UI自动化测试4
1、白盒测试
在软件架构的层面来说,测试最核心的步骤就是在软件开发过程中。就软件本身而言,软件的行为或者功能是软件 细节实现的产物,这些最终是交付给用户的东⻄。所以在早期执行测试的系统有可能是一个可测试和健壮的系统, 它会带来为用户提供的功能往往是让人满意的结果。因此给予这样的⻆度,开始执行测试的最佳方法是来自源代 码,也就是软件编写的地方以及开发人员。由于源代码是对开发人员是可⻅的,这样的一个测试过程我们可以称为白盒测试。
2、自动化测试用例组成
在自动化测试过程中,编写的每一个测试用例都是需要借助单元测试框架的,那么在Python技术栈中,单元测试框架主要是unittest和Pytest,Java技术栈里面主要使用的是junit和testng。
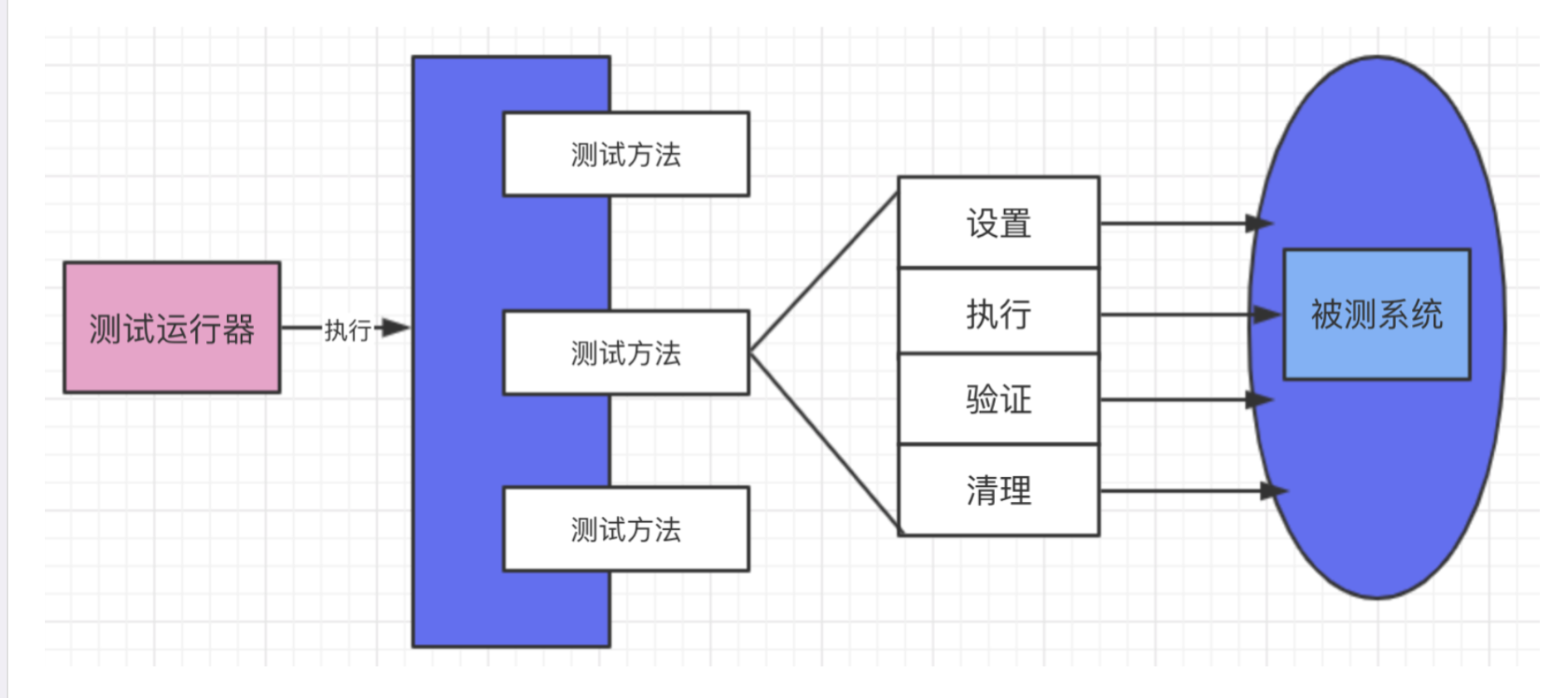
设置:做一件事的前置动作,也就是初始化 执行:测试步骤(具体干一件事的操作步骤) 验证:断言,验证做一件事的结果是否正确 清理:后置动作
2.1selenium原生的断言
(1)assertEqual:比较两个对象是否相等
def test_baidu_title(self):
'''验证百度title'''
title=self.driver.title
self.assertEqual(title,'百度一下,你就知道')
(2)assertIN:比较一个对象是否包含另一个对象;
(3)assertIs():比较两个字符串的内存地址
(4)assertTrue:针对bool类型验证true or false;真真为真,真假为假,即断言内容返回真,则为真,断言内容返回假则为假。
def test_baidu_displayed(self):
'''验证百度’关于百度‘是否可展示'''
so = self.driver.find_element(By.LINK_TEXT,'关于百度')
self.assertTrue(so.is_displayed())
3、单元测试
在python中,单元测试的框架主要就是unittest。unittest属于标准库,只要安装了python解释器后就可以直接导入使用了。导入的方式为:import unittest。自动化测试的方法是由unittest库下的TestCase类提供的,所以我们写自动化测试用例前必须继承unittest库中的TestCase类。
4、unittest测试框架
注意事项:
1、在测试类里面编写的测试方法必须是test开头的,也就是测试的步骤和断言部分的方法名,必须以test开头,推荐使用test_,并且一言以蔽之,如测试百度的标题名的测试用例,其方法名为:test_baidu_title(self)。
2、在测试类中,若使用的是常规的测试固件,那么有多少个测试用例,其里面的初始化和清理就执行多少次。
3、如果在测试类中,有很多个测试用例,而我们仅仅想执行某一个测试用例,那么就将鼠标放在该测试用例的名称处,然后运行即可。
4.1unittes组件
unittest是属于Python语言的单元测试框架,它的核心组件如下:
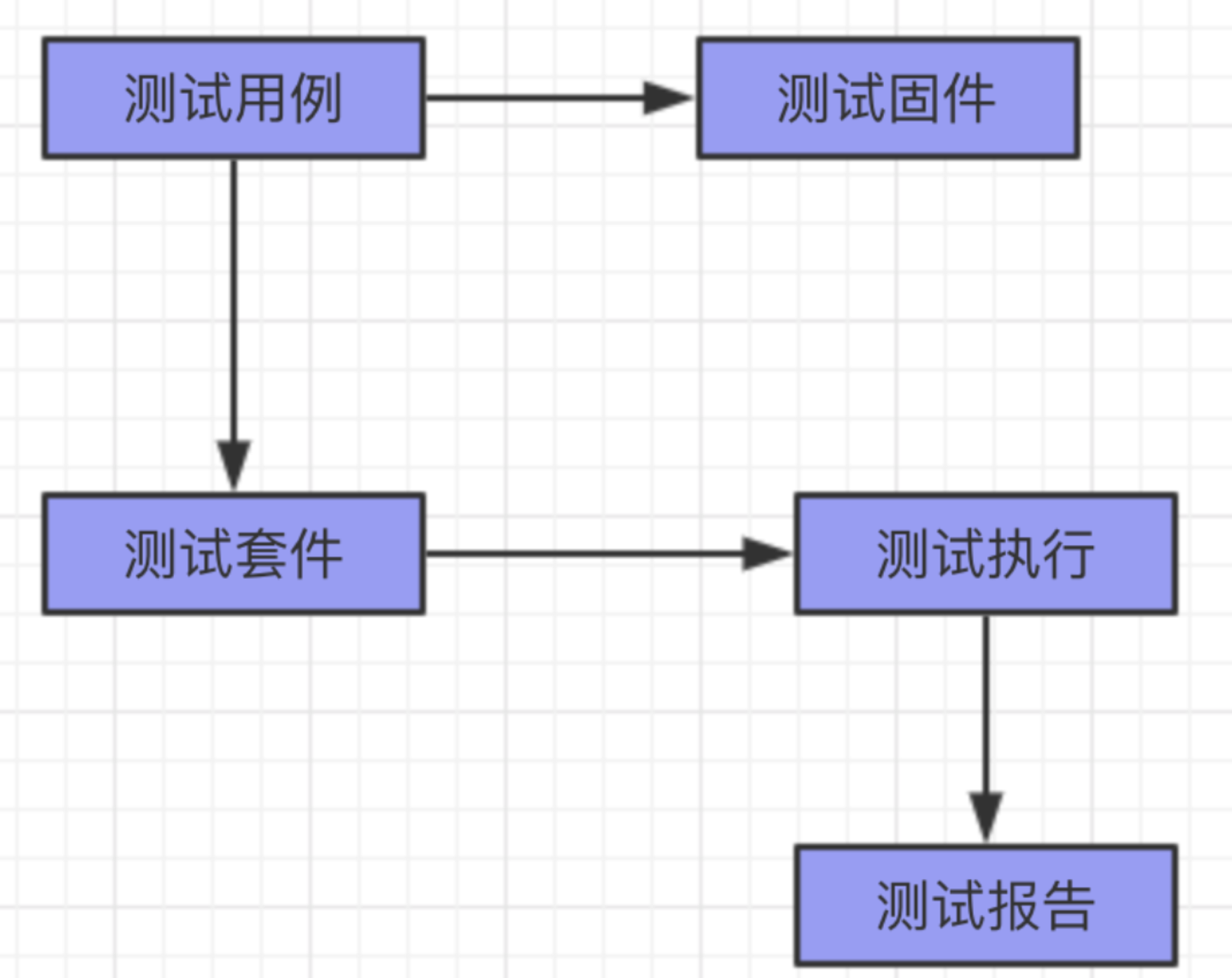
测试用例:就是测试类里面编写的测试方法 测试固件:初始化和清理,使用到的方法分别是setUp()和tearDown() 测试套件:就是测试用例的集合,在一个测试套件可以有很多的测试用例,它的英文单词是TestSuite 测试执行:TestRunner,执行测试套件或者测试用例 测试报告:TestReport,就是执行所有测试用例后的结果信息
4.1.1测试用例
在自动化测试类中编写的测试用例不需要刻意的进行排序,让测试框架内部按照他的排序规则去执行,其内通过是通过ascill码的规则将测试用例方法名称的字母转化为数字,这里不包含test这部分,是指test_后面的用例名称按照从小到大的顺序执行。
注意事项:
1、每个测试用例都需要有名字,也就是每个方法都必须由注释信息。
2、编写的每一个自动化测试用例都必须是独立的,和其他的测试用例之间没有任何的依赖性。
3、每个测试用例都必须由断言。
4、测试方法也就是测试用例的名称必须以test开头,最好规范、有约束、一言以蔽之,如test_。
5、最好一个测试用例方法对应一个业务测试点,不要多个业务检查点写在一个测试用例中。
6、如果涉及到业务逻辑的处理,最好把业务逻辑的处理放在断言前面,避免因为业务逻辑执行错误导致断言失败。
4.1.2测试固件
测试固件表示一个测试用例或者多个测试以及清理工作所需要的设置或者准备,也就是初始化和清理的步骤。
4.1.2.1常规测试固件
常规的测试固件:初始化setUp(self),清理tearDown(self)
4.1.2.2测试固件的分离
我们可以通过继承的思想,将测试固件分离出来,以确保当地址和浏览器改变时,我们操作比较简单。分离测试固件的时候,我们需要继承unittest.TestCase类,这是因为我们要调用的setUp(self)和tearDown(self)的方法是TestCase类中的,分离出来后,我们在测试类中继承我们分离出来的固件类就可以了。
#将测试固件放到一个python文件中,可在另外的类中直接继承
from selenium import webdriver
import unittest
class Init(unittest.TestCase):
def setUp(self) -> None:
self.driver = webdriver.Chrome()
self.driver.maximize_window()
self.driver.get('http://www.baidu.com')
self.driver.implicitly_wait(30)
def tearDown(self) -> None:
self.driver.quit()
#在另外的python文件中继承
from test.init import Init
class TestBaidu(Init):
4.1.3测试套件
测试套件顾名思义就是相关测试用例的集合。在unittest中主要通过TestSuite类提供对测试套件的支持,执行测试套件用的方法是unittest库下的TextTestRunner()类中的run的方法。
def alltests():
'''获取要执行的测试模块'''
suite=unittest.TestLoader().discover(
#start.dir指的是测试模块的路径
start_dir=os.path.dirname(__file__),
#pattern通过正则方式加载所有测试模块
pattern='test_*.py')
return suite
4.1.4测试执行
TestRunner:测试执行指的是针对测试套件或者是测试用例进行执行的过程。
4.1.5测试报告
TestReport:所有的测试测试用例执行完成后输出的汇总结果报告信息。unittest生成测试报告需要使用到第三方的HTMLTestRunner的库,下载该库后,把该库放在Python安装目录下的lib目录下。导入的方法为:import HTMLTestRunner。获取测试报告的步骤:
(1)在当前测试路径下创建一个report文件夹;
(2)加载所有的测试模块;
(3)获取测试报告。
import unittest
import os
import HTMLTestRunner
def alltests():
'''获取要执行的测试模块'''
suite=unittest.TestLoader().discover(
#start.dir指的是测试模块的路径
start_dir=os.path.dirname(__file__),
#pattern通过正则方式加载所有测试模块
pattern='test_*.py')
return suite
def run():
filename=os.path.join(os.path.dirname(__file__),'report','index.html')
fp=open(filename,'wb') #把测试报告写入文件中,b是以二进制的方式写入
runner=HTMLTestRunner.HTMLTestRunner(
stream=fp,
title='UI自动化',
description='first test'
)
runner.run(alltests())
if __name__ == '__main__':
run()

最终测试报告的结果

5、单元测试框架之参数化
5.1参数化概述
参数化就是指相同的测试步骤,不同的测试数据,那么这样的测试场景我们就可以使用参数化的解决思路来解决。也就是说使用一个测试用例的代码,执行多个测试场景。参数化需要借助外部的parameterized的库,安装命令:pip3 install parameterized。
5.2参数化本质
针对测试数据进行循环,每次循环的时候对列表中的元素的值一一赋值的过程。
5.3参数化示例
这里以新浪邮箱的登录输入框(用户名、密码)为例:
import unittest
from selenium import webdriver
from selenium.webdriver.common.by import By
import time as t
from parameterized import parameterized,param
class TestSina(unittest.TestCase):
def setUp(self) -> None:
self.driver = webdriver.Chrome()
self.driver.maximize_window()
self.driver.get('https://mail.sina.com.cn/')
self.driver.implicitly_wait(30)
def tearDown(self) -> None:
self.driver.quit()
#参数化需要借助外部的parameterized的库中的expand方法,param指向的是每次循环的测试数据。分别指用户名、密码和点击登录后提示的文本信息
@parameterized.expand([
param('','','请输入邮箱名'),
param('qwdq','dqwd','您输入的邮箱名格式不正确'),
param('qds.@sina.com','dqwd','登录名或密码错误')
])
def test_username_password(self,username,password,result):
'''新浪邮箱验证账户密码异常'''
self.driver.find_element(By.ID, 'freename').send_keys(username)
self.driver.find_element(By.ID, 'freepassword').send_keys(password)
self.driver.find_element(By.LINK_TEXT, '登录').click()
t.sleep(3)
text1 = self.driver.find_element(By.XPATH,'/html/body/div[3]/div/div[2]/div/div/div[4]/div[1]/div[1]/div[1]/span[1]')
self.assertEqual(text1.text, result)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号