



scikit-learn模型参数保存和多分类策略(one vs one和one vs rest)
模型参数保存
方式1 使用 pickle
例如
>>> from sklearn import svm
>>> from sklearn import datasets
>>> clf = svm.SVC(gamma='scale')
>>> iris = datasets.load_iris()
>>> X, y = iris.data, iris.target
>>> clf.fit(X, y)
SVC(C=1.0, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape='ovr', degree=3, gamma='scale', kernel='rbf',
max_iter=-1, probability=False, random_state=None, shrinking=True,
tol=0.001, verbose=False)
>>> import pickle
>>> s = pickle.dumps(clf) 保存为一个变量
>>> clf2 = pickle.loads(s) 调用保存
>>> clf2.predict(X[0:1])
array([0])
>>> y[0]
0
方式2 使用joblib’s 保存到文件(推荐)
例如
>>> from joblib import dump, load
>>> dump(clf, 'filename.joblib') 保存
>>> clf = load('filename.joblib') 调用
参考自 scikitlearn-docs 2.1.4
多分类策略
one vs rest 和 one vs one
1
One-vs-all 也称为one vs rest
参考
https://www.cnblogs.com/sl0309/p/10395010.html
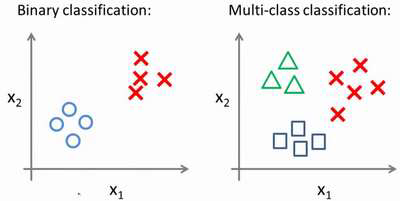
右侧有三类,
在此策略下,
三角 为一类 叉叉和方格 一同为一类
同理
叉叉 为一类 三角和方格 一同为一类
方格 为一类 三角和叉叉 一同为一类
这样 三个分类变成了 三个二分类
推广
类1 类2 类3 类4 ….类k
分为k个二分类
1 类1和其他(类2,3,。。。之和)
2 类2和其他(类1,3,。。。之和)
…
k 类k和其他(类1,2,。。,k-1之和)
2
one-versus-one
一对一的分类。
参考 https://www.cnblogs.com/CheeseZH/p/5265959.html
有图有三个类
成对(两两)组成
三角 和 叉叉
方格 和 叉叉
三角 和 方格
类1 类2 类3 类4 。。。 类k
K-1个 类1 类2 and 类1 类3 and 。。。。 and 类1 类k
K-2个 类2 类3 and 类2 类4 and 。。。 and 类2 类k
。。。
1个 类k-1 and 类k
共(k-1)x((k-1)+1)/2

