数据采集与融合技术作业1
| 学号姓名 | 102202103王文豪 |
|---|---|
| gitee仓库地址 | https://gitee.com/wwhpower/project_wwh.git |
作业①:
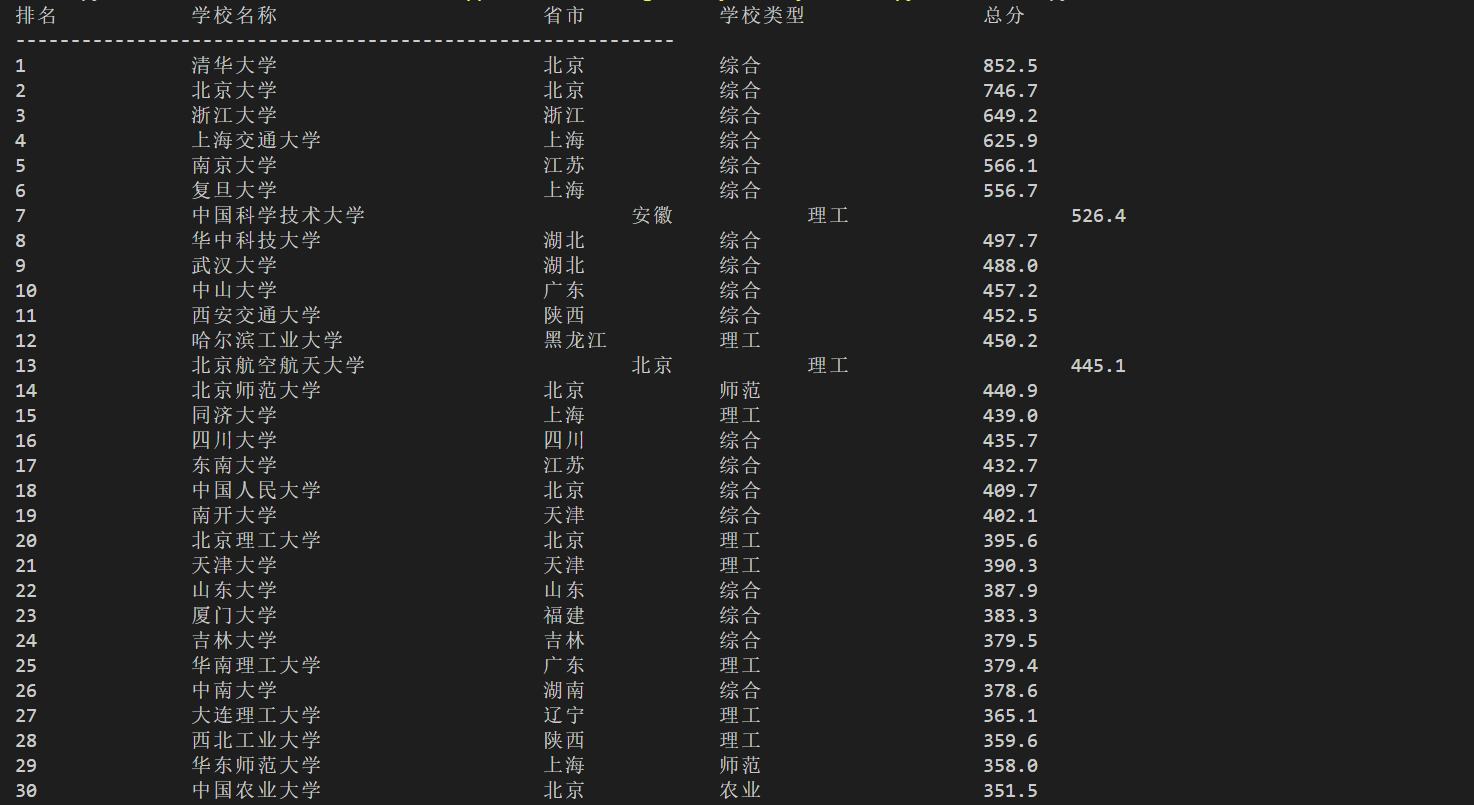
(1)用requests和BeautifulSoup库方法定向爬取给定网址(http://www.shanghairanking.cn/rankings/bcur/2020 )的数据,屏幕打印爬取的大学排名信息。
代码如下:
import urllib.request
from bs4 import BeautifulSoup
import re
# 目标网址
url = "http://www.shanghairanking.cn/rankings/bcur/2020"
# 使用 urllib 请求网页内容
response = urllib.request.urlopen(url)
html_content = response.read()
# 使用 BeautifulSoup 解析 HTML
soup = BeautifulSoup(html_content, 'html.parser')
# 找到包含排名信息的表格
table = soup.find('table')
# 打印标题
print("排名\t\t学校名称\t\t\t省市\t\t学校类型\t\t总分")
print("-" * 60) # 打印分隔线
# 遍历表格的每一行
for row in table.find_all('tr')[1:]: # 跳过标题行
# 提取每行的数据
cols = row.find_all('td')
rank = cols[0].text.strip()
# 获取学校名称的中文部分
school_name_full = cols[1].get_text(strip=True, separator=" ")
# 使用正则表达式匹配中文字符
school_name = re.search(r'[\u4e00-\u9fa5]+', school_name_full)
school_name = school_name.group(0) if school_name else "未知"
province = cols[2].text.strip()
school_type = cols[3].text.strip()
total_score = cols[4].text.strip()
# 打印提取的信息,使用格式化字符串确保排列工整
print(f"{rank}\t\t{school_name}\t\t\t{province}\t\t{school_type}\t\t\t{total_score}")
爬取图片如下:
(2)
由于在之前的作业中已经做过,相当于在复习一遍用requests和BeautifulSoup库方法。
作业②:
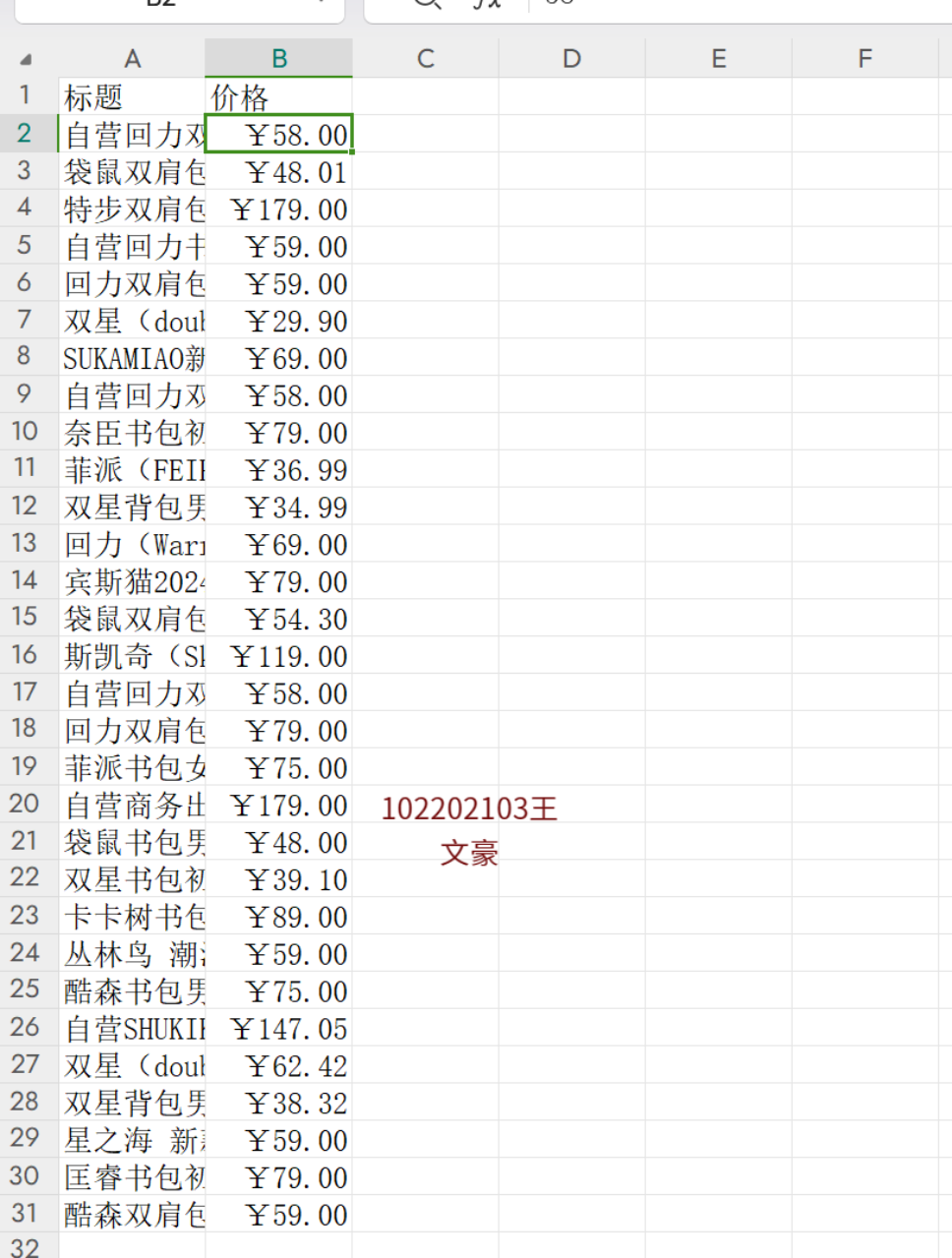
(1)用requests和re库方法设计某个商城(自已选择)商品比价定向爬虫,爬取该商城,以关键词“书包”搜索页面的数据,爬取商品名称和价格。
代码如下:
import requests
from bs4 import BeautifulSoup
import csv
import time
import random
import re
# 指定输出文件名称
filename = 'jd.csv'
fieldnames = ['标题', '价格']
# 创建一个 DictWriter 对象
with open(filename, 'w', newline='', encoding='utf-8') as csvfile:
csvwriter = csv.DictWriter(csvfile, fieldnames=fieldnames)
csvwriter.writeheader()
# 京东搜索书包的URL
for page in range(1, 2):
print("=" * 10 + f'正在爬取第{page}页' + '=' * 10)
url = f'https://search.jd.com/Search?keyword=%E4%B9%A6%E5%8C%85&enc=utf-8&suggest=1.his.0.0&wq=&pvid=ab451a85d5ba4840a146605c06b45f25' # 示例URL,请根据实际情况调整
time.sleep(random.randint(1, 4))
# 发送请求
headers = {
'Cookie': '__jdv=76161171|baidu-pinzhuan|t_288551095_baidupinzhuan|cpc|0f3d30c8dba7459bb52f2eb5eba8ac7d_0_2f47caf1ebc348caacea7fd7e71289ef|1727243836390; __jdu=1727243836389628243500; 3AB9D23F7A4B3CSS=jdd034BF62SYQY7T3F4K2R2QMM5CRDT2AEYCETU374RMOY44NJSJSUSZNKINLL7JJJ3IRFI5KWW6YRE6CI4TLMAP4BRQTQYAAAAMSE7AVZOYAAAAACQLNDKC47MHVT4X; _gia_d=1; areaId=16; ipLoc-djd=16-1303-0-0; PCSYCityID=CN_350000_350100_0; shshshfpa=18ea115c-97e2-e021-5fe6-9ee56d126924-1727243838; shshshfpx=18ea115c-97e2-e021-5fe6-9ee56d126924-1727243838; jsavif=1; jsavif=1; xapieid=jdd034BF62SYQY7T3F4K2R2QMM5CRDT2AEYCETU374RMOY44NJSJSUSZNKINLL7JJJ3IRFI5KWW6YRE6CI4TLMAP4BRQTQYAAAAMSE7AVZOYAAAAACQLNDKC47MHVT4X; rkv=1.0; TrackID=1jBwr9xs86GCgRpyrHJEsDNz7rVcsYso_9AvgU4b_DO2VK8uNlW1EjYyrVo61mhpyemQ7y3pUl8eHSMWqbJcYY1CiQLiykeNbqHzwaF3y0Z0; thor=0E6422EDA016390BE69CC11C7EBBFAF93C80C4B8C0F396BD0DC5ABDCD6C8059DCBCE32AF3B20160B8FB11E18DF1A9355AF7412F11ED3AC1BD4A54F4F1690F76393C621A7F749CCDABE13FAAD0019C45C9AEA0365BD1640E6C8AACAC6858A9BC83372E43F3BDC5E6ABFE75418121F2034D150C1F0E3674397FF5B6831ECCC32A67FA52D662941A83B64B45711D8E58B74BC4617445F54E783565D26E54419C735; flash=3_ELysEHEcYLzVDlQ766c6YjiqwXndaVFVCF9uiqwkbH-VrzyXdPoViPDoX6F-JVgXvmaei7fI1BW-Zx13VSi7vdh_VdoQaI76WIbN4HoZt6yi6FV1EqYo4rYDxT3NMeED4GED5OcgvBQjjmxzXBOoAofvbd7v0Glw0RJwNzVp50ihr3ZEFQwq; light_key=AASBKE7rOxgWQziEhC_QY6yaUbk49n_bE7JwnX6wOi3YIrGuKedxeroC4Lxpr1ffbK0r9q73; pinId=lRS9izMua2qysrT7q0Oo4Q; pin=jd_bkLMYQtTZhmp; unick=jd_3rkvppvjv6e414; ceshi3.com=000; _tp=WmtyKtWSXJFfP85voo8uKg%3D%3D; _pst=jd_bkLMYQtTZhmp; avif=1; qrsc=2; 3AB9D23F7A4B3C9B=4BF62SYQY7T3F4K2R2QMM5CRDT2AEYCETU374RMOY44NJSJSUSZNKINLL7JJJ3IRFI5KWW6YRE6CI4TLMAP4BRQTQY; __jda=76161171.1727243836389628243500.1727243836.1727243836.1727243836.1; __jdb=76161171.5.1727243836389628243500|1.1727243836; __jdc=76161171; shshshfpb=BApXSzu_KJPdAHL9MZaUOle0v95LW1Nj-BmVlPxdo9xJ1MoKd7oC2', # 请填写您的淘宝Cookie
'Referer': 'https://www.jd.com/',
'Sec-Ch-Ua':'"Google Chrome";v="129", "Not=A?Brand";v="8", "Chromium";v="129"',
'Sec-Ch-Ua-Mobile':'?0',
'Sec-Ch-Ua-Platform':'"Windows"',
'Sec-Fetch-Dest':'document',
'Sec-Fetch-Mode':'navigate',
'Sec-Fetch-Site':'same-site',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/129.0.0.0 Safari/537.36'
}
res = requests.get(url=url, headers=headers)
# 检查请求是否成功
if res.status_code == 200:
soup = BeautifulSoup(res.text, 'html.parser')
# 商品信息
items = soup.find_all('li', class_='gl-item')
for item in items:
title = item.find('div', class_='p-name p-name-type-2').get_text(strip=True)
price = item.find('div', class_='p-price').get_text(strip=True)
# 写入CSV文件
csvwriter.writerow({'标题': title, '价格': price})
else:
print(f"请求失败,状态码:{res.status_code}")
print("爬取完成!")
爬取的图片:
(2)作业心得
由于在之前的作业中已经做过,相当于在复习一遍用requests和BeautifulSoup库方法。
作业③:
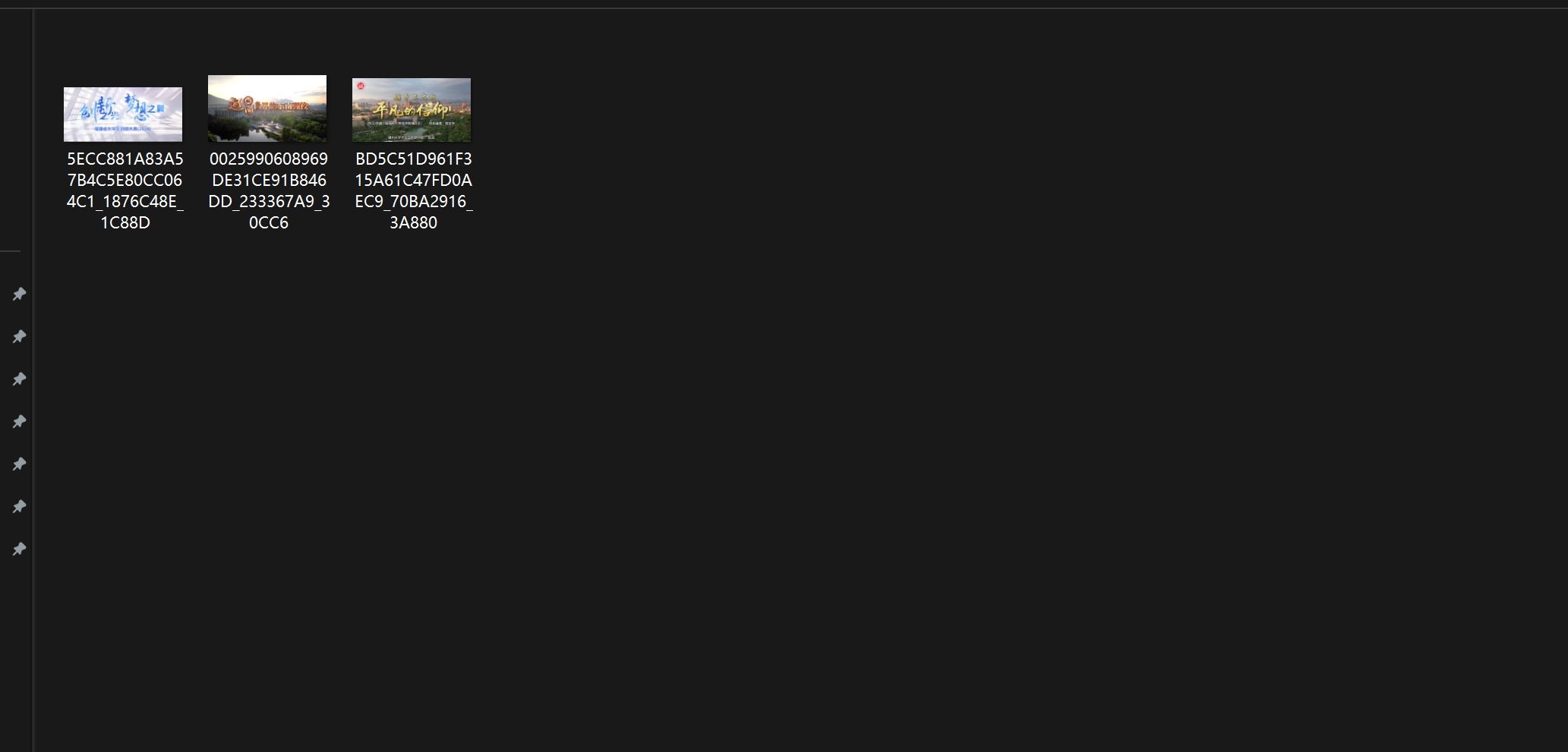
(1)爬取一个给定网页( https://xcb.fzu.edu.cn/info/1071/4481.htm)或者自选网页的所有JPEG和JPG格式文件
代码如下:
import os
import requests
from bs4 import BeautifulSoup
from urllib.parse import urljoin
import re
def clean_filename(filename):
# 移除文件名中不允许的字符
return re.sub(r'[\\/*?:"<>|]', '', filename)
def download_images(url, folder_name):
# 发送HTTP请求
response = requests.get(url)
response.encoding = 'utf-8'
# 解析HTML内容
soup = BeautifulSoup(response.text, 'html.parser')
# 创建一个文件夹来保存图片
if not os.path.exists(folder_name):
os.makedirs(folder_name)
# 找到所有图片标签
img_tags = soup.find_all('img')
# 下载并保存图片
for img in img_tags:
img_url = img.get('src')
if img_url:
# 确保图片格式为JPEG或JPG
if img_url.lower().endswith(('.jpg', '.jpeg')):
# 将相对路径转换为完整的URL
full_img_url = urljoin(url, img_url)
try:
img_data = requests.get(full_img_url).content
file_name = clean_filename(full_img_url.split('/')[-1])
file_path = os.path.join(folder_name, file_name)
with open(file_path, 'wb') as file:
file.write(img_data)
print(f'图片已保存:{file_path}')
except requests.exceptions.RequestException as e:
print(f'无法下载图片:{full_img_url},错误信息:{e}')
# 目标网页URL
url = 'https://news.fzu.edu.cn/yxfd.htm'
folder_name = 'downloaded_images'
download_images(url, folder_name)
爬取的图片:
(2)作业心得
我需要找到图片所拥有的"img"标签,找到它的url链接,同时确保爬取的图片是jpg与jpeg格式,下载到文件夹中。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号