ElasticSearch
ElasticSearch是什么
Elaticsearch,简称为es, es是一个开源的高扩展的分布式全文检索引擎,它可以近乎实时的存储、检索数据;本
身扩展性很好,可以扩展到上百台服务器,处理PB级别的数据。es也使用Java开发并使用Lucene作为其核心来实
现所有索引和搜索的功能,但是它的目的是通过简单的RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得
简单。
ElasticSearch和Solr
- Solr 利用 Zookeeper 进行分布式管理,而 Elasticsearch 自身带有分布式协调管理功能;
- Solr 支持更多格式的数据,而 Elasticsearch 仅支持json文件格式;
- Solr 官方提供的功能更多,而 Elasticsearch 本身更注重于核心功能,高级功能多有第三方插件提供;
- Solr 在传统的搜索应用中表现好于 Elasticsearch,但在处理实时搜索应用时效率明显低于 Elasticsearch
ElasticSearch的安装和启动
下载es的安装包
ElasticSearch分为Linux和Window版本 ,ElasticSearch的官方地址: https://www.elastic.co/products/elasticsearch
安装Win版es服务
Window版的ElasticSearch的安装很简单,类似Window版的Tomcat,解压开即安装完毕,解压后的ElasticSearch
的目录结构如下:

启动ES服务
点击ElasticSearch下的bin目录下的elasticsearch.bat启动,控制台显示的日志信息如下:
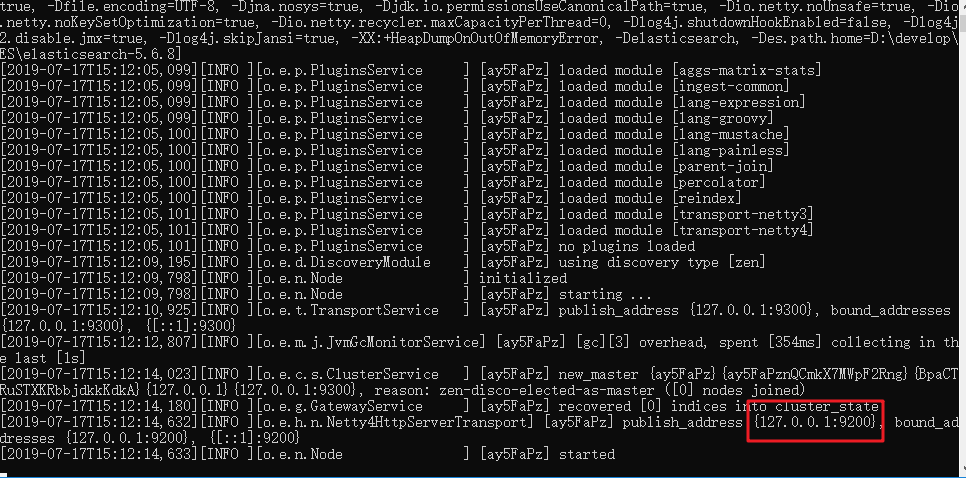
可以看到绑定了两个端口: - 9300:集群节点间通讯接口,接收tcp协议 - 9200:客户端访问接口,接收Http协议
注意:
修改 config/jvm.options
把内存改为1g
通过浏览器访问ElasticSearch服务器,看到如下返回的json信息,代表服务启动成功

注意:ElasticSearch是使用java开发的,且本版本的es需要的jdk版本要是1.8以上,所以安装ElasticSearch
之前保证JDK1.8+安装完毕,并正确的配置好JDK环境变量,否则启动ElasticSearch失败。
安装ES的图形化界面插件
ElasticSearch不同于Solr自带图形化界面,我们可以通过安装ElasticSearch的head插件,完成图形化界面的效果,
完成索引数据的查看。安装插件的方式有两种,在线安装和本地安装。本文档采用本地安装方式进行head插件的
安装。elasticsearch-5-*以上版本安装head需要安装node和grunt
1.安装图形化界面head插件
下载head插件:https://github.com/mobz/elasticsearch-head
解压elasticsearch-head-master.zip到任意目录,但是要和elasticsearch的安装目录区别开
2.安装nodejs程序
https://nodejs.org/en/download/
node-v8.9.4-x64.msi
3.安装head依赖,将grunt安装为全局命令 ,Grunt是基于Node.js的项目构建工具
cmd控制台中输入: npm install -g grunt-cli
cmd进入到head目录中执行 npm install
4.修改elasticsearch配置文件:elasticsearch.yml,增加以下两句命令:
http.cors.enabled: true http.cors.allow-origin: "*"
此步为允许elasticsearch跨越访问
5.进入head目录启动head,在命令提示符下输入命令:
grunt server 注:每次使用都要执行
为了方便我们可以在head目录下创建文本文档输入:grunt server 把它文件名及类型改为head.bat
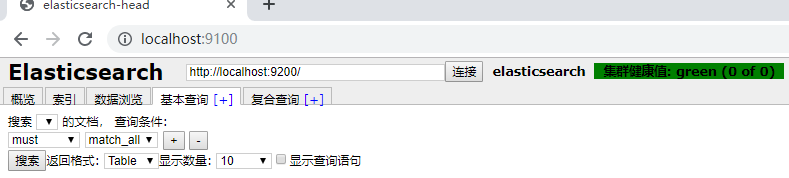
6.打开浏览器,输入 http://localhost:9100,看到如下页面:
扩展:测试集群
继续安装一个ES(解压即可)-->修改内存-->允许跨域-->全部重启-->测试
ElasticSearch概述
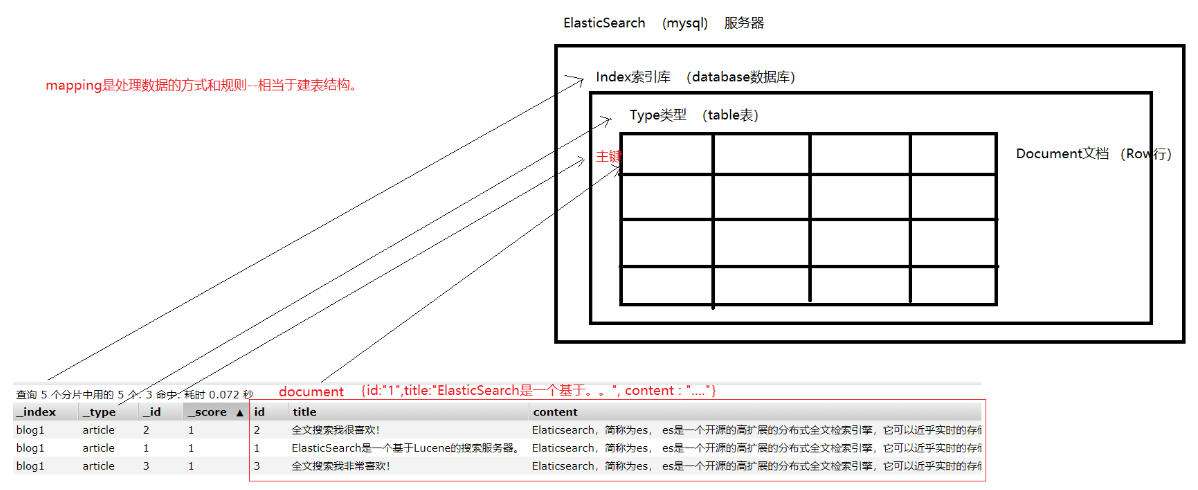
Elasticsearch是面向文档(document oriented)的,这意味着它可以存储整个对象或文档(document)。然而它不仅
仅是存储,还会索引(index)每个文档的内容使之可以被搜索。在Elasticsearch中,你可以对文档(而非成行成列的
数据)进行索引、搜索、排序、过滤。ES比传统关系型数据库,就像如下:
Relational DB -> Databases -> Tables -> Rows -> Columns
Elasticsearch -> Indices -> Types -> Documents -> Fields
ElasticSearch核心概念
接近实时NRT
Elasticsearch是一个接近实时的搜索平台。这意味着,从索引一个文档直到这个文档能够被搜索到有一个轻微的延
迟(通常是1秒以内)
集群cluster
一个集群就是由一个或多个节点组织在一起,它们共同持有整个的数据,并一起提供索引和搜索功能。一个集群由
一个唯一的名字标识,这个名字默认就是“elasticsearch”。这个名字是重要的,因为一个节点只能通过指定某个集
群的名字,来加入这个集群
节点node
一个节点是集群中的一个服务器,作为集群的一部分,它存储数据,参与集群的索引和搜索功能。和集群类似,一
个节点也是由一个名字来标识的,默认情况下,这个名字是一个随机的漫威漫画角色的名字,这个名字会在启动的
时候赋予节点。这个名字对于管理工作来说挺重要的,因为在这个管理过程中,你会去确定网络中的哪些服务器对
应于Elasticsearch集群中的哪些节点。
一个节点可以通过配置集群名称的方式来加入一个指定的集群。默认情况下,每个节点都会被安排加入到一个叫
做“elasticsearch”的集群中,这意味着,如果你在你的网络中启动了若干个节点,并假定它们能够相互发现彼此,
它们将会自动地形成并加入到一个叫做“elasticsearch”的集群中。
在一个集群里,只要你想,可以拥有任意多个节点。而且,如果当前你的网络中没有运行任何Elasticsearch节点,
这时启动一个节点,会默认创建并加入一个叫做“elasticsearch”的集群。
索引index
一个索引就是一个拥有几分相似特征的文档的集合。比如说,你可以有一个客户数据的索引,另一个产品目录的索
引,还有一个订单数据的索引。一个索引由一个名字来标识(必须全部是小写字母的),并且当我们要对对应于这
个索引中的文档进行索引、搜索、更新和删除的时候,都要使用到这个名字。在一个集群中,可以定义任意多的索
引
类型type
在一个索引中,你可以定义一种或多种类型。一个类型是你的索引的一个逻辑上的分类/分区,其语义完全由你来
定。通常,会为具有一组共同字段的文档定义一个类型。比如说,我们假设你运营一个博客平台并且将你所有的数
据存储到一个索引中。在这个索引中,你可以为用户数据定义一个类型,为博客数据定义另一个类型,当然,也可
以为评论数据定义另一个类型。
文档document
一个文档是一个可被索引的基础信息单元。比如,你可以拥有某一个客户的文档,某一个产品的一个文档,当然, 也可以拥有某个订单的一个文档。文档以JSON(Javascript Object Notation)格式来表示,而JSON是一个到处存 在的互联网数据交互格式。 在一个index/type里面,你可以存储任意多的文档。注意,尽管一个文档,物理上存在于一个索引之中,文档必须 被索引/赋予一个索引的type。
分片和复制 shards&replicas
一个索引可以存储超出单个结点硬件限制的大量数据。比如,一个具有10亿文档的索引占据1TB的磁盘空间,而任 一节点都没有这样大的磁盘空间;或者单个节点处理搜索请求,响应太慢。为了解决这个问题,Elasticsearch提供 了将索引划分成多份的能力,这些份就叫做分片。当你创建一个索引的时候,你可以指定你想要的分片的数量。每 个分片本身也是一个功能完善并且独立的“索引”,这个“索引”可以被放置到集群中的任何节点上。分片很重要,主 要有两方面的原因: 1)允许你水平分割/扩展你的内容容量。 2)允许你在分片(潜在地,位于多个节点上)之上 进行分布式的、并行的操作,进而提高性能/吞吐量。 至于一个分片怎样分布,它的文档怎样聚合回搜索请求,是完全由Elasticsearch管理的,对于作为用户的你来说, 这些都是透明的。 在一个网络/云的环境里,失败随时都可能发生,在某个分片/节点不知怎么的就处于离线状态,或者由于任何原因 消失了,这种情况下,有一个故障转移机制是非常有用并且是强烈推荐的。为此目的,Elasticsearch允许你创建分 片的一份或多份拷贝,这些拷贝叫做复制分片,或者直接叫复制。
复制之所以重要,有两个主要原因: 在分片/节点失败的情况下,提供了高可用性。因为这个原因,注意到复制分 片从不与原/主要(original/primary)分片置于同一节点上是非常重要的。扩展你的搜索量/吞吐量,因为搜索可以 在所有的复制上并行运行。总之,每个索引可以被分成多个分片。一个索引也可以被复制0次(意思是没有复制) 或多次。一旦复制了,每个索引就有了主分片(作为复制源的原来的分片)和复制分片(主分片的拷贝)之别。分 片和复制的数量可以在索引创建的时候指定。在索引创建之后,你可以在任何时候动态地改变复制的数量,但是你 事后不能改变分片的数量。 默认情况下,Elasticsearch中的每个索引被分片5个主分片和1个复制,这意味着,如果你的集群中至少有两个节 点,你的索引将会有5个主分片和另外5个复制分片(1个完全拷贝),这样的话每个索引总共就有10个分片
映射mapping
mapping是处理数据的方式和规则方面做一些限制,如某个字段的数据类型、默认值、分析器、是否被索引等等,
这些都是映射里面可以设置的,其它就是处理es里面数据的一些使用规则设置也叫做映射,按着最优规则处理数据
对性能提高很大,因此才需要建立映射,并且需要思考如何建立映射才能对性能更好?和建立表结构表关系数据库
三范式类似。
ElasticSearch操作入门
创建maven工程
引入坐标
<dependencies>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>5.6.8</version>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>transport</artifactId>
<version>5.6.8</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-to-slf4j</artifactId>
<version>2.9.1</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.24</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-simple</artifactId>
<version>1.7.21</version>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.12</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.10</version>
</dependency>
</dependencies>
新建索引
@Test//创建索引库及添加文档 public void test1() throws Exception { //1.创建客户端访问对象 TransportClient client=new PreBuiltTransportClient(Settings.EMPTY) .addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("127.0.0.1"),9300)); //2.创建文档 //{id:"1",title:"xxx",content:"xxxxxx"} XContentBuilder builder= XContentFactory.jsonBuilder() .startObject() .field("id","1") .field("title","ElasticSearch是一个基于Lucene的搜索服务器") .field("content","它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。") .endObject(); //3.创建索引库及添加文档 client.prepareIndex("blog1","article","1").setSource(builder).get(); //4.关闭资源 client.close(); }
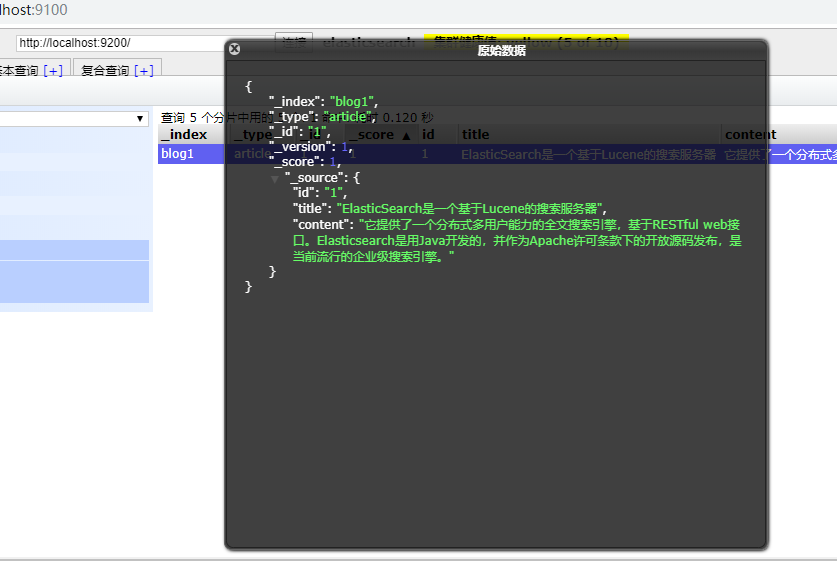
搜索文档数据
查询全部
@Test//查询全部 public void test2() throws Exception { //创建客户端访问对象 TransportClient client=new PreBuiltTransportClient(Settings.EMPTY) .addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("127.0.0.1"),9300)); //创建查询对象 SearchResponse searchResponse=client.prepareSearch("blog1").setTypes("article").setQuery(QueryBuilders.matchAllQuery()) .get(); //处理查询结果 SearchHits hits=searchResponse.getHits();//表示查询到的文档 System.out.println("查询到了"+hits.totalHits+"个文档"); //迭代器遍历 Iterator<SearchHit> iterator = hits.iterator(); while (iterator.hasNext()){ SearchHit hit = iterator.next();//拿到一个文档对象 System.out.println(hit.getSourceAsString()); System.out.println(hit.getSource().get("title")); } //关闭资源 client.close(); }
字符串查询
查询全部的代码不变,只需改正创建对象即可
//2、创建查询对象,并返回结果 SearchResponse searchResponse = client.prepareSearch("blog1").setTypes("article")
.setQuery(QueryBuilders.queryStringQuery("提供")).get();
词条查询
查询全部的代码不变,只需改正创建对象即可
//2、创建查询对象,并返回结果 SearchResponse searchResponse = client.prepareSearch("blog1").setTypes("article")
.setQuery(QueryBuilders.termQuery("title","搜索")).get();
模糊查询
查询全部的代码不变,只需改正创建对象即可
//2、创建查询对象,并返回结果 SearchResponse searchResponse = client.prepareSearch("blog1").setTypes("article")
.setQuery(QueryBuilders.wildcardQuery("title","*搜索*")).get();
ElasticSearch集成IK分词器
ik分词器的安装
下载地址:https://github.com/medcl/elasticsearch-analysis-ik/releases
解压
将解压后的文件夹拷贝到elasticsearch-5.6.8\plugins下,并重命名文件夹为ik
重新启动ElasticSearch,即可加载IK分词器
ik分词器测试
IK提供了两个分词算法ik_smart 和 ik_max_word
其中 ik_smart 为最少切分,ik_max_word为最细粒度划分
我们分别来试一下
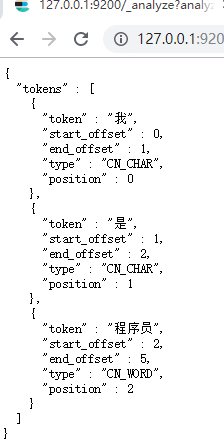
1)最小切分:在浏览器地址栏输入地址
http://127.0.0.1:9200/_analyze?analyzer=ik_smart&pretty=true&text=我是程序员
输出的结果为:
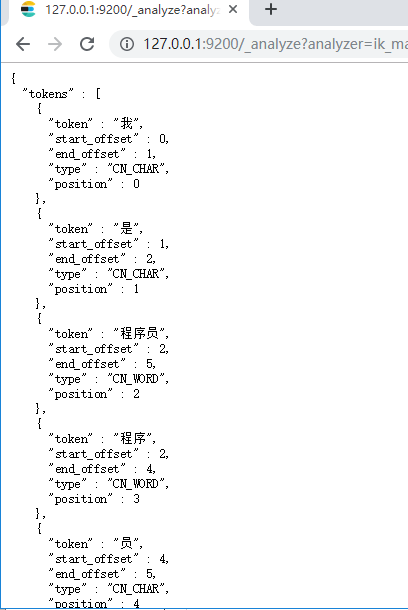
2)最细切分:在浏览器地址栏输入地址
http://127.0.0.1:9200/_analyze?analyzer=ik_max_word&pretty=true&text=我是程序员
输出的结果为
ElasticSearch常用编程操作
索引相关操作
创建索引
@Test //创建索引库 public void test1() throws Exception { //1、创建客户端访问对象 TransportClient client = new PreBuiltTransportClient(Settings.EMPTY) .addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("127.0.0.1"), 9300)); //2、创建索引 index //client.admin().indices().prepareCreate("blog2").get(); client.admin().indices().prepareDelete("blog2").get(); //3、关闭资源 client.close(); }
删除索引

映射相关操作
创建映射
@Test
//创建映射
public void test2() throws Exception {
//1.创建客户端访问对象
TransportClient client=new PreBuiltTransportClient(Settings.EMPTY)
.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("127.0.0.1"),9300));
//创建索引
client.admin().indices().prepareCreate("blog2").get();
/*** 格式:
* "mappings" : {
"article" : {
"properties" : {
"id" : { "type" : "string" },
"content" : { "type" : "string" },
"title" : { "type" : "string" }
}
}
}
*/
//创建映射
XContentBuilder builder= XContentFactory.jsonBuilder()
.startObject()
.startObject("article")
.startObject("properties")
.startObject("id")
.field("type","long")
.field("store","long")
.endObject()
.startObject("title")
.field("type","string")
.field("store","true")
.field("analyzer","ik_smart")
.endObject()
.startObject("content")
.field("type","string")
.field("store","true")
.field("analyzer","ik_smart")
.endObject()
.endObject()
.endObject()
.endObject();
//建立与索引库和type的关系
PutMappingRequest mappingRequest= Requests.putMappingRequest("blog2").type("article").source(builder);
//执行
client.admin().indices().putMapping(mappingRequest).get();
//关闭资源
client.close();
}
建立文档(通过XContentBuilder)
@Test //创建索引库及添加文档 public void test3() throws Exception { //1、创建客户端访问对象 TransportClient client = new PreBuiltTransportClient(Settings.EMPTY) .addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("127.0.0.1"),9300)); //2、创建文档对象 //{id:"1",title:"xxx",content:"xxxxxx"} XContentBuilder builder = XContentFactory.jsonBuilder() .startObject() .field("id","1") .field("title","ElasticSearch是一个基于Lucene的搜索服务器。") .field("content","它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。官方客户端在Java、.NET(C#)、PHP、Python、Apache Groovy、Ruby和许多其他语言中都是可用的。根据DB-Engines的排名显示,Elasticsearch是最受欢迎的企业搜索引擎,其次是Apache Solr,也是基于Lucene。") .endObject(); //3、创建索引库及添加文档 client.prepareIndex("blog2", "article", "1").setSource(builder).get(); //4、关闭资源 client.close(); }
建立文档(使用Jackson转换实体)
创建Article实体
public class Article { private Integer id; private String title; private String content; getter/setter... }
引入jackson坐标
<
dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-core</artifactId>
<version>2.8.1</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.8.1</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-annotations</artifactId>
<version>2.8.1</version>
</dependency>
代码实现
@Test //创建文档(通过实体转json) public void test5() throws Exception { //1、创建客户端访问对象 TransportClient client = new PreBuiltTransportClient(Settings.EMPTY) .addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("127.0.0.1"),9300)); //2、创建文档对象 Article a = new Article(); a.setId(2L); a.setTitle("搜索工作其实很快乐"); a.setContent("我们希望我们的搜索解决方案要快,我们希望有一个零配置和一个完全免费的搜索模\n" + "式,我们希望能够简单地使用JSON通过HTTP的索引数据,我们希望我们的搜索服务器始终可用,我们希望能够一台开\n" + "始并扩展到数百,我们要实时搜索,我们要简单的多租户,我们希望建立一个云的解决方案。Elasticsearch旨在解\n" + "决所有这些问题和更多的问题。"); //3.创建一个json转换器 ObjectMapper mapper =new ObjectMapper(); //4、创建索引库及添加文档 {id:xxx, title:xxx, content:xxx} client.prepareIndex("blog2", "article", a.getId()+"").setSource(mapper.writeValueAsString(a)).get(); //5、关闭资源 client.close(); }
更改文档
在创建文档代码基础上更改步骤4 //方式一 client.prepareUpdate("blog2", "article", a.getId()+"").setDoc(mapper.writeValueAsString(a)).get(); //方式二 client.update(new UpdateRequest("blog2","article",a.getId()+"").doc(mapper.writeValueAsString(a))).get();
删除文档
在创建文档代码基础上更改步骤4 方式一 client.prepareDelete("blog2", "article", a.getId()+"").get(); 方式二 client.delete(new DeleteRequest("blog1","article",a.getId()+"")).get();
批量插入数据
删除blog2然后创建索引和映射
@Test //批量创建文档 public void test8() throws Exception { //1、创建客户端访问对象 TransportClient client = new PreBuiltTransportClient(Settings.EMPTY) .addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("127.0.0.1"),9300)); //3.创建一个json转换器 ObjectMapper mapper =new ObjectMapper(); for (int i = 1; i <= 100; i++) { //2、创建文档对象 Article a = new Article(); a.setId(i); a.setTitle(i+"搜索工作其实很快乐"); a.setContent(i+"我们希望我们的搜索解决方案要快,我们希望有一个零配置和一个完全免费的搜索模\n" + "式,我们希望能够简单地使用JSON通过HTTP的索引数据,我们希望我们的搜索服务器始终可用,我们希望能够一台开\n" + "始并扩展到数百,我们要实时搜索,我们要简单的多租户,我们希望建立一个云的解决方案。Elasticsearch旨在解\n" + "决所有这些问题和更多的问题。"); //4、创建索引库及添加文档 {id:xxx, title:xxx, content:xxx} client.prepareIndex("blog2", "article", a.getId()+"").setSource(mapper.writeValueAsString(a)).get(); } //5、关闭资源 client.close(); }
分页和排序
@Test //分页和排序 public void test9() throws Exception { //创建客户端访问对象 TransportClient client=new PreBuiltTransportClient(Settings.EMPTY) .addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("127.0.0.1"),9300)); //创建查询对象 SearchRequestBuilder requestBuilder = client.prepareSearch("blog2").setTypes("article") .setQuery(QueryBuilders.matchAllQuery()); //分页:参数1:从哪开始查,参数2:每页查多少 requestBuilder.setFrom(0).setSize(20); //排序 requestBuilder.addSort("id", SortOrder.ASC); //执行查询并返回结果 SearchResponse searchResponse = requestBuilder.get(); SearchHits hits = searchResponse.getHits(); System.out.println("共查询到了"+hits.getTotalHits()+"条"); Iterator<SearchHit> iterator = hits.iterator(); while (iterator.hasNext()){ SearchHit searchHit = iterator.next(); System.out.println(searchHit.getSourceAsString()); } }
高亮显示
@Test //高亮显示 public void test10() throws Exception { //创建客户端访问对象 TransportClient client=new PreBuiltTransportClient(Settings.EMPTY) .addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("127.0.0.1"),9300)); //创建查询对象 SearchRequestBuilder requestBuilder = client.prepareSearch("blog2").setTypes("article") .setQuery(QueryBuilders.termQuery("title","搜索")); //高亮显示 HighlightBuilder builder=new HighlightBuilder(); builder.preTags("<font color='red'>"); builder.field("title"); builder.postTags("</font>"); requestBuilder.highlighter(builder); //分页:参数1:从哪开始查,参数2:每页查多少 requestBuilder.setFrom(0).setSize(20); //排序 requestBuilder.addSort("id", SortOrder.ASC); //执行查询并返回结果 SearchResponse searchResponse = requestBuilder.get(); SearchHits hits = searchResponse.getHits(); System.out.println("共查询到了"+hits.getTotalHits()+"条"); Iterator<SearchHit> iterator = hits.iterator(); while (iterator.hasNext()){ SearchHit searchHit = iterator.next(); //System.out.println(searchHit.getSourceAsString()); HighlightField field = searchHit.getHighlightFields().get("title"); System.out.println(field.fragments()[0]); } }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号