

Hive Sql实现高难度的 sql 需求
题目:
(1).前置条件:
有以下数据集I,表查询结果如下图所示,设置该表为表:test_user_scan。
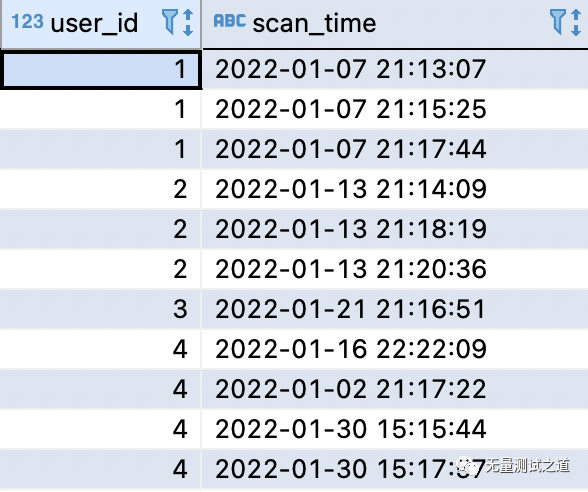
(2).题目要求:
使用 hive sql 查询出每个用户相邻两次浏览时间之差小于三分钟的次数。
预期结果:
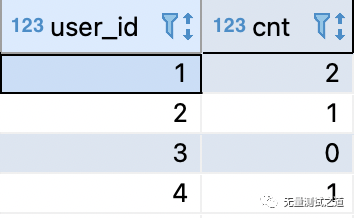
解题思路:
(1). 子查询G 作为 left join 的主表,主要是为了获取所有的user_id
查询结果如下:
user_id scan_time
1 2022-01-07 21:13:07
1 2022-01-07 21:15:25
1 2022-01-07 21:17:44
2 2022-01-13 21:14:09
2 2022-01-13 21:18:19
2 2022-01-13 21:20:36
3 2022-01-21 21:16:51
4 2022-01-02 21:17:22
4 2022-01-16 22:22:09
4 2022-01-30 15:15:44
4 2022-01-30 15:17:57
(2). 子查询H 作为 left join 的副表,主要是为了统计每个用户相邻两次浏览时间之差小于三分钟的总次数。
查询结果如下:
user_id cnt
1 2
2 1
4 1
子查询H = 子查询C join 子查询D
(C=D, 使用C join D进行自关联,是为了处理:“相邻两次”和“浏览时间之差小于三分钟”的逻辑。)
子查询C,查询结果如下(与子查询D查询结果一致):
user_id scan_time rn
1 2022-01-07 21:13:07 1
1 2022-01-07 21:15:25 2
1 2022-01-07 21:17:44 3
2 2022-01-13 21:14:09 1
2 2022-01-13 21:18:19 2
2 2022-01-13 21:20:36 3
3 2022-01-21 21:16:51 1
4 2022-01-02 21:17:22 1
4 2022-01-16 22:22:09 2
4 2022-01-30 15:15:44 3
4 2022-01-30 15:17:57 4
子查询D,查询结果如下:
user_id scan_time rn
1 2022-01-07 21:13:07 1
1 2022-01-07 21:15:25 2
1 2022-01-07 21:17:44 3
2 2022-01-13 21:14:09 1
2 2022-01-13 21:18:19 2
2 2022-01-13 21:20:36 3
3 2022-01-21 21:16:51 1
4 2022-01-02 21:17:22 1
4 2022-01-16 22:22:09 2
4 2022-01-30 15:15:44 3
4 2022-01-30 15:17:57 4
(3). 最后使用子查询G 的结果 left join 子查询H 的结果,查询结果如预期结果所示
使用 user_id 作为关联条件,并对 cnt 为 null 的数据进行 nvl 判断转换为0,最后使用 user_id 和 cnt 进行分组过滤重复数据
解题方式一:
适用于不用创建物理表的情况下
使用数据集I、A、E替代物理表:test_user_scan,直接复制以下 hive sql 语句,可以在 Apache Hive 环境直接运行,得到以上预期结果数据。
select G.user_id, CASE WHEN nvl(H.cnt, 0) = 0 THEN 0 ELSE H.cnt END cnt from ( select * from( select 1 user_id,date_format(regexp_replace('2022/1/7 21:13:07', '/', '-'), 'yyyy-MM-dd HH:mm:ss') scan_time union all select 1 user_id,date_format(regexp_replace('2022/1/7 21:15:25', '/', '-'), 'yyyy-MM-dd HH:mm:ss') scan_time union all select 1 user_id,date_format(regexp_replace('2022/1/7 21:17:44', '/', '-'), 'yyyy-MM-dd HH:mm:ss') scan_time union all select 2 user_id,date_format(regexp_replace('2022/1/13 21:14:09', '/', '-'), 'yyyy-MM-dd HH:mm:ss') scan_time union all select 2 user_id,date_format(regexp_replace('2022/1/13 21:18:19', '/', '-'), 'yyyy-MM-dd HH:mm:ss') scan_time union all select 2 user_id,date_format(regexp_replace('2022/1/13 21:20:36', '/', '-'), 'yyyy-MM-dd HH:mm:ss') scan_time union all select 3 user_id,date_format(regexp_replace('2022/1/21 21:16:51', '/', '-'), 'yyyy-MM-dd HH:mm:ss') scan_time union all select 4 user_id,date_format(regexp_replace('2022/1/16 22:22:09', '/', '-'), 'yyyy-MM-dd HH:mm:ss') scan_time union all select 4 user_id,date_format(regexp_replace('2022/1/2 21:17:22', '/', '-'), 'yyyy-MM-dd HH:mm:ss') scan_time union all select 4 user_id,date_format(regexp_replace('2022/1/30 15:15:44', '/', '-'), 'yyyy-MM-dd HH:mm:ss') scan_time union all select 4 user_id,date_format(regexp_replace('2022/1/30 15:17:57', '/', '-'), 'yyyy-MM-dd HH:mm:ss') scan_time )I order by user_id,scan_time )G left join ( select C.user_id, count(1) as cnt from ( select B.*, row_number() over(partition by user_id order by scan_time) rn from ( select * from ( select 1 user_id,date_format(regexp_replace('2022/1/7 21:13:07', '/', '-'), 'yyyy-MM-dd HH:mm:ss') scan_time union all select 1 user_id,date_format(regexp_replace('2022/1/7 21:15:25', '/', '-'), 'yyyy-MM-dd HH:mm:ss') scan_time union all select 1 user_id,date_format(regexp_replace('2022/1/7 21:17:44', '/', '-'), 'yyyy-MM-dd HH:mm:ss') scan_time union all select 2 user_id,date_format(regexp_replace('2022/1/13 21:14:09', '/', '-'), 'yyyy-MM-dd HH:mm:ss') scan_time union all select 2 user_id,date_format(regexp_replace('2022/1/13 21:18:19', '/', '-'), 'yyyy-MM-dd HH:mm:ss') scan_time union all select 2 user_id,date_format(regexp_replace('2022/1/13 21:20:36', '/', '-'), 'yyyy-MM-dd HH:mm:ss') scan_time union all select 3 user_id,date_format(regexp_replace('2022/1/21 21:16:51', '/', '-'), 'yyyy-MM-dd HH:mm:ss') scan_time union all select 4 user_id,date_format(regexp_replace('2022/1/16 22:22:09', '/', '-'), 'yyyy-MM-dd HH:mm:ss') scan_time union all select 4 user_id,date_format(regexp_replace('2022/1/2 21:17:22', '/', '-'), 'yyyy-MM-dd HH:mm:ss') scan_time union all select 4 user_id,date_format(regexp_replace('2022/1/30 15:15:44', '/', '-'), 'yyyy-MM-dd HH:mm:ss') scan_time union all select 4 user_id,date_format(regexp_replace('2022/1/30 15:17:57', '/', '-'), 'yyyy-MM-dd HH:mm:ss') scan_time )A order by user_id,scan_time )B )C join ( select F.*, row_number() over(partition by user_id order by scan_time) rn from ( select * from ( select 1 user_id,date_format(regexp_replace('2022/1/7 21:13:07', '/', '-'), 'yyyy-MM-dd HH:mm:ss') scan_time union all select 1 user_id,date_format(regexp_replace('2022/1/7 21:15:25', '/', '-'), 'yyyy-MM-dd HH:mm:ss') scan_time union all select 1 user_id,date_format(regexp_replace('2022/1/7 21:17:44', '/', '-'), 'yyyy-MM-dd HH:mm:ss') scan_time union all select 2 user_id,date_format(regexp_replace('2022/1/13 21:14:09', '/', '-'), 'yyyy-MM-dd HH:mm:ss') scan_time union all select 2 user_id,date_format(regexp_replace('2022/1/13 21:18:19', '/', '-'), 'yyyy-MM-dd HH:mm:ss') scan_time union all select 2 user_id,date_format(regexp_replace('2022/1/13 21:20:36', '/', '-'), 'yyyy-MM-dd HH:mm:ss') scan_time union all select 3 user_id,date_format(regexp_replace('2022/1/21 21:16:51', '/', '-'), 'yyyy-MM-dd HH:mm:ss') scan_time union all select 4 user_id,date_format(regexp_replace('2022/1/16 22:22:09', '/', '-'), 'yyyy-MM-dd HH:mm:ss') scan_time union all select 4 user_id,date_format(regexp_replace('2022/1/2 21:17:22', '/', '-'), 'yyyy-MM-dd HH:mm:ss') scan_time union all select 4 user_id,date_format(regexp_replace('2022/1/30 15:15:44', '/', '-'), 'yyyy-MM-dd HH:mm:ss') scan_time union all select 4 user_id,date_format(regexp_replace('2022/1/30 15:17:57', '/', '-'), 'yyyy-MM-dd HH:mm:ss') scan_time )E order by user_id,scan_time )F )D ON C.user_id=D.user_id where C.rn = D.rn + 1 and abs((unix_timestamp(C.scan_time) - unix_timestamp(D.scan_time))/60) < 3 group by C.user_id ) H on G.user_id = H.user_id group by G.user_id,H.cnt;
解题方式二:
适用于先创建物理表:test_user_scan的情况下
将测试数据 insert 至 test_user_scan 表。
表数据结果如下:
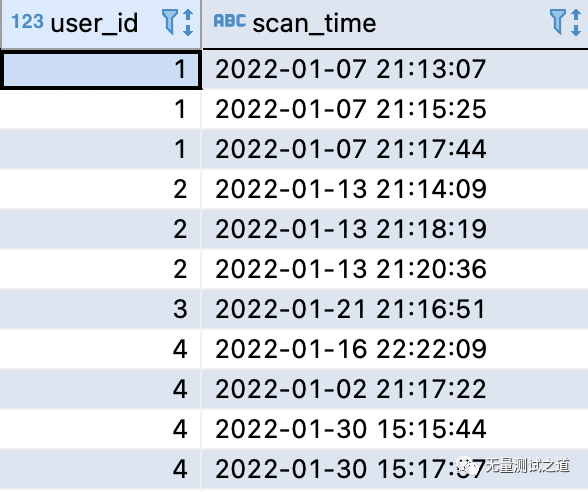
将解题方式一中的数据集I、A、E替换成表 test_user_scan 即可。
select G.user_id, CASE WHEN nvl(H.cnt, 0) = 0 THEN 0 ELSE H.cnt END cnt from ( select * from test_user_scan order by user_id,scan_time )G left join ( select C.user_id, count(1) as cnt from ( select B.*, row_number() over(partition by user_id order by scan_time) rn from ( select * from test_user_scan order by user_id,scan_time )B )C join ( select F.*, row_number() over(partition by user_id order by scan_time) rn from ( select * from test_user_scan order by user_id,scan_time )F )D ON C.user_id=D.user_id where C.rn = D.rn + 1 and abs((unix_timestamp(C.scan_time) - unix_timestamp(D.scan_time))/60) < 3 group by C.user_id ) H on G.user_id = H.user_id group by G.user_id,H.cnt;
知识点归纳:
使用 hive sql 完成这道 Sql 题,所使用到的函数或方法如下:
(1).regexp_replace
正则替换函数,将日期字符串的 "/" 替换为 "-" ;
(2).date_format
日期格式化函数,将使用 regexp_replace 函数替换好的日期字符串,转换为:年月日时分秒(yyyy-MM-dd HH:mm:ss)格式的数据类型,便于后续时间的排序;
(3).row_number() over(partition by user_id order by scan_time) rn
row_number() 函数可以根据指定的分组字段和排序字段对数据结果集进行先分组后排序并标记对应的数字序号,目的是为了提供每个用户相邻两次的比较条件,具体应用在文中的:where C.rn = D.rn + 1这个判断条件里。
(4).abs((unix_timestamp(C.scan_time) - unix_timestamp(D.scan_time))/60)
unix_timestamp 函数将时间日期换算成秒,除以60是为了换算成分钟,因为题目要求是小于3分钟;
abs 函数是求绝对值的,这里为了避免正负数影响条件判断所以加了个绝对值的判断;
(5).case when行转列的条件判断
CASE WHEN nvl(H.cnt, 0) = 0 THEN 0 ELSE H.cnt END cnt
因为用户 user_id 为3的测试数据只有1条,因此没有相邻之说,然而题目预期结果里要求没有的就统计为0,在子查询H 中没有 user_id 为3的结果。
因此在子查询G 作为主表后,user_id 为3对应的 cnt 的值为 null,所以就有了这里 case when 中 nvl 函数对 null 值的处理。
nvl(H.cnt, 0)表示:如果H.cnt的值为null,则将其值转换为0。
欢迎关注【无量测试之道】公众号,回复【领取资源】
Python+Unittest框架API自动化、
Python+Unittest框架API自动化、
Python+Pytest框架API自动化、
Python+Pandas+Pyecharts大数据分析、
Python+Selenium框架Web的UI自动化、
Python+Appium框架APP的UI自动化、
Python编程学习资源干货、
资源和代码 免费送啦~
文章下方有公众号二维码,可直接微信扫一扫关注即可。
备注:我的个人公众号已正式开通,致力于IT互联网技术的分享。
包含:数据分析、大数据、机器学习、测试开发、API接口自动化、测试运维、UI自动化、性能测试、代码检测、编程技术等。
微信搜索公众号:“无量测试之道”,或扫描下方二维码:

添加关注,让我们一起共同成长!

