount) { if ((e = p.next) == null) { p.next = newNode(hash, key, value, null); if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st treeifyBin(tab, hash); break; } if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) break; p = e; } } if (e != null) { // existing mapping for key V oldValue = e.value; if (!onlyIfAbsent || oldValue == null) e.value = value; afterNodeAccess(e); return oldValue; } } ++modCount; if (++size > threshold) //当元素个数大于16*0.75=12时,就开始调整数组大小。每次调整都是原来的2倍。 resize(); afterNodeInsertion(evict); return null; }
final Node<K,V>[] resize() { Node<K,V>[] oldTab = table; //null int oldCap = (oldTab == null) ? 0 : oldTab.length; //oldCap =null int oldThr = threshold; int newCap, newThr = 0; if (oldCap > 0) { if (oldCap >= MAXIMUM_CAPACITY) { threshold = Integer.MAX_VALUE; return oldTab; } else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY && //新的大小 = 旧的大小左移一位;即旧大小的两倍 oldCap >= DEFAULT_INITIAL_CAPACITY) newThr = oldThr << 1; // double threshold } else if (oldThr > 0) // initial capacity was placed in threshold newCap = oldThr; else { //进入这里 // zero initial threshold signifies using defaults newCap = DEFAULT_INITIAL_CAPACITY; //newCap =16 newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY); } if (newThr == 0) { float ft = (float)newCap * loadFactor; newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ? (int)ft : Integer.MAX_VALUE); } threshold = newThr; @SuppressWarnings({"rawtypes","unchecked"}) Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap]; //创建了一个新的数组,大小为16 table = newTab; //大小16 if (oldTab != null) { for (int j = 0; j < oldCap; ++j) { Node<K,V> e; if ((e = oldTab[j]) != null) { oldTab[j] = null; if (e.next == null) newTab[e.hash & (newCap - 1)] = e; else if (e instanceof TreeNode) ((TreeNode<K,V>)e).split(this, newTab, j, oldCap); else { // preserve order Node<K,V> loHead = null, loTail = null; Node<K,V> hiHead = null, hiTail = null; Node<K,V> next; do { next = e.next; if ((e.hash & oldCap) == 0) { if (loTail == null) loHead = e; else loTail.next = e; loTail = e; } else { if (hiTail == null) hiHead = e; else hiTail.next = e; hiTail = e; } } while ((e = next) != null); if (loTail != null) { loTail.next = null; newTab[j] = loHead; } if (hiTail != null) { hiTail.next = null; newTab[j + oldCap] = hiHead; } } } } } return newTab; }
总结;
- 当HashMap刚创建时,table是null,为了节省空间,当添加第一个元素时,table容量调整为16
- 当元素个数大于阈值(16*0.75 = 12)时,会进行扩容,扩容后大小为原来的2倍,目的是减少调整元素的个数
- jdk1.8 当每个链表长度大于8,并且数组元素个数大于等于64时,会调整为红黑树,目的是提高执行效率
- jdk1.8 当链表长度小于6时,调整成链表
- jdk1.8以前,链表是头插入,jdk1.8以后是尾插入
HashSet与HashMap
public HashSet() { map = new HashMap<>(); }
public boolean add(E e) { return map.put(e, PRESENT)==null; //实质是调用map中的put方法 }
HashMap:
- JDK1.2版本,线程不安全,运行效率快;允许用null作为key或是value
Hashtable:
- JDK1.0版本,线程安全,运行效率慢;不允许null作为key或是value
- 无参构造:用默认初始容量:11和加载因子:0.75构造一个新的空哈希表。
Properties:
- Hashtable的子类,要求key和value都是String.通常用于配制文件的读取
- 表示了一个持久的属性集。可以保存在流中或从流中加载。
TreeMap:
- 实现了SortedMap接口(是Map的子接口),可以对key自动排序
TreeMap:
package com.java.leetcode.collection; import java.util.TreeMap; /* TreeMap的使用 存储结构:红黑树 */ public class TMap { public static void main(String[] args) { TreeMap<Student,String> treeMap = new TreeMap<Student,String>(); Student s1 = new Student("张三","男"); Student s2 = new Student("李四","男"); Student s3 = new Student("小芳","女"); treeMap.put(s1,"北京"); treeMap.put(s2,"上海"); treeMap.put(s3,"杭州"); System.out.println(treeMap); //会直接挂掉。报类型转换异常。因为treeMap存储结构是红黑树,需要指定比较方式,实现Comparable接口,或者Comparator treeMap.put(new Student("李四","男"),"北京"); //此时不需要重写equals和hashcode方法也会添加失败。因为这里是用compare比较的,此处key相同,后面的value会覆盖前面的value System.out.println(treeMap); //遍历啥的不写了....用keySet()或者entrySet() } }
实现Comparable接口;
package com.java.leetcode.collection; public class Student implements Comparable<Student>{ private String name; private String sex; @Override public String toString() { return "Student{" + "name='" + name + '\'' + ", sex='" + sex + '\'' + '}'; } public Student(String name, String sex) { this.name = name; this.sex = sex; } public String getName() { return name; } public void setName(String name) { this.name = name; } public String getSex() { return sex; } public void setSex(String sex) { this.sex = sex; } @Override public int compareTo(Student o) { int nn = this.name.compareTo(o.name); int cn = this.sex.compareTo(o.sex); return nn == 0 ?cn:nn; } }
//还可以通过实现Comparator:实现定制比较(比较器)
TreeMap<Student,String> treeMap = new TreeMap<Student,String>(new Comparator<Student>() { @Override public int compare(Student o1, Student o2) { int nn = o1.getName().compareTo(o2.getName()); int cn = o1.getSex().compareTo(o2.getSex()); return nn == 0 ?cn:nn; } });
TreeSet和TreeMap
public TreeSet() { this(new TreeMap<E,Object>()); //实质上是用了TreeMap }
public boolean add(E e) { return m.put(e, PRESENT)==null; //实际是用了Map里是put方法 }
