《数据挖掘导论》研读(2)
基本数据挖掘技术
决策树
从数据产生决策树的机器学习技术称为决策树学习,是一种有指导学习模型,其中C4.5算法是面向非商业用途分类决策树的经典和常用算法。
决策树算法的一般过程
以C4.5为基础,决策树算法的一般过程如下:
- 给定一个表示为“属性-值”格式的数据集T。数据集有多个具有多个输入属性和一个输出属性组成;
- 使用一个最能区别T中实例的输入属性,C4.5使用增益率来选择该属性;
- 使用该属性创建一个树节点,同时创建该节点的分支,每个分支为该节点的所有可能取值;
- 使用这些分支,将数据集中的实例进行分类,成为细分的子类;
- 将当前子类的实例组合设为T,对数据集中的剩余属性重复2、3步,直到没有剩余属性或子类中的实例满足预定义的标准,则终止过程,创建一个叶子节点,该节点为沿此分支所表达的分类类别,其值为输出属性的值。
使用在CSDN下载的bank.arff为例,进行使用:
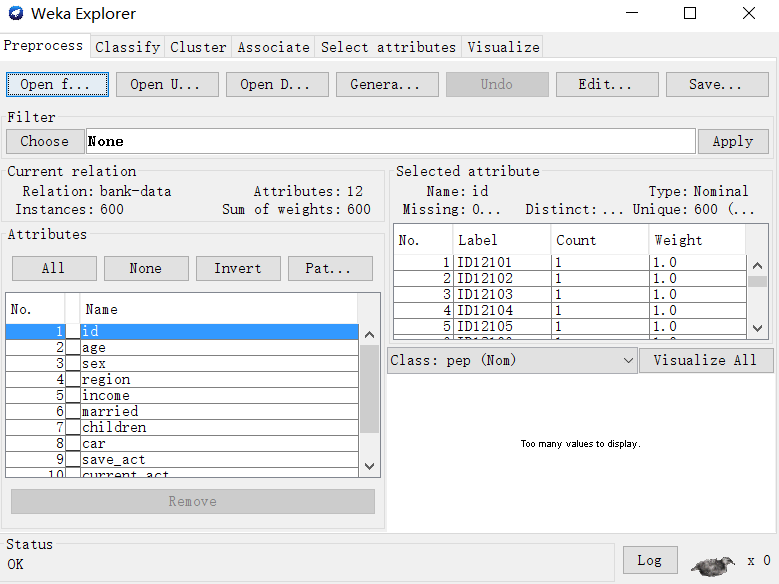
可知,实例个数为600,属性个数为600
在Classify选项页中,使用J48(C4.5算法),建立决策树模型
点击Start,即可进行数据挖掘,
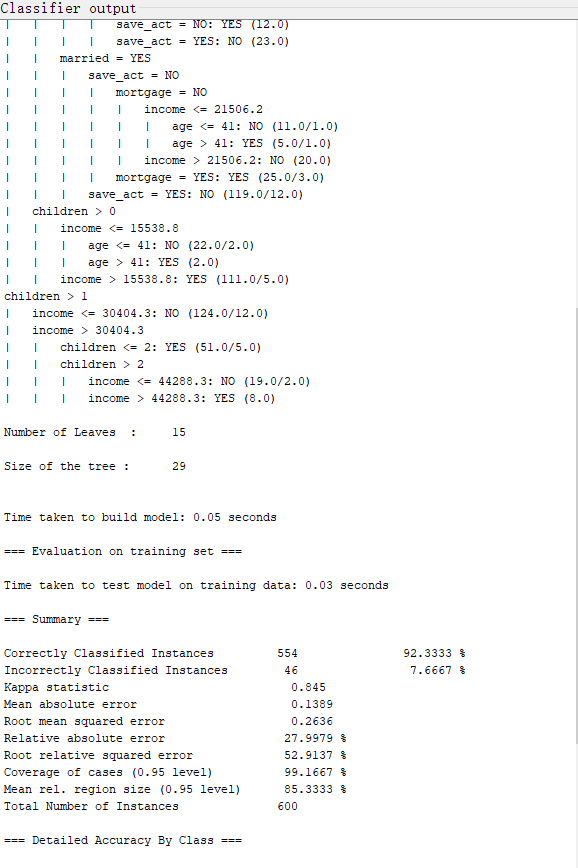
可以看到600个实例中,正确的554个,46个错误的,正确率达到92.3333%
可以认为模型的性能较好。但是本例使用的检验数据为训练数据,对于模型在未来的未知数据中所表现的性能,不能通过现在的分类正确率进行评估。
为了直观地看到决策树,Result list中右击选择visualize tree命令,打开Tree View窗口。
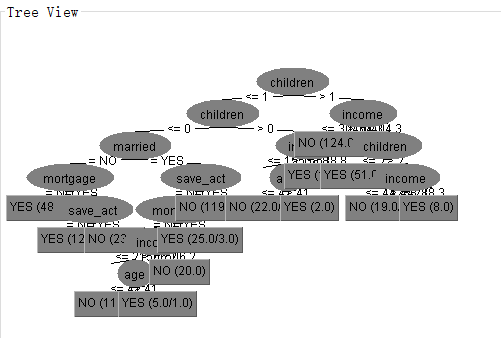
分类未知实例
将Test options设置为Supplied test set ,并打开arff文件作为检验集,同时生成树。
决策树算法的关键技术
- 选择最能区别数据集中实例属性的方法
-
- C4,5使用信息论的方法,即使用增益率的概念来选择属性,目的是实例的层次和节点数量最小,使数据的概化程度最大‘
- C4.5选择的思想是:选择具有最大增益率的属性作为分支节点来分类示例数据。要了解增益率的概念,首先要了解信息论中信息上和信息增益的概念,在此不再赘述信息上的概念,学习一下信息增益。
- 信息增益表示当x取xi值时,其对降低x的熵的贡献大小。
![]()

2.剪枝方法
剪枝是为了控制决策树规模,优化决策树而采取的剪除部分分支的方法。分为两种:预剪枝和后剪枝。
预剪枝是在树的生长过程中设定停止生长指标,一般是指定树的最大深度和当前集合中实力数量小于预先设定的阈值,当达到该指标时就停止继续分支,是决策树不能充分生长,以达到剪枝的目的。预剪枝最大的问题是最大深度的预先指定会影响树的质量。
后剪枝是在已经生长完全的树上,根据一定的规则标准,剪掉树中不具备一般代表性的子树,取而代之的是叶子节点。C4.5就是采用后剪枝技术。
后剪枝技术的计算量代价比预剪枝方法大得多,尤其是大数据集中,仅在小数据集中具有一定的优势。
3.检验方法
Weka提供了以下四种检验方法:
- use training set:使用在训练集实例上的预测效果进行检验;
- supplied test set:使用另提供的检验实例进行检验,此时需要单击Set来选择用来检验的数据集文件;
- cross-validation:使用交叉验证来检验分类器,所用的折数填在Folds文本框中;
- percent split:百分比检验。从数据集中按一定百分比取出部分数据作为检验集实例用,根据分类其在这些实例上的预测效果来检验分类器的质量。取出的数据量由百分比决定。
决策树规则
整棵决策树可以被映射为一组规则,规则比决策树更加具有吸引力。将树映射为规则前,需要进行剪枝,防止使规则变得过于复杂。而且实际上,大多数决策树算法都能够自动化规则的创建和简化过程。
其他决策树算法
ID3使用信息增益,而非信息增益率。
CHAID决策树算法。
关联规则
一般情况下,使用置信度来度量每个关联规则在前提条件下结果发生的可能性。为了减少因为次数少造成的偏差,加入了支持度这一概念。
关联分析算法——Apriori算法。思想为:
- 生成条目集;
- 使用生成的条目集创建一组关联规则。
聚类分析技术
这里介绍的是K-means算法
基本思想:
- 随机选择一个K值,用以确定簇的总数。
- 在数据集中任意选择K个实例,将它们作为初始的簇中心。
- 计算这K个簇中心与其他剩余实例的简单欧式距离,用这个距离作为实例之间相似性的度量,将与某个簇相似高的实例划分到该簇中,成为其成员之一。
- 使用每个簇中的实例来计算该簇新的簇中心。
- 如果计算得到新的簇中心等于上次迭代的簇中心,终止算法过程。否则,用新的簇中心作为簇中心并重复步骤3-5.
其中,简单欧氏距离为:Distance(A-B)=[(x1-x2)²+(y1-y2)²]½
K-均值算法的最优聚类通常为:簇中所有实例与簇中心的误差平方和最小的聚类。寻找最佳聚类的方法就是对于给定的K值,选择不同的初始簇中心重复执行算法。对于大的数据集,一般算法是指定一个终止标准,如可接受的最大均方差。
使用Weka
加载事先做好的.csv数据集

Remove掉Instance列,使该属性不参加训练。切换到Cluster选项卡,选择SimpleKMeans算法。
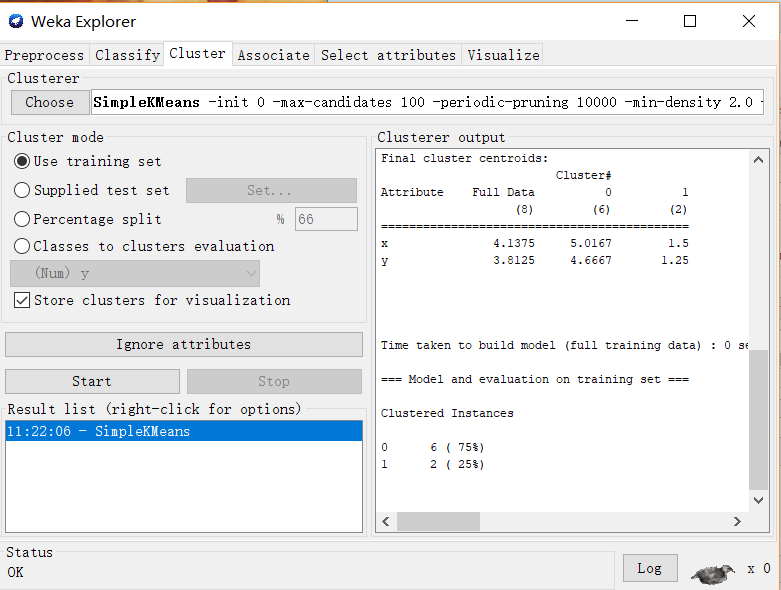
查看结果后可以看到实例被分为0和1,详细信息就不再赘述。
数据挖掘技术的选择
- 数据挖掘技术分为三个大类,包括有指导的学习技术、关联分析和无指导的聚类技术。
- 不同的数据挖掘技术对数据集中的属性之间的相关程度有不同的适应性。
- 不同的数据技术对数据类型本身是敏感的。
- 针对数据本身,要了解其数据分布。
- 了解数据属性对于分类的预测能力。
- 对于数据集中存在噪声数据和缺失数据的考虑。
- 如果学习时有指导的,判断输出属性是一个还是多个。
- 对所学知识的解释能力往往也是在选择某种技术建模时选择考虑的内容。
- 在选择挖掘技术是是否有时间上的考虑。
- 选择机器学习技术还是统计技术的一些考虑。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号