Product Quantization
Background
如何在数据海量的内容库中快速检索出Top-k的信息候选?
- 缩小查找的范围,快速找到最有可能成为近邻的一个粗集合
- 对Embedding向量做压缩,快速计算两个Embedding的距离。
本实践内容的代码管理在Codes24/FlashCIM/文件夹下的pq_lib中
Vector Quantization
将一个向量空间中的点用其中的一个有限子集来进行编码的过程。
通过Vector Quantization进行压缩的原理是减少表示图像的灰度级数。例如,我们可以使用 8 个值而不是 256 个值。因此,这意味着我们可以有效地使用 3 比特而不是 8 比特来编码单个像素,从而将内存使用量减少约 2.5 倍。
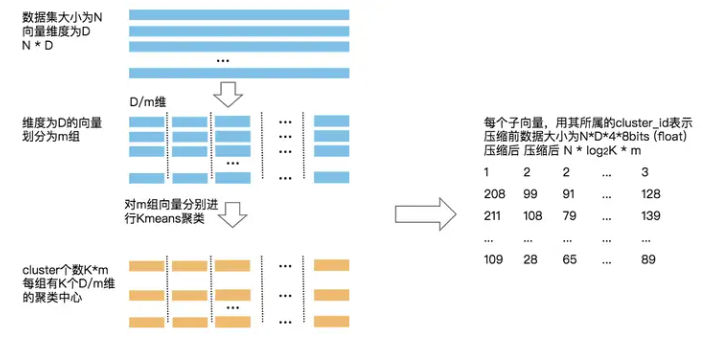
假设1个数据集中包含N个元素,每个元素是D维向量,使用K-MEANS算法进行聚类,最终产生K个聚类中心,如K=256,那么可用8bit进行表示,0-255表示每个cluster ID,通过cluster ID查询到中心的向量,用中心向量作为该元素的近似表示。
CSR=8bit32bit×DCSR=8bit32bit×D
Product quantization
把D维向量分成m组,每组进行Kmeans聚类。可以实现m组子向量的Kmeans算法并行求解,但同时表示空间增大,变为KmKm。
为什么要进行乘积量化?主要是为了减少索引的内存占用。乘积量化工作栈如下:
- 将一个大的、高维的向量分成大小相等的块,创建子向量。
- 为每个子向量确定最近的质心,将其称为再现或重建值。
- 用代表相应质心的唯一id替换这些再现值。
在生成码表和量化后,经常会求解一个query的最近邻或topk近邻,主要有SDC和ADC两种方法。
- SDC:x和y的距离等于经过encoding后的x和y的距离,即distance(q(x), q(y))。
- ADC:x和y的距离等于x和encoding后的y的距离, 即distance(x, q(y))。
IVFPQ
IVFPQ 是一种用于数据检索的索引方法,它结合了倒排索引(Inverted File)和乘积量化(Product Quantization)的技术。
- 倒排索引(Inverted File): 这是一种数据结构,用于加速搜索。对于每个特征向量,倒排索引存储了包含该特征向量的数据的列表,这使得在查询时可以快速定位包含相似特征的数据。
- 乘积量化(Product Quantization): 这是一种降维和量化的技术。在数据检索中,通常使用很高维度的特征向量来描述数据。乘积量化通过将这些高维向量分解成较小的子向量,并对每个子向量进行独立的量化,从而减少了存储和计算的复杂性。这有助于加快检索速度。
还有图v用这个i有如下:
- 建立索引: 在建立索引阶段,首先将数据库中的每个数据提取出高维度的特征向量。然后使用乘积量化将这些高维度的特征向量映射到低维度的码本中。最后在低维度的码本上构建倒排索引,为每个码本对应的数据建立一个倒排列表。
- 查询处理: 当进行查询时,首先将查询数据的特征向量进行乘积量化,映射到码本中。然后,通过倒排索引找到包含与查询码本相似的倒排列表。
- 倒排列表剪枝: 利用倒排列表的信息,可以剪枝掉一些明显不相似的数据,从而减小搜索空间。这是通过检查查询码本与倒排列表中的码本之间的距离进行的。
- 精确匹配: 对于剩余的倒排列表中的数据,通过计算它们的原始特征向量与查询特征向量之间的距离,进行更精确的匹配。这可以使用标准的相似性度量,如欧氏距离或余弦相似度。
- 返回结果: 根据相似性度量的结果,返回与查询数据相似度最高的数据作为搜索结果。
参考资料
https://github.com/GoGoDuck912/pytorch-vector-quantization/tree/main
https://blog.csdn.net/deephub/article/details/135102464
https://zhuanlan.zhihu.com/p/645783024
https://blog.csdn.net/fs1341825137/article/details/126246896


【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 清华大学推出第四讲使用 DeepSeek + DeepResearch 让科研像聊天一样简单!
· 推荐几款开源且免费的 .NET MAUI 组件库
· 实操Deepseek接入个人知识库
· 易语言 —— 开山篇
· Trae初体验