第七周进度报告
这周主要学习Java爬虫的相关知识,和正则表达式在爬虫中的应用
爬虫
- Pattern: 表示正则表达式
- Matcher: 文本匹配器,作用按照正则表达式的规则去读取字符串,从头开始读取,在大串上去找符合匹配规则的子串
String s = "Java自从95年问世以来,经历了很多版本,目前企业中用的最多的是Java8和Java11,因为这两个版本是长期支持版本," + "下一个长期支持的版本是" +
"Java17,相信未来不久Java17也会逐渐登上历史舞台.";
//1.获取正则表达式的对象
Pattern p = Pattern.compile("Java\\d{0,2}");
//2.获取文本匹配器的对象 拿着m去读取s,找符合p规则的字串
Matcher m = p.matcher(s);
//3.利用循环读取
while(m.find()){
System.out.println(m.group());
}
带条件爬取
/*
需求1: 爬取版本号为8,11,17的Java文本,但是只要Java,不显示版本号。
需求2: 爬取版本号为8,11,17的Java文本。正确爬取结果为: Java8 Java11 Java17 Java17
需求3: 爬取除了版本号为8,11,17的Java文本,
**/
String s = "Java自从95年问世以来,经历了很多版本,目前企业中用的最多的是Java8和Java11,因为这两个版本是长期支持版本," + "下一个长期支持的版本是" +
"Java17,相信未来不久Java17也会逐渐登上历史舞台.";
//需求1: ?理解为前面的数据java,=表示在java后面要跟随的数据,但是在获取之前,只获取前半部分
String regex1 = "(?i)(java)(?=8|11|17)";
//需求2:
String regex2 = "(?i)(java)(?:8|11|17)";
//需求3:
String regex3 = "(?i)(java)(?!8|11|17)";
//1.获取正则表达式的对象
Pattern p = Pattern.compile(regex3);
//2.获取文本匹配器的对象 拿着m去读取s,找符合p规则的字串
Matcher m = p.matcher(s);
//3.利用循环读取
while(m.find()){
System.out.println(m.group());
}
贪婪爬取和非贪婪爬取
- 贪婪爬取:在爬取数据的时候尽可能的多获取数据
- 非贪婪爬取: 在爬取数据的时候尽可能地少获取数据
public static void main(String[] args) {
String s = "klklklkkljxzcnxzncklxznkvabbbbbbbbbbbbbbbbbbbbxjvkj";
//1.贪婪爬取
String regex1 = "ab+";
//2.非贪婪爬取
String regex2 = "ab+?";
Pattern p = Pattern.compile(regex2);
Matcher m = p.matcher(s);
while(m.find()){
System.out.println(m.group());
}
}
正则表达式在字符串方法中的使用

public static void main(String[] args) {
String s = "你dskadhjksaj我dhsjadhjkls大帅哥dsaldjs666";
String regex = "[\\w&&[^_]]+";
//replaceAll
System.out.println(s.replaceAll(regex,"乐"));
//split
String[] arr = s.split(regex);
for (int i = 0; i < arr.length; i++) {
System.out.println(arr[i]);
}
//matches
System.out.println(s);
System.out.println(s.matches(regex));
}
分组捕获和非分组捕获
分组规则

public static void main(String[] args) {
//分组捕获
String s = "ads12d1sa";
String regex = "(.).+\\1";
System.out.println(s.matches(regex));
String s2 = "abcds12d31sabc";
String regex2 = "(.+).+\\1";
System.out.println(s.matches(regex2));
String s3 = "aaagf132h1fgaab";
String regex3 = "((.)\\2)*.+\\1";
System.out.println(s3.matches(regex3));
//正则内部用\\,外部用组的内容用$
String s4 = "我我我我我啦啦啦啦啦啦啦啦啦哈哈哈哈哈哈哈哈哈啊啊啊啊啊";
System.out.println(s4.replaceAll("(.)\\1+","$1"));
}
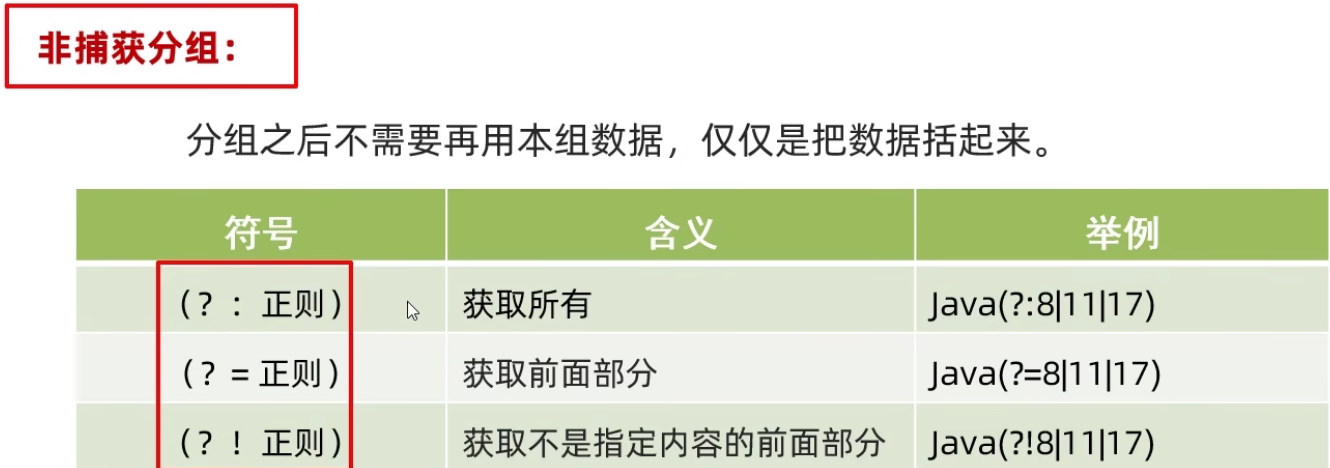
非捕获分组: 仅仅是吧数据括起来,不占用组号
常见API
Date
时间有关的知识点

public static void main(String[] args) {
/*
public Date(); // 创建Data对象,表示当前时间
public Date(long data) //创建Data对象,表示指定时间
public void setTime(long time) //设置/修改 (time)毫秒值
public long getTime() //获取时间对象的毫秒值
*/
Date d1 = new Date();
System.out.println(d1);
Date d2 = new Date(1000L);
System.out.println(d2);
long l = d2.getTime();
System.out.println(l);
}
public static void main(String[] args) {
//时间计算
Date d1 = new Date(0L);
long time = d1.getTime();
time += 1000L * 60 * 60 * 24 * 365; //获取一年后的时间
d1.setTime(time);
System.out.println(d1);
//时间比较
Random r = new Random();
Date d2 = new Date(Math.abs(r.nextInt()));
Date d3 = new Date(Math.abs(r.nextInt()));
System.out.println("d2: " + d2.getTime());
System.out.println("d3: " + d3.getTime());
if(d2.getTime() > d3.getTime()){ //取出毫秒值进行比较
System.out.println("d3在前");
}
else if(d2.getTime() < d3.getTime()){
System.out.println("d2在前");
}
else {
System.out.println("时间相等");
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号