
概率论与数理统计
基础
频率 =
当n趋向于无穷大的时候,频率 = 概率
条件概率,指在事件A已经发生的概率下,事件B发生的概率,记为,也就是A交B在A里面占的比重
事件的独立性,如果P(B|A) = P(B),说明事件A对事件B的发生没有影响,也就是P(AB) = P(A)P(B),称A、B相互独立
这个独立性就是,说,事件A,B的交集是空
贝叶斯公式
分布函数:称,为变量X的分布函数
性质:
1.,
2.单调不减
3.是右连续的,即
如果满足上述条件,那么他必然是某个随机变量的分布函数
概率密度函数 = 分布函数的导函数,注意概率密度函数的值没有实际的意义
概率密度函数的积分区间 = 某些事件发生的概率
同时
各种分布
0-1分布
E(x) = p
D(x) = p(1 - p)
| X | 0 | 1 |
|---|---|---|
| P | 1 - p | p |
二项分布,X ~ B(n,p)
E(x) = np
D(x) = np(1 - p)
n次相互独立的0-1分布实验 (也叫n重伯努利实验)
X ~ B(12,)
P(X = 2 ) =
Poisson定理,当n很大,p很小时,令
Poisson分布,X ~ P()
E(x) =
D(x) =
P(X = k) =
几何分布,X ~ GE(p)
就是射击命中率为p,射击k次才成功的概率
P(X = k) =
超几何分布
E(x) =
D(x) =
正态分布,X ~ N(,)
E(x) =
一般将正态分布化为标准正态分布,X ~ N(0,1)进行分析
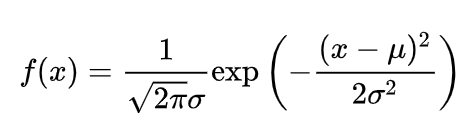
最大值 = ,越小,曲线越陡峭
假设X ~ N(0,1),有
概率密度函数:
分布函数:
标准化:有X ~ N(,)
则分布函数为
注意3原则
二维正态分布
指数分布,X ~
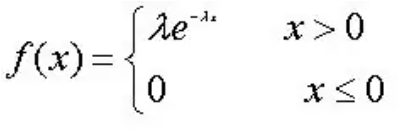
指数分布的无记忆性:
P(X > s + t | X > s) = P(X > t)
均匀分布,X ~ U(a,b)
E(x) =
D(x) =
已知X为连续型随机变量,Y = g(x),且已知X的概率密度为,求Y的概率密度
分布函数法
求随机变量,Y = 的概率密度
, 时
从而Y的概率密度函数为
公式法
由于y = 严格单调可微,其反函数为x = h(y) = ln(y),y > 0,因此Y的概率密度函数为
随机变量的数字特征
期望,加权平均和
期望,E(x^k),这个一定要按积分定义去算,E(x + y) = E(x) + E(y)
y = g(x)的时候,求E(y),相对于把E(x)的积分定义中的x替换为g(x),其他不变
当X,Y相互独立的时候,E(XY) = E(X)E(Y)
方差,随机变量可能取值与其均值的偏离程度
D(X) = = -
D(CX) =
D(X + C) =
如果X、Y相互独立,
协方差,随机变量之间的相关关系
cov(X,Y) = E((X - E(X)) * (Y - E(Y))) = E(XY) - E(X) * E(Y)
cov(X,X) = D(X)
cov(aX + b,cY + d) = accov(X,Y)
cov(X + Y,Z) = cov(X,Z) + cov(Y,Z)
D(X + Y) = D(X) + D(Y) + 2cov(X,Y)
D(X - Y) = D(X) + D(Y) - 2cov(X,Y)
相关系数,刻画变量之间的线性关系
若随机变量X,Y相互独立,且方差均大于0,则
的充要条件差是,存在常数,b,使得P(Y = aX + b) = 1
若A、B是随机事件,
注意相关关系描述的是线性关系的强弱,而独立关系是更强的关系
可能不相关,但不独立、
本文来自博客园,作者:XDU18清欢,转载请注明原文链接:https://www.cnblogs.com/XDU-mzb/p/16401092.html


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律