

轻松掌握 Linux 文本处理三剑客:grep、awk 和 sed 实战演练
Shell 脚本语言编程有哪些优势呢?
Shell 脚本语言的优势在于能够以最轻量级最快捷的速度处理 Linux 操作系统偏底层的业务。比如软件的自动化安装、更新版本,监控报警,日志分析等。虽然其他高级编程语言如 PHP、Python、Ruby 等语言也能做到,但是效率和开发成本上会大打折扣,所谓“杀鸡用牛刀”,有点得不偿失。
成熟的技术人会摒弃华而不实的方法,而会根据不同的场景选择最合适的工具去解决问题,朴实而高效。比如本文着重介绍的 Linux 三剑客:grep、awk 和 sed 就是 Linux 文本处理问题的最高效工具。
下面,我们将依次介绍 Linux 文本处理三剑客的基础语法,使用场景和特性,以及给出对应的实战演练题目。
Shell 编程环境安装
- Windows 用户,建议安装 Git Bash 软件。
- Mac 用户,建议安装 iterm2 软件。
- ssh 工具
Linux 三剑客介绍


- grep:主要用于文本内容查找,支持正则表达式。
- awk:主要用于文本内容的分析处理,也常用于处理数据,生成报告,非常适用于需要按列处理的数据。(现在很多Linux使用gawk)
- sed:全称为 Stream editor ,主要用于文本内容的编辑,默认只处理模式空间,不改变原数据,而且 sed 使用逐行读取的方式处理数据。


- -A<行数 x>:除了显示符合范本样式的那一列之外,并显示该行之后的 x 行内容。
- -B<行数 x>:除了显示符合样式的那一行之外,并显示该行之前的 x 行内容。
- -C<行数 x>:除了显示符合样式的那一行之外,并显示该行之前后的 x 行内容。
- -c:统计匹配的行数
- -e :实现多个选项间的逻辑or 关系
- -E:扩展的正则表达式
- -f 文件名:从文件获取 PATTERN 匹配
- -F :相当于fgrep
- -i --ignore-case #忽略字符大小写的差别。
- -n:显示匹配的行号
- -o:仅显示匹配到的字符串
- -q:静默模式,不输出任何信息
- -s:不显示错误信息。
- -v:显示不被 pattern 匹配到的行,相当于[^] 反向匹配
- -w :匹配 整个单词
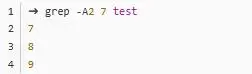
-A2 7 的效果就是找到 7 ,然后输出 7 后面两行。-B2 7和-C2 7就是找到 7 ,然后分别输出 7 前面两行和前后两行:

grep -c命令的作用就是输出匹配到的行数,比如我们想找包含aaa的有几行,一眼就能看出来有两行,第一行和第三行都包含:grep -e命令是实现多个匹配之间的或关系,比如我们想找包含aaaa或者bbbb的,显然应该返回第一行和第二行:
grep -F
fgrep
pattern
'aa*'
-F

aa*
grep -f 文件名
pattern
aa*

实际上等同于grep 'aa*' testgrep -i --ignore-case作用是忽略大小写。grep -n显示匹配的行号,就是多显示了个行号,不用细说。grep -o仅显示匹配到的字符串,还是用刚才的aa*距离,之前显示的都是匹配到的字符所在的整行,这个命令是只显示匹配到的字符:

grep -q不打印匹配结果。刚看到这个我疑惑了半天,让你搜索字符串,你不给我结果那有啥用?然后发现还有一条很多教程没说:如果有匹配的内容则立即返回状态值 0。所以一般用在shell脚本中,在 if 判断里面。grep -s不显示错误信息,不解释。grep -v显示不被匹配到的行,相当于[^]反向匹配,最常见的还是用在查找线程的命令里,有时候会打印grep线程,可以再加上这么一个去除自己:
-
➜ ps -ef|grep Typora
-
501 91616 1 0 五11上午 ?? 13:39.32 /Applications/Typora.app/Contents/MacOS/Typora
-
501 14814 93748 0 5:33下午 ttys002 0:00.00 grep --color=auto --exclude-dir=.bzr --exclude-dir=CVS --exclude-dir=.git --exclude-dir=.hg --exclude-dir=.svn Typora
-
-
➜ ps -ef|grep Typora|grep -v grep
-
501 91616 1 0 五11上午 ?? 13:39.32 /Applications/Typora.app/Contents/MacOS/Typora
grep
grep -w
pattern

可以看到第二次结果为空,因为没有aaa这个单词。
grep 实战演练题目
- 找出 nginx.log 中所有 404 和 503 报错的 log 数据
$grep -E ' 404 | 500 ' nginx.log | wc -l
$awk '$9~/404|500/' nginx.log | wc -l




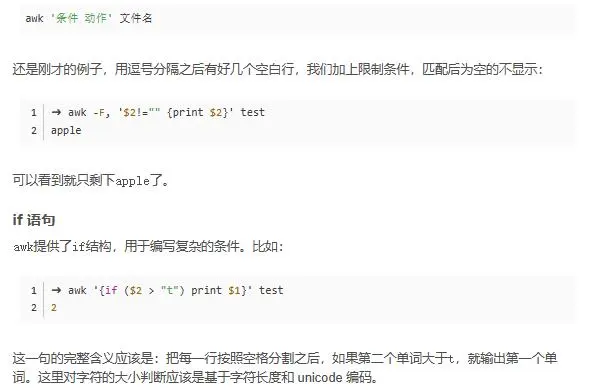
- -F fs or --field-separator fs 指定输入文件折分隔符,fs是一个字符串或者是一个正则表达式,如-F:。
- -v var=value or --asign var=value 赋值一个用户定义变量。
- -f scripfile or --file scriptfile 从脚本文件中读取awk命令。

awk '{print $1,$4}' test就可以看到:对比可以很清楚的发现,这行语句的作用是打印每行的第一个和第四个单词。这里如果是$0的话就是把整行都输出出来。awk- -F命令以指定使用哪个分隔符,默认是空格或者 tab 键:
10 There are orange、apple和mongo三项,然后我们要的是第二项。
- FILENAME:当前文件名
- FS:字段分隔符,默认是空格和制表符。
- RS:行分隔符,用于分割每一行,默认是换行符。
- OFS:输出字段的分隔符,用于打印时分隔字段,默认为空格。
- ORS:输出记录的分隔符,用于打印时分隔记录,默认为换行符。
- OFMT:数字输出的格式,默认为%.6g。
- toupper():字符转为大写。
- tolower():字符转为小写。
- length():返回字符串长度。
- substr():返回子字符串。
- sin():正弦。
- cos():余弦。
- sqrt():平方根。
- rand():随机数。
sed
pattern表达式
- 20 30,35 行数与行数范围
- /pattern/ 正则匹配
- //,// 正则匹配的区间
action
- d 删除
- p 打印,通畅结合-n参数
- s/REGEXP/REPLACEMENT/[FLAGS]
- 替换时引用 \1 \2 匹配的字段
sed
sed 命令的作用是利用脚本来处理文本文件。使用方法: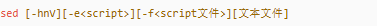
参数说明:
- -e<script>或--expression=<script> 以选项中指定的 script 来处理输入的文本文件,这个-e可以省略,直接写表达式。
- -f<script文件>或--file=<script文件>以选项中指定的 script 文件来处理输入的文本文件。
- -h或--help显示帮助。
- -n 或 --quiet 或 --silent 仅显示 script 处理后的结果。
- -V 或 --version 显示版本信息。
- a:新增, a 的后面可以接字串,而这些字串会在新的一行出现(目前的下一行)~
- c:取代, c 的后面可以接字串,这些字串可以取代 n1,n2 之间的行!
- d:删除,因为是删除啊,所以 d 后面通常不接任何咚咚;
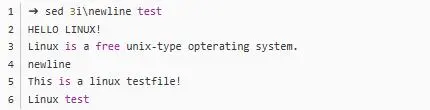
- i:插入, i 的后面可以接字串,而这些字串会在新的一行出现(目前的上一行);
- p:打印,亦即将某个选择的数据印出。通常 p 会与参数 sed -n 一起运行~
- s:取代,通常这个 s 的动作可以搭配正规表示法,例如 1,20s/old/new/g 。

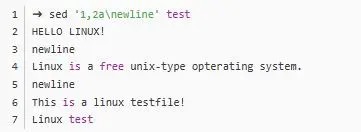
增加内容
sed -e 3a\newLine testfile这个命令的意思就是,在第三行后面追加newLine这么一行字符,字符前面要用反斜线作区分。执行完毕之后可以看到结果: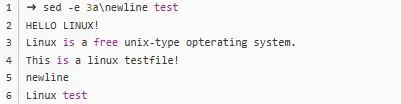
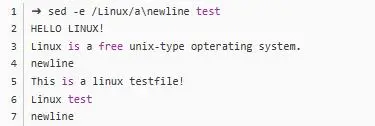
sed /Linux/i\newline test是在所有匹配到Linux的行前面插入:
删除
d,用法跟前面也很相似,就不赘述,例子如下:
替换
c。举个栗子: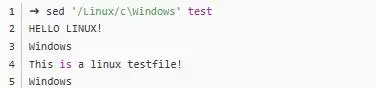
s,但是用法由不太一样了,最常见的用法:sed 's/old/new/g'其中old代表想要匹配的字符,new是想要替换的字符,比如: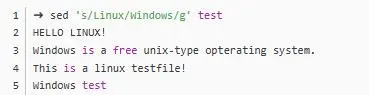
/g的意思是一行中的每一次匹配,因为一行中可能匹配到很多次。我们拿一个新的文本文件做例子:
a变成大写A,那应该这么写:a出现。s还有很多用法,还是回到第一个文件,比如可以用/^/和/$/分别代表行首和行尾:
- ^ 表示一行的开头。如:/^#/ 以#开头的匹配。
- $ 表示一行的结尾。如:/}$/ 以}结尾的匹配。
- \< 表示词首。如:`\ 表示以 abc 为首的詞。
- \> 表示词尾。如:abc\> 表示以 abc 結尾的詞。
- . 表示任何单个字符。
- * 表示某个字符出现了0次或多次。
- [ ] 字符集合。如:[abc] 表示匹配a或b或c,还有 [a-zA-Z] 表示匹配所有的26个字符。如果其中有^表示反,如 [^a] 表示非a的字符
//括起来: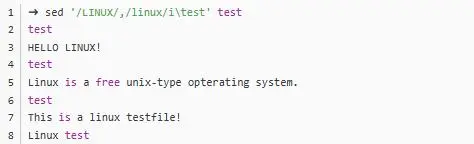
LINUX的那一行,到匹配到linux的那一行,也就是 123 这三行多个匹配
-e命令可以执行多次匹配,相当于顺序依次执行两个sed命令:


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 【杭电多校比赛记录】2025“钉耙编程”中国大学生算法设计春季联赛(1)