MySQL学习之第三章-操作数据库
三、操作数据库
操作数据库-->操作数据库中的表-->操作表中的数据
MySQL的关键字不区分大小写
MySQL中若表名或字段名是MySQL中的关键字时,需要加上``
1、操作数据库
1.DCL语言
-
创建用户
CREATE USER 用户名@'IP地址' IDENTIFIED BY '密码'; --注意:'IP地址'可以设置为localhost(代表本机)或者'%'(代表允许所有IP地址登录) -
删除用户
DROP USER 用户名@'IP地址'; 注意:'IP地址'可以设置为localhost(代表本机)或者'%'(代表允许所有IP地址登录) -
用户授权
GRANT 权限1,权限2,...... ON 数据库名.* TO 用户名@'IP地址' IDENTIFIED BY '密码'; 注意:所有的数据库就用*.*,所有的权限就用all或者all privileges -
撤销授权
REVOKE 权限1,权限2,...... ON 数据库名.* FROM 用户名@'IP地址' IDENTIFIED BY '密码'; 注意:所有的数据库就用*.*,所有的权限就用all或者all privileges -
刷新权限
FLUSH PRIVILEGES; -
查看权限
SHOW GRANTS FOR 用户名@'IP地址'; 注意:'IP地址'可以设置为localhost(代表本机)或者'%'(代表允许所有IP地址登录) -
修改密码
#修改密码 SET PASSWORD = PASSWORD('123456'); #登录授权 GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY '123456'; #刷新授权 FLUSH PRIVILEGES; -
忘记密码
1、可以在配置文件里加上 skip-grant-tables ,注意写到[mysqld]参数组下,表示跳过授权 2、重启MySQL再登录就不需要密码,进去改密码,改完后,直接 FLUSH PRIVILEGES; 就可以使用新密码来登录了 (例:UPDATE mysql.user SET PASSWORD=PASSWORD("123456") WHERE USER="root" AND HOST="localhost";) 3、改完后记得去掉配置文件例的 skip-grant-tables,重新启动MySQL服务 4、再使用新的密码登录就可以了
2.数据库操作
-
创建数据库
-- REATE DATABASE [F NOT EXISTS] 数据库名 CREATE DATABASE IF NOT EXISTS school -
删除数据库
-- DROP DATABASE [IF EXISTS] 数据库名 DROP DATABASE IF EXISTS school -
使用数据库
USE school -
查看数据库
SHOW DATABASES -- 查看所有的数据库
2、数据库的数据类型
1.数值
| 类型 | 描述 | 所占字节 |
|---|---|---|
| tinyint | 十分小的整数值 | 1 |
| smallint | 较小的整数值 | 2 |
| mediumint | 中等大小的整数值 | 3 |
| int(常用) | 标准的整数 | 4 |
| bigint | 较大的整数值 | 8 |
| float | 浮点数 | 4 |
| double | 浮点数 | 8 |
| decimal | 字符串形式的浮点数,常用于金融计算 |
2.字符串
| 类型 | 描述 | 所占字节 |
|---|---|---|
| char | 定长字符串 | 0~255 |
| varchar | 可变长字符串 | 0-65535 |
| tinyblob | 不超过 255 个字符的二进制字符串 | 0~255 |
| tinytext | 短文本字符串 | 0~255 |
| blob | 二进制形式的长文本数据 | 0-65535 |
| text | 长文本数据 | 0-65535 |
| mediumblob | 二进制形式的中等长度文本数据 | 0-16777215 |
| mediumtext | 中等长度文本数据 | 0-16777215 |
| longblob | 二进制形式的极大文本数据 | 0-4294967295 |
| longtext | 极大文本数据 | 0-4294967295 |
注意:char(n) 和 varchar(n) 中括号中 n 代表字符的个数,并不代表字节个数,比如 CHAR(30) 就可以存储 30 个字符。
CHAR 和 VARCHAR 类型类似,但它们保存和检索的方式不同。它们的最大长度和是否尾部空格被保留等方面也不同。在存储或检索过程中不进行大小写转换。
3.时间日期
| 类型 | 所占字节 | 范围 | 格式 | 用途 |
|---|---|---|---|---|
| date | 3 | 1000-01-01/9999-12-31 | YYYY-MM-DD | 日期值 |
| time | 3 | '-838:59:59'/'838:59:59' | HH:MM:SS | 时间值或持续时间 |
| year | 1 | 1901/2155 | YYYY | 年份值 |
| datetime | 8 | 1000-01-01 00:00:00/9999-12-31 23:59:59 | YYYY-MM-DD HH:MM:SS | 混合日期和时间值 |
| timestamp | 4 | 1970-01-01 00:00:00/2038 结束时间是第 2147483647 秒 | YYYYMMDD HHMMSS | 混合日期和时间值,时间戳 |
4.null
没有值,未知
注意:不要使用null进行运算,结果为null
3、数据库字段属性
Unsigned:无符号的整数,申明了该列不能为负数zerofill:可用于任何数值类型,用0填充所有剩余字段空间null:为列指定null属性时,该列可以保持为空not null:如果将一个列定义为not null,将不允许向该列插入null值auto_increment:新插入的行赋一个唯一的整数标识符。为列赋此属性将为每个新插入的行赋值为上一次插入的ID+1(也可自定义)MySQL要求将auto_increment属性用于作为主键的列。此外,每个表只允许有一个auto_increment列。primary key:用于确保指定行的唯一性。指定为主键的列中,值不能重复,也不能为空。为指定为主键的列赋予auto_increment属性是很常见的,因为此列不必与行数据有任何关系,而只是作为一个唯一标识符。unique:被赋予unique属性的列将确保所有值都有不同的值,只是null值可以重复。一般会指定一个列为unique,以确保该列的所有值都不同。default:确保在没有任何值可用的情况下,赋予某个常量值,这个值必须是常量。binary:binary属性只用于char和varchar值。当为列指定了该属性时,将以区分大小写的方式排序。与之相反,忽略binary属性时,将使用不区分大小写的方式排序。
4、操作数据表
1.创建表
-- 一般格式,括号内最后一行不用加逗号,一切符号均使用英文符号
/*
CREATE TABLE [IF NOT EXISTS] `表名`(
`字段名` 数据类型 [属性] [属性] ··· [索引] [注释],
······,
······,
······,
`字段名` 数据类型 [属性] [属性] ··· [索引] [注释]
)ENGINE=InnoDB DEFAULT CHARSET=utf8 [注释]
*/
CREATE TABLE IF NOT EXISTS `student` (
`id` int NOT NULL AUTO_INCREMENT,
`stu_no` varchar(15) NOT NULL COMMENT '学号',
`stu_name` varchar(10) DEFAULT '匿名' COMMENT '姓名',
`stu_sex` varchar(2) DEFAULT '男' COMMENT '性别',
`brithday` date NOT NULL COMMENT '出生年月',
`phone` varchar(11) DEFAULT NULL COMMENT '电话号码',
`address` varchar(20) DEFAULT NULL COMMENT '家庭住址',
`email` varchar(50) DEFAULT NULL COMMENT '邮箱',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='学生表'
-- 搜索引擎InnoDB和默认字符集utf8在配置文件中已经申明,这里可以不用写
2.修改表
-
修改表名
-- ALTER TABLE 原表名 RENAME 新表名 ALTER TABLE score RENAME scores -
增加字段
-- ALTER TABLE 表名 ADD 字段名 数据类型 ALTER TABLE scores ADD `time` date -
修改字段约束
-- ALTER TABLE 表名 MODIFY 字段名 数据类型 [属性] ALTER TABLE scores MODIFY `time` datetime -
修改字段名
-- ALTER TABLE 表名 CHANGE 旧字段名 新字段名 数据类型 [属性] ALTER TABLE scores CHANGE `time` times time -
删除字段名
-- ALTER TABLE 表名 DROP 字段名 ALTER TABLE scores DROP `time`
3.删除表
-- DROP TABLE [IF EXISTS] 表名
DROP TABLE IF EXISTS score
4.查看表
-- 查看全部表
SHOW TABLES
-- 查看建表的sql语句
-- SHOW CREATE TABLE 表名
SHOW CREATE TABLE student
-- 查看表结构
-- DESC 表名
DESC student
5、操作表中数据
数据库存在的意义:存储数据,管理数据
1、DML操作数据
DML语言:数据操作语言,insert、update、delete
1.插入数据insert
insert into 表名 (字段1,字段2,···) values (值1,值2,···)
-- insert into 表名 (字段1,字段2,···) values (值1,值2,···)
insert into `user` (id,name,password) values(1,'张三','123456')
-- 可以省略字段名,但值要和字段名一一匹配
insert into `user` values(1,'张三','123456')
-- 一般情况下插入数据,字段名和值要一一匹配
-- 当主键自增时,可以不用写主键字段,如id字段是主键且自增,插入语句可写为
insert into `user` (name,password) values('张三','123456')
-- 同时插入多条数据,values后面的值使用,分开
insert into `user` values('张三','123456'),('李四','432126'),('王五','436426')
拓展:MD5加密
md5的全称是message-digest algorithm 5(信息-摘要算法),在90年代初由mit laboratory for computer science和rsa data security inc的ronald linn rivest开发出来,经md2、md3和md4发展而来。它的作用是让大容量信息在用数字签名软件签署私人密匙前被"压缩"成一种保密的格式(就是把一个任意长度的字节串变换成一定长的大整数)。
MD5还广泛用于加密和解密技术上,在很多操作系统中,用户的密码是以MD5值(或类似的其它算法)的方式保存的, 用户Login的时候,系统是把用户输入的密码计算成MD5值,然后再去和系统中保存的MD5值进行比较,而系统并不“知道”用户的密码是什么。
MYSQL实现MD5加密
如果数据库表User中有一列为password,存放的是md5加密的数据,
如何更新新的数据。
update user set `password` = md5("123321") where uName = "lihua";插入新的数据:
insert into user(uName,`password`) values("xiaoqiang",md5("123321"));这样存放在数据中的密码信息就是保密存放的,但是通过md5加密后的数据是
不能逆向使用的,也就是说如果想查看用户的密码信息,则需要通过数据查询匹配来实现。比如需要进行用户身份认证,则需要执行下面查询语句:
select * from user where uName = "lihua" and `password` = md5("123321");
2.修改数据update
修改哪张表,修改哪条数据,修改该条数据的哪个字段?修改多字段使用,隔开
update 表名 set 字段名 = 新值 [, 字段名 = 新值] where 条件
update `user` set name = '李华' where id = 1
update `user` set name = '李华',`password` = '324567' where id < 3
-- 通过多个条件定位数据,可以使用逻辑词and、or、between...and...等
update `user` set name = '李华' where id = 1 and `password` = '123456'
注意:如果不指定修改哪条数据,那么将修改整个表的数据的该字段!!!
3.删除数据delete
delete from 表名 where 条件
-- 这样会删除全部数据
delete from `user`
delete from `user` where id = 1
TRUNCATE操作:完全清空一个数据表,表的结构和索引约束不会变TRUNCATE和delete的区别:
- 相同点:都能删除数据,且不会删除表结构
- 不同点:
- TRUNCATE会重新设置自增列,计数器归零,自增重新从1开始
- TRUNCATE不会影响事务
2、DQL查询数据(超重点)
DQL:数据查询语言select
所有的查询都用它,简单的,复杂的都能做,数据库中的最核心的语言。基本上开发的所有系统大部分都是在查数据,所以要重点掌握。
select完整的语法:
SELECT [ALL | DISTINCT | DISTINCTROW | TOP] {* | talbe_name.* | [talbe_name.]field1 [AS alias1] [,[talbe_name.]field2[AS alias2] [,…]]} FROM talbe_name1 [AS table_alias1] [ LEFT | RIGHT | INNER | JOIN talbe_name2 [AS talbe_alias2] ON 连接条件] -- 连接查询 [WHERE…] -- 指定结果满足的条件 [GROUP BY…] -- 指定结果按照哪几个字段进行分组 [HAVING…] -- 过滤分组的记录须满足的次要条件 [ORDER BY…] -- 指定查询记录按一个或多个条件排序 [LIMIT {[offset,] row_count | row_countOFFSET offset}]; -- 指定查询的记录从哪条到哪条说明:
用中括号([])括起来的部分表示是可选的,用大括号({})括起来的部分是表示必须从中选择其中的一个。
1.简单查询(单表查询)
-
查询全部字段
-- SELECT * FROM 表名 SELECT * FROM `user` -
查询指定字段
-- SELECT 字段名1,字段名2··· FROM 表名 SELECT * FROM `user` -
给结果字段和表起别名
-- SELECT 字段名1 AS '别名1',字段名2 AS '别名1'··· FROM 表名 AS 别名 SELECT name AS '姓名',`password` AS '密码' FROM `user` AS a -- 经过试验,可以不用写AS,即 SELECT name '姓名',`password` '密码' FROM `user` a注意:别名可以使用单引号、双引号引起来,当只有一个单词时,可以省略引号,当有多个单词且有空格或特殊符号时,不能省略,AS可以省略。
-
使用函数
-- 统计数据条数 SELECT COUNT(*) '数据条数' FROM `user` -- 获取年龄,当前年份减去出生年份 YEAR(NOW())-YEAR(brithday) SELECT YEAR(NOW())-YEAR(brithday) '年龄' FROM student WHERE id = 1 -- 查询成绩等级 SELECT score, CASE WHEN score >= 90 THEN 'A' WHEN score <90 and score >= 75 THEN 'B' WHEN score <75 and score >= 60 THEN 'C' ELSE 'D' END AS 成绩级别 FROM SC ;控制函数:
1、IF(条件表达式,表达式1,表达式2):如果条件表达式成立,返回表达式1,否则返回表达式2
2、case的格式一:
CASE 变量或字段或表达式
WHEN 常量1 THEN 值1
WHEN 常量2 THEN 值2
...
ELSE 值n
END AS 返回值的别名;3、case的格式二:
CASE
WHEN 条件1 THEN 值1
WHEN 条件2 THEN 值2
...
ELSE 值n
END AS 返回值的别名MySQL有很多内置函数,具体可参考https://www.runoob.com/mysql/mysql-functions.html或参考MySQL官方文档:https://dev.mysql.com/doc/refman/8.0/en/built-in-function-reference.html
-
去重
-- select distinct * from 表名 select distinct * from `user` -
补充
-- 查看数据库版本 SELECT VERSION() -- 计算表达式 SELECT 10*4+4 '计算结果' -- 查看变量 SELECT @@auto_increment_increment '增量' -- 操作结果(给查询的分数加1分) SELECT studentno, studentresult + 1 '分数' FROM scores -- 判断某字段或表达式是否为null,如果为null,返回指定的值,否则返回原本的值 SELECT IFNULL(字段名, 指定值) FROM 表名; -- 判断某字段或表达式是否为null,如果是null,则返回1,否则返回0 SELECT ISNULL(字段名) FROM 表名;select 后面跟的都是表达式,文本值、列、Null、函数、计算表达式、系统变量等等。
select 表达式 from 表名 条件
2.条件查询
SELECT 查询列表 FROM 表名 WHERE 筛选条件;
-
条件运算符
>、>=、<、<=、=、< = >、! =、< >
注意:=只能判断普通类型的数值,而< = >不仅可以判断普通类型的数值还可以判断NULL
! =和< >都是判断不等于的意思,但是MySQL推荐使用< >
-- 查询工资大于12000的员工信息 SELECT * FROM employees WHERE salary > 12000 ; -- 查询员工编号<=>100的员工信息 SELECT * FROM employees WHERE employee_id <=> 100 ; -
逻辑运算符
and、or、not
-- 查询工资>12000和工资<18000的员工信息 SELECT * FROM employees WHERE salary > 12000 AND salary < 18000 ; -- 查询工资>12000或工资<18000的员工信息 SELECT * FROM employees WHERE salary <= 12000 OR salary >= 18000 ; -- 查询工资不在12000到18000的员工信息 SELECT * FROM employees WHERE NOT (salary > 12000 AND salary < 18000) ; -
模糊运算符
- like:%任意多个字符、_任意单个字符,如果有特殊字符,需要使用escape转义
- between and
- not between and
- in
- is null
- is not null
注意:in列表的值类型必须一致或兼容,in列表中不支持通配符%和_
=、 !=不能用来判断NULL、而< => 、is null 、 is not null可以用来判断NULL,但注意<=>也可以判断普通类型的数值
-- 查询员工名中第一个字符为B、第四个字符为d的员工信息 SELECT * FROM employees WHERE last_name LIKE 'B__d%' ; -- 查询员工编号在100到120之间的员工信息 SELECT * FROM employees WHERE employee_id BETWEEN 100 AND 120 ; -- 查询员工编号不在100到120之间的员工信息 SELECT * FROM employees WHERE employee_id NOT BETWEEN 100 AND 120 ; -- 查询员工的工种编号是 IT_PROG、AD_VP、AD_PRES中的一个的员工名和工种编号 SELECT last_name,job_id FROM employees WHERE job_id IN ('IT_PROT', 'AD_VP', 'AD_PRES') ; -- 查询没有奖金的员工名和奖金率 SELECT last_name,commission_pct FROM employees WHERE commission_pct IS NULL ; -- 查询有奖金的员工名和奖金率 SELECT last_name,commission_pct FROM employees WHERE commission_pct IS NOT NULL ;
3.排序查询
SELECT 查询列表 FROM 表
[WHERE 筛选条件]
ORDER BY 排序列表 [asc | desc] ;
- 排序列表可以是单个字段、多个字段、别名、函数、表达式
- asc代表升序,desc代表降序,如果不写,默认是asc
- order by的位置一般放在查询语句的最后(除limit语句之外)
-- 按单个字段排序:查询学生信息,要求按学号降序
SELECT * FROM student
ORDER BY SId DESC ;
-- 按多个字段排序:查询成绩信息,要求先按学号升序,再按成绩降序
SELECT SId, score FROM SC
ORDER BY SId ,score DESC
-- 按函数排序查询:查询学生信息,按名字长度降序
SELECT * FROM student
ORDER BY LENGTH(Sname) DESC ;
从左到右依次排列,如果出现重复值,则按照右侧的排序规则进行排序;
例如:学号序排序,但是遇到重复值,则再按照成绩降序排序
若学号没有重复值,则不用再按照成绩排序
4.分组查询
SELECT
查询列表
FROM
表
[where 筛选条件]
GROUP BY 分组的字段
[having 分组后的筛选]
[order BY 排序的字段];
和分组函数一同查询的字段必须是group by后出现的字段,分组可以按一个或多个字段分组,分组可以搭配排序使用
| 针对的表 | 语句位置 | 连接的关键词 | |
|---|---|---|---|
| 分组前筛选 | 分组前的原始表 | group by前 | where |
| 分组后筛选 | 分组后的结果集 | group by后 | having |
-- 查询各科总成绩
SELECT cid,SUM(score) `各科总成绩`
FROM sc
GROUP BY cid
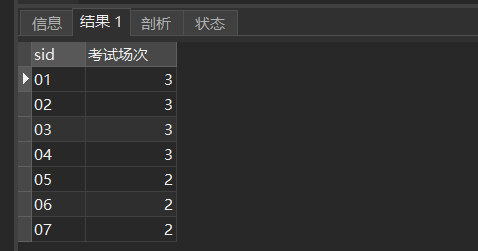
-- 每个学生考试场数,按考试场数升序
SELECT sid,COUNT(*) `考试场次`
FROM sc
GROUP BY sid
ORDER BY `考试场次`;
-- 查询不同课程的平均分,最高分,最低分,平均分大于80
-- 核心:(根据不同的课程分组)
SELECT c.CName,AVG(score) 平均分,MAX(score) 最高分,MIN(score) 最低分
FROM sc
INNER JOIN course c
ON sc.CId = c.CId
GROUP BY sc.CId -- 通过什么字段来分组
HAVING 平均分 > 80
where和having的区别
where:
- where是一个约束声明,使用where来约束来自数据库的数据;
- where是在结果返回之前起作用的;
- where中不能使用聚合函数。
having:
- having是一个过滤声明;
- 在查询返回结果集以后,对查询结果进行的过滤操作;
- 在having中可以使用聚合函数。
这里有个关于起别名的问题:
如果别名使用单引号''圈住的话,order by 别名 结果会出现错误,看下面的例子:
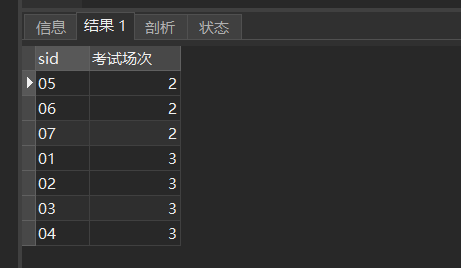
SELECT sid,COUNT(*) '考试场次' FROM sc GROUP BY sid ORDER BY '考试场次';结果:
结果是按照降序顺序排序,但默认是升序排序,若去掉单引号
SELECT sid,COUNT(*) 考试场次 FROM sc GROUP BY sid ORDER BY 考试场次;排序结果是正确的。
*结论:起别名不使用单引号和双引号,如果别名没有特殊字符(%、*、&、空格),就直接写别名,如图中的考试场次,若有特殊字符,需要加上
反引号``(Tab键上面),如`考试&场数`、`考试 场数`。在MySQL中创建的表名或字段名如果与MySQL的关键字冲突,加上反引号``即可。在Markdown中,反引号需要转义,否则会被解析成样式。在markdown中转义反引号有两种方式,一是使用反斜杠\加上反引号,但这种方式值适用于反引号不成对出现的情况下,若成对出现还是会被解析成样式;二是使用Unicode编码
`,这种方式反引号可以成对出现,推荐使用。
5.联合查询
-
UNION
UNION集合并运算符是针对两个集合操作的,两个集合必须有相同的列数;列具有相同的数据类型(至少能够隐式转换的);最终输出的集合的列名是,由第一个集合的列名来确定的(可以用来连接多个结果)。
查询选修了02号课程或者03号课程的学生的学号
SELECT SId FROM sc WHERE CId = 02 UNION SELECT SId FROM sc WHERE CId = 03
6.复杂查询(多表查询)
-
连接查询
连接查询又称多表查询,当查询的字段来自于多个表时,就会用到连接查询
7种连接方式:
-
内连接
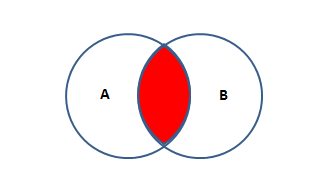
两张表共有的部分(内连接),取交集。保留了有交集的数据
SQL语句:
SELECT * FROM 表A A INNER JOIN 表B B ON A.KEY=B.KEY; -
左外连接
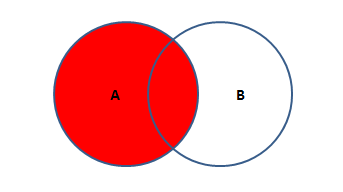
A独有的部分加上和A和B公共的部分。也叫左外连接。保留了A的全部数据和B的有交集的数据
SQL语句:SELECT * FROM 表A A LEFT JOIN 表B B ON A.KEY = B.KEY; -
右外连接
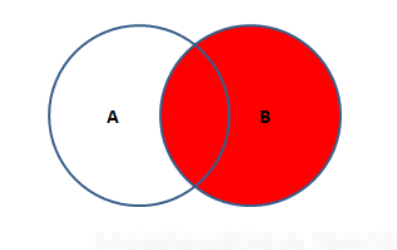
B独有的部分加上和A和B公共的部分。也叫右外连接。保留了B的全部数据和A的有交集的数据
SQL语句如下:
SELECT * FROM 表A A RIGHT JOIN 表B B ON A.KEY = B.KEY; -
A独有
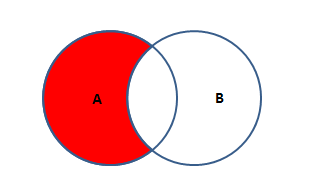
A表独有的部分。保留了A除去有交集的数据后的数据
SQL语句如下:SELECT * FROM 表A A LEFT JOIN 表B B ON A.KEY = B.KEY WHERE B.KEY IS NULL; -
B独有
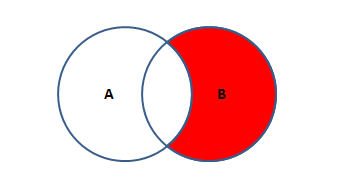
B表独有的部分。保留了B除去有交集的数据后的数据
SQL语句如下:SELECT * FROM 表A A RIGHT JOIN 表B B ON A.KEY = B.KEY WHERE A.KEY IS NULL; -
全连接(MySQL中不支持,Oracle支持)
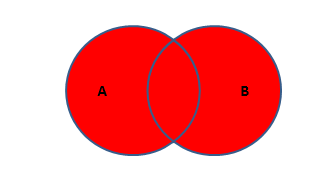
两张表的所有部分。就是左外连接+右外连接在去重一次,保留了A和B的完整数据
SQL语句如下(正常全连接的SQL语句):
SELECT * FROM 表A A FULL OUTER JOIN 表B B ON A.KEY = B.KEY;MySQL不支持全连接的直接实现方式,但是提供了间接的实现方式,就是A表独有+B表独有,在去重一次。
MySQL实现全连接的SQL语句如下:
SELECT * FROM 表A A LEFT JOIN 表B B ON A.KEY = B.KEY UNION -- 关键字union:就是连接并去重的意思 SELECT * FROM 表A A RIGHT JOIN 表B B ON A.KEY = B.KEY; -
全外连接
两张表的独有部分加起来,保留了去除A和B有交集的数据后的数据
直接实现的SQL语句如下:
SELECT * FROM 表A A FULL OUTER JOIN 表B B ON A.KEY = B.KEY WHERE A.KEY IS NULL OR B.KEY IS NULL;在MySQL中上面也不支持这条语句,有间接的实现方式。其实就是A独有和B独有加起来就OK了。
MySQL中实现全外连接的SQL语句如下:SELECT * FROM 表A A LEFT JOIN 表B B ON A.KEY = B.KEY WHERE B.KEY IS NULL UNION SELECT * FROM 表A A RIGHT JOIN 表B B ON A.KEY = B.KEY WHERE A.KEY IS NULL;
笛卡尔积:笛卡尔积又叫交叉连接(cross join),是在没有连接条件下的两个表的连接,包含了所连接的两个表中所有元组的全部组合,即若A表有m行,B表有n行,连接后表有m*n行。
SQL语句:
SELECT * FROM 表A A CROSS JOIN 表B B例子:
-- 内连接 -- 查询每个学生及其课程考试成绩 SELECT * FROM student s INNER JOIN sc ON s.sid=sc.SId -- 查询80分以上学生的学号、姓名、课程号、课程名、课程成绩 SELECT s.sid,sname,c.cid,cname,score FROM student s INNER JOIN sc ON s.sid=sc.SId and score > 80 JOIN course c on c.CId=sc.CId -- 外连接,左外连接和右外连接其实都差不多,就看你想要保留数据的表在join的左边还是 右边。 -- 查询缺考的学生信息 -- 思路:将学生表和成绩表连接,要查询缺考的学生,那么就要保留学生表的全部信息,就要使用左外连接,然后通过where语句找出成绩为null的学生。 SELECT s.* FROM student s LEFT JOIN sc ON s.sid = sc.SId WHERE score IS null -- 查询没有安排考试的课程信息 SELECT c.* FROM course c LEFT JOIN sc ON c.Cid = sc.cId WHERE sc.CId is NULL -- 上面的语句和下面的语句执行结果是一样的 SELECT c.* FROM sc RIGHT JOIN course c ON c.Cid = sc.cId WHERE sc.CId is NULL自连接:
顾名思义就是自己连接自己,因此只有一张表用来连接生成临时表;
例如:每一个员工(employee)都有自己的经理(manager),并且每一个经理自身也是公司的员工,自身也有自己的经理。下面我们需要将每一个员工自己的名字和经理的名字都找出来。此时只有一张表,该怎么做呢?
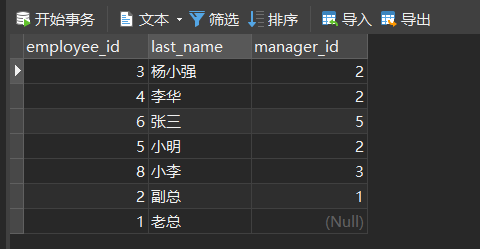
-- 查询员工名和它对应上级的名称 SELECT e.employee_id 员工id, e.last_name 员工名字, m.employee_id 经理id, m.last_name 经理名字 FROM employee e, employee m WHERE e.`manager_id` = m.`employee_id` ; -- 结果一样 SELECT e.employee_id 员工id, e.last_name 员工名字, m.employee_id 经理id, m.last_name 经理名字 FROM employee e JOIN employee m ON e.`manager_id` = m.`employee_id` ;结果:
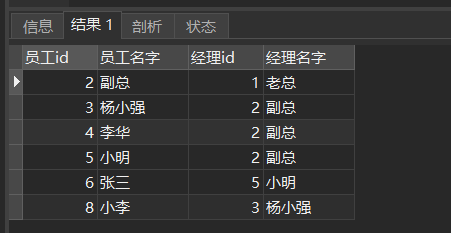
自连接实例:
-- 查询02课程成绩高于02学生的成绩的学生 SELECT a.* FROM sc a INNER JOIN sc b ON a.cid = 02 AND a.score > b.score AND b.sid = 02 AND b.cid = 02 ORDER BY a.score DESCSQL语句连接筛选条件放在ON和WHERE的区别
在连接查询语法中,另人迷惑首当其冲的就要属on筛选和where筛选的区别了, 在我们编写查询的时候, 筛选条件的放置不管是在on后面还是where后面, 查出来的结果总是一样的, 既然如此,那为什么还要多此一举的让SQL查询支持两种筛选器呢? 事实上, 这两种筛选器是存在差别的,只是如果不深究不容易发现而已。
SQL中的连接查询分为3种, cross join、inner join和outer join , 在 cross join和inner join中,筛选条件放在on后面还是where后面是没区别的,极端一点,在编写这两种连接查询的时候,只用on不使用where也没有什么问题。因此,on筛选和where筛选的差别只是针对outer join,也就是平时最常使用的left join和right join。
来看一个示例,左外连接学生表和成绩表,
SELECT s.*,sc.* FROM student s LEFT JOIN sc ON s.sid = sc.SId AND sc.CId = 01 ON之后的筛选结果如下图
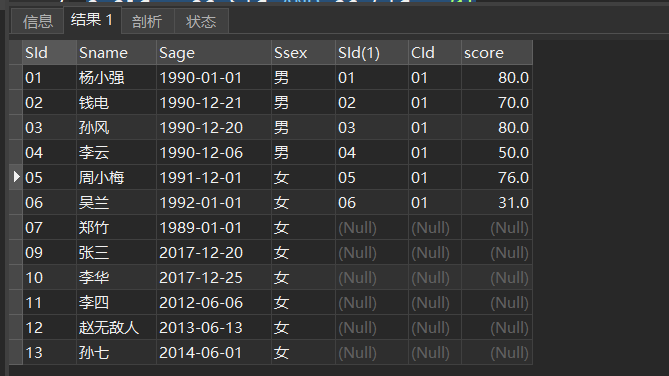
SELECT s.*,sc.* FROM student s LEFT JOIN sc ON s.sid = sc.SId WHERE sc.CId = 01 WHERE语句筛选结果如下:
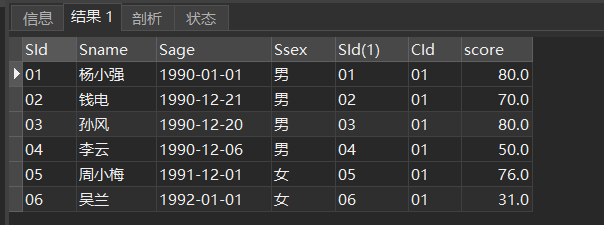
结论:
区别在于,筛选条件放在ON的后面是在联合之前就进行筛选,放在WHERE后面是在联合之后的结果集上进行筛选。
筛选条件放在ON的后面保留了基准表数据的完整性,筛选条件放在WHERE后面只筛选符合条件的数据,可以不保留基准表数据的完整性。
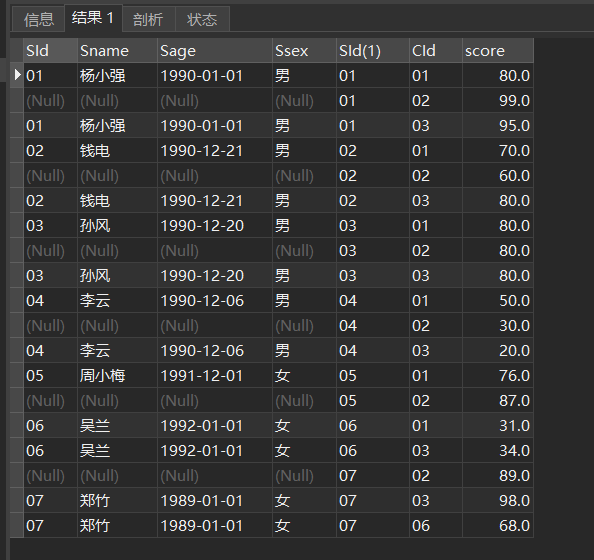
举个例子,学生表右外连接成绩表,筛选条件放在ON,
-- 筛选课程号不是02的学生和成绩信息 SELECT s.*,sc.* FROM student s RIGHT JOIN sc ON s.sid = sc.SId AND sc.CId <> 02 结果如下图,可以看出,sc表保留了完整的数据,但学生表的数据是不完整的。
可以这么理解,AND sc.CId <> 02 筛选掉了课程号为02的数据,但是为了保留sc表的数据的完整性,将本该过滤掉的记录又加了回来,而学生表中与sc表中课程号为02的课程关联的数据用null表示。
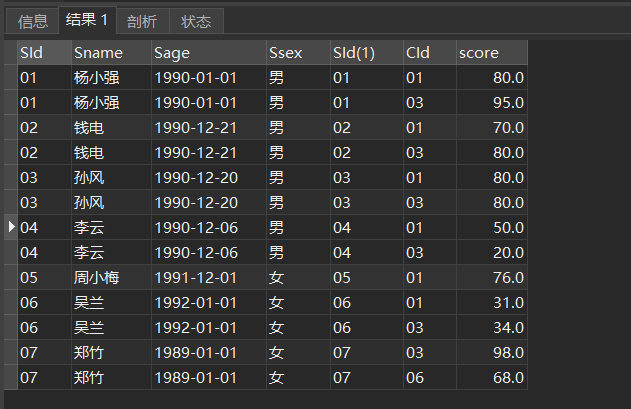
筛选条件放在WHERE
SELECT s.*,sc.* FROM student s RIGHT JOIN sc ON s.sid = sc.SId WHERE sc.CId <> 02 结果如下,可以看到sc表中的已经没有了课程号为02的记录。
-
-
子查询
子查询是指在一个SELECT查询语句中包含另一个SELECT查询语句,即一个SELECT语句嵌入到另一个SELECT语句中。其中,外层的SELECT语句称为父查询或外查询,外面的语句可以是insert、delete、update、select等,,嵌入内层的SELECT语句称为子查询或内查询。因此,子查询也被称为嵌套查询(nested query)。
-
无关子查询
无关子查询的执行不依赖于父查询。它的执行过程是:首先执行子查询语句,将得到的子查询结果集传递给父查询语句使用。无关子查询中对父查询没有任何引用。
例子:
-- 查询其他系中比计算机系(CS)某一学生年龄小的学生的姓名和年龄 SELECT sname, sage FROM student WHERE sage < ANY ( SELECT sage FROM student WHERE sdept = 'CS' ) AND sdept <> 'CS' -
相关子查询
在相关子查询中,子查询的执行依赖于父查询,多数情况下是子查询的WHERE语句中引用了父查询的表。
相关子查询的执行过程与无关子查询不同,无关子查询中的子查询只执行一次,而相关子查询中的子查询需要重复地执行。具体执行过程如下:
- 父查询每执行一次循环,子查询都会被重新执行一次,并且每一次父查询都将查询引用列的值传给子查询。
- 如果子查询的任何元组与其匹配,父查询就返回结果元组。
- 再回到第一步,直到处理完父表的每一个元组。
下面举例说明:
查询成绩表sc中每个课程大于该课程平均成绩的成绩信息SELECT * FROM sc As a WHERE score > ( SELECT AVG(score) FROM sc AS b WHERE a.CId=b.CId )在该语句中,内查询是求每个课程的平均成绩,至于是哪个课程的平均成绩需要看参数a.CId的值,而该值是与父查询相关的。
查询所有选修了课程号为02的学生的姓名
SELECT Sname FROM student s WHERE EXISTS ( SELECT * FROM sc WHERE sc.SId = s.SId AND CId = 02 ) -- 结果一样 SELECT Sname FROM student s WHERE s.SId IN ( SELECT sc.SId FROM sc WHERE sc.SId = s.SId AND CId = 02 ) -- 查询没有选修课程号为02的学生的姓名 SELECT Sname FROM student s WHERE NOT EXISTS ( SELECT * FROM sc WHERE sc.SId = s.SId AND CId = 02 ) SELECT Sname FROM student s WHERE s.SId NOT IN ( SELECT sc.SId FROM sc WHERE sc.SId = s.SId AND CId = 03 )带有EXISTS的子查询,通过逻辑与算符EXISTS或NOT EXISTS检查子查询返回的结果是否存在,使用EXISTS时,如果子查询的结果集中至少包含一个元组,则返回”TRUE“;如果结果集为空,则返回”FALSE“(有就输出,没有就不输出)。对于NOT EXISTS 结果取反。
子查询也可嵌套在查询结果集中:
-- 查询每个部门的员工个数 SELECT d.*, ( SELECT COUNT(*) FROM employees e WHERE e.department_id = d.`department_id` ) 个数 FROM departments d ;
-
7.分页查询
语法:
SELECT
查询列表
FROM
表1 别名1
【连接类型】 JOIN 表2 别名2 ON 连接条件
【WHERE 分组前的筛选】
【GROUP BY 分组字段】
【HAVING 分组后的筛选 】
【ORDER BY 排序字段 ASC|DESC】
LIMIT 【offset, 】size ;
- limit语句放在查询语句的最后
- offset代表起始索引,
起始索引从0开始,size代表条目个数 - 分页语句:select 查询列表 from 表 limit (page-1)*size,size;
例子
-- 查询02号课程成绩在前4名的学生学号和成绩
SELECT sid,score FROM sc
WHERE cid = 02
ORDER BY score DESC
LIMIT 0,4

 浙公网安备 33010602011771号
浙公网安备 33010602011771号