机器学习(sklearn-KNN预测+分类)
一、k-近邻算法(k-Nearest Neighbor,KNN)
简单地说,K-近邻算法采用测量不同特征值之间的距离方法进行分类。
-
- 优点:精度高(计算距离)、对异常值不敏感(单纯根据距离进行分类,会忽略特殊情况)、无数据输入假定(不会对数据预先进行判定)。
- 缺点:时间复杂度高、空间复杂度高。
- 适用数据范围:数值型和标称型。
工作原理:
-
- 存在一个样本数据集合,也称作训练样本集,并且样本集中每个数据都存在标签,即我们知道样本集中每一数据 与所属分类的对应关系
- 输人没有标签的新数据后,将新数据的每个特征与样本集中数据对应的 特征进行比较,然后算法提取样本集中特征最相似数据(最近邻近)的分类标签。
- 一般来说,我们 只选择样本数据集中前K个最相似的数据,这就是K-近邻算法中K的出处,通常K是不大于20的整数。
- 最后 ,选择K个最相似数据中出现次数最多的分类,作为新数据的分类。
原理图例:

邻近算法计算过程:

二、KNN实例(电影分类)
需求:使用K-近邻算法分类爱情片和动作片。有人曾经统计过很多电影的打斗镜头和接吻镜头,下图显示了6部电影的打斗和接吻次数。假如有一部未看过的电影,如何确定它是爱情片还是动作片呢?我们可以使用K-近邻算法来解决这个问题。
实验包数据下载:提取码
第一步:实验数据导入:
以下实验基于jupyter编辑器做开发!
import pandas as pd import numpy as np # 导入数据 data = pd.read_excel('./my_films.xlsx') data
数据展示图例:
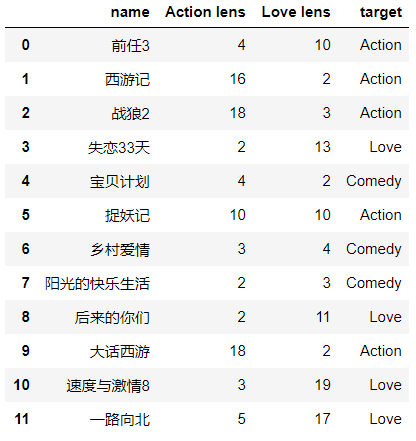
第二步:样本数据的提取与结果分类
#样本数据的提取 feature = data[['Action lens','Love lens']] target = data['target'] # 导入KNN类 from sklearn.neighbors import KNeighborsClassifier # 实例化算法模型,设置k值为3 # k值的设置有特定算法,这里我们的k值的预估的值 knn = KNeighborsClassifier(n_neighbors=3) # 模型训练 knn.fit(feature,target) # KNN电影结果预估 传入参数:打斗次数(Action lens=19),接吻次数(Love lens=18) knn.predict([[19,18]]) #结果>>>array(['Action'], dtype=object) #一种简单的方法k值预测评分,预测k越趋近于1的值,则当前k值最适合当前模型 knn.score(feature,target) # 结果>>>0.9166666666666666
三、KNN实例(预测年收入是否大于50K美元)
- 需求:读取adult.txt文件,最后一列是年收入,并使用KNN算法训练模型,然后使用模型预测一个人的年收入是否大于50
- 实验数据分析:
- 特征数据:较大机率会影响收入的参数值选取(获取年龄、教育程度、职位、每周工作时间作为机器学习数据)
- 目标数据:获取薪水作为对应结果
- 样本数据的特征数据必须为可以计算int/float数据类型,如果不是则需要把数据转换成int/float数据类型
实验包数据下载:提取码
第一步:实验数据导入:
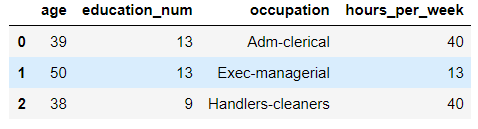
# 读取数据 df = pd.read_csv('./data/adults.txt') df.head(3)
显示前3条数据图例:

第二步:样本数据的获取
#样本数据的提取 feature = df[['age','education_num','occupation','hours_per_week']] target = df['salary'] # 查看数据前3行 feature.head(3)
样本数据图例展示:
第三步:这里获取到的我们需要的样本数据,但是特征数据要用于模型训练,则需要转换成能计算的数值型数据
注意:str类型的数据转换成数值(int/float)类型后,注意转换后的数值要与其他参于模型训练的数据数值权重比基本相同,否则实验结果不准确
# 数据转换,将String类型数据(occupation)转换为int # 数据去重 s = feature["occupation"].unique() # 创建一个空字典 dic = {} j = 0 for i in s: dic[i] = j j += 1 # 替换occupation这一列为数值类型,map映射 # 注意:str类型的数据转换成数值(int/float)类型后,注意转换后的数值与其他参于模型训练的数据数值权重比基本相同 feature['occupation'] = feature['occupation'].map(dic) feature.head(3)
数据转换的的特征数据展示:

第四步:数据拆分,拆分数据为两部分(训练数据与测试数据)
训练数据(特征数据[自变量]&目标数据[因变量]):用于机器模型训练
测试数据(特征数据[自变量]&目标数据[因变量]): 预测值与真实值对比,或者用于k值计算
# 样本数据的拆分 样本共计32560条 # 设置32500条数据为训练数据 x_train = feature[:32500] y_train = target[:32500] # 设置最后60数据为测试数据 x_test = feature[32500:] y_test = target[32500:] # KNN模型训练 knn = KNeighborsClassifier(n_neighbors=50) knn.fit(x_train,y_train) # 预测k值 knn.score(x_test,y_test) # k值结果>>>0.7868852459016393
第五步:预测数据与真实数据实验对比
# 使用测试数据进行测试 print('真实的分类结果:',np.array(y_test)) print('模型的分类结果:',np.array(knn.predict(x_test))) # 结果>>> 真实的分类结果: ['<=50K' '<=50K' '<=50K' '<=50K' '>50K' '<=50K' '>50K' '<=50K' '<=50K' '<=50K' '>50K' '<=50K' '<=50K' '>50K' '<=50K' '<=50K' '<=50K' '<=50K' '>50K' '>50K' '<=50K' '<=50K' '<=50K' '<=50K' '<=50K' '<=50K' '<=50K' '<=50K' '<=50K' '<=50K' '>50K' '<=50K' '>50K' '>50K' '<=50K' '<=50K' '>50K' '<=50K' '>50K' '>50K' '<=50K' '<=50K' '<=50K' '<=50K' '<=50K' '>50K' '<=50K' '<=50K' '<=50K' '<=50K' '<=50K' '<=50K' '<=50K' '<=50K' '>50K' '<=50K' '<=50K' '>50K' '<=50K' '<=50K' '>50K'] 模型的分类结果: ['<=50K' '<=50K' '>50K' '<=50K' '>50K' '<=50K' '<=50K' '<=50K' '<=50K' '<=50K' '<=50K' '<=50K' '<=50K' '<=50K' '<=50K' '<=50K' '<=50K' '<=50K' '<=50K' '<=50K' '<=50K' '<=50K' '<=50K' '<=50K' '<=50K' '<=50K' '<=50K' '<=50K' '<=50K' '<=50K' '<=50K' '<=50K' '>50K' '>50K' '<=50K' '<=50K' '>50K' '<=50K' '>50K' '<=50K' '<=50K' '<=50K' '<=50K' '>50K' '<=50K' '<=50K' '<=50K' '<=50K' '>50K' '<=50K' '<=50K' '<=50K' '<=50K' '<=50K' '>50K' '<=50K' '<=50K' '<=50K' '<=50K' '<=50K' '<=50K']
第六步:加入测试数据,预测年收入大于50k美金结果(分类)
# 数据结果分类 age,education_num,occupation,hours_per_week knn.predict([[50,12,4,50]]) #结果>>> array(['>50K'], dtype=object)
https://www.cnblogs.com/WiseAdministrator/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号