【论文笔记+复现踩坑】End-to-end Recovery of Human Shape and Pose(CVPR 2018)
PS. 这里做的论文笔记主要是为自己方便回顾。

概述
做了什么:引入一个端到端的Human Mesh Recovery框架,从包含人体的RGB位图中重建出一个SMPL的3D网格,并尝试重新投影回图片上
目的:最小化关键点的重投影损失,使得我们可以使用只带2D准确标注的户外场景图像就能进行训练
难点:
- 缺乏自然场景下的大规模ground truth的3D数据集
- 单视角下2D到3D映射所固有的模糊性(缺乏深度信息),可能会导致产生的模型异常,如自相交、异常的人体姿势等情况
- 预测相机视角又会在人体大小和摄像机的距离建引入额外的scale ambiguity
- 旋转的回归问题
关键点:
- 在从图片推断出3D人体模型后,将它重投影到2D图片上计算2D损失
- 引入生成对抗网络(GANs),通过训练鉴别器来推断生成的3D人体模型是否为真人,且形体姿势是否合理(需要3D训练集)(鉴别器能够学到3D关节角度的限制)
- 由于欧拉角旋转表示法存在多对一的映射,转换成旋转矩阵可以保证其唯一性
优点:
- 直接从图像推断出SMPL参数
- 可以直接生成网格
- 方法是端到端的
- 可以不需要使用配对的2D-3D数据集,并且不依赖中间2D关键点侦测
- 运行效率可以达到实时级别(1080Ti在部件分割任务上用时0.04sec)
现有的一些从2D图片恢复人体3D网格的方法专注于恢复人体3D关节点的坐标位置。但问题在于:
- 关节点是离散的,但人体在3D空间的表示是密集连续的
- 3D关节点位置本身并不能约束每个关键点之间的关系,仅通过这些位置并不能很好的预测人体姿势和体型
论文的做法:
- 为kinematic tree中的每个3D关键点输出相对的3D旋转矩阵,来捕获3D的头部和肢体角度方向。预测角度还可以确定肢体的对称性和肢体长度等信息的合理性
- 该模型从3D人体模型数据集中能够学习到3D关节角度的限制
论文具体做法
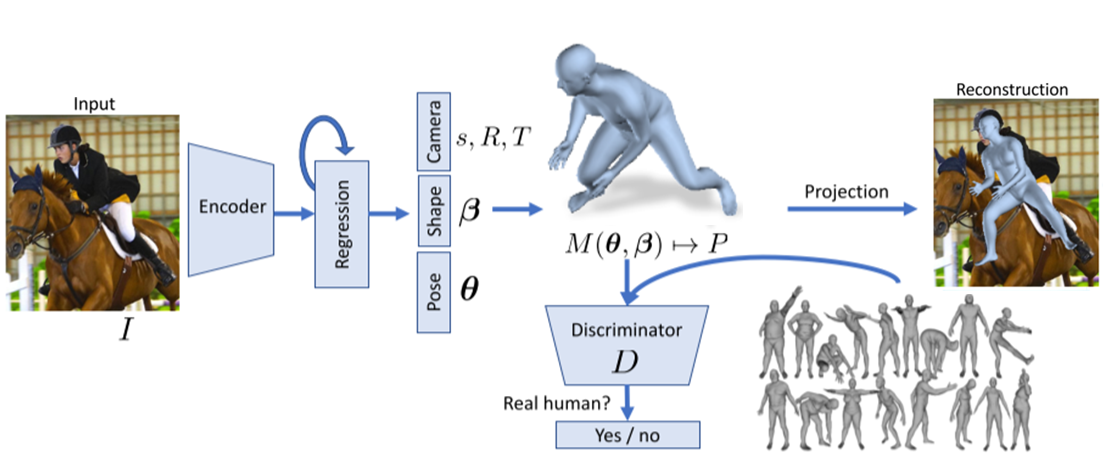
数据集输入:带2D关节点Ground Truth的图像数据
Encoder
使用ResNet-50网络对图像进行编码
- Input:224x224 RGB图像
- Output:经过平均池化后的特征\(\phi\in\mathbf{R}^{2048}\)
3D Regression
-
Input:concat后的\([\phi, \Theta_t]\),初始的\(\Theta_0\)源自
neutral_smpl_mean_param.h5 -
Layer 1:
Linear(2048 + 85, 1024), ReLU(), Dropout(0.5) -
Layer 2:
Linear(1024, 1024), ReLU(), Dropout(0.5) -
Layer 3:
Linear(1024, 85) -
Output:\(\Delta\Theta_t\)
Iterative error feedback(IEF):计算出残差\(\Delta\Theta_t\)后进行加法更新:\(\Theta_{t+1}=\Theta_{t} + \Delta\Theta_t\)
其中\(\Theta=\{\mathbf{\theta}, \mathbf{\beta}, R, t, s\}, \mathbf{\theta}\in\mathbf{R}^{3K}, \mathbf{\beta}\in\mathbf{R}^{10},R\in\mathbf{R}^{3},t\in\mathbf{R}^{2},s\in\mathbf{R}\).K=23,θ为SMPL关节点的轴角,β控制SMPL体型,R为全局轴角,t为摄像机xy平面的平移量,s为摄像机的缩放量
\(M(\mathbf{\theta}, \mathbf{\beta})\):代表SMPL模型的N=69803D顶点
\(X(\mathbf{\theta}, \mathbf{\beta})\):代表SMPL模型的23个3D关节点
对3D关节点的投影:\(\hat{\mathbf{x}}=s\Pi(RX(\mathbf{\theta}, \mathbf{\beta})) + t\),\(\Pi\)为正交投影
损失函数:
如果有3D ground truth,则对应的annotation为\([\mathbf{\beta}, \mathbf{\theta}]\)。网络输出则为\([\hat{\mathbf{\beta}}, \hat{\mathbf{\theta}}]\)
- 2D Loss:\(L_{reproj}=\sum_i\parallel v_i(\mathbf{x}_i - \hat{\mathbf{x}}_i)\parallel_{1}\),\(v_i\)为2D关节点i的可视性(1可见,0不可见)
- 3D SMPL Loss:\(L_{smpl}=\parallel[\mathbf{\beta_i}, \mathbf{\theta_i}] - [\hat{\mathbf{\beta_i}}, \hat{\mathbf{\theta_i}}]\parallel_2^2\)
- 3D Joint Loss:\(L_{joints}=\parallel(\mathbf{X}_i - \hat{\mathbf{X}}_i)\parallel_2^2\)
- 3D Loss:\(L_{3D}=L_{smpl}+L_{joints}\)
Discriminator
- Input:\(\beta, \theta\)
Shape Discriminator:
- Layer 1:
Linear(10, 5), ReLU() - Layer 2:
Linear(5, 1)
Pose Discriminator(C=9是因为轴角变成旋转矩阵):
-
Input:
NHWC = [N, 23, 1, 9] -
Layer 1:
Conv2d(out_c=32, k=1x1), ReLU() -
Layer 2:
Conv2d(out_c=32, k=1x1), ReLU()For pose respectively(K):
- Layer 3:
[N, 1, 1, 32]---Fully Connected--->Linear(32, 1)--->[N, 1]
For all pose(1):
- Layer 3:
[N, 23, 1, 32]=FC1024, ReLU() =>[N, 1024] - Layer 4:
FC1024, ReLU() - Layer 5:
FC1
- Layer 3:
Total:K+2 Discriminator
损失函数:
- Adversarial Loss for the encoder:\(min L_{adv}(E)=\sum_i\mathbf{E_{\Theta\sim p_E}[(D_i(E(I))-1)^2]}\)
- Objective for each discriminator:\(min L(D_i)=\sum_{i}\mathbf{E_{\Theta\sim p_{data}}}[(D_i(\Theta)-1)^2] + \mathbf{E_{\Theta\sim p_E}}[D_i(E(I))^2]\)
- Objective for encoder:\(L=\lambda(L_{reproj}+\mathbf{1}\ L_{3D})+L_{adv}\),这里1代表是否有ground truth 3D数据
实验
评价指标:
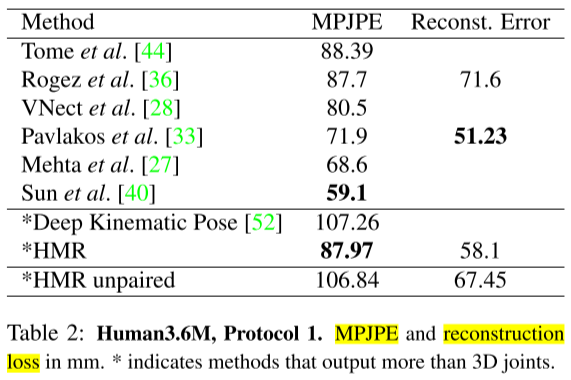
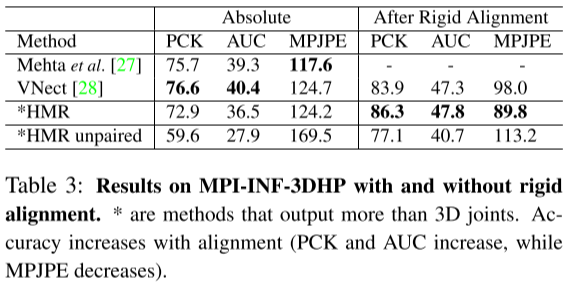
- Reconstruction: mean per joint position error(MPJPE) 、 Reconstruction error、PCK、AUC
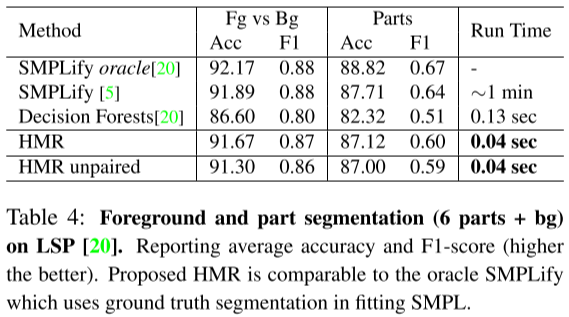
- Part segmentation: Acc、F1-score
测试数据集:Human3.6M,MPI-INF-3DHP
实验方法:
- T1、T2:对Human3.6M用不同方法评估Reconst. Error
- T3:对MPI-INF-3DHP,控制刚体对齐
- T4:部件分割
- Fig:对比使用/不使用配对的2D-to-3D监督


复现Demo踩坑
踩这个项目的坑踩了我好久,这里把环境配置的过程简单整理下。
复现主要环境:
- Linux Ubuntu 18.04
- Anaconda3
- Python2.7
先按顺序安装下面这些包:
| 包 | 版本 | 安装源 |
|---|---|---|
| cudatoolkit | 9.0 | conda |
| cudnn | 7.6.5 | conda |
| numpy | 1.14.0 | pip |
| tensorflow-gpu | 1.12.0 | pip |
numpy的版本不要太新,不然后续编译使用opencv2可能会带来一系列麻烦。
tensorflow-gpu使用的是项目推荐的版本
然后用下面的代码测试即可,得到True为成功:
import tensorflow as tf
print(tf.test.is_gpu_available())
编译安装opencv2
为了使用cmake编译opencv2,这里需要先安装一些东西:
$ sudo apt-get install build-essential
$ sudo apt-get install cmake
$ sudo apt-get install pkg-config
因为我们用的是python2.7,pip提供的opencv-python主要都是给python3.x用的,为此我们需要自己编译一个。
这里我选择的是opencv-2.4.13.6的版本:https://gitee.com/dhfhub/opencv/tree/2.4.13.6/
下载zip后解压,终端跳到目录opencv-2.4.13.6内,新建文件夹并进入,运行cmake。注意一定要是在hmr的虚拟环境下进行:
$ mkdir build
$ cd build
$ cmake -D CMAKE_BUILD_TYPE=RELEASE -D CMAKE_INSTALL_PREFIX=/usr/local ../opencv
生成完毕后,开始安装:
$ sudo make install
安装完毕后运行python测试opencv2,此时应该没有问题:
$ python
>>> import cv2
安装剩余包
为了编译安装opendr,需要先运行下面命令安装:
$ sudo apt install libosmesa6-dev
$ sudo apt-get install build-essential
$ sudo apt-get install libgl1-mesa-dev
$ sudo apt-get install libglu1-mesa-dev
$ sudo apt-get install freeglut3-dev
最后根据hmr项目里的requirements.txt来完成剩余安装:
| 包 | 版本 | 安装源 |
|---|---|---|
| scipy | 1.2.3(默认最新) | pip |
| opendr | 0.78(默认最新,不能是0.77) | pip |
| matplotlib | 2.2.5(默认最新) | pip |
| scikit-image | 0.14.5(默认最新) | pip |
| deepdish | 0.3.6(默认最新) | pip |
| absl-py | 0.10.0(默认最新) | pip |
| ipdb | 0.13.4(默认最新) | pip |
| tensorflow-estimator | 1.10.12(降级避免出现ts.estimator找不到问题) | pip |
尝试运行
回到hmr项目的目录,执行:
$ wget https://people.eecs.berkeley.edu/~kanazawa/cachedir/hmr/models.tar.gz && tar -xf models.tar.gz
获取模型文件后解压到hmr文件夹内,得到models的文件夹
然后尝试执行:
$ python -m demo --img_path data/coco1.png
此时可能还有一个报错:
TypeError: load() got an unexpected keyword argument 'encoding'
python-BaseException
Process finished with exit code 1
找到src/tf_smpl/batch_smpl.py,将dd = pickle.load(f, encoding="latin-1")里的encoding部分删掉,然后再尝试再次执行。这时候应该能跑出结果了。
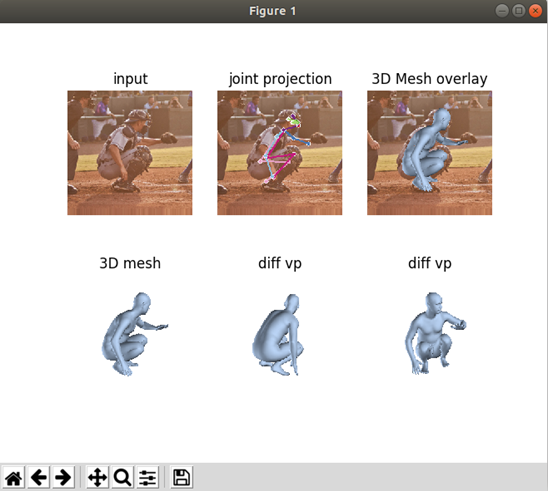
执行:
$ python -m demo --img_path data/im1954.jpg


 浙公网安备 33010602011771号
浙公网安备 33010602011771号