


redis入门
NOSQL数据库-Redis
1. nosql的概念
2. redis的常用数据类型
3. redis的string操作命令
4. redis的hash操作命令
5. redis的list操作命令
6. redis的set操作命令
7. redis的两种持久化机制
8. jedis对redis进行操作
什么是NOSQL
NoSQL(NoSQL = Not Only SQL),意即“不仅仅是SQL”,是一项全新的数据库理念,泛指非关系型的数据库。
为什么需要NOSQL
解决三高:
高并发
高负载(高存储)
高扩展(高可用)
NOSQL的特点
易扩展
大数据量,高性能
灵活的数据模型
高可用
Redis概述
Redis是用C语言开发的一个开源的高性能键值对(key-value)数据库
Redis的数据结构
Redis应用场景
1.做缓存: 缓存的是使用频次较高,但不是特别重要的数据.请求来时,优先查询非关系型数据库,
如果没有查到则查询关系型数据库,从关系型数据库中查询到结果后,将结果存放到非关系型数据库中,并将结果返回给浏览器.
如果查询到了,直接将查询结果返回给浏览器即可
当用户执行 增 删 改操作时,优先操作关系型数据库, (数据丢失)
操作完毕后,删除非关系型数据库中的相关数据. (数据同步)
2.聊天室的在线好友列表
3.任务队列。(秒杀、抢购、12306等等)
4.应用排行榜
5.网站访问统计
6.数据过期处理(可以精确到毫秒
7.分布式集群架构中的session分离
WindowsRedis安装:
解压缩即可
WindowsrRedis启动和关闭:
启动:
方式1:
启动服务器: 双击 redis-server.exe 文件
启动客户端: 双击 redis-cli.exe 文件
方式2: 使用指定配置文件开启服务 (会持久化) ★
启动服务器: 在dos命令中输入 redis-server.exe redis.windows.conf
启动客户端: 在dos命令中输入 redis-cli.exe
关闭:
方式1: 点击 X 号
方式2: 正常关闭 ★
在dos命令中输入 redis-cli.exe shutdown
LinuxRedis安装
1.需要安装c语言的编译环境 yum install gcc-c++ 或者上传10个依赖程序包 rpm -iUvh *.rpm 2.上传包 alt + p 3.进入上传的目录下 4.解压 tar -zxvf redis-3.0.0.tar.gz 5.进入redis cd redis-3.0.0 6.将代码进行编译(make) make 7.安装redis make PREFIX=/usr/local/src/redis install 8.进入redis安装目录下 cd /usr/local/src/redis/bin 产生如下文件 redis-benchmark ----性能测试工具 redis-check-aof ----AOF文件修复工具 redis-check-dump ----RDB文件检查工具(快照持久化文件) redis-cli ----命令行客户端 redis-server ----redis服务器启动命令 9.进入redis目录 cd /root/jia/redis/redis-3.0.0 10.将redis下的conf文件拷贝到redis下 cp redis.conf /usr/local/redis 11.进入redis的bin目录下 cd /usr/local/src/redis/bin 12.启动 ./redis-server ../redis.conf 使用redis客户端进行登陆 1.进入redis 的 bin目录 cd /usr/local/redis/bin 2.使用bin目录下的批处理进行登陆 ./redis-cli 3.输入ping ping 4.设置数据(重要) set key value 5.获得数据(重要) get key 后端启动 vim /usr/local/redis/redis.conf 1.找到一下代码 修改成yes daemonize no ==>>daemonize yes 2.启动时,指定配置文件 cd /usr/local/redis/ ./bin/redis-server ./redis.conf
Redis命令
字符串类型String概述
字符串类型是Redis中最为基础的数据存储类型,它在Redis中是二进制安全的,这便意味着该类型存入和获取的数
据相同。在Redis中字符串类型的Value最多可以容纳的数据长度是512M
字符串类型String常用命令
set key value
设定key持有指定的字符串value,如果该key存在则进行覆盖操作。总是返回”OK”
127.0.0.1:6379> set company "company"
OK
127.0.0.1:6379>
get key
获取key的value。如果与该key关联的value不是String类型,redis将返回错误信息,因为get命令只能用于获
取String value;如果该key不存在,返回(nil)。
127.0.0.1:6379> set name "company"
OK
127.0.0.1:6379> get name
"company"
del key
删除指定key
127.0.0.1:6379> del name
(integer) 1
127.0.0.1:6379> get name
(nil)
哈希类型hash
哈希类型hash概述
Redis中的Hash类型可以看成具有String Key和String Value的map容器。所以该类型非常适合于存储值对象的信
息。如Username、Password和Age等。如果Hash中包含很少的字段,那么该类型的数据也将仅占用很少的磁盘
空间。每一个Hash可以存储4294967295个键值对。
哈希类型hash常用命令
hset key field value
为指定的key设定field/value对(键值对)。
127.0.0.1:6379> hset myhash username tom
(integer) 1
127.0.0.1:6379>
hdel key field [field … ]
可以删除一个或多个字段,返回值是被删除的字段个数
127.0.0.1:6379> hset myhash username tom
(integer) 1
127.0.0.1:6379> hget myhash username
"tom"
列表类型list
列表类型list概述
在Redis中,List类型是按照插入顺序排序的字符串链表。和数据结构中的普通链表一样,我们可以在其头部(left)和
尾部(right)添加新的元素。在插入时,如果该键并不存在,Redis将为该键创建一个新的链表。与此相反,如果链
表中所有的元素均被移除,那么该键也将会被从数据库中删除。List中可以包含的最大元素数量是4294967295
列表类型list常用命令
lpush key values[value1 value2…]
在指定的key所关联的list的头部插入所有的values,如果该key不存在,该命令在插入的之前创建一个与该key
关联的空链表,之后再向该链表的头部插入数据。插入成功,返回元素的个数。
127.0.0.1:6379> lpush mylist a b c
(integer) 3
127.0.0.1:6379>
lpop key
返回并弹出指定的key关联的链表中的第一个元素,即头部元素。如果该key不存在,返回nil;若key存在,则
返回链表的头部元素。
127.0.0.1:6379> lpush mylist a b c
(integer) 3
127.0.0.1:6379> lpop mylist
"c"
127.0.0.1:6379> lpop mylist
"b"
rpop key
从尾部弹出元素。
127.0.0.1:6379> lpush mylist a b c
(integer) 3
127.0.0.1:6379> rpop mylist
"a"
集合类型set
在Redis中,我们可以将Set类型看作为没有排序的字符集合,和List类型一样,我们也可以在该类型的数据值上执
行添加、删除或判断某一元素是否存在等操作。需要说明的是,这些操作的时间复杂度为O(1),即常量时间内完成
次操作。Set可包含的最大元素数量是4294967295,和List类型不同的是,Set集合中不允许出现重复的元素。
集合类型set的常用命令
sadd key values[value1、value2…]
向set中添加数据,如果该key的值已有则不会重复添加
127.0.0.1:6379> sadd myset a b c
(integer) 3
smembers key
获取set中所有的成员
127.0.0.1:6379> sadd myset a b c
(integer) 3
127.0.0.1:6379> smembers myset
1) "c"
2) "a"
3) "b"
srem key members[member1、member2…]
删除set中指定的成员
127.0.0.1:6379> srem myset a b
(integer) 2
127.0.0.1:6379> smembers myset
1) "c"
127.0.0.1:6379>
Redis的通用命令
keys pattern
获取所有与pattern匹配的key,返回所有与该key匹配的keys。*表示任意一个或多个字符,?表示任意一个字
符
127.0.0.1:6379> keys *
1) "company"
2) "mylist"
3) "myhash"
4) "myset"
del key1 key2…
删除指定的key
127.0.0.1:6379> del company
(integer) 1
exists key
判断该key是否存在,1代表存在,0代表不存在
127.0.0.1:6379> exists compnay
(integer) 0
127.0.0.1:6379> exists mylist
(integer) 1
127.0.0.1:6379>
type key
获取指定key的类型。该命令将以字符串的格式返回。 返回的字符串为string、list、set、hash,如果key不
存在返回none
127.0.0.1:6379> type company
string
127.0.0.1:6379> type mylist
list
127.0.0.1:6379> type myset
set
127.0.0.1:6379> type myhash
hash
127.0.0.1:6379>
Redis的持久化概述
Redis的高性能是由于其将所有数据都存储在了内存中,为了使Redis在重启之后仍能保证数据不丢失,需要将数据
从内存中同步到硬盘中,这一过程就是持久化。Redis支持两种方式的持久化,一种是RDB方式,一种是AOF方
式。可以单独使用其中一种或将二者结合使用。
RDB持久化(默认支持,无需配置)
该机制是指在指定的时间间隔内将内存中的数据集快照写入磁盘。
AOF持久化
该机制将以日志的形式记录服务器所处理的每一个写操作,在Redis服务器启动之初会读取该文件来重新构建
数据库,以保证启动后数据库中的数据是完整的。
无持久化
我们可以通过配置的方式禁用Redis服务器的持久化功能,这样我们就可以将Redis视为一个功能加强版的
memcached了。
redis可以同时使用RDB和AOF
RDB持久化机制
优点:
1.一旦采用该方式,那么你的整个Redis数据库将只包含一个文件,这对于文件备份而言是非常完美的。比如,
你可能打算每个小时归档一次最近24小时的数据,同时还要每天归档一次最近30天的数据。通过这样的备份
策略,一旦系统出现灾难性故障,我们可以非常容易的进行恢复。
2.对于灾难恢复而言,RDB是非常不错的选择。因为我们可以非常轻松的将一个单独的文件压缩后再转移到其
它存储介质上性能最大化。
3.对于Redis的服务进程而言,在开始持久化时,它唯一需要做的只是fork(分叉)出子进程,之
后再由子进程完成这些持久化的工作,这样就可以极大的避免服务进程执行IO操作了。
4.相比于AOF机制,如果数据集很大,RDB的启动效率会更高
缺点:
1.如果你想保证数据的高可用性,即最大限度的避免数据丢失,那么RDB将不是一个很好的选择。因为系统一
旦在定时持久化之前出现宕机现象,此前没有来得及写入磁盘的数据都将丢失。
2.由于RDB是通过fork子进程来协助完成数据持久化工作的,因此,如果当数据集较大时,可能会导致整个服务
器停止服务几百毫秒,甚至是1秒钟
RDB持久化机制的配置
################################ SNAPSHOTTING ################################# # # Save the DB on disk: # # save <seconds> <changes> # # Will save the DB if both the given number of seconds and the given # number of write operations against the DB occurred. # # In the example below the behaviour will be to save: # after 900 sec (15 min) if at least 1 key changed # after 300 sec (5 min) if at least 10 keys changed # after 60 sec if at least 10000 keys changed # # Note: you can disable saving at all commenting all the "save" lines. # # It is also possible to remove all the previously configured save # points by adding a save directive with a single empty string argument # like in the following example: # # save "" save 900 1 save 300 10 save 60 10000
上面配置的是RDB方式数据持久化时机
关键字 时间(秒) key修改数量 解释 save 900 1 每900秒(15分钟)至少有1个key发生变化,则dump内存快照 save 300 10 每300秒(5分钟)至少有10个key发生变化,则dump内存快照 save 60 10000 每60秒(1分钟)至少有10000个key发生变化,则dump内存快照
AOF持久化机制优点
1.该机制可以带来更高的数据安全性,即数据持久性。Redis中提供了3中同步策略,即每秒同步、每修改同步 和不同步。事实上,每秒同步也是异步完成的,其效率也是非常高的,所差的是一旦系统出现宕机现象,那 么这一秒钟之内修改的数据将会丢失。而每修改同步,我们可以将其视为同步持久化,即每次发生的数据变 化都会被立即记录到磁盘中。可以预见,这种方式在效率上是最低的。 2.由于该机制对日志文件的写入操作采用的是append模式,因此在写入过程中即使出现宕机现象,也不会破坏 日志文件中已经存在的内容。然而如果我们本次操作只是写入了一半数据就出现了系统崩溃问题,不用担 心,在Redis下一次启动之前,我们可以通过redis-check-aof工具来帮助我们解决数据一致性的问题。 3.如果日志过大,Redis可以自动启用rewrite机制。即Redis以append模式不断的将修改数据写入到老的磁盘文 件中,同时Redis还会创建一个新的文件用于记录此期间有哪些修改命令被执行。因此在进行rewrite切换时可 以更好的保证数据安全性。 4.AOF包含一个格式清晰、易于理解的日志文件用于记录所有的修改操作。事实上,我们也可以通过该文件完成 数据的重建
AOF持久化机制缺点
1.对于相同数量的数据集而言,AOF文件通常要大于RDB文件
2.根据同步策略的不同,AOF在运行效率上往往会慢于RDB。总之,每秒同步策略的效率是比较高的,同步禁用
策略的效率和RDB一样高效。
AOF持久化配置
开启AOF持久化
############################## APPEND ONLY MODE ############################### # By default Redis asynchronously dumps the dataset on disk. This mode is # good enough in many applications, but an issue with the Redis process or # a power outage may result into a few minutes of writes lost (depending on # the configured save points). # # The Append Only File is an alternative persistence mode that provides # much better durability. For instance using the default data fsync policy # (see later in the config file) Redis can lose just one second of writes in a # dramatic event like a server power outage, or a single write if something # wrong with the Redis process itself happens, but the operating system is # still running correctly. # # AOF and RDB persistence can be enabled at the same time without problems. # If the AOF is enabled on startup Redis will load the AOF, that is the file # with the better durability guarantees. # # Please check http://redis.io/topics/persistence for more information. appendonly no
将appendonly修改为yes,开启aof持久化机制,默认会在目录下产生一个appendonly.aof文件
AOF持久化时机
# appendfsync always
appendfsync everysec
# appendfsync no
上述配置为aof持久化的时机,解释如下:
关键字 持久化时机 解释
appendfsync always 每执行一次更新命令,持久化一次
appendfsync everysec 每秒钟持久化一次
appendfsync no 不持久化
Jedis的介绍
Redis不仅是使用命令来操作,现在基本上主流的语言都有客户端支持,比如java、C、C#、C++、php、
Node.js、Go等。 在官方网站里列一些Java的客户端,有Jedis、Redisson、Jredis、JDBC-Redis、等其中官方推荐
使用Jedis和Redisson。 在企业中用的最多的就是Jedis,Jedis同样也是托管在github上,地址:
https://github.com/xetorthio/jedis。
使用Jedis操作redis需要导入jar包如下:
commons-pool2-2.3.jar
jedis-2.7.0.jar
Jedis的常用API
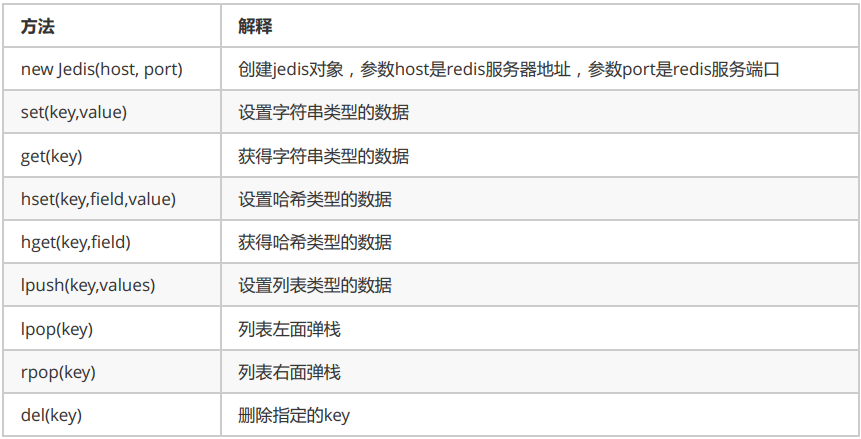
jedis的基本操作
@Test public void testJedisSingle(){ //1 设置ip地址和端口 Jedis jedis = new Jedis("localhost", 6379); //2 设置数据 jedis.set("name", "dmimi"); //3 获得数据 String name = jedis.get("name"); System.out.println(name); //4 释放资源 jedis.close(); }
jedis连接池的基本概念
jedis连接资源的创建与销毁是很消耗程序性能,所以jedis为我们提供了jedis的池化技术,jedisPool在创建时初始
化一些连接资源存储到连接池中,使用jedis连接资源时不需要创建,而是从连接池中获取一个资源进行redis的操
作,使用完毕后,不需要销毁该jedis连接资源,而是将该资源归还给连接池,供其他请求使用。
jedisPool的基本使用
@Test public void testJedisPool(){ //1 获得连接池配置对象,设置配置项 JedisPoolConfig config = new JedisPoolConfig(); // 1.1 最大连接数 config.setMaxTotal(30); // 1.2 最大空闲连接数 config.setMaxIdle(10) //2 获得连接池 JedisPool jedisPool = new JedisPool(config, "localhost", 6379); //3 获得核心对象 Jedis jedis = null; try { jedis = jedisPool.getResource(); //4 设置数据 jedis.set("name", "damimi"); //5 获得数据 String name = jedis.get("name"); System.out.println(name); } catch (Exception e) { e.printStackTrace(); } finally{ if(jedis != null){ jedis.close(); } / / 虚拟机关闭时,释放pool资源 if(jedisPool != null){ jedisPool.close(); } } }
编写jedis连接池的工具类
JedisUtils.java
package com.jia.utils; import java.util.ResourceBundle; import redis.clients.jedis.Jedis; import redis.clients.jedis.JedisPool; import redis.clients.jedis.JedisPoolConfig; public class JedisUtils { private static JedisPoolConfig poolConfig = null; private static JedisPool jedisPool = null; private static Integer maxTotal = null; private static Integer maxIdle = null; private static String host = null; private static Integer port = null; static{ //读取配置文件 获得参数值 ResourceBundle rb = ResourceBundle.getBundle("jedis"); maxTotal = Integer.parseInt(rb.getString("jedis.maxTotal")); maxIdle = Integer.parseInt(rb.getString("jedis.maxIdle")); port = Integer.parseInt(rb.getString("jedis.port")); host = rb.getString("jedis.host"); poolConfig = new JedisPoolConfig(); poolConfig.setMaxTotal(maxTotal); poolConfig.setMaxIdle(maxIdle); jedisPool = new JedisPool(poolConfig,host,port); } public static Jedis getJedis(){ Jedis jedis = jedisPool.getResource(); return jedis; }
jedis.properties
jedis.host=localhost jedis.port=6379 jedis.maxTotal=30 jedis.maxIdle=10

