ssm
spring
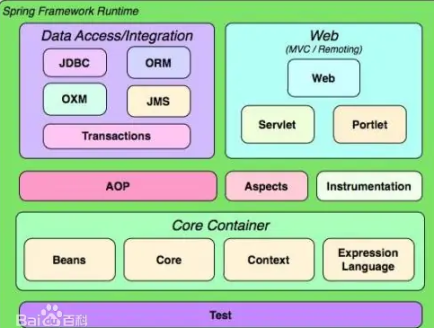
什么是spring?
spring是一个轻量级的控制反转(IOC)和面向切面(AOP)的JavaEE框架
什么是spring的IOC容器
把对象的创建、管理、装配交给spring容器;
spring容器通过依赖注入来管理组件
容器通过读取元数据(XML、注解、java代码提高)完成对象的实例化
目的:主要是为了解耦
什么是依赖注入(DI)—bean注入?
依赖注入是IOC的一种实现方式,意思是我们不用创建对象,而只需要描述它如何被创建。简而言之就是通过依赖注入提供给spring容器创建对象所需要信息。容器在运行期间动态的将某个依赖关系注入到组件之中。
依赖注入有三种实现方式:
- 构造函数注入:默认调用无参构造
<bean id="user" class="com.xc.User">
<!-- 使用有参构造注入 -->
<constructor-arg name="name" value="小葱"/>
<constructor-arg name="age" value="20"/>
</bean>
- setter注入
<bean id=”……” class=”……”>
<property name=”属性1” value=”……”/>
<property name=”属性2” value=”……”/>
……
</bean>
Spring先调用Bean的默认构造函数实例化Bean对象,然后通过反射的方式调用Setter方法注入属性值。
- 使用注解:@AutoWired
IOC容器的两种实现方式
- BeanFacttory:是spring内部的使用接口,不提供开发人员进行使用;它在加载配置文件的时候不会创建对象,当使用对象是才会进行加载;(懒加载)
- ApplicationContext:BeanFactory接口的子接口,提供更多更强大的功能,一般由开发人员使用。当加载配置文件的时候就会创建相应的对象;
两个子接口(ClassPathXmlApplicationContext)(FileSystemXmlApplicationContext)
spring提供的配置方式
- 基于XML的配置:bean所依赖的组件在xml配置文件指定
<!--配置User对象创建-->
<bean id="user" class="com.xc.User">
<!-- 使用set方法注入属性
name:类里面属性名字(set后面的)
value:向属性注入的值
如果是值是集合:可以以property为基准继续赋值,数组(array),集合(list、map、set)
如果值是对象:<ref bean="唯一标识"/>
-->
<property name="name" value="小葱"/>
<property name="age" value="12"/>
</bean>
- 基于注解的配置:默认spring容器不会开启注解装配,需要手动开启
<!-- 引入注解配置 -->
<context:annotation-config/>
- 基于javaAPI配置
spring的java配置是通过@Bena和@Configuration来实现
- @Bean的作用和xml里面的
作用相同 - @Configuration表名该类是配置类,可以使用@Bean注解,放在类的上面
@Configuration//作为配置类,替代xml配置文件
@ComponentScan(basePackages = {"com.xc"})//组件扫描
@EnableTransactionManagement//开启事务注解
public class SpringConfig {
//创建数据库连接池
@Bean//用在方法上,把方法的返回值加入spring容器
public DruidDataSource getDataSource(){
DruidDataSource dataSource = new DruidDataSource();
dataSource.setDriverClassName("com.mysql.cj.jdbc.Driver");
dataSource.setUrl("jdbc:mysql:///test");
dataSource.setUsername("root");
dataSource.setPassword("root");
return dataSource;
}
//创建JdbcTemplate对象
@Bean
public JdbcTemplate getJdbcTemplate(DataSource dataSource){
//到ioc容器中根据类型找到dataSource
JdbcTemplate jdbcTemplate = new JdbcTemplate();
jdbcTemplate.setDataSource(dataSource);
return jdbcTemplate;
}
//创建事务管理器
@Bean
public DataSourceTransactionManager getTransactionManager(DataSource dataSource){
DataSourceTransactionManager transactionManager = new DataSourceTransactionManager();
transactionManager.setDataSource(dataSource);
return transactionManager;
}
}
spring中bean的作用域
scope配置项有几个个属性,用于描述不同的作用域。
- singleton:唯一的bean实例,spring中的bean默认是单例的
- prototype:每次请求都会创建一个新的bean实例
- request:每一次http请求都会产生一个新的bean,该bean只在当前的http request有效
- session:在一个http session中,一个bean对应一个实例
- global-session:全局的session
最后是三个,只在web 的ApplciationContext有效
将一个类声明为spring的bean的注解
- @Component:可以标注任意的类为spring的组件
- @Repository:对应持久层—dao层,主要用于数据库的操作
- @Service:对应服务层,主要实现一些复杂的逻辑,需要用到dao层
- @Controller:对springmvc的控制层,主要用于接收用户的请求并且调用service层返回数据给前端页面
spring中bean的生命周期?
Bean的生命周期是有spring容器来管理的:从对象创建到对象销毁的过程
- 实例化bena实例(无参构造),以及设置bean的属性
- 如果Bean实现了BeanNameAware接口的话,Spring将Bean的Id传递给setBeanName()方法(传入bean的名字)
- 如果Bean实现了BeanFactoryAware接口的话,Spring将调用setBeanFactory()方法,将BeanFactory容器实例传入,可以获取其他的Bean
- 接着会调用BeanPostProcess的前置初始化方法postProcessBeforeInitialization(主要作用是在spring实例化之后,初始化之前,添加一些自定义的处理逻辑)
- 如果实现类BeanFactoryPostProcess接口调用afterPropertiesSet方法,做一些属性被设定后自定义操作
- 调用Bean自己定义的init方法,做一些初始化操作
- 调用BeanPostProcess的后置初始化方法postProcessAfterInitialization方法,做一些初始完成之后的自定义操作
- 此时Bean已经准备就绪,可以在容器中使用,并且会一直在应用上下文当中,直到被销毁
- 如果bean实现了DisposableBean接口,Spring将调用它的destory()接口方法,同样,如果bean使用了destory-method 声明销毁方法,该方法也会被调用。
spring的自动装配
自动装配就是:当需要某个对象时,会通过Spring的上下文为你找出相应依赖项的类,通俗的说就是Spring会在上下文中自动查找,并自动给Bean装配与其相关的属性!
实现自动装配的两种方式:
- 通过XML配置文件
在xml配置文件中的bean标签中加入一个属性autowire
<bean id="people" class="com.xc.test" autowire="byName">
<property name="name" value="张三"/>
</bean>
使用autowire关键字声明bean的自动装配方式。
属性值:
byName:通过bean名字,也就是setter方法后的名字,再到配置文件中寻找一个与该名字相同id的Bean,注入
byType:根据类型注入(也就是class:在xml里要唯一,否则会报错)
constructor:通过构造函数注入来注入依赖项,适合注入大量参数
no:默认设置,没有自动装配
- 通过注解
<context:annotation-config/> 使用注解前应在xml配置文件开启注解配置
- @AutoWired:根据属性类型(byType)进行注入
- @Qualifier:bean的id
- @Resource:先根据组件名称(默认)、找不到,再通过属性类型查找
- @Value:注入普通类型属性
spring中同名的bean
- 同一个配置文件中存在同名的bean,以上面的为准
- 不同配置文件中存在同一个bean,后解析的配置文件会覆盖先解析的配置文件
- 同文件中@Component和@Bean出现同名bean,@Bean会生效
spring中循环依赖
就是对象A依赖对象B,对象B依赖对象A,形成了闭环。
public class A {
private B b;
}
public class B {
private A a;
}
- 通过构建函数创建A对象(A对象是半成品,还没注入属性和调用init方法)。
- A对象需要注入B对象,发现对象池(缓存)里还没有B对象(对象在创建并且注入属性和初始化完成之后,会放入对象缓存里)。
- 通过构建函数创建B对象(B对象是半成品,还没注入属性和调用init方法)。
- B对象需要注入A对象,发现对象池里还没有A对象。
- 创建A对象,循环以上步骤。
问题:如果在日常开发中我们用new 对象的方式发生这种循环依赖的话程序会在运行时一直循环调用,直至内存溢出报错。
spring循环依赖场景有两种:
-
构造器的循环依赖:spring是无法解决的,只能抛出
BeanCurrentlyInCreationException异常表示循环依赖 -
field属性的循环依赖:spring只解决scope为singleton(单例的setter)循环依赖,如果是多例,会抛出异常
解决方法:
通过三级缓存来解决循环依赖

spring单例对象的初始化大致分为三步:
- createBeanInstance:实例化,调用对象的构造方法实例化对象
- populateBean:填充属性,这一步主要是多bean的依赖属性进行填充
- initializeBean:初始化bean
其中一级缓存为单例池(
singletonObjects),二级缓存为早期曝光对象earlySingletonObjects,三级缓存为早期曝光对象工厂(singletonFactories)。-当A、B两个类发生循环引用时,在A完成实例化后,就使用实例化后的对象去创建一个对象工厂,并添加到三级缓存中;
当A进行属性注入时,发现依赖于B对象,此时尝试getBean(B),发现B还没创建,于是创建B,B在初始化的时候发现自己依赖于对象A,于是尝试getBean(A),尝试一级缓存(此时肯定没有,因为A还没初始化完全),尝试二级缓存(没有),尝试三级缓存(先获取缓存中的工厂,再通过工厂的getObject方法获取到对象)可以获取到对象,就注入对象B;此后B会走完其生命流程;当B创建完后,又注入A,A再完成整个生命周期。
为什么要使用三级缓存呢?二级缓存能解决循环依赖吗?“
二级缓存可以解决没有AOP代理的循环依赖
答:如果要使用二级缓存解决循环依赖,意味着所有Bean在实例化后就要完成AOP代理,这样违背了Spring设计的原则,Spring在设计之初就是通过后置处理器来在Bean生命周期的最后一步来完成AOP代理,而不是在实例化后就立马进行AOP代理。
spring中的单例Bean的线程安全问题
spring中的Bean默认是单例的,所以在定义成员变量时候可能会有线程安全问题
有状态Bean:可以存储数据,有实例变量的对象,是非线程安全的
无状态Bean:不可以存储数据,是不变的类,是线程安全的
解决方法:
- 把单例改为多例,这样每次请求都会创建一个新的bean,有自己的独立空间,来保证线程安全
- 使用ThreadLocal类:为每个使用该变量【全局变量、静态变量和类的成员变量】的线程分配一个独立的变量副本,从而互不影响
什么是AOP?
AOP:面向切面编程,就是在不改变源代码的情况下,实现功能的增强
实现AOP的技术:
- 静态代理(Aspectj):指使用AOP框架提供的命令进行编译,在编译阶段就可以生成代理类;因此也称编译时增强
- 动态代理:运行时,在内存中临时生成代理类。因此也称为运行时增强
- JDK的动态代理(有接口情况):通过反射来接收被代理的类,并且要求被代理的类必须实现一个接口。jdk代理的核心是InvocationHandler和 Proxy.newProxyInstance类
public class JDKProxy {
public static void main(String[] args) {
//创建接口实现类的代理对象
Class<?>[] interfaces = {UserDao.class};
UserDaoImpl userDao = new UserDaoImpl();
UserDao dao = (UserDao) Proxy.newProxyInstance(JDKProxy.class.getClassLoader(), interfaces, new UserDaoProxy(userDao));
System.out.println(dao.add(10, 20));
}
}
class UserDaoProxy implements InvocationHandler{
//1、把要增强的方法的对象传过来
private Object object;
public UserDaoProxy(Object o){
this.object=o;
}
//增强的逻辑
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
//方法之前执行
System.out.println("方法之前执行----"+method.getName()+"传递的参数----"+ Arrays.toString(args));
//被增强的方法执行
Object res = method.invoke(object, args);
//方法之后执行
System.out.println("方法之后执行----"+object);
return res;
}
}
- 无接口情况:使用CGLIB动态代理,创建当前类的子类的代理对象;通过继承的方式做的动态代理
- 定义一个类;
- 自定义
MethodInterceptor并重写intercept方法,intercept用于拦截增强被代理类的方法,和 JDK 动态代理中的invoke方法类似; - 通过
Enhancer类的create()创建代理类;
public class EmployeeAbilityCglibProxy {
public static EmployeeService createCglibProxy(Class cls) {
//创建Enhancer对象
Enhancer enhancer = new Enhancer();
//设置Enhancer对象的父类
enhancer.setSuperclass(cls);
//设置回调方法
enhancer.setCallback(new MethodInterceptor() {
public Object intercept(Object o, Method method, Object[] args,
MethodProxy methodProxy) throws Throwable {
//通过调用父类的方法实现对原始方法的调用
Object result = methodProxy.invokeSuper(o, args);
//后置增强内容,区别:JDKProxy仅对接口方法做增强,cglib对所有方法做增强,包括所有父类中的方法
if (method.getName().equals("getAbility")) {
System.out.println("拥有 C# 语言的开发能力");
System.out.println("拥有 Go 语言的开发能力");
}
return result;
}
});
//使用Enhancer对象创建对应的对象
return (EmployeeService) enhancer.create();
}
}
public class ProxyApp {
public static void main(String[] args) {
System.out.println("员工原始能力:");
EmployeeService es = new EmployeeServiceImpl();
es.getAbility();
System.out.println("==========================");
System.out.println("员工使用【Cglib 动态代理】进行增强后:");
EmployeeService esProxy =
EmployeeAbilityCglibProxy.createCglibProxy(EmployeeServiceImpl.class);
esProxy.getAbility();
}
}
spring事务的实现方式有哪些
- 编程式事务管理:通过编程的方式管理事务,灵活但难以维护
- 声明式事务(底层AOP):只需要通过注解和xml配置事务管理
- 基于注解方式
基于注解方式(常用):
@Transactional:在类上,表示这个类所有的方法都添加事务;如果在方法上,为这个方法添加事务
@Configuration//作为配置类,替代xml配置文件
@ComponentScan(basePackages = {"com.xc"})//组件扫描
@EnableTransactionManagement//开启事务
public class JdbcConfig {
//创建数据库连接池
@Bean//用在方法上,把方法的返回值加入spring容器
public DruidDataSource getDataSource(){
DruidDataSource dataSource = new DruidDataSource();
dataSource.setDriverClassName("com.mysql.cj.jdbc.Driver");
dataSource.setUrl("jdbc:mysql:///test");
dataSource.setUsername("root");
dataSource.setPassword("root");
return dataSource;
}
//创建JdbcTemplate对象
@Bean
public JdbcTemplate getJdbcTemplate(DataSource dataSource){
//到ioc容器中根据类型找到dataSource
JdbcTemplate jdbcTemplate = new JdbcTemplate();
jdbcTemplate.setDataSource(dataSource);
return jdbcTemplate;
}
//创建事务管理器
@Bean
public DataSourceTransactionManager getTransactionManager(DataSource dataSource){
DataSourceTransactionManager transactionManager = new DataSourceTransactionManager();
transactionManager.setDataSource(dataSource);
return transactionManager;
}
}
- 基于xml配置文件
<!--创建事务管理器-->
<bean id="transactionManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager">
<!--注入dataSource-->
<property name="dataSource" ref="dataSource"/>
</bean>
<!--开启事务注解-->
<tx:annotation-driven transaction-manager="transactionManager"></tx:annotation-driven>
事务的传播行为
propagation:事务传播行为(当一个事务方法被另一个事务方法调用时,这个事务方法如何进行)
- REQUIRED:如果有事务在运行,当前的方法就在这个事务内运行,否则,就启动一个新的事务,并且在自己的事务内运行
- REQUIRED-NEW:当前的方法必须启动新事务,并且它自己的事务内运行,如果有事务正在运行,应该将它挂起
- SUPPORTS:如果有事务正在运行,当前的方法就在这个事务内运行,否则它可以不运行在事务中
springmvc
springmvc的工作流程
- 用户发送请求(url)到DispatcherServlet(中央处理器)之后被拦截进行处理
- DispatcherServlet根据请求的信息调用HandlerMapper(处理器映射器),解析对应的handler。
- 解析到对应的handler(也就是Controller控制器)后,开始由HandlerAdapter(处理器适配器)处理
- HandlerAdapter会根据handler来调用真正的handler处理请求,并且处理相应的业务逻辑
- 处理完业务后,会返回一个ModelAndView对象,model是数据对象,view是逻辑上的view
- ViewResolver(视图解析器)会根据逻辑view找到真正的view
- DispatcherServlet把返回的model传给view(视图渲染)
- 最后把view返回给浏览器
@Controller注解的作用
该注解标记一个类为springmvc的 控制器controller,并且会交给spring管理。spring会扫描到该注解的类,然后扫描这个类下面带有@RequestMapper注解的方法,为这个方法生成一个处理器对象
还可以实现springmvc提供的Controller和HttpRequestHandler接口,对应的实现类也会被当场一个处理器对象
@RequestMapper作用:配置处理器的http请求方法,url,这样才能将请求和方法进行映射;简而言之就是通过http请求的url来访问对应的方法:可以用在类和方法上
@ResponseBody+@Controller = @RestController
@RequestBody:只能是post请求,接收一个json格式的数据
@Controller
@ResponseBody
@RequestMapping("/admin")
public class TestController {
@RequestMapping("/add")
public String add(@RequestBody User user){
return "test";
}
}
@RequestParam:用在方法参数,请求的参数
- 不加@RequestParam前端的参数名需要和后端控制器的变量名保持一致才能生效
- 不加@RequestParam参数为非必传,加@RequestParam写法参数为必传。但@RequestParam可以通过@RequestParam(required = false)设置为非必传。
- @RequestParam可以通过@RequestParam(“userId”)或者@RequestParam(value = “userId”)指定传入的参数名。
@PathVarible:用在方法参数,路径的变量 接收请求路径中占位符的值
//当使用Restful风格进行编程时,
@RequestMapping("/login/{id}/{pwd}")
public String login(@PathVariable int id,@PathVariable int pwd){
return "登入成功";
}
什么是springmvc的拦截器?
拦截器的作用:拦截用户的请求并且做出相应的处理。如权限验证、记录请求信息的日志、判断用户是否登录
拦截器的实现:实现HandlerInterceptor接口,重写方法
public interface HandlerInterceptor {
// 在Controller得到请求的时候进行拦截,如果不放行请求则Controller得不到请求
// 执行时机:在处理器方法执行前执行 返回false不放行;返回true,放行
default boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
方法参数:
1)request请求对象
2)response响应对象
3)handler拦截到的方法处理
return true;
}
//在处理器的方法执行后,视图渲染之前
default void postHandle(HttpServletRequest request, HttpServletResponse response, Object handler, @Nullable ModelAndView modelAndView) throws Exception {
执行时机:
方法参数:
1)request请求对象
2)response响应对象
3)handler拦截到的处理器方法
4)ModelAndView处理器方法返回的模型和视图对象,可以在方法中修改模型和视图
}
// 在视图跳转完成后调用此方法
default void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, @Nullable Exception ex) throws Exception {
}
}
springmvc的核心配置文件:
<!-- 配置拦截器 可以配置多个 按照顺序 -->
<mvc:interceptors>
<mvc:interceptor>
<!-- 拦截/book下的所有请求-->
<mvc:mapping path="/book/*"/>
<!-- 放行/user下的所有请求-->
<mvc:exclude-mapping path="/user/*"/>
<bean class="com.xc.filter.loginInterceptor"/>
</mvc:interceptor>
</mvc:interceptors>
过滤器和拦截器的区别?
过滤器(filter):
1) filter属于Servlet技术,只要是web工程都可以使用
2) filter主要对所有请求过滤
3) filter的执行时机早于Interceptor
拦截器(interceptor)
1) interceptor属于SpringMVC技术,必须要有SpringMVC环境才可以使用
2) interceptor通常对处理器Controller进行拦截
3) interceptor只能拦截dispatcherServlet处理的请求
为什么要使用springboot?
在使用spring开发时,需要配置很多包的依赖(包与包之间可能有冲突)和管理配置文件;springboot可以简化配置,快速搭建、开发和运行spring应用
使用springboot的好处:
- 自动配置
- 提供starter简化Maven配置:使用Spring或者SpringMVC我们需要添加大量的依赖,而这些依赖很多都是固定的,这里Spring Boot 通过starter能够帮助我们简化Maven配置。
- 内嵌tomcat服务器
- 独立运行spring项目:spring Boot可以以jar包的形式来运行
springboot中不同的生产环境
springboot可以支持不同环境的属性配置文件切换,通过创建application- {profile}.properties,环境标识名称可以是:dev(开发环境)、test(测试环境)、prod(生产环境);
使用:spring.profile.active 的值可指定为 {profile} 对应的值。
# 默认为开发环境
spring:
profiles:
active: dev
运行jar包时 指定环境:java -jar xxx.jar --spring.profiles.active=dev
springboot的核心注解
启动类上面的注解:@SpringBootApplication,包含下面的三个注解:
- @SpringBootConfiguration:组合了@Configuration注解,相当于一个配置类
- @EnableAutoConfiguration:打开自动配置的功能
- @ComponentScan:spring组件扫描
如何理解springboot中的Starters
Straters可以理解为启动器,它包含了一系列可以集成到应用里的依赖包。例如代码添加了spring-boot-starter-web,执行maven操作就会下载web应用需要的依赖jar包。开发者通过使用这些Starter可以快速的搭建开发环境,自动加载所需要的依赖和配置参数属性。
其工作原理:
springboot在启动的时候会做以下事情:
- springboot在启动时会去依赖的包中寻找resources/META-INF/spring.factories文件,然后根据文件中所配置的jar包去扫描项目中所依赖的jar包
- 根据spring.factories配置加载AutoConfigure类
- 根据@Conditional注解的条件,进行自动配置并且将Bean注入spring容器(@Conditional注解是可以根据一些自定义的条件动态的选择是否加载该bean到springIOC容器中去)
总结:其实就是springboot容器在启动时候,按照约定先去读取starter的配置信息,再根据配置信息对资源进行初始化,并且注入到spring容器中;这样springboot启动完成后,就已经准备好了一切资源,使用过程直接注入对应的Bean资源即可
mybatis
- mybatis是一个半ORM(对象关系映射)框架,它内部封装了操作数据库的繁琐的过程,方便开发者专注sql开发
- mybatis可以使用xml或注解来配置和映射数据
- mybatis免除了几乎所有的jdbc代码以及设置参数、获取结果集的工作
半自动映射框架,配置java对象与数据库表的对应关系,多表关联关系复杂
优点:
- 基于sql语句编程,很灵活,不会对应用程序或者数据库的现有设计造成任何影响;sql写在xml里,便于统一管理和优化;支持动态sql语句,并且可以重用
- 消除了jdbc大量的冗余代码,不需要手动开关连接
- 很好的与各种数据库兼容(mybatis使用jdbc连接数据库,所以只要jdbc支持的数据库,mybatis也都支持)
- 能够与spring很好的集成
- 解除了sql与程序代码的耦合;sql语句写在xml里
缺点:
- sql语句的编写工作量大,尤其当字段过多、关联表多时
- sql语句依赖于数据库,不能随意更改数据库
mybatis实现步骤
- 创建SqlSessionFactory
- 通过SqlSessionFactory创建SqlSession
- 通过SqlSession执行数据库操作
- 调用commit提交事务
- 调用close关闭
String resource = "mybatis-config.xml";
InputStream inputStream = Resources.getResourceAsStream(resource);
//创建sqlSessionFactory
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
//获取sqlSession实例对象
SqlSession sqlSession = sqlSessionFactory.openSession();
#{}和${}符号的区别
sql预编译:SQL 预编译指的是数据库驱动在发送 SQL 语句和参数给 数据库 之前对 SQL 语句进行编译,这样 数据库 执行 SQL 时,就不需要重新编译。
-
{}是占位符,预编译处理,可以防止sql注入;${}是字符串拼接,没有预编译处理,不能防止sql注入
- mybatis在处理#{}时,会把sql中的#{}替换为?,调用PreparedStatement来赋值;
- 变量替换后,#{}会自动添加单引号;${}不会添加单引号
如:user_id = #{userId},如果传入的值是111,那么解析成sql时的值为user_id = ‘111’
如:user_id = ${userId},如果传入的值是111,那么解析成sql时的值为user_id = 111
-
{}变量替换是在DBMS之中,${}变量替换是在DBMS之外
一个xml映射文件,都会有一个dao(Mapper)接口对应
接口的全限定名就是xml里namespace里的值,接口方法名就是sql语句的id名,,接口方法的参数就是传递给sql的参数;Mapper接口是没有实现类的,方法也不能重载(mybatis规定方法名与sql的id一致【sql的id不能重复】)
dao接口的工作原理是JDK动态代理,mybatis在运行时会调用jdk动态代理为Dao接口生成代理对象,代理对象会拦截接口方法,转而执行方法对应的sql语句,然后将sql执行结果返回
mapper如何传递多个参数
-
{0}代表第一个参数,#{1}代表第二个参数
- 使用@Param注解
User getUser(@Param("name") int name,@Param('password') password);
<select id=”getUser” resultType="User">
select name,password
from some_table
where name = #{name} and password = #{password}
</select>
- 多个参数封装成Map,以HashMap的形式传入到Mapper中
mybatis的动态sql
在mybatis的xml文件中,以标签的形式编写动态sql,执行原理是根据表达式的值完成逻辑判断,并动态拼接sql1功能
9中动态sql标签: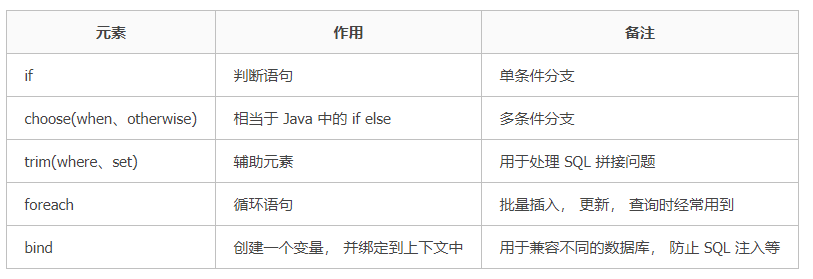
mybatis实现多对一的两种方式
- 联合查询:几个表联合查询,通过在ResultMap里面配置association节点配置,java
- 嵌套查询:先查一个表,根据这个表结果的外键id,再去另一个表里查询数据,也是association
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.xc.dao.StudentMapper">
<!--
Student:
private int id;
private String name;
//多个学生对应一个老师 多对一
private Teacher teacher;
Teacher:
private int id;
private String name;
-->
<!-- 联表查询-->
<select id="getAll" resultMap="StudentTeacher">
select s.id sid,s.name sname,t.name tname,t.id tid
from student s,teacher t
where s.tid=t.id
</select>
<resultMap id="StudentTeacher" type="com.xc.pojo.Student">
<result property="id" column="sid"/>
<result property="name" column="sname"/>
<association property="teacher" javaType="com.xc.pojo.Teacher">
<result property="id" column="tid"/>
<result property="name" column="tname"/>
</association>
</resultMap>
<!--=============================================================-->
<!-- 嵌套查询 1、先查询出所有学生信息-->
<!-- 2、根据查询出来的学生id,寻找对应的老师子查询-->
<select id="getAll" resultMap="StudentTeacher">
select *from student
</select>
<resultMap id="StudentTeacher" type="com.xc.pojo.Student">
<result property="id" column="id"/>
<result property="name" column="name"/>
<!-- 在Student中Teacher属性是对象 -->
<association property="teacher" column="tid" javaType="com.xc.pojo.Teacher"
select="getTeacher"/>
</resultMap>
<select id="getTeacher" resultType="com.xc.pojo.Teacher">
select *from teacher where id=#{id}
</select>
</mapper>
mybatis实现一对多的两种方式
- 联合查询:几个表联合查询,通过在ResultMap里面配置collection节点配置
- 嵌套查询:先查一个表,根据这个表结果的外键id,再去另一个表里查询数据,也是collection
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.xc.dao.TeacherMapper">
<!--
Student:
private int id;
private String name;
private int tid;
Teacher:
private int id;
private String name;
//一个老师对多个学生 一对多
List<Student> students;
-->
<!-- 方法一:联表查询-->
<select id="getTeacher" resultMap="TeacherStudent">
select t.id tid,t.name tname,s.id sid,s.name sname
from teacher t,student s
where s.tid=t.id and t.id=#{tid}
</select>
<resultMap id="TeacherStudent" type="com.xc.pojo.Teacher">
<result property="id" column="tid"/>
<result property="name" column="tname"/>
<collection property="students" ofType="com.xc.pojo.Student">
<result property="id" column="sid"/>
<result property="name" column="sname"/>
<result property="tid" column="tid"/>
</collection>
</resultMap>
<!--=============================================================-->
<!-- 方法二:嵌套查询-->
<select id="getTeacher" resultMap="TeacherStudent">
select *from teacher where id=#{tid}
</select>
<resultMap id="TeacherStudent" type="com.xc.pojo.Teacher">
<result property="id" column="id"/>
<result property="name" column="name"/>
<collection property="students" ofType="com.xc.pojo.Student"
column="id" javaType="ArrayList" select="getStudent"/>
</resultMap>
<select id="getStudent" resultType="com.xc.pojo.Student">
select *from student where tid=#{id}
</select>
</mapper>
mybatis的一级缓存和二级缓存
- mybatis的一级缓存只的是SqlSession(线程独有),作用域时SqlSession,mybatis默认开启一级缓存。在同一个SqlSession中,执行相同的sql查询时,第一次会去查询数据库,并且缓存;第二次会直接从缓存中取。当执行两次查询sql中间发生了增删改的操作,SqlSession的缓存会被清空
每次查询会从缓存中找,如果找不到再去数据库查询,然后把结果写在缓存。mybatis的内部缓存使用了HashMap,
key为:hashcode+statementId+sql语句;value为查询出来的结果集映射成的java对象。
- 二级缓存是mapper级别的(SqlSessionFactory-共享),默认没有开启;第一次调用mapper下的sql去查询信息,查询到的信息会存放到mapper的二级缓存中;第二次调用namespace下的mapper映射文件中,相同的sql查询,会从二级缓存中取
开启二级缓存
mapper的xml配置文件
先查二级缓存,二级缓存没有,再查一级缓存,再没有,直接DB;就是减少对数据库的直接查询,提高效率
不同的xml配置文件,id是否可以相同
mybatis中不同的xml映射文件,如果配置了namespace,那么id可以重复;如果没有配置,那么id不能重复
因为namespace+id是作为Map<String,MappedStatement> 的key使用的,如果没有namespace,就剩下id,id重复父导致数据覆盖
Map<String,MappedStatement>:封装了一个增删改查标签的全部属性,一个标签就是一个MappedStatement,保存在全局配置类中的

 浙公网安备 33010602011771号
浙公网安备 33010602011771号