Python网络爬虫(增量式爬虫)
一、增量式爬虫背景:
当我们在浏览相关网页的时候会发现,某些网站定时会在原有网页数据的基础上更新一批数据,例如某电影网站会实时更新一批最近热门的电影。小说网站会根据作者创作的进度实时更新最新的章节数据等等。那么,类似的情景,当我们在爬虫的过程中遇到时,我们是不是需要定时更新程序以便能爬取到网站中最近更新的数据呢?
二、增量式爬虫分析与设计
- 概念:通过爬虫程序监测某网站数据更新的情况,以便可以爬取到该网站更新出的新数据。
- 如何进行增量式的爬取工作,检测重复数据的三种情况:
- 在发送请求之前判断这个URL是不是之前爬取过
- 在解析内容后判断这部分内容是不是之前爬取过
- 写入存储介质时判断内容是不是已经在介质中存在
- 分析:
- 不难发现,其实增量爬取的核心是去重, 至于去重的操作在哪个步骤起作用,只能说各有利弊。在我看来,前两种思路需要根据实际情况取一个(也可能都用)。第一种思路适合不断有新页面出现的网站,比如说小说的新章节,每天的最新新闻等等;第二种思路则适合页面内容会更新的网站。第三个思路是相当于是最后的一道防线。这样做可以最大程度上达到去重的目的。
- 去重方法:
- 将爬取过程中产生的url进行存储,存储在redis的set中。当下次进行数据爬取时,首先对即将要发起的请求对应的url在存储的url的set中做判断,如果存在则不进行请求,否则才进行请求。
- 对爬取到的网页内容进行唯一标识的制定(数据指纹),然后将该唯一表示存储至redis的set中。当下次爬取到网页数据的时候,在进行持久化存储之前,首先可以先判断该数据的唯一标识在redis的set中是否存在,在决定是否进行持久化存储。
三、增量式爬虫实例(4567电影网)
增量式实际需求定制方式:通过获取电影详情页url地址存放redis数据库的set集合中,利用set自动去重的特性,存取爬虫爬取记录,达到增量式爬取需求
需求:获取网站电影信息(电影名称&电影详情页信息),url: http://www.4567kan.com/index.php/vod/show/id/5.html
爬虫文件:movie.py
# -*- coding: utf-8 -*- import scrapy from scrapy.linkextractors import LinkExtractor from scrapy.spiders import CrawlSpider, Rule from ..items import ZlsproItem from redis import Redis class MovieSpider(CrawlSpider): name = 'movie' # allowed_domains = ['www.xx.com'] # 起始url列表 start_urls = ['http://www.4567kan.com/index.php/vod/show/id/5.html'] # 规则解析器 rules = ( # follow=False 爬取当前HTML页面的所有连接提取器提取到的url Rule(LinkExtractor(allow=r'vod/show/id/5/page/\d+\.html'), callback='parse_item', follow=False), ) # 创建redis连接 conn = Redis(host="127.0.0.1", port=6379) # 数据解析 def parse_item(self, response): # 电影名称和详情页的url li_list = response.xpath('/html/body/div[1]/div/div/div/div[2]/ul/li') for li in li_list: # 获取电影名称 name = li.xpath('.//div[@class="stui-vodlist__detail"]/h4/a/text()').extract_first() # 获取电影详情页url detail_url = 'http://www.4567kan.com' + li.xpath( './/div[@class="stui-vodlist__detail"]/h4/a/@href').extract_first() # 实例化一个item对象 item = ZlsproItem() item['name'] = name # 通过redis中的集合(set自动去重特性,满足增量式爬取)存储电影详情页url # 向redis集合中插入数据,存在则插入失败,返回0。否则成功返回1 exist = self.conn.sadd("movie_detail_urls", detail_url) # 插入数据成功,则当前url是新数据,则手动请求获取内容信息 if exist: print("正在爬取网站更新数据!!!") yield scrapy.Request(detail_url, callback=self.parse_detail, meta={"item": item}) else: print("网站数据暂无更新数据!!!") # 电影详情页信息 def parse_detail(self, response): item = response.meta["item"] movie_desc = response.xpath('/html/body/div[1]/div/div/div/div[2]/p[5]/span[2]/text()').extract_first() item['movie_desc'] = movie_desc # 提交数据到管道 yield item
管道对象类配置:items.py
import scrapy class ZlsproItem(scrapy.Item): # define the fields for your item here like: name = scrapy.Field() movie_desc = scrapy.Field()
管道类:持久化存储。pipelines.py
class ZlsproPipeline(object):
# 数据持久化
def process_item(self, item, spider):
# print(item)
# 获取redis连接
conn = spider.conn
# 获取的电影信息存放redis数据库 列表中插入数据lpush
# 这里redis数据列表中存储字典时,版本不同可能保存,推荐版本redis 2.10.6
conn.lpush("movie_data", item)
return item
爬虫配置文件:settings.py
BOT_NAME = 'zlsPro' SPIDER_MODULES = ['zlsPro.spiders'] NEWSPIDER_MODULE = 'zlsPro.spiders' # Crawl responsibly by identifying yourself (and your website) on the user-agent USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36' # Obey robots.txt rules ROBOTSTXT_OBEY = False # 开启管道 ITEM_PIPELINES = { 'zlsPro.pipelines.ZlsproPipeline': 300, }
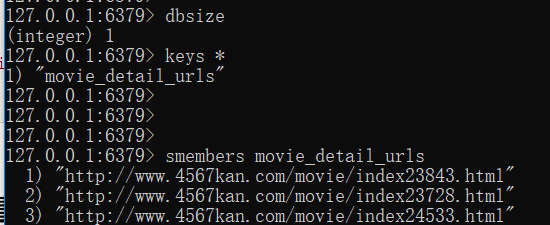
爬取内容,查看数据库存储电影详情页url
四、增量式爬虫实例(糗事百科)
增量式实际需求定制方式:针对于同一url中多内容爬取,通过制定数据指纹,对数据制定的一个唯一标识,例如MD5,sha等摘要算法做标识去重
需求:爬取糗事百科(内容&用户名), url:
爬虫文件:qiushi.py
# -*- coding: utf-8 -*- import scrapy from scrapy.linkextractors import LinkExtractor from scrapy.spiders import CrawlSpider, Rule from ..items import QiushiproItem from redis import Redis class QiushiSpider(CrawlSpider): name = 'qiushi' # allowed_domains = ['www.xx.com'] # 起始url列表 start_urls = ['https://www.qiushibaike.com/text/'] # 规则解析器 rules = ( Rule(LinkExtractor(allow=r'/text/page/\d+/'),callback='parse item',follow=True), Rule(LinkExtractor(allow=r"/text/$'),callback='parse_item',follow=True), ) # 创建redis连接 conn = Redis(host="127.0.0.1", port=6379) # 数据解析 def parse_item(self, response): # li标签列表 li_list = response.xpath('//div[@id="content-1eft"]/div') for li in li_list: # 实例化一个item对象 item = QiushiproItem() # 用户名
item['author']=div.xpath('./div[1]/a[2]/h2/text()|./div[1]/span[2]/h2/text()").extract_first() # 内容信息 item['content']=div.xpath(.//div[@class="content"]/span/text()").extract_first() #将解析到的数据值生成一个唯一的标识进行redis存储
source=item['author']+item['content] sourte_id=hashlib.sha256(source.encode()).hexdigest()
#将解析内容的唯一表示存储到redis的data_id中
ex=self.conn.sadd('data_id',source_id) if ex==1:
print(该条数据没有爬取过,可以爬取..……) yield item
else:
print(“该条数据已经爬取过了,不需要再次爬取了!!!)
https://www.cnblogs.com/WiseAdministrator/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号