数据采集与融合技术作业2
| 学号姓名 | 102202103王文豪 |
|---|---|
| gitee仓库地址 | https://gitee.com/wwhpower/project_wwh.git |
作业①:
(1)在中国气象网(http://www.weather.com.cn)给定城市集的 7日天气预报,并保存在数据库。
代码如下:
from bs4 import BeautifulSoup
import urllib.request
import sqlite3
class WeatherDB:
def openDB(self):
self.con = sqlite3.connect("weathers.db")
self.cursor = self.con.cursor()
try:
self.cursor.execute("CREATE TABLE IF NOT EXISTS weathers (wCity varchar(16), wDate varchar(16), wWeather varchar(64), wTemp varchar(32), PRIMARY KEY (wCity, wDate))")
except Exception as err:
print(f"Database creation error: {err}")
self.cursor.execute("DELETE FROM weathers")
def closeDB(self):
self.con.commit()
self.con.close()
def insert(self, city, date, weather, temp):
try:
self.cursor.execute("INSERT INTO weathers (wCity, wDate, wWeather, wTemp) VALUES (?, ?, ?, ?)", (city, date, weather, temp))
except Exception as err:
print(f"Error inserting data: {err}")
def show(self):
self.cursor.execute("SELECT * FROM weathers")
rows = self.cursor.fetchall()
print("%-16s%-16s%-32s%-16s" % ("city", "date", "weather", "temp"))
for row in rows:
print("%-16s%-16s%-32s%-16s" % (row[0], row[1], row[2], row[3]))
class WeatherForecast:
def __init__(self):
self.headers = {
"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"
}
self.cityCode = {"北京": "101010100"}
def forecastCity(self, city):
if city not in self.cityCode.keys():
print(f"{city} code cannot be found")
return
url = f"http://www.weather.com.cn/weather/{self.cityCode[city]}.shtml"
try:
req = urllib.request.Request(url, headers=self.headers)
with urllib.request.urlopen(req) as response:
data = response.read()
soup = BeautifulSoup(data, "lxml")
lis = soup.select("ul[class='t clearfix'] li")
for li in lis:
try:
date = li.select('h1')[0].text
weather = li.select('p[class="wea"]')[0].text
temp = li.select('p[class="tem"] span')[0].text + "/" + li.select('p[class="tem"] i')[0].text
print(city, date, weather, temp)
self.db.insert(city, date, weather, temp)
except Exception as err:
print(f"Error parsing data: {err}")
except Exception as err:
print(f"Error fetching data for {city}: {err}")
def process(self, cities):
self.db = WeatherDB()
self.db.openDB()
for city in cities:
self.forecastCity(city)
self.db.show()
self.db.closeDB()
ws = WeatherForecast()
ws.process(["北京"])
print("completed")
爬取图片如下:
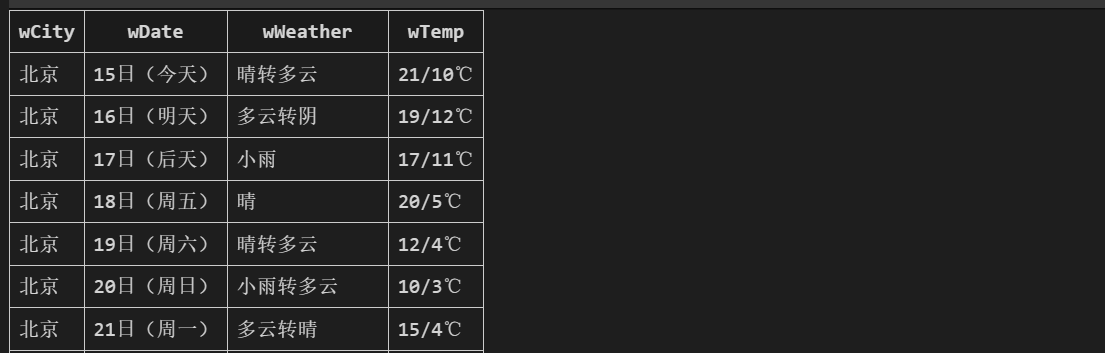
(2)心得体会
在实验中,我通过运用 BeautifulSoup 库对 HTML 文档进行解析,同时对网页结构进行分析,加强了我对于元素以及标签的提取能力。数据库创建及使用对数据进行存储,增强了我对于数据的储存管理能力。
作业②:
(1)用 requests 和 BeautifulSoup 库方法定向爬取股票相关信息,并存储在数据库中。
抓包:
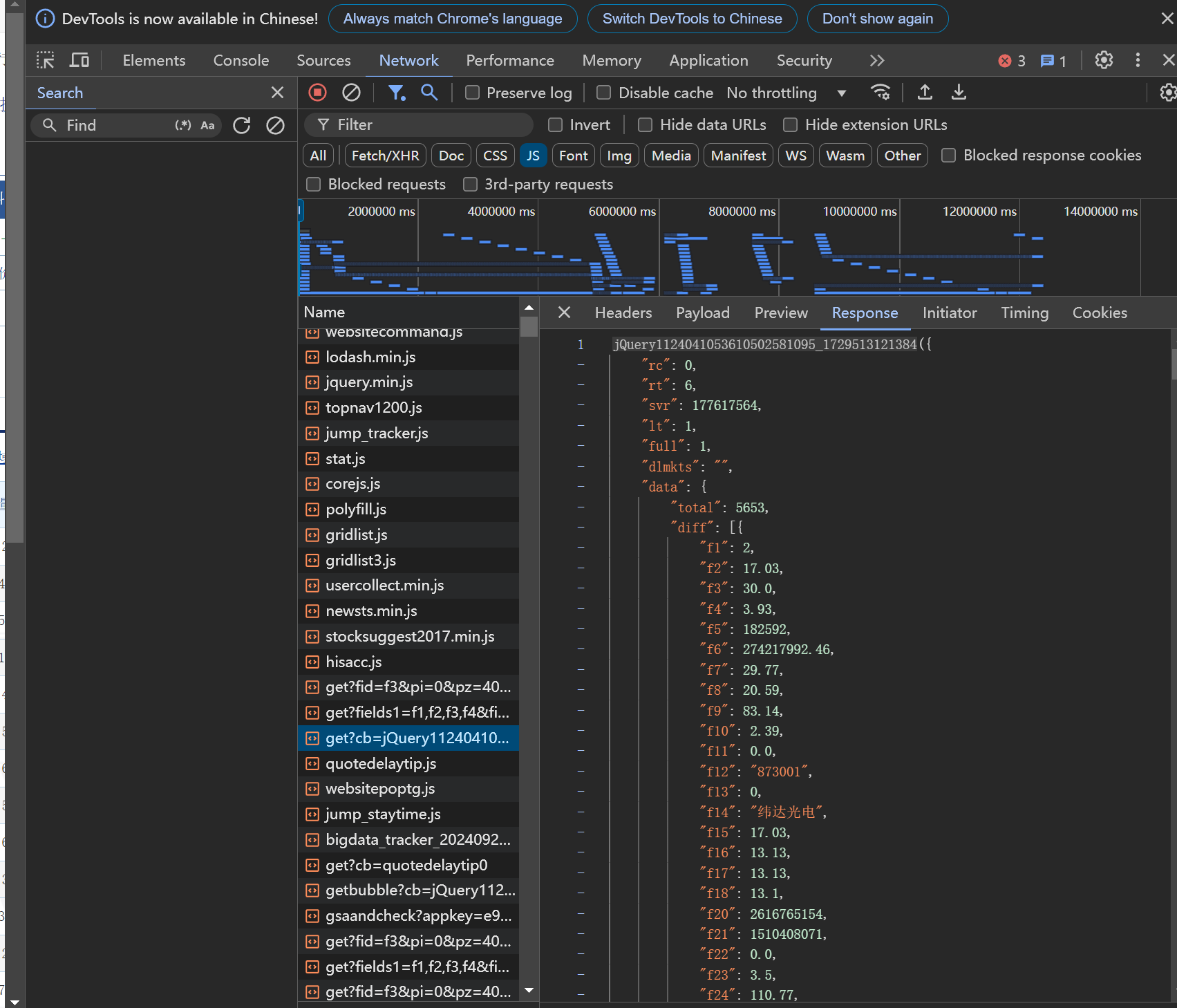
代码如下:
import requests
import json
import sqlite3
class StockDB:
"""数据库操作类"""
def __init__(self, db_name='stock.db'):
self.db_name = db_name
def openDB(self):
"""打开数据库"""
self.conn = sqlite3.connect(self.db_name)
self.cursor = self.conn.cursor()
self.cursor.execute('''
CREATE TABLE IF NOT EXISTS stocks (
id INTEGER PRIMARY KEY AUTOINCREMENT,
code TEXT NOT NULL,
name TEXT NOT NULL,
current_price REAL NOT NULL,
open_price REAL,
high_price REAL,
low_price REAL,
pre_close_price REAL,
change REAL,
change_rate REAL,
volume REAL,
amount REAL,
流通股本 REAL,
流通市值 REAL,
总股本 REAL,
总市值 REAL
)
''')
def insert(self, stock_data):
"""插入一条股票数据"""
self.cursor.execute('''
INSERT INTO stocks (code, name, current_price, open_price, high_price, low_price, pre_close_price, change, change_rate, volume, amount, 流通股本, 流通市值, 总股本, 总市值)
VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)
''', (
stock_data['f12'], # 股票代码
stock_data['f14'], # 股票名称
stock_data['f2'], # 当前价
stock_data['f3'], # 开盘价
stock_data['f4'], # 最高价
stock_data['f5'], # 最低价
stock_data['f6'], # 昨收价
stock_data['f7'], # 涨跌(元)
stock_data['f8'], # 涨跌幅(%)
stock_data['f15'], # 成交量(手)
stock_data['f16'], # 成交金额(万元)
stock_data['f17'], # 流通股本(亿股)
stock_data['f18'], # 流通市值(亿元)
stock_data['f10'], # 总股本(亿股)
stock_data['f9'] # 总市值(亿元)
))
self.conn.commit()
def show(self):
"""展示所有股票数据"""
self.cursor.execute('SELECT * FROM stocks')
stocks = self.cursor.fetchall()
for stock in stocks:
print(stock)
def closeDB(self):
"""关闭数据库"""
self.conn.close()
class StockCrawler:
def __init__(self):
self.headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/129.0.0.0 Safari/537.36',
'cookie': 'qgqp_b_id=676cc891cb84acdefca65212ca97d62c; st_si=15061432798499; st_pvi=12986909889368; st_sp=2024-10-15%2017%3A24%3A20; st_inirUrl=; st_sn=1; st_psi=20241021201829620-113200301321-6882775284; st_asi=delete'
}
def crawl_stocks(self):
searchlist = [1] # 假设我们只爬取第一页的数据
db = StockDB()
db.openDB()
for page in searchlist:
response = requests.get(url='https://62.push2.eastmoney.com/api/qt/clist/get?cb=jQuery1124041053610502581095_1729513121384&pn=1&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&dect=1&wbp2u=|0|0|0|web&fid=f3&fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23,m:0+t:81+s:2048&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1729513121385', params={
'cb': 'jQuery1124041053610502581095_1729513121384',
'pn': page,
'pz': 20,
'po': 1,
'np': 1,
'ut': 'bd1d9ddb04089700cf9c27f6f7426281',
'fltt': 2,
'invt': 2,
'wbp2u': '|0|0|0|web',
'fid': 'f3',
'fs': 'm:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23,m:0+t:81+s:2048',
'fields': 'f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152',
'_': '1729513121384'
}, headers=self.headers)
data = response.text[response.text.find('(') + 1:response.text.rfind(')')]
data = json.loads(data)
for stock_data in data['data']['diff']:
db.insert(stock_data)
db.show()
db.closeDB()
def process(self):
self.crawl_stocks()
# 使用
crawler = StockCrawler()
crawler.process()
爬取图片如下:
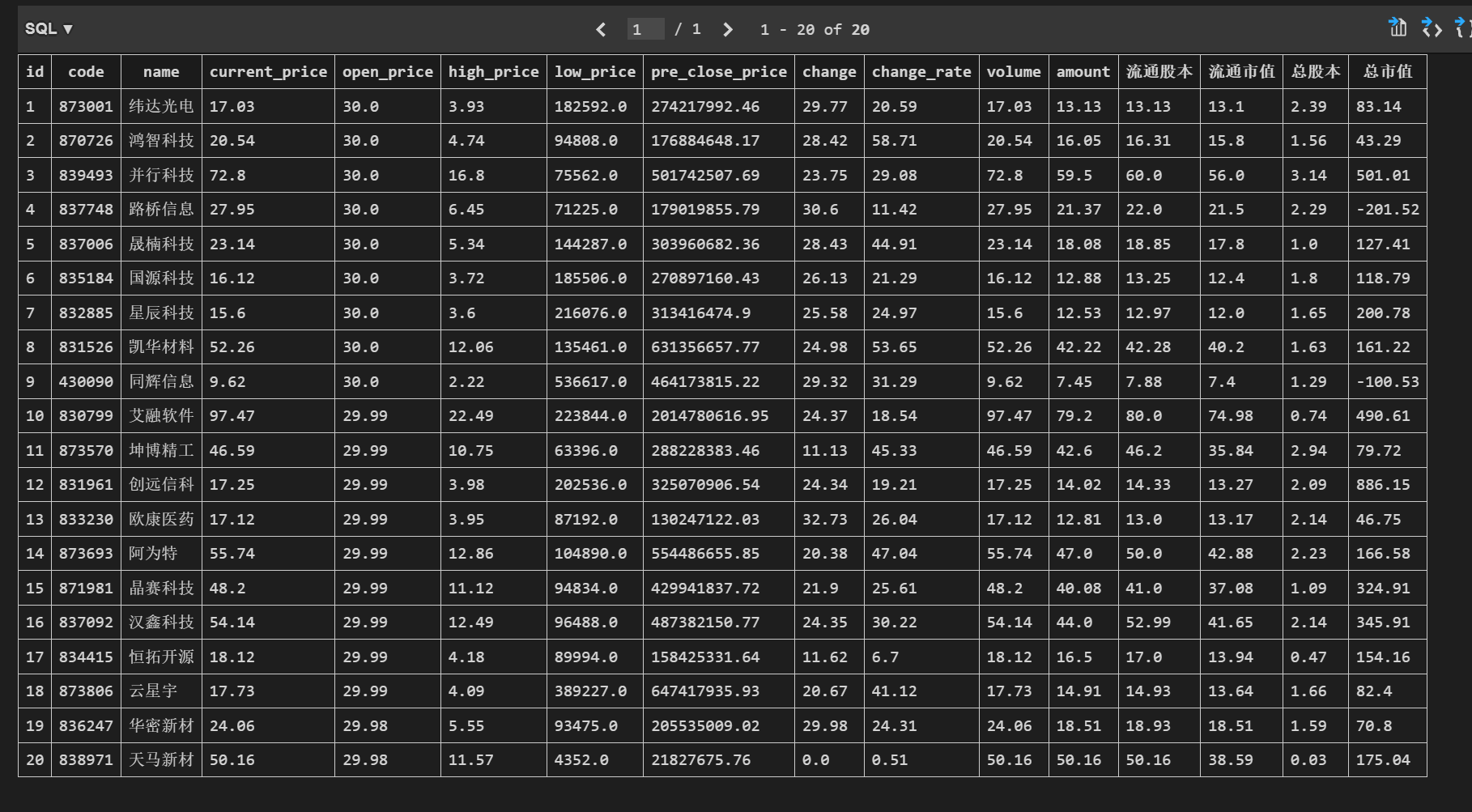
(2)心得体会
通过抓包,我可以观察到网页加载数据时的完整请求和响应过程,包括请求的URL、请求方法(GET、POST等)、请求头、请求参数以及服务器的响应内容。同时可以查看API请求的参数(如f1、f2等)和服务器返回的数据格式(通常是JSON、XML等),有助于我理解API的工作方式和数据结构。
作业③:
(1)爬取中国大学 2021 主榜(https://www.shanghairanking.cn/rankings/bcur/2021)所有院校信息,并存储在数据库中,同时将浏览器 F12 调试分析的过程录制 Gif 加
入至博客中。
调试的GIF:
代码如下:
import requests
import re
import sqlite3
# 创建数据库和表的函数
def create_database():
conn = sqlite3.connect('university.db') # 连接到SQLite数据库
cursor = conn.cursor()
cursor.execute('''
CREATE TABLE IF NOT EXISTS uni (
排名 TEXT PRIMARY KEY, # 排名作为主键
学校名称 TEXT, # 学校名称
省市 TEXT, # 学校所在的省市
学校类型 TEXT, # 学校类型
总分 TEXT # 学校的总分
)
''')
conn.commit() # 提交创建表的操作
return conn, cursor
# 从URL获取大学数据的函数
def fetch_university_data(url):
try:
response = requests.get(url) # 发送GET请求
response.raise_for_status() # 检查请求是否成功
return response.text # 返回响应的文本内容
except requests.RequestException as e:
print(f"获取数据时出错:{e}") # 打印错误信息
return None
# 解析大学数据的函数
def parse_university_data(text):
universities = [] # 初始化一个空列表来存储大学数据
# 使用正则表达式提取信息
names = re.findall(r',univNameCn:"(.*?)",', text)
scores = re.findall(r',score:(.*?),', text)
categories = re.findall(r',univCategory:(.*?),', text)
provinces = re.findall(r',province:(.*?),', text)
# 提取城市和类型的编码和值
code_segments = re.findall(r'function(.*?){', text)
if code_segments:
code = code_segments[0]
start_index = code.find('a')
end_index = code.find('pE')
code_names = code[start_index:end_index].split(',')
value_segments = re.findall(r'mutations:(.*?);', text)
if value_segments:
values = value_segments[0]
start_value = values.find('(') + 1
end_value = values.find(')')
value_names = values[start_value:end_value].split(",")
# 构建大学数据列表
for i in range(len(names)):
province_name = value_names[code_names.index(provinces[i])][1:-1]
category_name = value_names[code_names.index(categories[i])][1:-1]
universities.append((i + 1, names[i], province_name, category_name, scores[i]))
return universities
# 将大学数据插入数据库的函数
def insert_universities(cursor, universities):
for university in universities:
cursor.execute(
"INSERT INTO uni(排名, 学校名称, 省市, 学校类型, 总分) VALUES (?, ?, ?, ?, ?)",
(university[0], university[1], university[2], university[3], university[4])
)
# 主函数
def main():
# 创建数据库和表
conn, cursor = create_database()
url = "https://www.shanghairanking.cn/_nuxt/static/1728872418/rankings/bcur/2021/payload.js" # URL
# 获取数据
data_text = fetch_university_data(url)
if data_text:
# 解析大学数据
universities = parse_university_data(data_text)
# 将数据插入数据库
insert_universities(cursor, universities)
# 提交更改并关闭数据库连接
conn.commit()
conn.close()
if __name__ == "__main__":
main()
爬取图片如下:
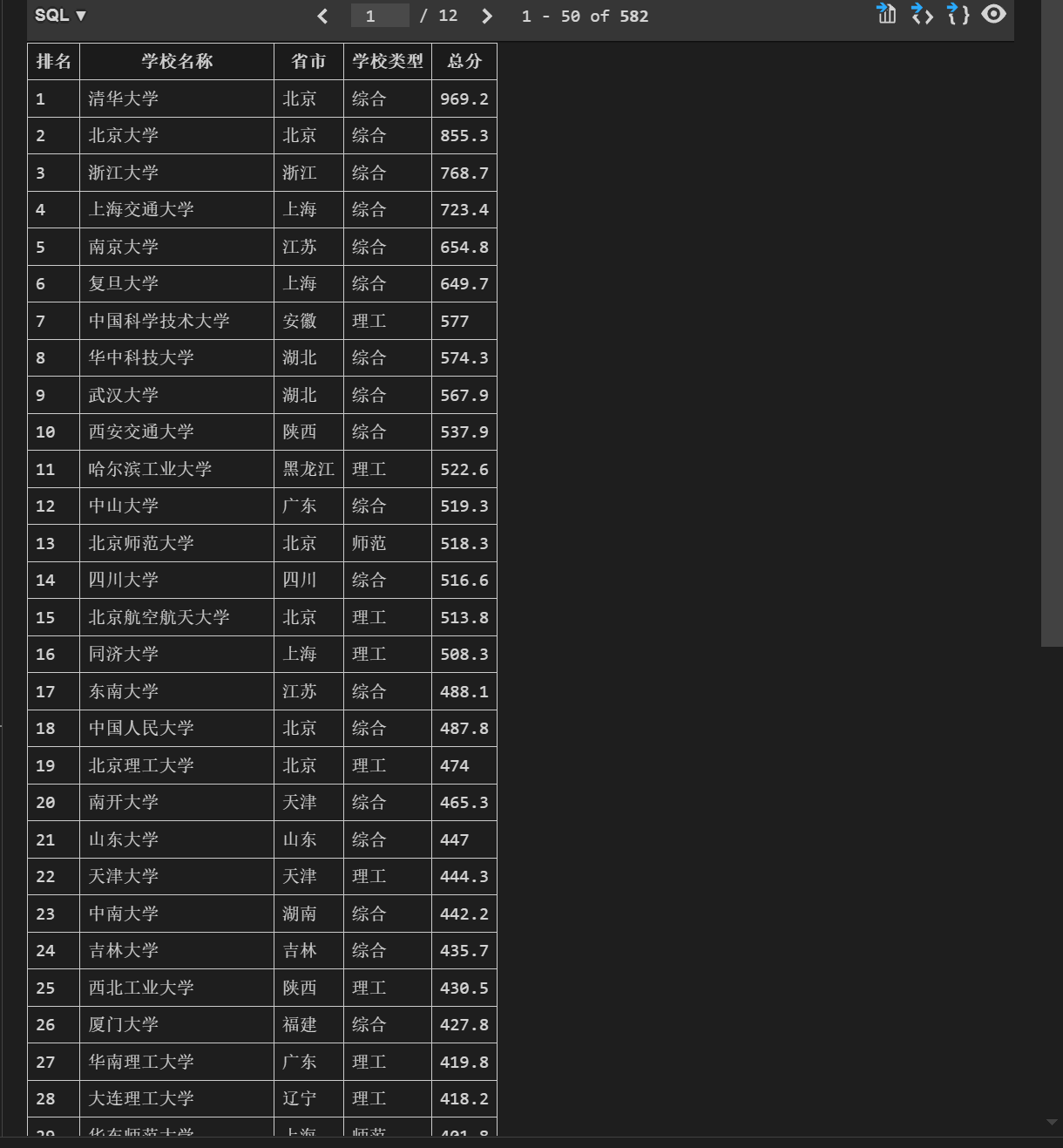
(2)心得体会
通过本次爬取项目,我深刻体会到了数据抓取的复杂性与趣味性。在实践中,我不仅提升了编程能力,也增强了对网页结构的理解。在爬取过程中,使用 F12 工具调试是必不可少的。通过查看网页的 Network 和 Elements 标签,我能够实时监控请求与响应的内容,从而确保数据抓取的准确性。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号