

Python之Base64加解密
欢迎关注【无量测试之道】公众号,回复【领取资源】,
Python编程学习资源干货、
Python+Appium框架APP的UI自动化、
Python+Selenium框架Web的UI自动化、
Python+Unittest框架API自动化、
资源和代码 免费送啦~
文章下方有公众号二维码,可直接微信扫一扫关注即可。
1、什么是Base64
Base64是一种基于64个可打印字符来表示二进制数据的表示方法。由于2^6=64,所以每6个比特为一个单元,对应某个可打印字符。
3个字节有24个比特,对应于4个Base64单元,即3个字节可由4个可打印字符来表示。在Base64中的可打印字符包括字母A-Z、a-z、数字0-9,这样共有62个字符,此外两个可打印符号在不同的系统中而不同。
Base64模块真正用得上的方法只有8个,分别是:
encode, decode, encodestring, decodestring, b64encode, b64decode, urlsafe_b64decode, urlsafe_b64encode。
它们8个可以两两分为4组:
encode,decode一组,专门用来编码和解码文件的, 也可以对StringIO里的数据做编解码;
encodestring,decodestring一组,专门用来编码和解码字符串;
b64encode,b64decode一组,用来编码和解码字符串,并且有一个替换符号字符的功能。
这个功能是这样的:因为Base64编码后的字符除了英文字母和数字外还有三个字符' + / =',其中'='只是为了补全编码后的字符数为4的整数,而'+'和'/'在一些情况下需要被替换的,b64encode和b64decode正是提供了这样的功能。至于什么情况下'+'和'/'需要被替换,最常见的就是对url进行Base64编码的时候。
urlsafe_b64encode,urlsafe_b64decode 一组,这个就是用来专门对url进行Base64编解码的,实际上也是调用的前一组函数。
2、Base64有什么使用场景
Base64是一种任意二进制到文本字符串的编码方法,常用于在URL、Cookie、网页中传输少量二进制数据,包括MIME的电子邮件及XML的一些复杂数据。
3、base64转换过程
如下图所示:
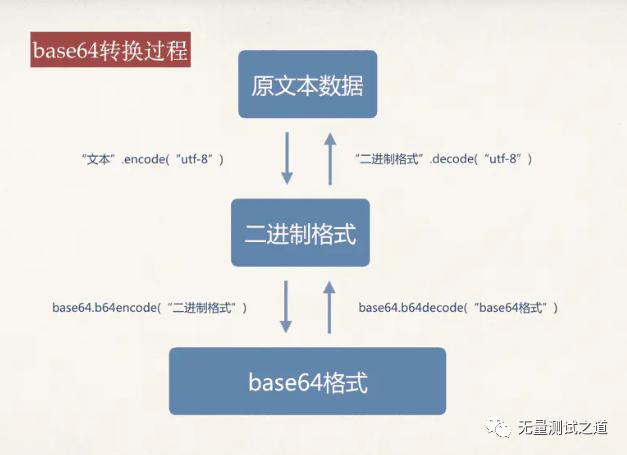
Python标准库中提供了base64模块,用来进行转换,因使用到以下二组方法,故做如下说明:
base64.b64encode()将bytes类型数据进行base64编码,返回编码后的bytes类型
base64.b64deocde()将base64编码的bytes类型进行解码,返回解码后的bytes类型
decode的作用是将其他编码的字符串转换成unicode编码
encode的作用是将unicode编码转换成其他编码的字符串
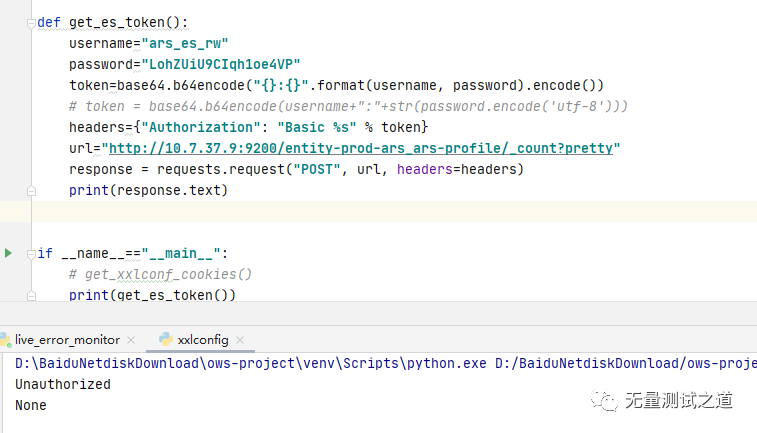
4、工作中遇到的问题
使用curl 命令可以正常的返回,如下:
tony@l-l-server1.beta.op.tx1 ~ $ curl "http://10.7.37.9:9200/entity-prod-ars_ars-profile/_count?pretty" -u'ars_es_rw:LohZUiU9CIqh1oe4VP' { "count" : 61475690, "_shards" : { "total" : 5, "successful" : 5, "skipped" : 0, "failed" : 0 } }
转换为Python的request请求时一直失败。如下图所示:
正确的处理应该是这样的:
def get_es_token(): username="ars_es_rw" password="LohZUiU9CIqh1oe4VP" token=base64.b64encode("{}:{}".format(username, password).encode()) headers = {'content-type': 'application/json',"Authorization":"Basic " + bytes.decode(token)} print(headers) url="http://10.7.37.9:9200/entity-prod-ars_ars-profile/_count?pretty" response = requests.request("POST", url, headers=headers) print(response.text)
备注:上面截图失败与下面成功的原因在于要使用bytes.decode方法将token bytes类型转换为str. 或写成:str(token,encoding=’utf8’)都可以。
简单解释下bytes是什么:
bytes 只负责以字节序列的形式(二进制形式)来存储数据,至于这些数据到底表示什么内容(字符串、数字、图片、音频等),完全由程序的解析方式决定。如果采用合适的字符编码方式(字符集),字节串可以恢复成字符串;反之亦然,字符串也可以转换成字节串。
以下是网上查的示例:
# bytes object b = b"example" # str object s = "example" # str to bytes sb = bytes(s, encoding = "utf8") # bytes to str bs = str(b, encoding = "utf8") # an alternative method # str to bytes sb2 = str.encode(s) # bytes to str bs2 = bytes.decode(b)
5、小技巧
可以看一下在Linux下的加密与解密字符串:
tony@l-l-server1.beta.op.tx1 ~ $ echo "ars_es_rw:LohZUiU9CIqh1oe4VP" | base64 YXJzX2VzX3J3OkxvaFpVaVU5Q0lxaDFvZTRWUAo= tony@l-l-server1.beta.op.tx1 ~ $ echo "YXJzX2VzX3J3OkxvaFpVaVU5Q0lxaDFvZTRWUA==" | base64 -d ars_es_rw:LohZUiU9CIqh1oe4VP
备注:我的个人公众号已正式开通,致力于测试技术的分享,包含:大数据测试、功能测试,测试开发,API接口自动化、测试运维、UI自动化测试等,微信搜索公众号:“无量测试之道”,或扫描下方二维码:
添加关注,一起共同成长吧。
