Python爬虫基础——re模块的提取、匹配和替换
re是Python的一个第三方库。
为了能更直观的看出re的效果,我们先新建一个HTML网页文件(可直接复制):
index.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<footer>
<div>
<div class="email">
Email:re@qq.com
</div>
<div class="tel">
手机号:88888888
</div>
</div>
</footer>
</body>
</html>
## OK,然后我们进入主题。
re主要有三个功能:提取、匹配、替换。
1、提取findall:
re.findall(【正则表达式】, 【被提取的字符串】)
注意:返回的类型是列表
我们应如何取出上文index.html中的Email或者手机号呢:
import re
with open('index.html', 'r', encoding='utf-8') as f:
# 读取index.html
html = f.read()
# 把html中的换行符,去掉,也就是替换成空字符串,因为.不能匹配到换行符
html = re.sub('\n', '', html)
print(html)
# 定义正则表达式,注意括号
pattern_1 = '<div class="email">(.*?)</div>'
# re.findall(【正则表达式】,【被提取的字符串】),返回类型是列表
ret_1 = re.findall(pattern_1, html)
# 字符串.strip(),可以去除首位的空格和换行符
print(ret_1[0].strip())
2、匹配match:
re.match(【正则表达式】, 【被匹配的字符串】)
注意:
如果匹配成功,返回<class 're.Match'>对象;
如果匹配不成功,返回None。
我们应如何编写定义密码的正则表达式呢:
import re
# 英文字母开头,可包括应为字母,数字、下划线,总位数6-16位
password_pattern = r'^[a-zA-Z][a-zA-Z0-9_]{5,15}$'
# 定义三个密码
pass1 = '1234567'
pass2 = 'k123456'
pass3 = 'k123'
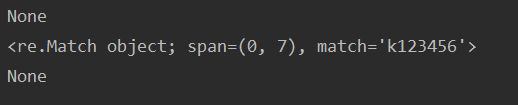
# 打印测试结果,匹配成功返回re.Match对象,不成功返回None
print(re.match(password_pattern, pass1))
print(re.match(password_pattern, pass2))
print(re.match(password_pattern, pass3))
输出结果为:
3、替换sub:
re.sub(【正则表达式】, 【替换成的字符串】, 【被匹配的字符串】)
觉得没看过sub的同学,那只能说明你看笔记不认真了,示范代码请看上上文~~
为我心爱的女孩~~
一个佛系的博客更新者,随手写写,看心情吧 (っ•̀ω•́)っ✎⁾⁾

 浙公网安备 33010602011771号
浙公网安备 33010602011771号