

Hive 函数 + Shell编程的具体实践与运用
Hive Shell参数
1.Hive命令行
(1). 命令:hive -i filename
含义:从文件初始化HQL
filename为test001.sql的内容如下

hive -i test001.sql命令执行结果如下

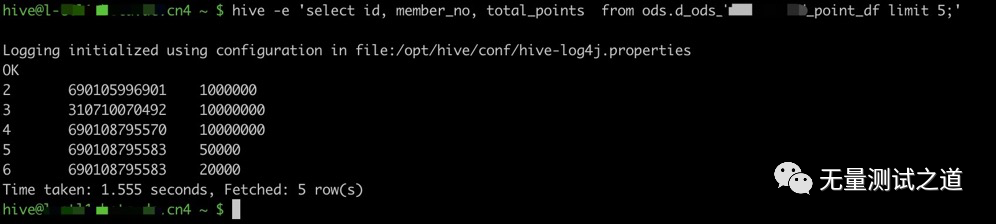
(2). 命令:hive -e 'sql语句'
含义:从命令行执行指定的HQL指令
具体执行示例如下:
(3). 命令:hive -f filename
含义:执行文件中的HQL脚本
这里的filename为test001.sql文件,文件内容如下

hive -f test001.sql执行结果如下

(4). 命令:hive -v
含义:输出执行的HQL语句到控制台
(5). 命令:hive -p
含义:connect to Hive Server on port number -hiveconf x=y Use this to set hive/hadoop configuration variables.
(6). 命令:hive -hiveconf set x=y;
含义:设置hive运行时候的参数配置信息
2.Hive参数配置方式
目的:设定 Hive 的参数可以优化 HQL 代码的执行效率,协助定位问题。
三种参数设定方式:
1. 配置文件
2. 命令行参数
3. 参数声明
配置文件
Hive 的配置文件包含:
用户自定义的配置文件:$HIVE_CONF_DIR/hive-site.xml
默认配置文件:$HIVE_CONF_DIR/hive-default.xml
用户自定义的配置文件会覆盖默认配置文件。
另外,Hive 也会读入 Hadoop 的配置,因为 Hive 是作为 Hadoop 的客户端启动的,Hive的配置会覆盖 Hadoop 的配置。
配置文件的设定对本机启动的所有 Hive 进程都有效。
命令行参数
启动 Hive 客户端或 Server 方式时,可以在命令行添加 -hiveconf param=value 来设定参数,例如:
hive -hiveconf hive.root.logger=INFO,console
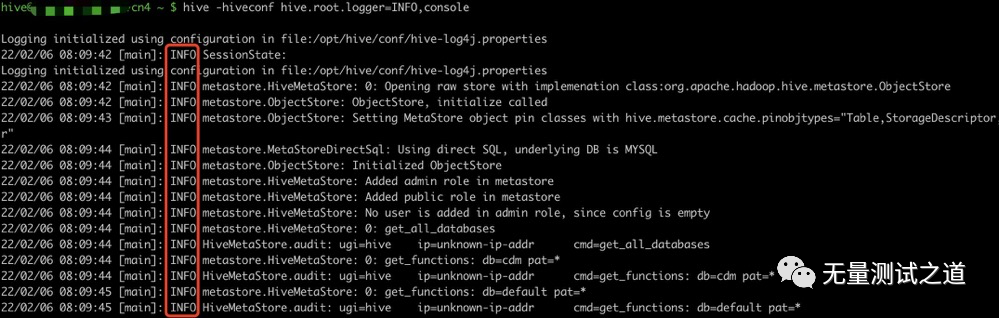
这一设定对本次启动的 Session(对于 Server 方式启动,则是所有请求的 Sessions)有效。
参数声明
可以在 HQL 中使用 SET 关键字设定参数,例如:
set mapred.reduce.tasks=100;
这一设定的作用域也是Session(一次会话)级别的。
上述三种设定方式的优先级依次递增。即参数声明 > 命令行参数 > 配置文件参数
注意:
某些系统级的参数,例如:log4j 相关的设定,必须用参数声明或命令行参数这两种方式设定,因为那些参数的读取在 Session 建立以前已经完成了。
Hive函数
1.内置函数
(1).查看系统自带的函数
show functions;
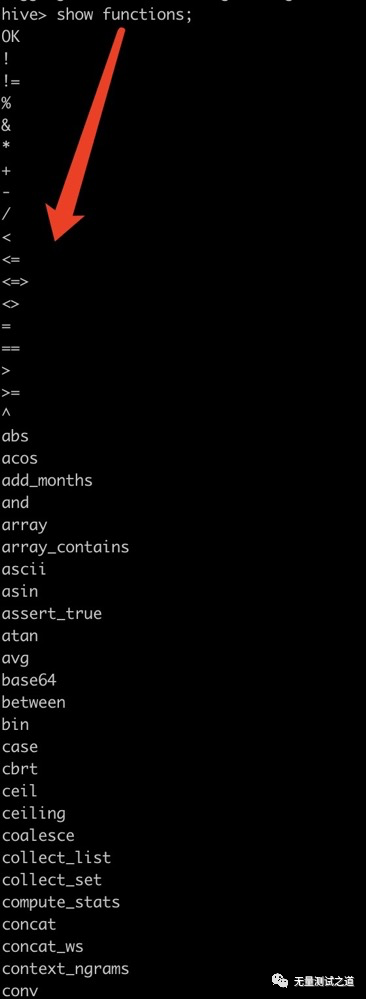
从上图中可以看到 hive 有许多系统自带的内置函数。
(2).显示自带的函数的用法
# 查看abs函数的用法 desc function abs;
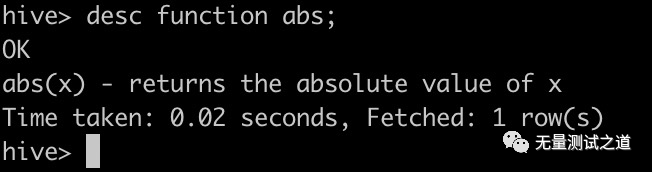
abs函数的含义:返回一个数的绝对值
(3).详细显示自带的函数的用法
# 详细显示upper函数的使用方法 desc function extended upper;
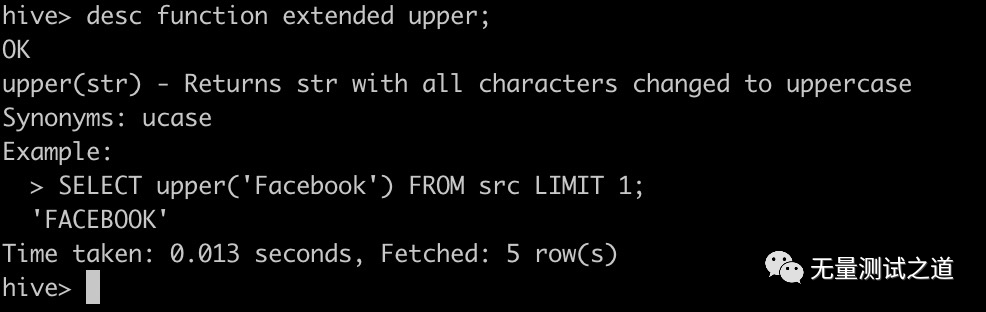
上图是举例说明,upper函数的功能是将字符串"Facebook"全部转换成大写"FACEBOOK"返回
(4).常用内置函数
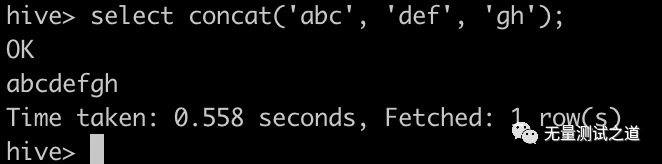
# 字符串拼接函数:concat 用法:select concat('abc', 'def', 'gh'); 实现效果:abcdefgh
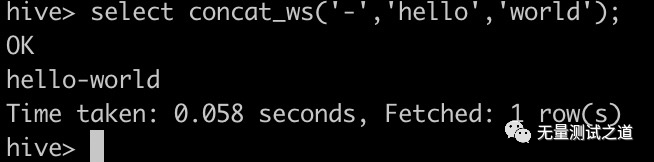
# 带分隔符字符串连接函数:concat_ws 用法:select concat_ws('-','hello','world') 实现效果:hello-world
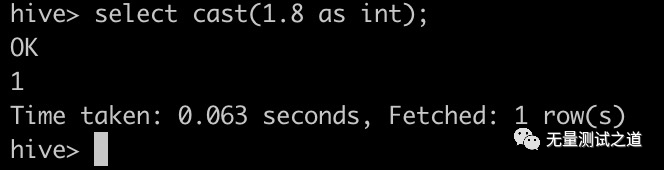
# 数据类型转换函数:cast 用法:select cast(1.8 as int); 实现效果:1
# json解析函数,用来处理json串:get_json_object 用法:select get_json_object('{"name":"tom", "age":"10"}', '$.name'); 实现效果:tom

# URL解析函数:parse_url 用法:select parse_url('http://www.baidu.com/path1?key1=value1&key2=value2#Ref1', 'HOST') 实现效果: 当关键字为HOST时,获取到的值为:www.baidu.com 当关键字为PATH时,获取到的值为:/path1 当关键字为QUERY时,获取到的值为:key1=value1&key2=value2 当关键字为QUERY,key1时,获取到的值为:value1




2.自定义函数
当 Hive 提供的内置函数无法满足我们的业务需求时,此时就可以考虑使用用户自定义函数。
自定义函数类别分为以下三种:
(1): UDF(User-Defined-Function): 一进一出
(2): UDAF(User-Defined Aggregation Function): 聚集函数,多进一出,类似于count、max等函数
(3): UDTF(User-Defined Table-Generating Functions): 一进多出,例如lateral view explore()
实现UDF函数注意事项
(1): 需要继承org.apache.hadoop.hive.ql.UDF
(2): 需要实现evaluate函数,且evaluate函数支持重载
(3): UDF必须要有返回类型,可以返回null,但是返回类型不能是void;
UDF中常用Text字符串、LongWritable等类型,不推荐使用java类型;
UDF自定义函数开发实例
step1: 创建Maven工程

step2: 开发Java类集成UDF

step3: 项目打成jar包,上传到Hive的lib目录下
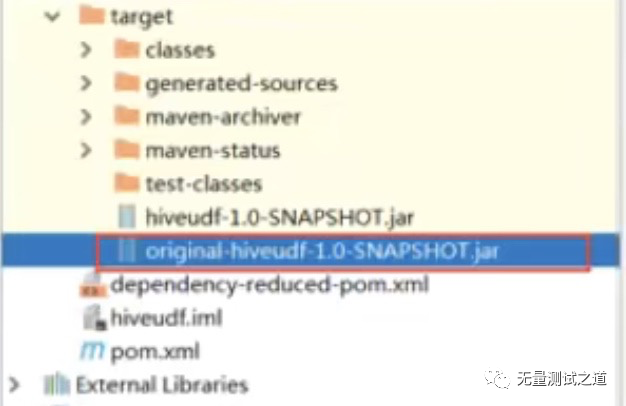
step4: Hive客户端添加打好的jar包
# 进入hive的lib目录下 cd /opt/hadoop/apache-hive-2.7.5-bin/lib # 给jar包重命名 mv original-hiveudf-1.0-SNAPSHOT.jar udf_upper.jar # Hive客户端添加jar包 add jar /opt/hadoop/apache-hive-2.7.5-bin/lib/udf_upper.jar
step5: 设置函数与我们自定义函数关联
create temporary function udf_upper as 'cn.itcast.udf.MyUDF';
step6: 使用自定义函数
select udf_upper('how are you?'); # 实际返回结果:实现了首字母大写的功能 How are you?
欢迎关注【无量测试之道】公众号,回复【领取资源】
Python+Unittest框架API自动化、
Python+Unittest框架API自动化、
Python+Pytest框架API自动化、
Python+Pandas+Pyecharts大数据分析、
Python+Selenium框架Web的UI自动化、
Python+Appium框架APP的UI自动化、
Python编程学习资源干货、
资源和代码 免费送啦~
文章下方有公众号二维码,可直接微信扫一扫关注即可。
备注:我的个人公众号已正式开通,致力于IT互联网技术的分享。
包含:数据分析、大数据、机器学习、测试开发、API接口自动化、测试运维、UI自动化、性能测试、代码检测、编程技术等。
微信搜索公众号:“无量测试之道”,或扫描下方二维码:

添加关注,让我们一起共同成长!
