

LRU 缓存机制
因为希望是O(1)的时间复杂度,所以很容易想到需要使用哈希表。那么接下来,就直接讲实现思路了。
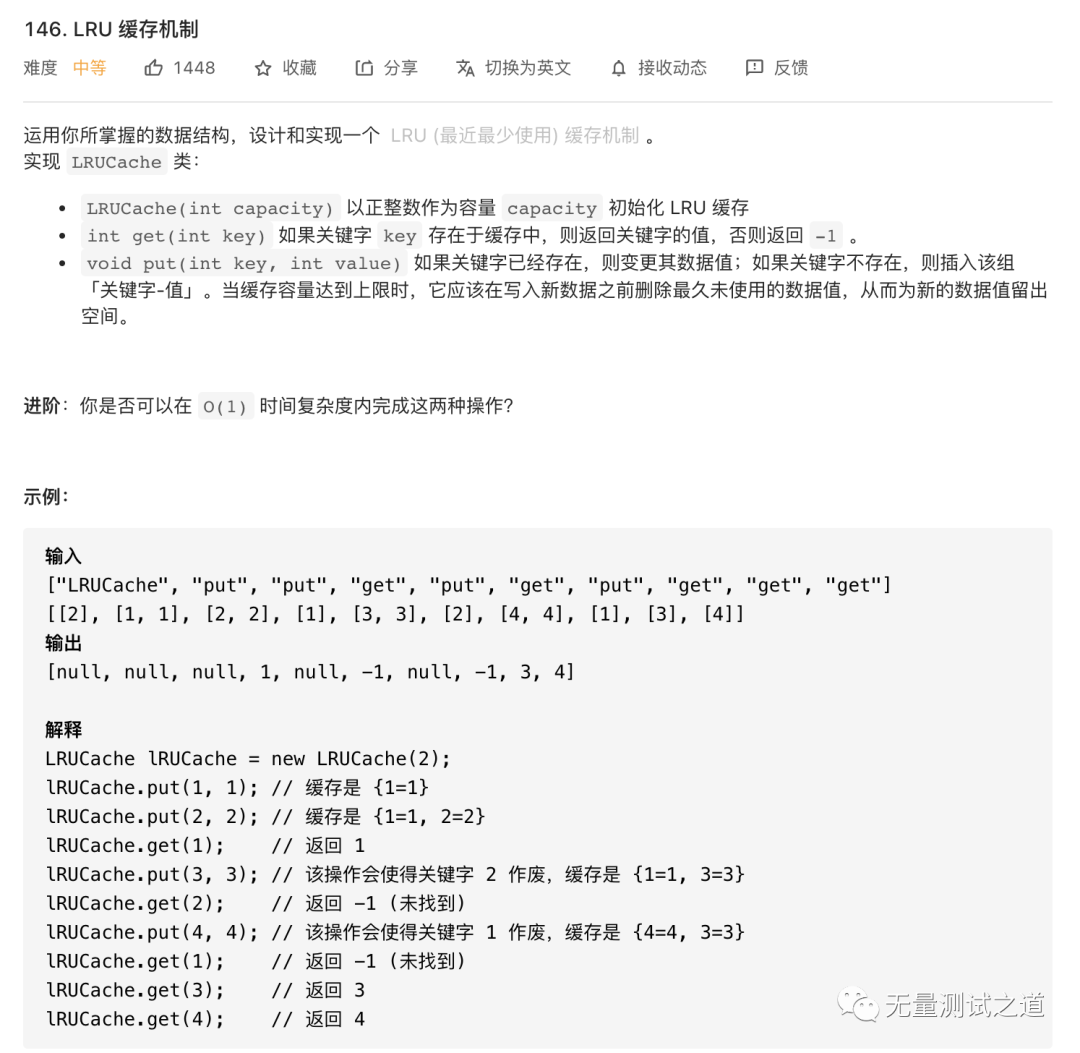
LRUCache 的常见实现方式是:哈希表+双向链表。那为什么不是哈希表+数组了。因为数组的查找和替换是O(N)级别的,所以需要使用双向链表。
思路:
说明:
-
map用来作为存储容器,key是传进来的Int值,value是Node节点;即map[int] = node。 -
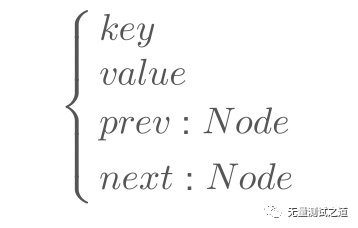
Node节点信息包含
{keyvalueprev:Nodenext:Node
3.LRUCache类包含:map, 以及first , last2 个虚拟的节点
图中的first节点和last的节点都是虚节点,不存储任何值,只是为了维持双向链表的完整性。
完成这个LRUCache的核心思路是:在存和取的时候更新节点的位置。
- 如果该节点存在,执行以下3步
- 如果该节点不存在
- 判断是否已经达到最大容量
取
- 如果没有取到值,就直接返回-1
- 如果取到值了,就需要更新这个节点的位置
- 我们需要将它更新到first节点的后面。具体的执行步骤有以下2步
- 删除该结点,【也就是第5个节点】
- 把该结点添加到first节点的后面
存
- 存的时候,先去根据key获取该结点信息
- 将其value的值更新一下
- 删除该结点
- 并且将该节点添加到first节点的后面
- 如果不是,就将该结点添加到first节点后面
- 如果是,就将最后一个节点【last的prev节点】删掉,然后将新节点添加到fisrt节点的后面
代码如下:swift版本和java版本
class LRUCache { //【swift版本】 private var map = [Int : Node]() private var capacity = 0 private let first = Node(0, 0) private let last = Node(0, 0) init(_ capacity: Int) { self.capacity = capacity // 初始化指向 first.next = last last.prev = first } func get(_ key: Int) -> Int { guard let node = map[key] else { return -1 } // 如果取到值了 //1.先将该结点删除掉,但是map不删 removeNode(node: node) //2.就将之插入到first节点的后面 insertToFirstBehind(node: node) return node.value } func put(_ key: Int, _ value: Int) { guard let node = map[key] else { // 添加一对新的key-value if map.count == capacity { // 淘汰最近最少使用的 即删掉last节点前的那个节点,并且map也删 let needDeleteNode = map.removeValue(forKey: last.prev!.key)! removeNode(node: needDeleteNode) } // 然后添加 let node = Node(key, value) map[key] = node insertToFirstBehind(node: node) return } // 值不为空就更新下值 node.value = value removeNode(node: node) insertToFirstBehind(node: node) } private func removeNode(node: Node) { node.next?.prev = node.prev node.prev?.next = node.next } private func insertToFirstBehind(node: Node) { // node 和 first.next first.next?.prev = node node.next = first.next //node 和 first first.next = node node.prev = first } class Node { public let key: Int public var value : Int public var prev: Node? public var next: Node? init(_ key: Int, _ value: Int) { self.key = key self.value = value } } }
public class LRUCache { //【java版本】 private Map<Integer, Node> map; private int capacity; // 虚拟头结点 private Node first; // 虚拟尾结点 private Node last; public LRUCache(int capacity) { map = new HashMap<>(capacity); this.capacity = capacity; first = new Node(); last = new Node(); first.next = last; last.prev = first; } public int get(int key) { Node node = map.get(key); if (node == null) return -1; removeNode(node); addAfterFirst(node); return node.value; } /** * @param node 将node节点插入到first节点的后面 */ private void addAfterFirst(Node node) { // node与first.next node.next = first.next; first.next.prev = node; // node与first first.next = node; node.prev = first; } /** * @param node 从双向链表中删除node节点 */ private void removeNode(Node node) { node.next.prev = node.prev; node.prev.next = node.next; } public void put(int key, int value) { Node node = map.get(key); if (node != null) { node.value = value; removeNode(node); } else { // 添加一对新的key-value if (map.size() == capacity) { // 淘汰最近最少使用的node\ removeNode(map.remove(last.prev.key)); // map.remove(last.prev.key); // removeNode(last.prev); } map.put(key, node = new Node(key, value)); } addAfterFirst(node); } private static class Node { public int key; public int value; public Node prev; public Node next; public Node(int key, int value) { this.key = key; this.value = value; } public Node() {} } }
总结
今天主要讲了LRU缓存的实现思路,以及具体的代码实现。其核心就是在存取的时候完成整个LRU算法的一个运转,保持最先最少使用的被淘汰,然后一直运转下去。使用的数据结构是大家比较熟悉的字典和双向链表。希望能帮助到大家。
欢迎关注【无量测试之道】公众号,回复【领取资源】
Python编程学习资源干货、
Python+Appium框架APP的UI自动化、
Python+Selenium框架Web的UI自动化、
Python+Unittest框架API自动化、
资源和代码 免费送啦~
文章下方有公众号二维码,可直接微信扫一扫关注即可。
备注:我的个人公众号已正式开通,致力于测试技术的分享,包含:大数据测试、功能测试,测试开发,API接口自动化、测试运维、UI自动化测试等,微信搜索公众号:“无量测试之道”,或扫描下方二维码:

添加关注,让我们一起共同成长!

