ceilometer 源码分析(polling)(O版)
一、简单介绍ceilometer
这里长话短说, ceilometer是用来采集openstack下面各种资源的在某一时刻的资源值,比如云硬盘的大小等。下面是官网现在的架构图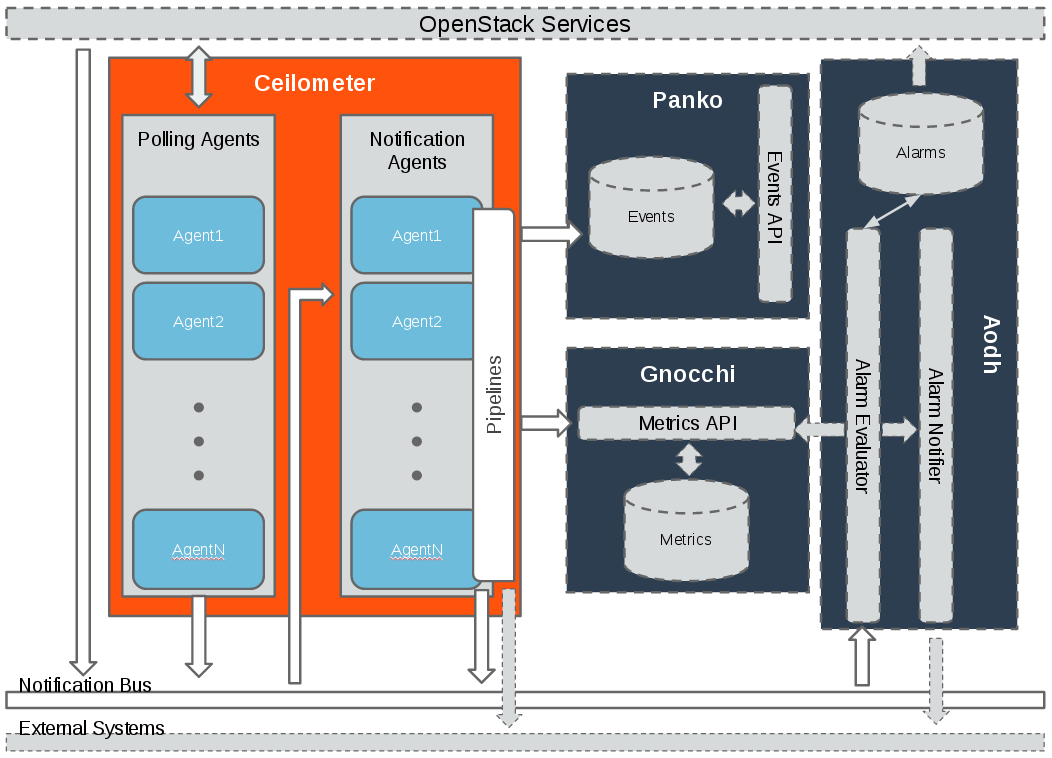
这里除了ceilometer的架构图,还有另外三个组件:
- Panko 用来存储事件的, 后面用来实现cloudkitty事件秒级计费也是我的工作之一,目前实现来一部分,有时间单独在写一篇博文。
- gnocchi是用来存储ceilometer的计量数据,之前的版本是存在mongo中, 不过随着计量数据的不断累计, 查询性能变得极低, 因此openstack后面推出来gnocchi项目,gnocchi的存储后端支持redis,file,ceph等等。这一块也是我负责,目前已经实现了, 有时间也可以写一篇文章。
- Aodh 是用来告警的。
这里需要注意ceilometer 主要有两个agent:
- 一个是polling 主要是定时调用相应的openstack接口来获取计量数据,
- 一个是notification 主要是用来监听openstack的事件消息,然后转换成相应的计量数据,
两者的计量数据, 最后通过定义的pipeline,传递给gnocchi暴露出来的rest API ,后面由gnocchi来做聚合处理以及存储
下面来看一下,具体的官网的数据采集和处理转发的架构图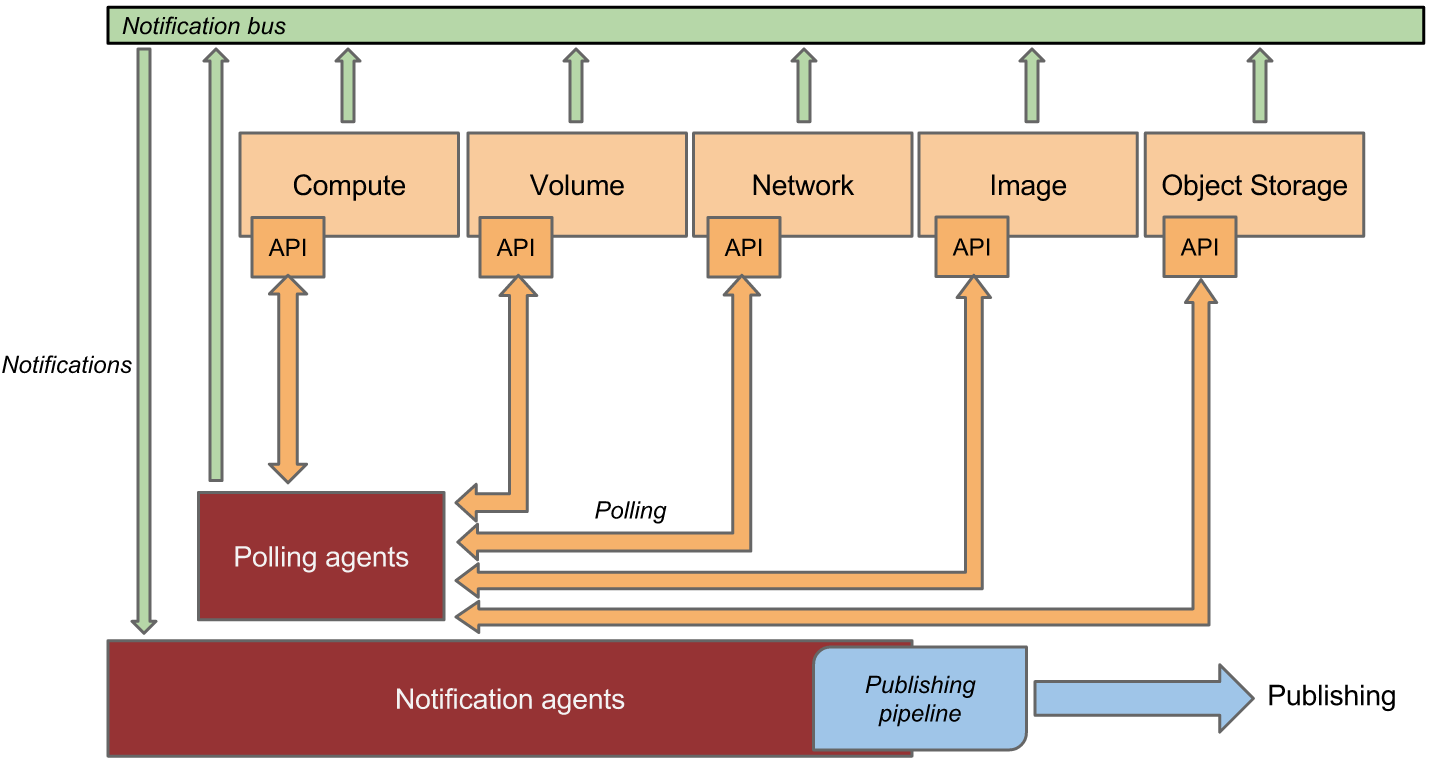
再来看一下数据的处理过程
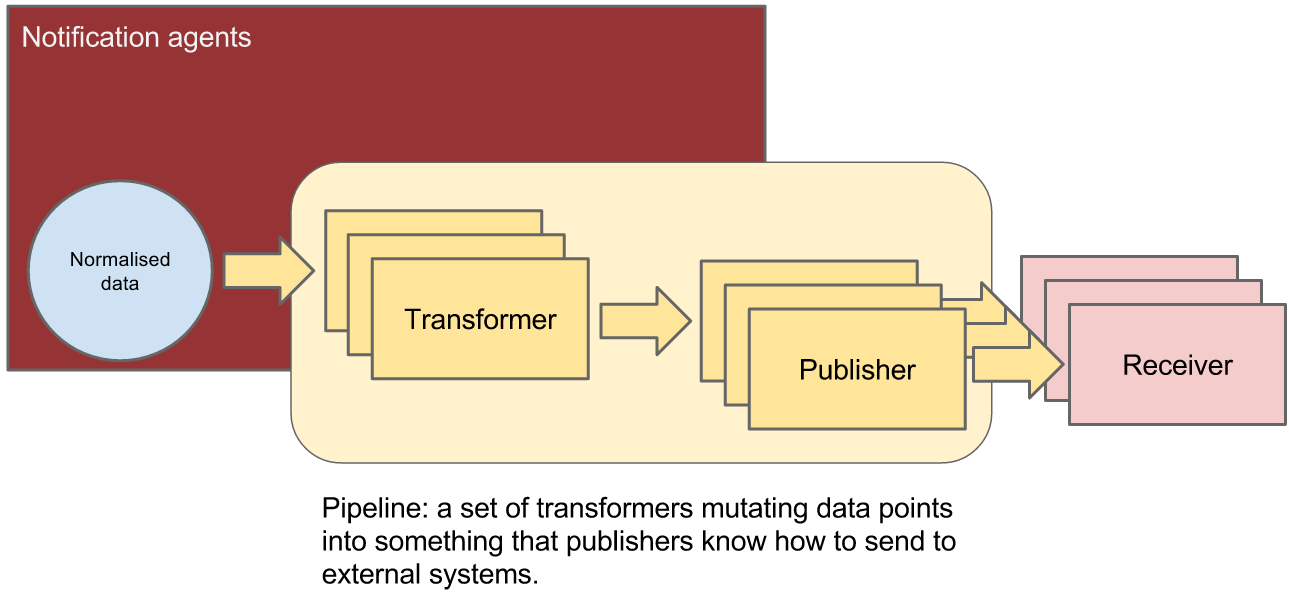
这里,我觉得官方文档的架构图描述得非常好, 我就不在多说来。
二、源码分析
说实话, 目测openstack估计是最大的python项目了,真的是一个庞然大物。第一次接触的时候,完全不知所措。不过看看就强一点了, 虽然有很多地方还是懵逼。看openstack下面的项目的话,其实有些文件很重要比如setup.py, 里面配置了项目的入口点。这篇文章,我主要分析polling这一块是如何实现的, 其他的地方类似。
- ceilometer polling-agent启动的地方
# ceilometer/cmd/polling.py
1 def main(): 2 conf = cfg.ConfigOpts() 3 conf.register_cli_opts(CLI_OPTS) 4 service.prepare_service(conf=conf) 5 sm = cotyledon.ServiceManager() 6 sm.add(create_polling_service, args=(conf,)) 7 oslo_config_glue.setup(sm, conf) 8 sm.run()
# 前面几行是读取配置文件, 然后通过cotyledon这个库add一个polling的service,最后run 起来。 cotyledon这个库简单看了一下,可以用来启动进程任务def create_polling_service(worker_id, conf):
return manager.AgentManager(worker_id,
conf,
conf.polling_namespaces,
conf.pollster_list)
# create_polling_service 返回了一个polling agent polling-namespaces的默认值为choices=['compute', 'central', 'ipmi'], -
polling AgentManager # ceilometer/agent/manager.py
1 class AgentManager(service_base.PipelineBasedService): 2 3 def __init__(self, worker_id, conf, namespaces=None, pollster_list=None, ): 4 5 namespaces = namespaces or ['compute', 'central'] 6 pollster_list = pollster_list or [] 7 group_prefix = conf.polling.partitioning_group_prefix 8 9 # features of using coordination and pollster-list are exclusive, and 10 # cannot be used at one moment to avoid both samples duplication and 11 # samples being lost 12 if pollster_list and conf.coordination.backend_url: 13 raise PollsterListForbidden() 14 15 super(AgentManager, self).__init__(worker_id, conf) 16 17 def _match(pollster): 18 """Find out if pollster name matches to one of the list.""" 19 return any(fnmatch.fnmatch(pollster.name, pattern) for 20 pattern in pollster_list) 21 22 if type(namespaces) is not list: 23 namespaces = [namespaces] 24 25 # we'll have default ['compute', 'central'] here if no namespaces will 26 # be passed 27 extensions = (self._extensions('poll', namespace, self.conf).extensions 28 for namespace in namespaces) 29 # get the extensions from pollster builder 30 extensions_fb = (self._extensions_from_builder('poll', namespace) 31 for namespace in namespaces) 32 if pollster_list: 33 extensions = (moves.filter(_match, exts) 34 for exts in extensions) 35 extensions_fb = (moves.filter(_match, exts) 36 for exts in extensions_fb) 37 38 self.extensions = list(itertools.chain(*list(extensions))) + list( 39 itertools.chain(*list(extensions_fb))) 40 41 if self.extensions == []: 42 raise EmptyPollstersList() 43 44 discoveries = (self._extensions('discover', namespace, 45 self.conf).extensions 46 for namespace in namespaces) 47 self.discoveries = list(itertools.chain(*list(discoveries))) 48 self.polling_periodics = None 49 50 self.partition_coordinator = coordination.PartitionCoordinator( 51 self.conf) 52 self.heartbeat_timer = utils.create_periodic( 53 target=self.partition_coordinator.heartbeat, 54 spacing=self.conf.coordination.heartbeat, 55 run_immediately=True) 56 57 # Compose coordination group prefix. 58 # We'll use namespaces as the basement for this partitioning. 59 namespace_prefix = '-'.join(sorted(namespaces)) 60 self.group_prefix = ('%s-%s' % (namespace_prefix, group_prefix) 61 if group_prefix else namespace_prefix) 62 63 self.notifier = oslo_messaging.Notifier( 64 messaging.get_transport(self.conf), 65 driver=self.conf.publisher_notifier.telemetry_driver, 66 publisher_id="ceilometer.polling") 67 68 self._keystone = None 69 self._keystone_last_exception = None 70 71 72 def run(self): 73 super(AgentManager, self).run() 74 self.polling_manager = pipeline.setup_polling(self.conf) 75 self.join_partitioning_groups() 76 self.start_polling_tasks() 77 self.init_pipeline_refresh()
1 初始化函数里面通过 ExtensionManager加载setup里面定义的各个指标的entry point 包括discover和poll,
discover就是调用openstack的api来get 资源,
poll 就是将discover获取到资源转换成相应的sample(某一时刻的指标值)
2 如果有多个agent 还会创建一个定时器来做心跳检测
3 定义收集到的数据通过消息队列转发送到哪里去 (oslo_messaging.Notifier)
4 之后通过run方法启动polling agent
# setup.py
ceilometer.discover.compute =
local_instances = ceilometer.compute.discovery:InstanceDiscovery
ceilometer.poll.compute =
disk.read.requests = ceilometer.compute.pollsters.disk:ReadRequestsPollster
disk.write.requests = ceilometer.compute.pollsters.disk:WriteRequestsPollster
disk.read.bytes = ceilometer.compute.pollsters.disk:ReadBytesPollster
disk.write.bytes = ceilometer.compute.pollsters.disk:WriteBytesPollster
disk.read.requests.rate = ceilometer.compute.pollsters.disk:ReadRequestsRatePollster
......
- 设置 polling 比如多长的时间间隔去获取资源的指标
1 def setup_polling(conf): 2 """Setup polling manager according to yaml config file.""" 3 cfg_file = conf.polling.cfg_file 4 return PollingManager(conf, cfg_file)
class PollingManager(ConfigManagerBase):
"""Polling Manager
Polling manager sets up polling according to config file.
"""
def __init__(self, conf, cfg_file):
"""Setup the polling according to config.
The configuration is supported as follows:
{"sources": [{"name": source_1,
"interval": interval_time,
"meters" : ["meter_1", "meter_2"],
"resources": ["resource_uri1", "resource_uri2"],
},
{"name": source_2,
"interval": interval_time,
"meters" : ["meter_3"],
},
]}
}
The interval determines the cadence of sample polling
Valid meter format is '*', '!meter_name', or 'meter_name'.
'*' is wildcard symbol means any meters; '!meter_name' means
"meter_name" will be excluded; 'meter_name' means 'meter_name'
will be included.
Valid meters definition is all "included meter names", all
"excluded meter names", wildcard and "excluded meter names", or
only wildcard.
The resources is list of URI indicating the resources from where
the meters should be polled. It's optional and it's up to the
specific pollster to decide how to use it.
"""
super(PollingManager, self).__init__(conf)
try:
cfg = self.load_config(cfg_file)
except (TypeError, IOError):
LOG.warning(_LW('Unable to locate polling configuration, falling '
'back to pipeline configuration.'))
cfg = self.load_config(conf.pipeline_cfg_file)
self.sources = []
if 'sources' not in cfg:
raise PollingException("sources required", cfg)
for s in cfg.get('sources'):
self.sources.append(PollingSource(s))
# 根据下面的配置文件 etc/ceilometer/polling.yaml 初始化配置---
sources:
- name: all_pollsters
interval: 600
meters:
- "*" - 将每个discovery根据相应的group id 加入到同一个组里面去
1 def join_partitioning_groups(self): 2 self.groups = set([self.construct_group_id(d.obj.group_id) 3 for d in self.discoveries]) 4 # let each set of statically-defined resources have its own group 5 static_resource_groups = set([ 6 self.construct_group_id(utils.hash_of_set(p.resources)) 7 for p in self.polling_manager.sources 8 if p.resources 9 ]) 10 self.groups.update(static_resource_groups) 11 12 if not self.groups and self.partition_coordinator.is_active(): 13 self.partition_coordinator.stop() 14 self.heartbeat_timer.stop() 15 16 if self.groups and not self.partition_coordinator.is_active(): 17 self.partition_coordinator.start() 18 utils.spawn_thread(self.heartbeat_timer.start) 19 20 for group in self.groups: 21 self.partition_coordinator.join_group(group)
- 开启polling task
1 def start_polling_tasks(self): 2 # allow time for coordination if necessary 3 delay_start = self.partition_coordinator.is_active() 4 5 # set shuffle time before polling task if necessary 6 delay_polling_time = random.randint( 7 0, self.conf.shuffle_time_before_polling_task) 8 9 data = self.setup_polling_tasks() 10 11 # Don't start useless threads if no task will run 12 if not data: 13 return 14 15 # One thread per polling tasks is enough 16 self.polling_periodics = periodics.PeriodicWorker.create( 17 [], executor_factory=lambda: 18 futures.ThreadPoolExecutor(max_workers=len(data))) 19 20 for interval, polling_task in data.items(): 21 delay_time = (interval + delay_polling_time if delay_start 22 else delay_polling_time) 23 24 @periodics.periodic(spacing=interval, run_immediately=False) 25 def task(running_task): 26 self.interval_task(running_task) 27 28 utils.spawn_thread(utils.delayed, delay_time, 29 self.polling_periodics.add, task, polling_task) 30 31 utils.spawn_thread(self.polling_periodics.start, allow_empty=True)
# 根据之前的polling.yaml和从setup文件动态加载的extensions生成一个个task
def setup_polling_tasks(self):
polling_tasks = {}
for source in self.polling_manager.sources:
polling_task = None
for pollster in self.extensions:
if source.support_meter(pollster.name):
polling_task = polling_tasks.get(source.get_interval())
if not polling_task:
polling_task = self.create_polling_task()
polling_tasks[source.get_interval()] = polling_task
polling_task.add(pollster, source)
return polling_tasks
之后通过periodics 和polling.yaml定义的间隔周期性的执行任务def interval_task(self, task):
# NOTE(sileht): remove the previous keystone client
# and exception to get a new one in this polling cycle.
self._keystone = None
self._keystone_last_exception = None
task.poll_and_notify()def poll_and_notify(self):
"""Polling sample and notify."""
cache = {}
discovery_cache = {}
poll_history = {}
for source_name in self.pollster_matches:
for pollster in self.pollster_matches[source_name]:
key = Resources.key(source_name, pollster)
candidate_res = list(
self.resources[key].get(discovery_cache))
if not candidate_res and pollster.obj.default_discovery:
candidate_res = self.manager.discover(
[pollster.obj.default_discovery], discovery_cache)
# Remove duplicated resources and black resources. Using
# set() requires well defined __hash__ for each resource.
# Since __eq__ is defined, 'not in' is safe here.
polling_resources = []
black_res = self.resources[key].blacklist
history = poll_history.get(pollster.name, [])
for x in candidate_res:
if x not in history:
history.append(x)
if x not in black_res:
polling_resources.append(x)
poll_history[pollster.name] = history
# If no resources, skip for this pollster
if not polling_resources:
p_context = 'new ' if history else ''
LOG.info(_LI("Skip pollster %(name)s, no %(p_context)s"
"resources found this cycle"),
{'name': pollster.name, 'p_context': p_context})
continue
LOG.info(_LI("Polling pollster %(poll)s in the context of "
"%(src)s"),
dict(poll=pollster.name, src=source_name))
try:
polling_timestamp = timeutils.utcnow().isoformat()
samples = pollster.obj.get_samples(
manager=self.manager,
cache=cache,
resources=polling_resources
)
sample_batch = []
for sample in samples:
# Note(yuywz): Unify the timestamp of polled samples
sample.set_timestamp(polling_timestamp)
sample_dict = (
publisher_utils.meter_message_from_counter(
sample, self._telemetry_secret
))
if self._batch:
sample_batch.append(sample_dict)
else:
self._send_notification([sample_dict])
if sample_batch:
self._send_notification(sample_batch)
except plugin_base.PollsterPermanentError as err:
LOG.error(_LE(
'Prevent pollster %(name)s from '
'polling %(res_list)s on source %(source)s anymore!')
% ({'name': pollster.name, 'source': source_name,
'res_list': err.fail_res_list}))
self.resources[key].blacklist.extend(err.fail_res_list)
except Exception as err:
LOG.error(_LE(
'Continue after error from %(name)s: %(error)s')
% ({'name': pollster.name, 'error': err}),
exc_info=True)# 循环调用discovery的extensions的 discover方法,获取资源, 之后调用polling的extensions的get_samples方法将资源转换成相应的指标对象sample
之后将消息发送到消息队列里面去。然后由ceilometer的notification agnet 获取,之后在做进一步的转换发送给gnocchi
polling agent 的基本过程就是这样的,后面就是notification agent 的处理

 浙公网安备 33010602011771号
浙公网安备 33010602011771号