WordCloud词云图
pyecharts-WordCloud词云图
一、什么是词云图?
词云图是一种用来展现高频关键词的可视化表达,通过文字、色彩、图形的搭配,产生有冲击力地视觉效果,而且能够传达有价值的信息。
制作词云图的网站有很多,简单方便,适合小批量操作。
BI软件如Tableau、PowerBI也可以做,当然相比较web网站复杂一点。
在编程方面,JavaScript是制作词云图的第一选择,像D3、echarts都非常优秀。
python也有不少可视化库能制作词云图,这次我们尝试使用pyecharts。
先上效果图(第一个遮罩是diamond 第二个是自定义的购物车形状遮罩图(文字填充黑色部分)):
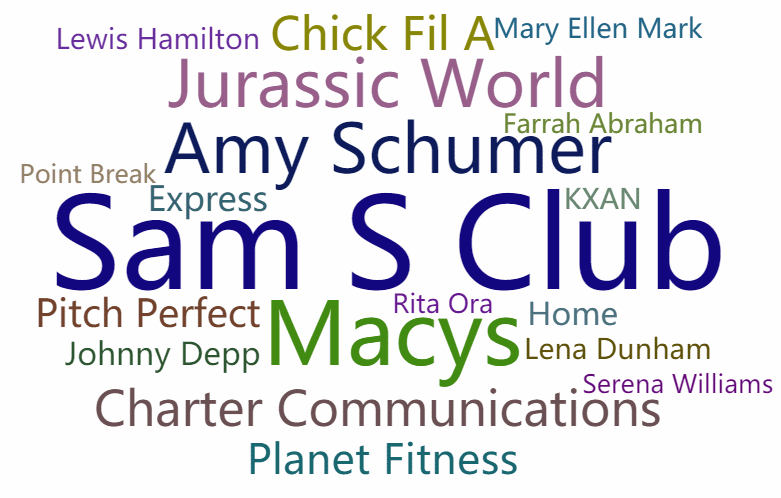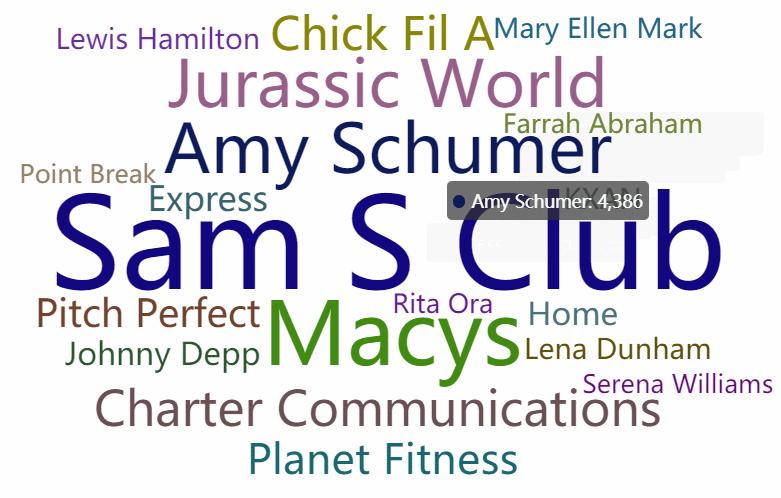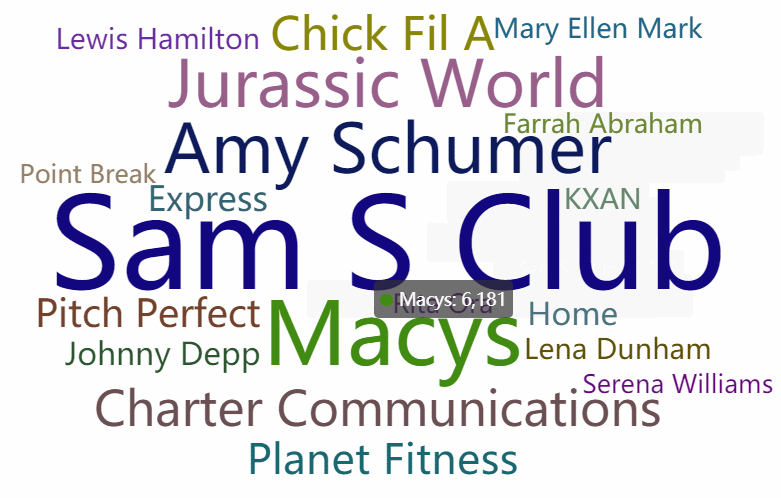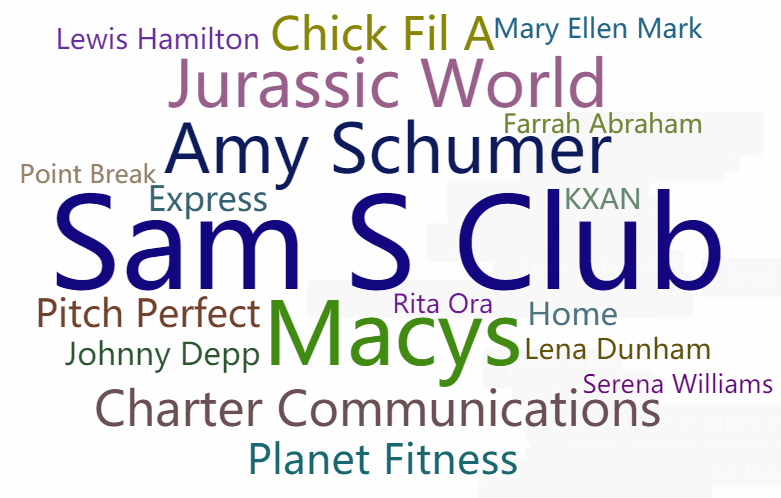

二、pyecharts介绍
pyecharts是基于echarts的python库,能够绘制多种交互式图表(鼠标滑过/点击能操作图表)。
pyecharts 分为 v0.5.X 和 v1 两个大版本,v0.5.X 和 v1 间不兼容。v1 是一个全新的版本,只支持Python3.6以上版本
pyecharts的特点如下:
- 简洁的 API 设计,使用如丝滑般流畅,支持链式调用
- 囊括了 30+ 种常见图表,应有尽有
- 支持主流 Notebook 环境,Jupyter Notebook 和 JupyterLab
- 可轻松集成至 Flask,Django 等主流 Web 框架
- 高度灵活的配置项,可轻松搭配出精美的图表
- 详细的文档和示例,帮助开发者更快的上手项目
- 多达 400+ 地图文件以及原生的百度地图,为地理数据可视化提供强有力的支持
import pyecharts.options as opts
from pyecharts.charts import WordCloud
"""
制作出来的html词云图文件,第一次打开无法显示,再次刷新就可了(这是echarts的bug)
"""
data = [
("生活资源", "999"),
("供热管理", "888"),
("供气质量", "777"),
("生活用水管理", "688"),
("一次供水问题", "588"),
("交通运输", "516"),
("城市交通", "515"),
("环境保护", "483"),
("房地产管理", "462"),
("城乡建设", "449"),
("社会保障与福利", "429"),
("社会保障", "407"),
("文体与教育管理", "406"),
("公共安全", "406"),
("公交运输管理", "386"),
("出租车运营管理", "385"),
("供热管理", "375"),
("市容环卫", "355"),
("自然资源管理", "355"),
("粉尘污染", "335"),
("噪声污染", "324"),
("土地资源管理", "304"),
("物业服务与管理", "304"),
("医疗卫生", "284"),
("粉煤灰污染", "284"),
("占道", "284"),
("供热发展", "254"),
("农村土地规划管理", "254"),
("生活噪音", "253"),
("供热单位影响", "253"),
("城市供电", "223"),
("房屋质量与安全", "223"),
("大气污染", "223"),
("房屋安全", "223"),
("文化活动", "223"),
("拆迁管理", "223"),
("公共设施", "223"),
("供气质量", "223"),
("供电管理", "223"),
("燃气管理", "152"),
("教育管理", "152"),
("医疗纠纷", "152"),
("执法监督", "152"),
("设备安全", "152"),
("政务建设", "152"),
("县区、开发区", "152"),
("宏观经济", "152"),
("教育管理", "112"),
("社会保障", "112"),
("生活用水管理", "112"),
("物业服务与管理", "112"),
("分类列表", "112"),
("农业生产", "112"),
("二次供水问题", "112"),
("城市公共设施", "92"),
("拆迁政策咨询", "92"),
("物业服务", "92"),
("物业管理", "92"),
("社会保障保险管理", "92"),
("低保管理", "92"),
("文娱市场管理", "72"),
("城市交通秩序管理", "72"),
("执法争议", "72"),
("商业烟尘污染", "72"),
("占道堆放", "71"),
("地上设施", "71"),
("水质", "71"),
("无水", "71"),
("供热单位影响", "71"),
("人行道管理", "71"),
("主网原因", "71"),
("集中供热", "71"),
("客运管理", "71"),
("国有公交(大巴)管理", "71"),
("工业粉尘污染", "71"),
("治安案件", "71"),
("压力容器安全", "71"),
("身份证管理", "71"),
("群众健身", "41"),
("工业排放污染", "41"),
("破坏森林资源", "41"),
("市场收费", "41"),
("生产资金", "41"),
("生产噪声", "41"),
("农村低保", "41"),
("劳动争议", "41"),
("劳动合同争议", "41"),
("劳动报酬与福利", "41"),
("医疗事故", "21"),
("停供", "21"),
("基础教育", "21"),
("职业教育", "21"),
("物业资质管理", "21"),
("拆迁补偿", "21"),
("设施维护", "21"),
("市场外溢", "11"),
("占道经营", "11"),
("树木管理", "11"),
("农村基础设施", "11"),
("无水", "11"),
("供气质量", "11"),
("停气", "11"),
("市政府工作部门(含部门管理机构、直属单位)", "11"),
("燃气管理", "11"),
("市容环卫", "11"),
("新闻传媒", "11"),
("人才招聘", "11"),
("市场环境", "11"),
("行政事业收费", "11"),
("食品安全与卫生", "11"),
("城市交通", "11"),
("房地产开发", "11"),
("房屋配套问题", "11"),
("物业服务", "11"),
("物业管理", "11"),
("占道", "11"),
("园林绿化", "11"),
("户籍管理及身份证", "11"),
("公交运输管理", "11"),
("公路(水路)交通", "11"),
("房屋与图纸不符", "11"),
("有线电视", "11"),
("社会治安", "11"),
("林业资源", "11"),
("其他行政事业收费", "11"),
("经营性收费", "11"),
("食品安全与卫生", "11"),
("体育活动", "11"),
("有线电视安装及调试维护", "11"),
("低保管理", "11"),
("劳动争议", "11"),
("社会福利及事务", "11"),
("一次供水问题", "11"),
]
(
WordCloud()
.add(series_name="热点分析", data_pair=data, word_size_range=[6, 66])
.set_global_opts(
title_opts=opts.TitleOpts(
title="热点分析", title_textstyle_opts=opts.TextStyleOpts(font_size=23)
),
)
.render("basic_wordcloud.html")
)
.add()函数的所有参数如下:
# 系列名称,用于 tooltip 的显示,legend 的图例筛选。 series_name: str, # 系列数据项,[(word1, count1), (word2, count2)] data_pair: Sequence, # 词云图轮廓,有 'circle', 'cardioid', 'diamond', 'triangle-forward', 'triangle', 'pentagon', 'star' 可选 shape: str = "circle", 如:shape=SymbolType.DIAMOND # 自定义的图片(目前支持 jpg, jpeg, png, ico 的格式,其他的图片格式待测试) # 该参数支持: # 1、 base64 (需要补充 data 头); # 2、本地文件路径(相对或者绝对路径都可以) # 注:如果使用了 mask_image 之后第一次渲染会出现空白的情况,再刷新一次就可以了(Echarts 的问题) # Echarts Issue: https://github.com/ecomfe/echarts-wordcloud/issues/74 mask_image: types.Optional[str] = None, # 单词间隔 word_gap: Numeric = 20, # 单词字体大小范围 word_size_range=None, # 旋转单词角度 rotate_step: Numeric = 45, # 距离左侧的距离 pos_left: types.Optional[str] = None, # 距离顶部的距离 pos_top: types.Optional[str] = None, # 距离右侧的距离 pos_right: types.Optional[str] = None, # 距离底部的距离 pos_bottom: types.Optional[str] = None, # 词云图的宽度 width: types.Optional[str] = None, # 词云图的高度 height: types.Optional[str] = None, # 允许词云图的数据展示在画布范围之外 is_draw_out_of_bound: bool = False, # 提示框组件配置项,参考 `series_options.TooltipOpts` tooltip_opts: Union[opts.TooltipOpts, dict, None] = None, # 词云图文字的配置 textstyle_opts: types.TextStyle = None, 如:textstyle_opts=opts.TextStyleOpts(font_family="cursive"), # 词云图文字阴影的范围 emphasis_shadow_blur: types.Optional[types.Numeric] = None, # 词云图文字阴影的颜色 emphasis_shadow_color: types.Optional[str] = None,
和其他可视化库不一样,pyecharts支持链式调用。
也就是说添加图表元素、修改图表配置,只需要简单的调用组件即可。
下面来个示例:
# 导入WordCloud及配置模块
from pyecharts import options as opts
from pyecharts.charts import WordCloud
from pyecharts.globals import SymbolType
# 添加词频数据
words = [
("Sam S Club", 10000),
("Macys", 6181),
("Amy Schumer", 4386),
("Jurassic World", 4055),
("Charter Communications", 2467),
("Chick Fil A", 2244),
("Planet Fitness", 1868),
("Pitch Perfect", 1484),
("Express", 1112),
("Home", 865),
("Johnny Depp", 847),
("Lena Dunham", 582),
("Lewis Hamilton", 555),
("KXAN", 550),
("Mary Ellen Mark", 462),
("Farrah Abraham", 366),
("Rita Ora", 360),
("Serena Williams", 282),
("NCAA baseball tournament", 273),
("Point Break", 265),
]
# WordCloud模块,链式调用配置,最终生成html文件
c = (
WordCloud()
.add("", words, word_size_range=[20, 100], shape=SymbolType.DIAMOND)
.set_global_opts(title_opts=opts.TitleOpts(title="WordCloud-shape-diamond"))
.render("wordcloud_diamond.html")
)
生成词云图:
Python爬虫+数据清洗+pyecharts词云图
-爬取豆瓣电影Top250 分析高产高分导演有哪些人?
1、爬虫爬取网页数据,存储到本地json文件
import requests
from bs4 import BeautifulSoup
import json
import re
headers = {
'User-Agent': 'User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.117 Safari/537.36',
"Host": "movie.douban.com",
"Referer": "https: // movie.douban.com / top250",
}
#请求数据
def reqHtml(url):
response = requests.get(url,headers=headers)
response.encoding = response.apparent_encoding
return response.text
#解析数据
def parseHtml(html):
soup = BeautifulSoup(html,"lxml")
ol = soup.select(".article .grid_view")[0]
for item in ol.select("li .item"):
newLine = {}
try:
picSrc = item.select(".pic img")[0]["src"]
title = item.select(".info .hd")[0].get_text().strip().replace("\n","")
bd = item.select(".info .bd p")[0].get_text().strip().replace("\n","")
starScore = item.select(".info .bd .star")[0].get_text().strip().replace("\n","")
quote = item.select(".info .bd .quote")[0].get_text().strip().replace("\n","")
newLine["picSrc"] = picSrc
newLine["title"] = title
newLine["bd"] = bd
newLine["starScore"] = starScore
newLine["quote"] = quote
print(newLine)
movie_info.append(newLine)
except:
print("====================>","本条信息爬取出错")
continue
#数据本地保存
def saveData(filename,data,mode="a+"):
with open("./spiderData/"+filename,mode) as fw:
#将数据data转为json格式 存入fw句柄中
fw.write(json.dumps(data))
print("------>","写入文件成功")
def startSpider():
for i in range(10):
print("开始爬取第%s页数据..."%i)
url = "https://movie.douban.com/top250?start={}&filter=".format(25 * i)
html = reqHtml(url)
data = parseHtml(html)
if __name__ == '__main__':
# movie_info = []
# startSpider()
#将获取的所有数据列表就写入文件中
# saveData("douban.json",movie_info)
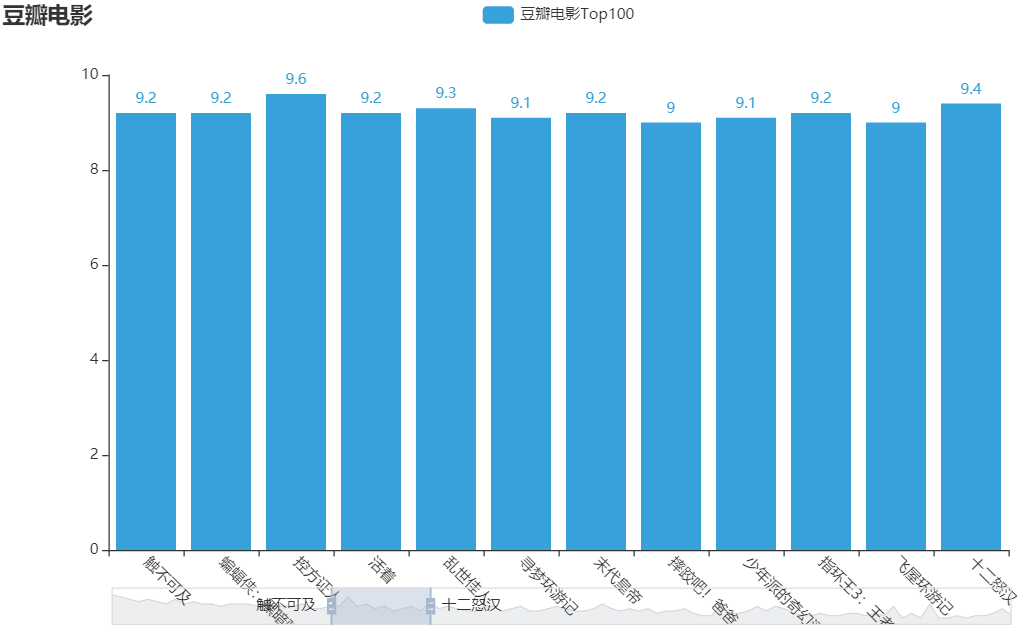
2、数据清洗并制作Bar柱状图
#柱状图
def showBar(data,filename,length=20):
xAxis = []
yAxis = []
for i in range(length):
title = re.split(r'/',data[i]["title"])[0]
score = float(data[i]["starScore"][:3])
xAxis.append(title)
yAxis.append(score)
bar = (Bar(init_opts=opts.InitOpts(theme=ThemeType.DARK))
.add_xaxis(xAxis)
.add_yaxis("豆瓣电影Top"+str(length),yAxis)
.set_global_opts(
title_opts={"text":"豆瓣电影","subtitle":"Top"+str(length)},
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=-45)),
datazoom_opts=opts.DataZoomOpts(range_start=0,range_end=11,pos_bottom="bottom"),
)
)
# render 会生成本地 HTML 文件,默认会在当前目录生成 render.html 文件
# bar.render()
# 也可以传入路径参数,如
bar.render("./dataVisual/"+filename+".html")
if __name__ == '__main__':
# movie_info = []
# startSpider()
#将获取的所有数据列表就写入文件中
# saveData("douban.json",movie_info)
#数据可视化展示-柱状图
with open("./spiderData/douban.json",'r') as fr:
data = json.loads(fr.readlines()[0])
showBar(data,"barRender",100)
3、数据清洗并制作WordCloud词云图
#词云图
def showWordCloud(data,filename):
from collections import Counter
c = Counter()
for item in data:
try:
director = re.findall('导演:(.*?)主演:',item["bd"],re.S)[0].strip()
c[director] = c[director]+1
except:
continue
print(c.most_common())
(
WordCloud()
.add(series_name="高分电影导演",
data_pair=c.most_common(), word_size_range=[3, 66],
rotate_step=30,
# mask_image="douban.png",
shape="diamond"
)
.set_global_opts(
title_opts=opts.TitleOpts(
title="高分电影导演", title_textstyle_opts=opts.TextStyleOpts(font_size=23)
),
tooltip_opts=opts.TooltipOpts(is_show=True),
)
.render("./dataVisual/"+filename+".html")
)
if __name__ == '__main__':
# movie_info = []
# startSpider()
#将获取的所有数据列表就写入文件中
# saveData("douban.json",movie_info)
#数据可视化展示-柱状图
with open("./spiderData/douban.json",'r') as fr:
data = json.loads(fr.readlines()[0])
# showBar(data,"barRender",100)
showWordCloud(data,"wordCloudRender")
效果图如下:

完整代码:
import requests
from bs4 import BeautifulSoup
import json
import re
from pyecharts.charts import Bar
from pyecharts import options as opts
from pyecharts.globals import ThemeType
from pyecharts.charts import WordCloud
from pyecharts.globals import SymbolType
headers = {
'User-Agent': 'User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.117 Safari/537.36',
"Host": "movie.douban.com",
"Referer": "https: // movie.douban.com / top250",
}
#请求数据
def reqHtml(url):
response = requests.get(url,headers=headers)
response.encoding = response.apparent_encoding
return response.text
#解析数据
def parseHtml(html):
soup = BeautifulSoup(html,"lxml")
ol = soup.select(".article .grid_view")[0]
for item in ol.select("li .item"):
newLine = {}
try:
picSrc = item.select(".pic img")[0]["src"]
title = item.select(".info .hd")[0].get_text().strip().replace("\n","")
bd = item.select(".info .bd p")[0].get_text().strip().replace("\n","")
starScore = item.select(".info .bd .star")[0].get_text().strip().replace("\n","")
quote = item.select(".info .bd .quote")[0].get_text().strip().replace("\n","")
newLine["picSrc"] = picSrc
newLine["title"] = title
newLine["bd"] = bd
newLine["starScore"] = starScore
newLine["quote"] = quote
print(newLine)
movie_info.append(newLine)
except:
print("====================>","本条信息爬取出错")
continue
#数据本地保存
def saveData(filename,data,mode="a+"):
with open("./spiderData/"+filename,mode) as fw:
#将数据data转为json格式 存入fw句柄中
fw.write(json.dumps(data))
print("------>","写入文件成功")
#数据分析及可视化
#柱状图
def showBar(data,filename,length=20):
xAxis = []
yAxis = []
for i in range(length):
title = re.split(r'/',data[i]["title"])[0]
score = float(data[i]["starScore"][:3])
xAxis.append(title)
yAxis.append(score)
bar = (Bar(init_opts=opts.InitOpts(theme=ThemeType.DARK))
.add_xaxis(xAxis)
.add_yaxis("豆瓣电影Top"+str(length),yAxis)
.set_global_opts(
title_opts={"text":"豆瓣电影","subtitle":"Top"+str(length)},
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=-45)),
datazoom_opts=opts.DataZoomOpts(range_start=0,range_end=11,pos_bottom="bottom"),
)
)
# render 会生成本地 HTML 文件,默认会在当前目录生成 render.html 文件
# bar.render()
# 也可以传入路径参数,如
bar.render("./dataVisual/"+filename+".html")
#词云图
def showWordCloud(data,filename):
from collections import Counter
c = Counter()
for item in data:
try:
director = re.findall('导演:(.*?)主演:',item["bd"],re.S)[0].strip()
c[director] = c[director]+1
except:
continue
print(c.most_common())
(
WordCloud()
.add(series_name="高分电影导演",
data_pair=c.most_common(), word_size_range=[3, 66],
rotate_step=30,
# mask_image="douban.png",
shape="diamond"
)
.set_global_opts(
title_opts=opts.TitleOpts(
title="高分电影导演", title_textstyle_opts=opts.TextStyleOpts(font_size=23)
),
tooltip_opts=opts.TooltipOpts(is_show=True),
)
.render("./dataVisual/"+filename+".html")
)
def startSpider():
for i in range(10):
print("开始爬取第%s页数据..."%i)
url = "https://movie.douban.com/top250?start={}&filter=".format(25 * i)
html = reqHtml(url)
data = parseHtml(html)
if __name__ == '__main__':
# movie_info = []
# startSpider()
#将获取的所有数据列表就写入文件中
# saveData("douban.json",movie_info)
#数据可视化展示-柱状图
with open("./spiderData/douban.json",'r') as fr:
data = json.loads(fr.readlines()[0])
# showBar(data,"barRender",100)
showWordCloud(data,"wordCloudRender")
参考:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号