HTTP协议—图解
前言
说到HTTP,我想大家都知道它是超文本传输协议,规定了浏览器和服务器之间互相通信的规则。但是如果问你它是怎样规定的?又是怎样进行通信的?或许你就会觉得不就是在浏览器输入一个URL,然后服务器返回一个页面嘛。毫无疑问这样的理解远远不够,让你继续往下说就会觉得好像是这样又有点词不达意。其实这说明我们理解的还不够深,而深入理解HTTP也恰恰是身为前端人员必备的一项技能,网上关于HTTP的解释很多但也有点难懂,后来我在《HTTP图解》这本书里看到了用图片的方式向我们解释了HTTP,很清晰易懂,所以在这里分享给大家。
一、了解Web及网络基础
1、使用HTTP协议访问Web
你知道当我们在网页浏览器(Web browser)的地址栏中输入 URL时,Web 页面是如何呈现的吗?

Web 页面当然不能凭空显示出来。根据 Web 浏览器地址栏中指定的URL,Web 浏览器从 Web 服务器端获取文件资源(resource)等信息,从而显示出 Web 页面。
像这种通过发送请求获取服务器资源的 Web 浏览器等,都可称为客户端(client)。

Web 使用一种名为 HTTP(HyperText Transfer Protocol,超文本传输协议 1)的协议作为规范,完成从客户端到服务器端等一系列运作流程。而协议是指规则的约定。可以说,Web 是建立在 HTTP 协议上通信的。
2、TCP/IP协议族
为了理解 HTTP,我们有必要事先了解一下 TCP/IP 协议族。通常使用的网络(包括互联网)是在 TCP/IP 协议族的基础上运作的。而 HTTP 属于它内部的一个子集。
计算机与网络设备要相互通信,双方就必须基于相同的方法。比如,如何探测到通信目标、由哪一边先发起通信、使用哪种语言进行通信、怎样结束通信等规则都需要事先确定。不同的硬件、操作系统之间的通信,所有的这一切都需要一种规则。而我们就把这种规则称为协议(protocol)。
TCP/IP 是互联网相关的各类协议族的总称,如下图:
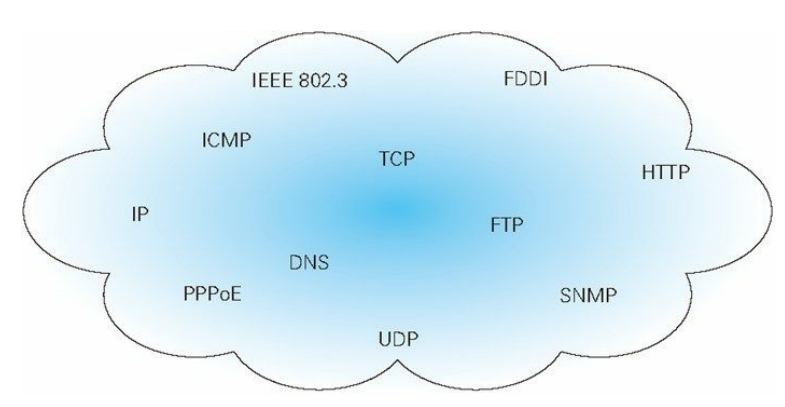
3、TCP/IP的分层管理
TCP/IP 协议族里重要的一点就是分层。TCP/IP 协议族按层次分别分 为以下 4 层:应用层、传输层、网络层和数据链路层。
把 TCP/IP 层次化是有好处的。比如,如果互联网只由一个协议统 筹,某个地方需要改变设计时,就必须把所有部分整体替换掉。而分 层之后只需把变动的层替换掉即可。把各层之间的接口部分规划好之 后,每个层次内部的设计就能够自由改动了。
值得一提的是,层次化之后,设计也变得相对简单了。处于应用层上 的应用可以只考虑分派给自己的任务,而不需要弄清对方在地球上哪 个地方、对方的传输路线是怎样的、是否能确保传输送达等问题。
TCP/IP 协议族各层的作用如下:
4、TCP/TP通信传输流
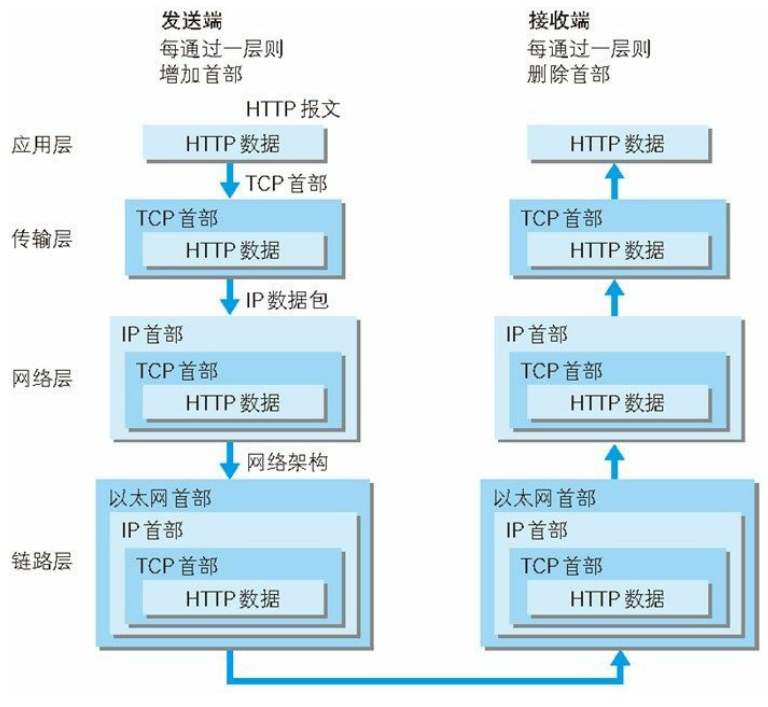
我们来举一个例子说明这个通信流程,比如说我们想打开某个网页,流程如下:
- 首先作为发送端的客户端在应用层(HTTP 协议)发出一个想看某个 Web 页面的 HTTP 请求。
- 为了传输方便,在传输层(TCP 协议)把从应用层处收到的数据(HTTP 请求报文)进行分割,并在各个报文上打上标记序号及端口号后转发给网络层。
- 在网络层(IP 协议),增加作为通信目的地的 MAC 地址后转发给链路层。这样一来,发往网络的通信请求就准备齐全了。
- 接收端的服务器在链路层接收到数据,按序往上层发送,一直到应用层。
- 当传输到应用层,才能算真正接收到由客户端发送过来的 HTTP请求发送端在层与层之间传输数据时。
(每经过一层时必定会被打上一个该层所属的首部信息。反之,接收端在层与层传输数据时,每经过一层时会把对应的首部消去。)
5、各种协议和HTTP协议之间的关系
学习了和 HTTP 协议密不可分的 TCP/IP 协议族中的各种协议后,我们再通过这张图来了解下 IP 协议、TCP 协议和 DNS 服务在使用HTTP 协议的通信过程中各自发挥了哪些作用。
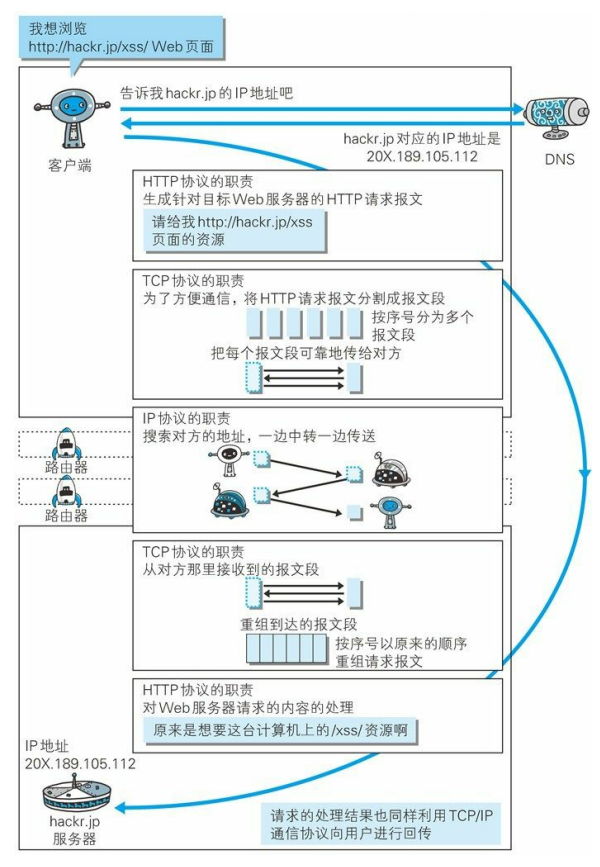
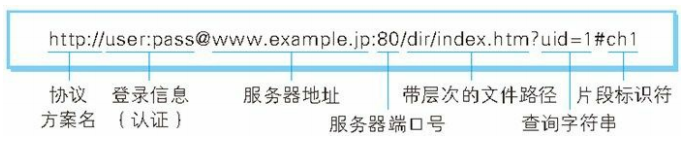
7、URI 和URL
与 URI(统一资源标识符)相比,我们更熟悉 URL(UniformResource Locator,统一资源定位符)。在WWW上,每一信息资源都有统一的且在网上唯一的地址,该地址就叫URL。URL正是使用 Web 浏览器等访问 Web 页面时需要输入的网页地址。比如,下图的 http://hackr.jp/就是 URL。

URI 用字符串标识某一互联网资源,而 URL表示资源的地点(互联网上所处的位置)。可见 URL是 URI 的子集。 接下来我们来看一下URI的格式(在充分理解的基础上,也可用 URL替换 URI。):
二、HTTP协议
1、客户端与服务端之间的通信
HTTP 协议规定,请求从客户端发出,最后服务器端响应该请求并返回。换句话说,肯定是先从客户端开始建立通信的,服务器端在没有接收到请求之前不会发送响应。如下:
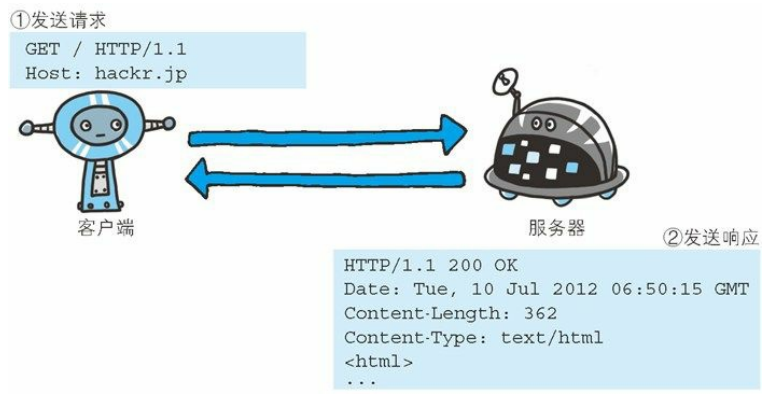
下面则是从客户端发送给某个 HTTP 服务器端的请求报文中的内容。
接收到请求的服务器,会将请求内容的处理结果以响应的形式返回。

HTTP 是一种不保存状态,即无状态协议。HTTP 协议自身不对请求和响应之间的通信状态进行保存。也就是说在 HTTP 这个级别,协议对于发送过的请求或响应都不做持久化处理。
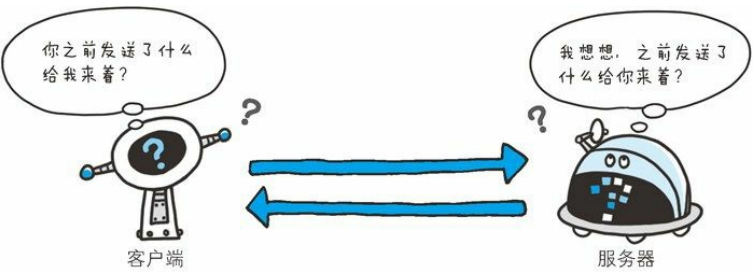
使用 HTTP 协议,每当有新的请求发送时,就会有对应的新响应产生。协议本身并不保留之前一切的请求或响应报文的信息。这是为了更快地处理大量事务,确保协议的可伸缩性,而特意把 HTTP 协议设计成如此简单的。
可是,随着 Web 的不断发展,因无状态而导致业务处理变得棘手的情况增多了。比如,用户登录到一家购物网站,即使他跳转到该站的其他页面后,也需要能继续保持登录状态。针对这个实例,网站为了能够掌握是谁送出的请求,需要保存用户的状态。
HTTP/1.1 虽然是无状态协议,但为了实现期望的保持状态功能,于是引入了 Cookie 技术。有了 Cookie 再用 HTTP 协议通信,就可以管理状态了。
3、HTTP方法
(1)GET 获取资源
GET 方法用来请求访问已被 URL 识别的资源。指定的资源经服务器端解析后返回响应内容。也就是说,如果请求的资源是文本,那就保持原样返回;如果是像 CGI(通用网关接口)那样的程序,则返回经过执行后的输出结果。
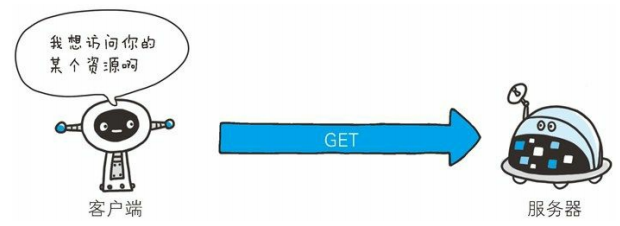
GET方法请求响应的例子:

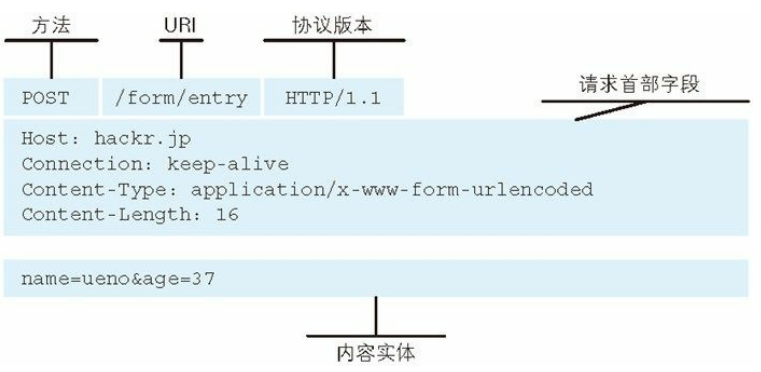
(2)POST传输实体的主体
POST 方法用来传输实体的主体。虽然用 GET 方法也可以传输实体的主体,但一般不用 GET 方法进行传输,而是用 POST 方法。虽说 POST 的功能与 GET 很相似,但POST 的主要目的并不是获取响应的主体内容。
POST方法请求响应的例子:

(3)PUT传输文件
PUT 方法用来传输文件。就像 FTP 协议的文件上传一样,要求在请求报文的主体中包含文件内容,然后保存到请求 URI 指定的位置。但是,鉴于 HTTP/1.1 的 PUT 方法自身不带验证机制,任何人都可以上传文件 , 存在安全性问题,因此一般的 Web 网站不使用该方法。

(4)HEAD获得报文首部
HEAD 方法和 GET 方法一样,只是不返回报文主体部分。用于确认URI 的有效性及资源更新的日期时间等。

(5)DELETE删除文件
DELETE 方法用来删除文件,是与 PUT 相反的方法。DELETE 方法按请求 URI 删除指定的资源。其本质和PUT方法一样不带验证机制,所以不适用DELETE方法。

(6)方法归纳
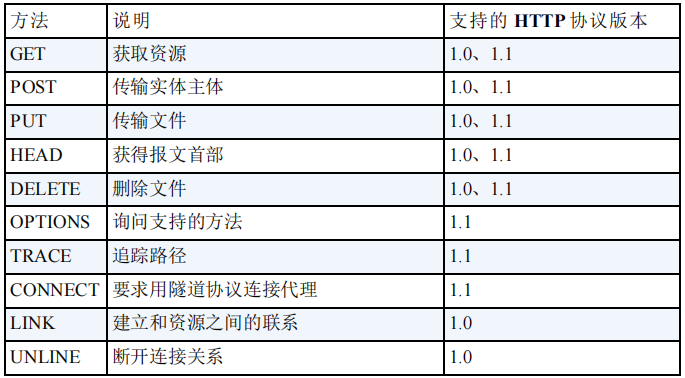
LINK 和 UNLINK 已被 HTTP/1.1 废弃,不再支持。
4、持久连接节省通信量
HTTP 协议的初始版本中,每进行一次 HTTP 通信就要断开一次 TCP连接。 以当年的通信情况来说,因为都是些容量很小的文本传输,所以即使这样也没有多大问题。可随着 HTTP 的普及,文档中包含大量图片的情况多了起来。
比如,使用浏览器浏览一个包含多张图片的 HTML页面时,在发送请求访问 HTML页面资源的同时,也会请求该 HTML页面里包含的其他资源。因此,每次的请求都会造成无谓的 TCP 连接建立和断开,增加通信量的开销。
持久连接的好处在于减少了 TCP 连接的重复建立和断开所造成的额外开销,减轻了服务器端的负载。另外,减少开销的那部分时间,使HTTP 请求和响应能够更早地结束,这样 Web 页面的显示速度也就相应提高了
5、使用Cookie的状态管理
HTTP 是无状态协议,它不对之前发生过的请求和响应的状态进行管理。也就是说,无法根据之前的状态进行本次的请求处理。
如图,如果让服务器管理全部客户端状态则会成为负担。
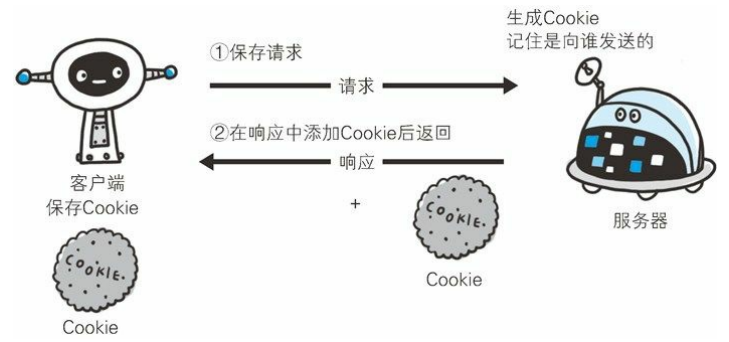
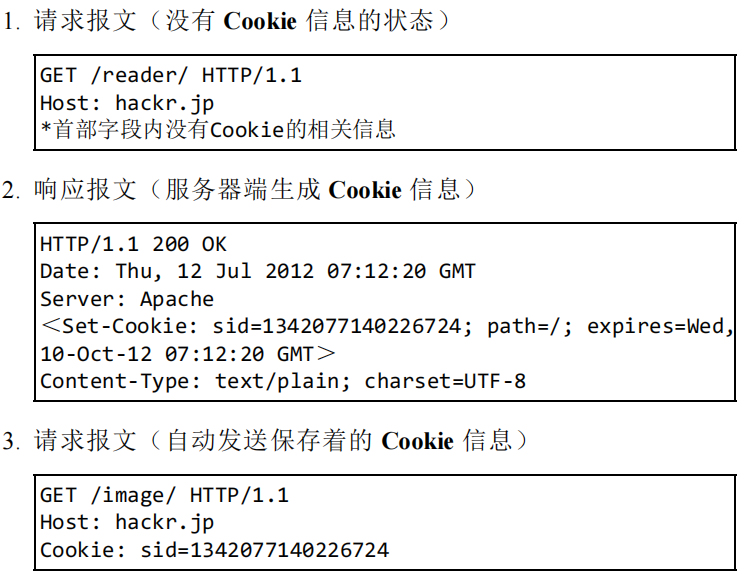
保留无状态协议这个特征的同时又要解决类似的矛盾问题,于是引入了 Cookie 技术。Cookie 技术通过在请求和响应报文中写入 Cookie 信息来控制客户端的状态。
Cookie 会根据从服务器端发送的响应报文内的一个叫做 Set-Cookie 的首部字段信息,通知客户端保存 Cookie。当下次客户端再往该服务器发送请求时,客户端会自动在请求报文中加入 Cookie 值后发送出去。
服务器端发现客户端发送过来的 Cookie 后,会去检查究竟是从哪一个客户端发来的连接请求,然后对比服务器上的记录,最后得到之前的状态信息。让我们来看一下具体过程:
- 没有 Cookie 信息状态下的请求
- 第 2 次以后(存有 Cookie 信息状态)的请求

有了Cookie之后,HTTP请求报文和响应报文的内容如下:
注:本文内容来源自《HTTP图解》,想详细了解的同学可以购买本书查阅。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号