Python爬虫进阶——Request对象之Get请求与URL编码【英雄联盟吧】
在上一篇中,我们是通过urllib.request.urlopen直接访问的网页地址,但在实际应用中,我们更多地使用urllib.request.Request对象,因为其可以封装headers和data。
一、Request类的参数
class Request:
def __init__(self, url, data=None, headers={},
origin_req_host=None, unverifiable=False,
method=None):
注意:
url:访问的URL地址;
data:像URL地址发送的数据,无则为GET,有则为POST;
headers:请求头,类型为字典;
origin_req_host:日常不用,忽略;
unverifiable:日常不用,忽略;
method:默认GET,可设为POST;
二、构造Request对象
import urllib.request as ur
# 构造一个Request对象
request = ur.Request('https://edu.csdn.net/')
response = ur.urlopen(request).read()
print(response)
三、尝试data打包
以“英雄联盟百度贴吧”为例。
1、分析URL地址:

然而,当我们将网址复制到py文件中,网址却变成了“乱码”?
url = 'https://tieba.baidu.com/f?kw=%E8%8B%B1%E9%9B%84%E8%81%94%E7%9B%9F&ie=utf-8&pn=0'
原来是当GET请求中有汉字时,传递时会对其进行URL编码。
(其实对于任何文字都会进行编码,只是英文和数字编码前后一致而已。)
2、URL编码和解码:
import urllib.parse as up
data = {
'kw': '英雄联盟',
'ie': 'utf-8',
'pn': '0'
}
# 编码
data_url = up.urlencode(
data
)
print(data_url)
# 解码
ret = up.unquote(data_url)
print(ret)
输出如下:

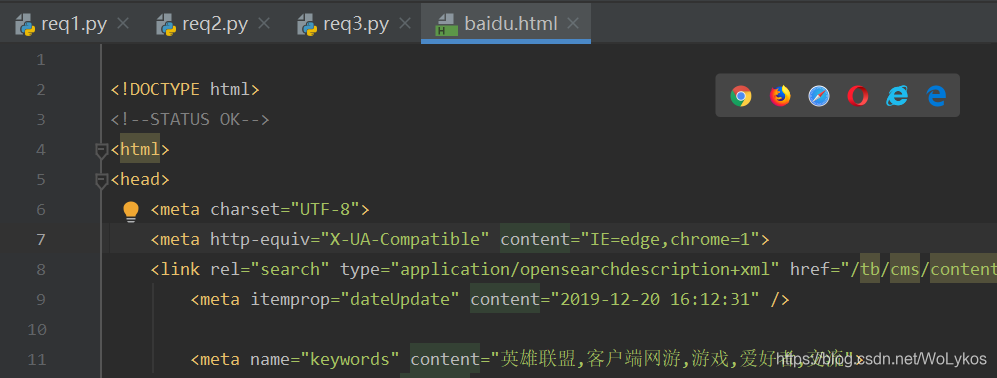
3、利用编码进行百度贴吧的访问:
import urllib.request as ur
# 应使用的是URL编码之后的data_url
request = ur.Request('https://tieba.baidu.com/f?'+data_url)
response = ur.urlopen(request).read()
with open('baidu.html', 'wb') as f:
f.write(response)
输出如下:
4、进行抽离和完善:
import urllib.parse as up
import urllib.request as ur
# 只需更改kw即可,还可更改pn
kw = '美剧'
data = {
'kw': kw,
'ie': 'utf-8',
'pn': '0'
}
# 编码
data_url = up.urlencode(
data
)
print(data_url)
# 解码
ret = up.unquote(data_url)
print(ret)
# 应使用的是URL编码之后的data_url
request = ur.Request('https://tieba.baidu.com/f?'+data_url)
response = ur.urlopen(request).read()
with open('%s.html' % kw, 'wb') as f:
f.write(response)
为我心爱的女孩~~
一个佛系的博客更新者,随手写写,看心情吧 (っ•̀ω•́)っ✎⁾⁾

 浙公网安备 33010602011771号
浙公网安备 33010602011771号