编译原理--02 自顶向下、自底向上的LR分析复习(清华大学出版社第3版)
前言
| 目录 |
|---|
| 01 文法和语言、词法分析复习 |
| 02 自顶向下、自底向上的LR分析复习 |
| 03 语法制导翻译和中间代码生成复习 |
| 04 符号表、运行时存储组织和代码优化复习 |
| 05 用C++手撕PL/0 |
第4章 自顶向下的语法分析方法
确定的自顶向下分析思想
开始符号集或首符号集:设\(G=(V_T,V_N,P,S)\)是上下文无关文法。
\(FIRST(\alpha)=\{a \mid\alpha \stackrel{*}{\Rightarrow} a\beta, a\in V_T, \alpha,\beta\in V^*\}\)
若\(\alpha \stackrel{*}{\Rightarrow} \varepsilon\),则规定\(\varepsilon \in FIRST(\alpha)\),称\(\varepsilon \in FIRST(\alpha)\)为\(\alpha\)的开始符号集或首符号集
简单来说,就是查看该句型推导出的所有句子的首字母集合。
例如文法\(G[S]:\)
\(S\rightarrow Ap\)
\(S\rightarrow Bq\)
\(A\rightarrow aA\)
\(A\rightarrow \varepsilon\)
\(B\rightarrow Bb\)
\(B\rightarrow b\)
那么\(FIRST(S)=\{a,b,p\}\),\(FIRST(A)=\{a,\varepsilon\}\),\(FIRST(B)=\{b\}\)
FOLLOW集:设\(G=(V_T,V_N,P,S)\)是上下文无关文法,\(A\in V_N\),S是开始符号
\(FOLLOW(A)=\{a\mid S\stackrel{*}{\Rightarrow}\mu A\beta且a\in V_T,a\in FIRST(\beta), \mu\in {V_T}^*, \beta\in V^+\)
若\(S \stackrel{*}{\Rightarrow}\mu A\beta\),且\(\beta \stackrel{*}{\Rightarrow}\varepsilon\),则 \(\# \in FOLLOW(A)\)
简单来说,就是查看该句型在被推导前后面跟随的所有可能的第一个字母的集合。
例如之前的文法\(G[S]\),\(FOLLOW(S)=\{\#\}\),\(FOLLOW(A)=\{p\}\),\(FOLLOW(B)=\{b,q\}\)
选择符号集:一个产生式的选择符号集SELECT。给定上下文无关文法的产生式\(A\rightarrow \alpha, A\in V_N, \alpha\in V^*\),若\(\alpha\stackrel{*}{\nRightarrow}\varepsilon\),则\(SELECT(A\rightarrow\alpha)=FIRST(\alpha)\)
而如果\(\alpha\stackrel{*}{\Rightarrow}\varepsilon\),则\(SELECT(A\rightarrow\alpha)=(FIRST(\alpha)-\{\epsilon\})\cup FOLLOW(A)\)。
求出选择符号集,是为了找到哪些符号应该使用该推导。那么,如果\(A\rightarrow \alpha\)不能推出空串,显然 从该推导得到的所有句子的首字母构成的集合 来反向看出 哪些字母应该使用该推导。而如果\(A\rightarrow \alpha\)能推出空串,则还要考虑该非终结符的后跟字符。
一个上下文无关文法是LL(1)文法的充要条件,是对每个非终结符A的两个不同产生式,\(A\rightarrow\alpha, A\rightarrow\beta\),满足
例如文法\(G[S]:\)
\(S\rightarrow aA\)
\(S\rightarrow d\)
\(A\rightarrow bAS\)
\(A\rightarrow \varepsilon\)
有:
\(SELECT(S\rightarrow aA)=\{a\}\)
\(SELECT(S\rightarrow d)=\{d\}\)
\(SELECT(A\rightarrow bAS)=\{b\}\)
\(SELECT(A\rightarrow \varepsilon)=\{a,d,\#\}\)
所以:
\(SELECT(S\rightarrow aA)\cap SELECT(S\rightarrow d)=\{a\}\cap\{d\}=\emptyset\)
\(SELECT(A\rightarrow bAS)\cap SELECT(A\rightarrow \varepsilon)=\{b\}\cap\{a,d,\#\}=\emptyset\)
LL(1)文法的判别
LL(1)的含义:第1个L 表明 从左向右扫描输入串,第2个L 表明 分析过程中将使用最左推导,1表明只需向右看一个符号就知道该选择哪个产生式推导。
- 找出能推出\(\varepsilon\)的非终结符
- 计算FIRST集
- 计算FOLLOR集
- 计算SELECT集
- 进行判断
某些非LL(1)文法到LL(1)文法的等价变换
LL(1)文法的充分条件为不含左公共因子
提取左公共因子
例如\(A\rightarrow \alpha\beta\mid \alpha\gamma\),可以写成:
\(A\rightarrow \alpha B\)
\(B\rightarrow \beta\)
\(B\rightarrow \gamma\)
一般情况如\(A\rightarrow \alpha_1\alpha_2...\alpha_n(\beta_1\mid\beta_2\mid...\mid\beta_n)\),可以写成:
\(A\rightarrow\alpha_1 A_1\)
\(A_1\rightarrow\alpha_2 A_2\)
\(...\)
\(A_{n-1}\rightarrow\alpha_n B\)
\(B\rightarrow\beta_1\)
\(B\rightarrow\beta_2\)
\(...\)
\(B\rightarrow\beta_n\)
此外,还需要检查文法是否含有隐式的左公共因子,如:
\((1)A\rightarrow ad\)
\((2)A\rightarrow Bc\)
\((3)B\rightarrow aA\)
将(3)带入(2),可暴露出左公共因子:
\((1)A\rightarrow ad\)
\((2)A\rightarrow aAc\)
\((3)B\rightarrow aA\)
可以看到此时(3)为多余规则,可以删去,最后整理得到:
\((1)A\rightarrow aB\)
\((2)B\rightarrow Ac\)
\((2)B\rightarrow d\)
改写后的文法不含空产生式,且无左递归时,则改写后的文法是LL(1)文法
若还有空产生式,则还需要用LL(1)文法的判别方式进行判断
消除左递归
对于包含直接左递归的文法,如\(G[A]:A\rightarrow Ab,A\rightarrow c, A\rightarrow d\)
可以直接改写成右递归:\(A\rightarrow cA', A\rightarrow dA', A'\rightarrow bA',A'\rightarrow \varepsilon\)
一般情况下,如\(A\rightarrow A(\beta_1\mid\beta_2\mid...\mid\beta_n), A\rightarrow \alpha_1\mid\alpha_2\mid...\mid\alpha_n\),分为了包含左递归和不含左递归的两部分,可以变形为:
\(A\rightarrow \alpha_1 A'\)
\(A\rightarrow \alpha_2 A'\)
\(...\)
\(A\rightarrow \alpha_n A'\)
\(A'\rightarrow \beta_1 A'\)
\(A'\rightarrow \beta_2 A'\)
\(...\)
\(A'\rightarrow \beta_n A'\)
对于包含间接左递归的文法,如\(G[S]:\)
\((1)A\rightarrow aB\)
\((2)A\rightarrow Bb\)
\((3)B\rightarrow Ac\)
\((4)B\rightarrow d\)
可以考虑把(1)和(2)带入(3):
\((1)B\rightarrow aBc\)
\((2)B\rightarrow Bbc\)
\((3)B\rightarrow d\)
不会引起左递归的式子为(1)和(3),故可以写成:
\((1)B\rightarrow aBcB'\)
\((2)B\rightarrow dB'\)
\((3)B'\rightarrow bcB'\)
\((4)B'\rightarrow \varepsilon\)
消除一切左递归

LL(1)文法的实现
程序实现
- 求出文法G[S]各个产生式的SELECT集合
- 然后根据集合内的符号来选择所属产生式
写程序时,用getsym来读入下一个符号,如果有不合法的符号,应当有错误处理。
如文法\(L(G[A]): A\rightarrow aBd \mid b, B\rightarrow\varepsilon\mid c\)
\(SELECT(A\rightarrow aBd)=\{a\}\)
\(SELECT(A\rightarrow b)=\{b\}\)
\(SELECT(B\rightarrow \varepsilon)=\{d\}\)
\(SELECT(B\rightarrow c)=\{c\}\)
void PraseA()
{
if (sym == 'a')
{
getsym();
PraseB();
if (sym == 'd')
getsym();
}
else if (sym == 'b')
{
getsym();
}
else
{
error();
}
}
void PraseB()
{
if (sym == 'c')
{
getsym();
}
else if (sym == 'd')
{
}
else
{
error();
}
}
预测分析表
求出所有规则的SELECT集后,根据集合填入预测分析表。如上面的文法:
| a | b | c | d | # | |
|---|---|---|---|---|---|
| A | \(\rightarrow aBd\) | \(\rightarrow b\) | |||
| B | \(\rightarrow c\) | \(\rightarrow \varepsilon\) |
下表是对对\(acd\)的分析过程:
| 步骤 | 分析栈 | 剩余输入串 | 推导所用产生式或匹配 |
|---|---|---|---|
| 1 | #A | acd# | A→aBd |
| 2 | #dBa | acd# | a匹配 |
| 3 | #dB | cd# | B→c |
| 4 | #dc | cd# | c匹配 |
| 5 | #d | d# | d匹配 |
| 6 | # | # | 接受 |
一开始把起始非终结符放入分析栈,然后会有2种情况:
- 若分析栈栈顶为非终结符,根据剩余输入串的首字符以及预测分析表来选择产生式。如果找到合适的产生式,此时需要把分析栈栈顶的非终结符弹出,然后根据产生式右边的句型从右往左依次入栈。如果没找到,则出现异常。
- 若分析栈栈顶为终结符,此时如果和剩余输入串的首字符相匹配,则弹出分析栈栈顶终结符,并查看输入串的下一个字符。如果不匹配,则出现异常。
这一章的可能考点
- 判别文法是否为LL(1)
- 已知LL(1)文法,构造预测分析表
- 给定LL(1)文法和输入串,写出分析过程表
第5章 自底向上的移进-归约分析
自底向上的移进-规约分析要求对输入符号串自左向右扫描,按句柄进行归约。
移进:将输入串的下一个字符移入符号栈
归约:符号栈中的顶部几个符号如果能匹配某条推导式的右边,则用该推导式的左边替换
自底向上的移进-归约法是每次对最左边的内容进行归约,它的逆过程为自顶向下的规范(最右)推导。
设文法 \(G[S]\) 为
\(S\rightarrow aAcBe\)
\(A\rightarrow b\)
\(A\rightarrow Ab\)
\(B\rightarrow d\)
对输入串\(abbcde\)使用自顶向下的最右推导:
对应的,我们可以得到它的逆过程,即规约过程。
| 步骤 | 符号栈 | 输入符号串 | ----------动作---------- |
|---|---|---|---|
| (1) | # | abbcde# | 移进 |
| (2) | #a | bbcde# | 移进 |
| (3) | #ab | bcde# | 归约\((A\rightarrow b)\) |
| (4) | #aA | bcde# | 移进 |
| (5) | #aAb | cde# | 归约\((A\rightarrow Ab)\) |
| (6) | #aA | cde# | 移进 |
| (7) | #aAc | de# | 移进 |
| (8) | #aAcd | e# | 归约\((B\rightarrow d)\) |
| (9) | #aAcB | e# | 移进 |
| (10) | #aAcBe | # | 归约\((S\rightarrow aAcBe)\) |
| (11) | #S | # | 接受(acc) |
第6章 LR分析
LR(K)分析使用自底向上分析法,从左到右扫描符号,只需要根据分析栈中的符号栈和向右顺序查看输入串的K(K>=0)个符号来确定分析器接下来是移进还是规约,因而也能唯一地确定句柄。
LR分析器
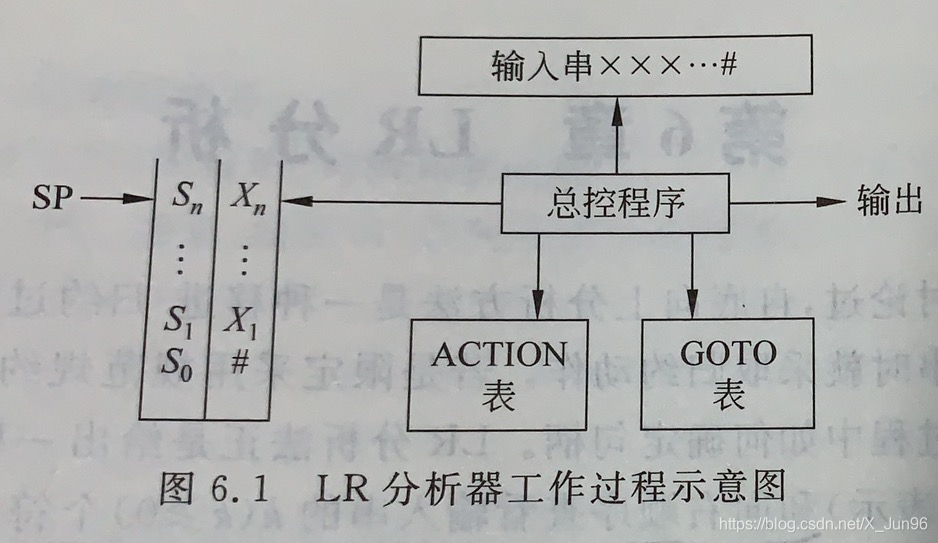
总控程序负责LR分析过程
分析栈分为状态栈和文法符号栈。它们均是后进先出。
分析表分为动作(ACTION)表和状态转换(GOTO)表两个部分。
SP为栈指针,指向状态栈和文法符号栈,即状态栈和符号栈元素数目始终保持一致。
状态转换表内容按关系\(GOTO[S_i, X]=S_j\)确定,即当栈顶状态为\(S_i\)遇到栈顶符号\(X\)时应当转向状态\(S_j\)
动作表按\(ACTION[S_i,a]\)确定了栈顶状态为\(S_i\)时遇到输入符号\(a\)应执行的动作。
动作按优先程度排列:
规约:如果栈顶形成了句柄\(\beta\)(它的长度为\(r\)),且有原来的推导\(A\rightarrow\beta\)来进行规约,则从状态栈和文法符号栈中自顶向下去掉\(r\)个符号,即对SP减去\(r\)。接着把A移入文法符号栈内,再根据此时修改SP后的栈顶状态,把满足\(S_j=GOTO[S_i, A]\)的状态移进状态栈。
移进:如果栈顶没有形成句柄,且\(S_j=GOTO[S_i,a]\)成立,则把\(S_j\)移入到状态栈,把\(a\)移入到文法符号栈。其中\(i\)和\(j\)表示状态号。
接受acc:当归约到文法符号栈中只剩下文法的开始符号S,并且输入符号串只剩下#(表示已经结束),则为分析成功。
报错:如果状态栈顶的当前状态遇到了不该出现的文法符号时则报错,说明输入串不是该文法能接受的句子。
LR(0)分析
已知文法\(G[S]:\)
\((1)S\rightarrow aAcBe\)
\((2)A\rightarrow b\)
\((3)A\rightarrow Ab\)
\((4)B\rightarrow d\)
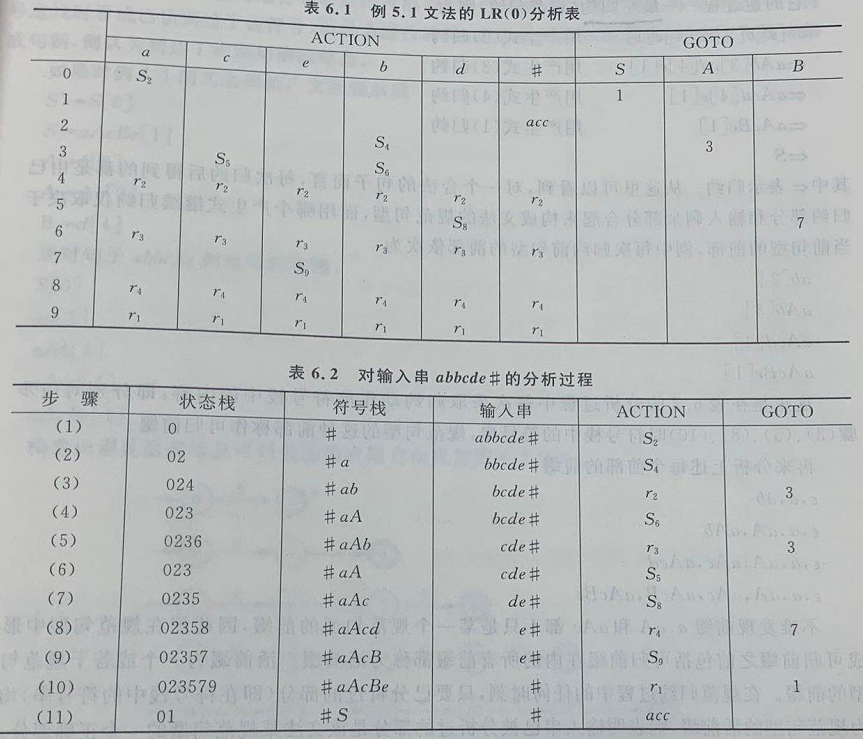
对输入串\(abbcde\#\)用自底向上归约的方法来分析,由于到第5步栈中的符号串为\(\#aAb\),此时状态栈的栈顶状态\(0236\)决定了应该用(3)式而不是(2)式来归约。
分析表和分析过程如下:
可归前缀和活前缀
为了更清楚地表示最右推导与最左归约的关系,可以在推导过程中加入一些附加信息。对上面的文法用\([i]\)编号:
\(S\rightarrow aAcBe[1]\)
\(A\rightarrow b[2]\)
\(A\rightarrow Ab[3]\)
\(B\rightarrow d[4]\)
对输入串abbcde进行最右推导,把序号也带入:
\(S\Rightarrow aAcBe[1]\Rightarrow aAcd[4]e[1]\Rightarrow aAb[3]cd[4]e[1]\Rightarrow ab[2]b[3]cd[4]e[1]\)
对应的逆过程——最左归约(规范归约,即从左到右归约)为:
\(ab[2]b[3]cd[4]e[1]\) 用产生式(2)归约
\(\Leftarrow aAb[3]cd[4]e[1]\) 用产生式(3)归约
\(\Leftarrow aAcd[4]e[1]\) 用产生式(4)归约
\(\Leftarrow aAcBe[1]\) 用产生式(1)归约
\(S\)
这里用\(\Leftarrow\)表示归约。
每次归约前,句型的前部依次为:
\(ab[2]\),它的前缀为\(\varepsilon, a, ab\)
\(aAb[3]\),它的前缀为\(\varepsilon, a, aA, aAb\)
\(aAcd[4]\),它的前缀为\(\varepsilon, a, aA, aAc, aAcd\)
\(aAcBe[1]\),它的前缀为\(\varepsilon, a, aA, aAc, aAcB, aAcBe\)
这些规范句型的前部我们称之为可归前缀。而a, aA, aAc等这些出现在一个或多个可归前缀的部分,可称之为活前缀,它的长度不能超过当前句型句柄的末端。
拓广文法是指对原文法G增加产生式\(S'\rightarrow S\),其中\(S\)为原文法G的开始符号。这样确保新的开始符号\(S'\)只会在推导式的左边出现(而\(S\)不一定)
使用拓广文法可以将上面的文法表示成:
\(S'\rightarrow S[0]\)
\(S\rightarrow aAcBe[1]\)
\(A\rightarrow b[2]\)
\(A\rightarrow Ab[3]\)
\(B\rightarrow d[4]\)
对句子\(abbcde\)列出可归前缀:
\(S[0]\)
\(ab[2]\)
\(aAb[3]\)
\(aAcd[4]\)
\(aAcBe[1]\)
活前缀及可归前缀的一般计算方法
重要!!!这部分可以不需要看,因为我们可以直接通过构造识别活前缀的DFA来反向求出活前缀以及可归前缀。
设\(G=(V_N, V_T, P, S)\)是一个上下文无关文法,对于\(A\in V_N\),有
其中S'是G的拓广文法G'的开始符号
\(LC(A)\)表明了在规范推导(最右推导)中在非终结符A左边出现的符号串集合。
推论:若文法G中有产生式\(B\rightarrow \gamma A\delta\),则有
因为对任一形为\(\alpha B\omega\)的句型,必然有规范推导:
因此对任一\(\alpha \in LC(B)\),必有\(\alpha \gamma \in LC(A)\),即\(LC(B) \cdot\{\gamma\} \subseteq LC(A)\)
对于文法\(G[S]\):
\(S'\rightarrow S\)
\(S\rightarrow aAcBe\)
\(A\rightarrow b\)
\(A\rightarrow Ab\)
\(B\rightarrow d\)
需列出方程组求解(此处为正规式):
用正规式表示求解结果:
规定\(LR(0)C(A\rightarrow\beta)=LC(A)\cdot\beta\),这样包含句柄的活前缀有:
包含句柄的活前缀也就是可归前缀,将它们展开也就得到了所有的活前缀
对于递归型:
一直展开可以看到:
\(LC(A)\)
\(= a\mid LC(A)\cdot c\)
\(=a\mid (a\mid LC(A)\cdot c)\cdot c\)
\(=a\mid ac\mid LC(A)\cdot cc\)
\(=a\mid ac\mid acc\mid LC(A)\cdot ccc\)
\(=...\)
故\(LC(A)=ac^*\)
LR(0)项目规范族的构造
1. LR(0)项目
在文法G'中为每个产生式的右部的适当位置添加一个圆点构成项目
例如\(A\rightarrow Ab\)有3个项目:
\([0] A\rightarrow \cdot Ab\)
\([1] A\rightarrow A\cdot b\)
\([2] A\rightarrow Ab\cdot\)
而空产生式\(A\rightarrow\varepsilon\)只有一个项目\(A\rightarrow\cdot\)。
\(\cdot\)左边的符号表示已经被扫描过的部分,右边如果还有符号,则它的第一个符号则是下一个将会被扫描的符号。

2. 构造识别活前缀的NFA
列出所有项目后,这些项目标上编号用于构造NFA,确定\(S'\rightarrow \cdot S\)为初态,有2种情况:
- 即将从\(S'\rightarrow \cdot S\)过渡到\(S\rightarrow \cdot aA\)。这两个项目用\(\rightarrow\)连接,并在上面标记\(\varepsilon\)
- 即将从\(S\rightarrow\cdot aA\)过渡到\(S\rightarrow a\cdot A\)。这两个项目用\(\rightarrow\)连接,并在上面标记\(a\)
根据圆点所在位置和圆点后的符号状况,可以分为4类:
- 移进项目,形如\(A\rightarrow a\cdot aB\),圆点后面是终结符
- 待约项目,形如\(A\rightarrow aa\cdot B\),圆点后面是非终结符,需要移进完非终结符内的所有符号才能归约符号B
- 归约项目,形如\(A\rightarrow aaB\cdot\),圆点后面没有符号,此时可以进行归约
- 接受项目,形如\(S'\rightarrow A\),S'是所有产生式唯一的左部
3. LR(0)项目集规范族的构造
从NFA构造成DFA的关键点仅在于,使用闭包函数,将当前项目(它前面不是由\(\varepsilon\)推出)以及后面用\(\varepsilon\)弧连接的所有项目,构成一个新的项目集。
但一个项目集中不能同时存在:
- 移进项目和归约项目,形如\(A\rightarrow a\cdot a\beta\)和\(B\rightarrow \gamma\cdot\)
- 归约项目和归约项目,形如和\(A\rightarrow \beta\cdot\)和\(B\rightarrow \gamma\cdot\)
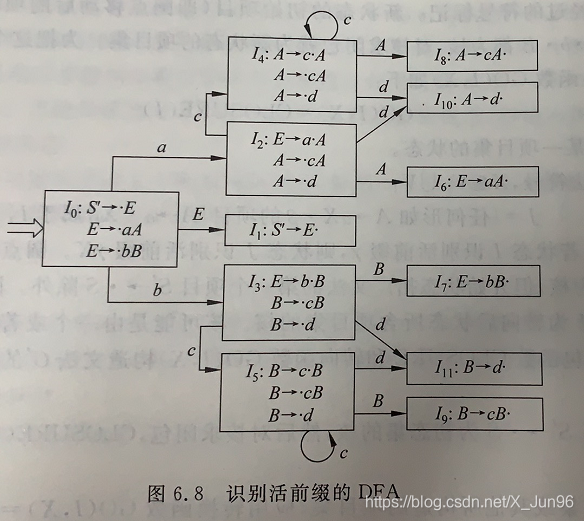
重点来了!从\(I_0\)项目集到最终要进行归约的式子(即圆点在式子最后)的路径扫过的符号顺序就是这条推导式的活前缀!
比如从上图就可以看出:
\(E\rightarrow bB\)的可归前缀为\(bB\)
\(A\rightarrow cA\)的可归前缀为\(acc^*A\)
4. LR(0)分析表的构造
现有LR(0)项目集规范族:
\(I_k\)为项目集的名,k为状态名,令包含\(S'\rightarrow \cdot S\)项目的集合\(I_k\)的下标k作为分析器的初始状态。分析表的ACTION表和GOTO表构造步骤如下:
- 若项目\(A\rightarrow \alpha\cdot a\beta\)属于\(I_k\),且\(I_k\stackrel{a}{\rightarrow}I_j\),则置\(ACTION[k,a]=S_j\)
- 若项目\(A\rightarrow \alpha\cdot\)属于\(I_k\),则对任何终结符和#号都置\(ACTION[k,*]=r_j\)
- 若\(I_k\stackrel{A}{\rightarrow}I_j\),则置\(GOTO[k,A]=j\)
- 若项目\(S'\rightarrow S\)属于\(I_k\),则置\(ACTION[k,\#]=acc\),表示接受
SLR(1)分析
假定一个LR(0)规范族中含有如下的项目集(举例):
也就是该项目集中出现了移进—归约冲突和归约—归约冲突。
根据LR(0)分析,此时无法确定是移进,还是归约,即产生了冲突。但我们可以向前查看一个符号(即查看当前剩余输入串最前面一个符号),来确定接下来的动作,这就是SLR(1)分析。
对于上面的例子,要求三个项目中 \(·\) 后面的符号各不相同,即要求它们的FOLLOR集互不相交:
\(FOLLOW(A)\cap\{b\}=\emptyset\)
\(FOLLOW(B)\cap\{b\}=\emptyset\)
\(FOLLOW(A)\cap FOLLOW(B)=\emptyset\)
即说明在状态5时,如果面临某输入符号为\(a\),则可以按以下规定决策:
- 若\(a=b\),则移进
- 若\(a\in FOLLOW(A)\),则用产生式\(A\rightarrow \gamma\)归约
- 若\(b\in FOLLOW(B)\),则用产生式\(B\rightarrow \delta\)归约
- 此外,则报错
接下来是分析表的修改,比如说产生式2为\(A\rightarrow \gamma\),产生式3为\(B\rightarrow \delta\),\(FOLLOW(A)=c\),\(FOLLOW(B)=d\),原本LR(0)时候分析表对应:
| 状态 | --- a --- | --- b --- | --- c --- | --- d --- | --- # --- |
|---|---|---|---|---|---|
| 5 | \(r_2,r_3\) | \(r_2,r_3,S_6\) | \(r_2,r_3\) | \(r_2,r_3\) | \(r_2,r_3\) |
可见冲突非常严重,经过修改后,变成了:
| 状态 | a | b | c | d | # |
|---|---|---|---|---|---|
| 5 | \(S_6\) | \(r_2\) | \(r_3\) |
此时的分析表满足SLR(1)分析。
LR(1)分析
现有一文法\(G'\):
\((1)S'\rightarrow S\)
\((2)S\rightarrow aAd\)
\((3)S\rightarrow bAc\)
\((4)S\rightarrow aec\)
\((5)S\rightarrow bed\)
\((6)A\rightarrow e\)
它的识别活前缀的DFA如下:
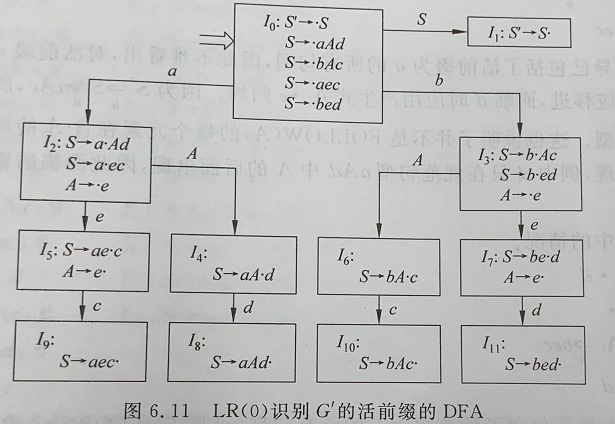
留意到\(I_5\)中存在移进—归约冲突,\(FOLLOW(A)\cap\{c\}=\{c,d\}\cap\{c\}=\{c\}\)
以及\(I_7\)中存在移进—归约冲突,\(FOLLOW(A)\cap\{d\}=\{c,d\}\cap\{d\}=\{d\}\)
它们的交集都不为空,不满足SLR(1)文法,需要考虑使用LR(1)文法。
在\(I_5\)中,由于
\(S'\mathop{\Rightarrow}\limits_{R}S\mathop{\Rightarrow}\limits_{R}aAd\mathop{\Rightarrow}\limits_{R}aed\)
\(S'\mathop{\Rightarrow}\limits_{R}S\mathop{\Rightarrow}\limits_{R}aec\)
对于活前缀\(ae\)来说,当面临符号\(c\)时应该移进,面临符号\(d\)时应用产生式\(A\rightarrow e\)归约。因为\(S'\mathop{\Rightarrow}\limits_{R}S\mathop{\nRightarrow}\limits_{R}aAc\),故\(aAc\)不是该文法的规范句型。
若\([A\rightarrow a\cdot B\beta]\in I_n\),则\([B\rightarrow\cdot\gamma]\in I_n\)。可以考虑把\(FIRST(\beta)\)作为用产生式\(B\rightarrow\gamma\)归约的搜索符,成为向前搜索符,这样在要决定是归约还是移进的时候看看输入串下一个符号是否属于\(FIRST(\beta)\)集。向前搜索符通常也放在相应项目的后面。
LR(1)项目集族的构造
首先以 \(S'\rightarrow\cdot S,\#\) 作为初始项目集,\(\#\)为向前搜索符(表示活前缀\(\gamma\)要规约成\(S\)时,必须面临输入符\(\#\)才行)
和LR(0)相比,区别仅在于:如果项目\((A\rightarrow\alpha\cdot B\beta, a)\)属于该项目集,\(B\rightarrow\gamma\)是文法中的产生式,\(\beta\in V^*\),\(b\in FIRST(\beta a)\),则\((B\rightarrow \cdot\gamma, b)\)属于该项目集,并且沿着该项目集开始往后\(B\rightarrow \gamma\)的所有项目都用同一个向前搜索符\(b\)。
注意:向前搜索符有可能不止一个!
例1
现在目光来到上图的项目集\(I_2\)
\(S\rightarrow a\cdot Ad\)
\(S\rightarrow a\cdot ec\)
\(A\rightarrow \cdot e\)
首先\(aAd\)被归约成\(S\)时,根据唯一推导\(S\)的式子\(S'\rightarrow S\),可以确定\(S\)后面没有符号,故\(S\rightarrow a\cdot Ad\)的向前搜索符为\(\#\)。
同理,\(S\rightarrow a\cdot ec\)的向前搜索符也为\(\#\)
现在,由于项目中有\((S\rightarrow a\cdot Ad,\#)\)和\((A\rightarrow\cdot e,?)\)(这里用?表示还不知道向前搜索符),在对\(A\rightarrow e\)这条式子归约之前,可以看到,显然归约是对\(·\)后面的\(A\)进行的,且\(A\)的后面是\(d\),又有整个推导式\(aAd\)的后面是\(\#\),因此\(FIRST(d\#)=d\)。故在归约前需要判断当前输入串的第一个符号是不是为\(d\)。因此\(A\rightarrow\cdot e\)向前搜索符为\(d\)
\(S\rightarrow a\cdot Ad, \#\)
\(S\rightarrow a\cdot ec, \#\)
\(A\rightarrow \cdot e, d\)
例2
再举一个复杂点的例子,现在有\(G[S']:\)
\(S'\rightarrow S\)
\(S\rightarrow BB\)
\(B\rightarrow aB\)
\(B\rightarrow b\)
已知它的初始项目集\(I_0\)为:
\((1)S'\rightarrow\cdot S\)
\((2)S\rightarrow\cdot BB\)
\((3)B\rightarrow\cdot aB\)
\((4)B\rightarrow\cdot b\)
显然,(1)和(2)的向前搜索符都为#
现在关键在推导式3和4,因为他们推导时用的都是\(S\rightarrow\cdot BB\)中的第一个\(B\),在归约的时候要确定它后面构成的串\(B\#\)的\(FIRST\)集,在这里\(FIRST(B\#)=\{a,b\}\),故(3)和(4)的向前搜索符应该都为\(a,b\)
\((1)S'\rightarrow\cdot S,\#\)
\((2)S\rightarrow\cdot BB,\#\)
\((3)B\rightarrow\cdot aB,a/b\)
\((4)B\rightarrow\cdot b,a/b\)
这一章可能的考点
- 已知文法,构造LR(0)的活前缀DFA,可能会要构造分析表,又或者判别是否为LR(0)
- LR(1)补全DFA图,或判别
- SLR(1)判别

 浙公网安备 33010602011771号
浙公网安备 33010602011771号