Python网络爬虫(scrapy中selenium的应用)
一、项目背景
在通过scrapy框架进行某些网站数据爬取的时候,往往会碰到页面动态数据加载的情况发生,如果直接使用scrapy对其url发请求,是绝对获取不到那部分动态加载出来的数据值。但是通过观察我们会发现,通过浏览器进行url请求发送则会加载出对应的动态加载出的数据。那么如果我们想要在scrapy也获取动态加载出的数据,则必须使用selenium创建浏览器对象,然后通过该浏览器对象进行请求发送,获取动态加载的数据值。
二、网易新闻案例分析
需求:爬取网易新闻的国内板块下的新闻数据
需求分析:当点击国内超链进入国内对应的页面时,会发现当前页面展示的新闻数据是被动态加载出来的,如果直接通过程序对url进行请求,是获取不到动态加载出的新闻数据的。则就需要我们使用selenium实例化一个浏览器对象,在该对象中进行url的请求,获取动态加载的新闻数据。
三、selenium在scrapy中使用的原理分析:
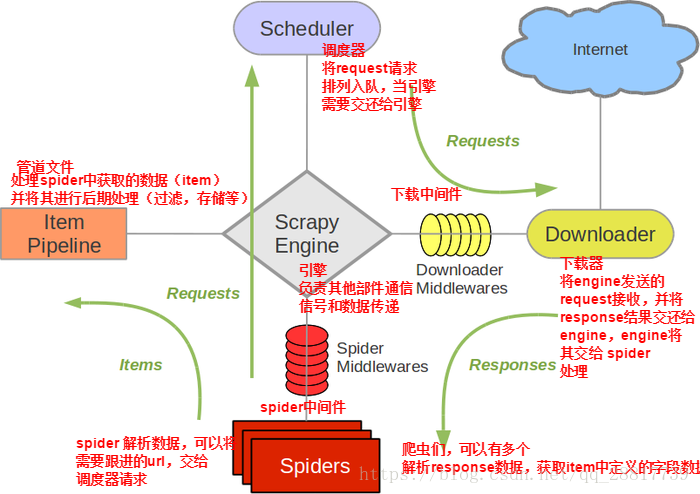
当引擎将国内板块url对应的请求提交给下载器后,下载器进行网页数据的下载,然后将下载到的页面数据,封装到response中,提交给引擎,引擎将response在转交给Spiders。Spiders接受到的response对象中存储的页面数据里是没有动态加载的新闻数据的。要想获取动态加载的新闻数据,则需要在下载中间件中对下载器提交给引擎的response响应对象进行拦截,切对其内部存储的页面数据进行篡改,修改成携带了动态加载出的新闻数据,然后将被篡改的response对象最终交给Spiders进行解析操作。
四、selenium在scrapy中的使用流程:
- 重写爬虫文件的构造方法,在该方法中使用selenium实例化一个浏览器对象(因为浏览器对象只需要被实例化一次)
- 重写爬虫文件的closed(self,spider)方法,在其内部关闭浏览器对象。该方法是在爬虫结束时被调用
- 重写下载中间件的process_response方法,让该方法对响应对象进行拦截,并篡改response中存储的页面数据
- 在配置文件中开启下载中间件
五、代码的框架分析(简)
爬虫文件:
class WangyiSpider(RedisSpider): name = 'wangyi' #allowed_domains = ['www.xxxx.com'] start_urls = ['https://news.163.com'] def __init__(self): #实例化一个浏览器对象(实例化一次) self.bro = webdriver.Chrome(executable_path='/Users/bobo/Desktop/chromedriver') #必须在整个爬虫结束后,关闭浏览器 def closed(self,spider): print('爬虫结束') self.bro.quit()
中间件文件:
from scrapy.http import HtmlResponse #参数介绍: #拦截到响应对象(下载器传递给Spider的响应对象) #request:响应对象对应的请求对象 #response:拦截到的响应对象 #spider:爬虫文件中对应的爬虫类的实例 def process_response(self, request, response, spider): #响应对象中存储页面数据的篡改 if request.url in['http://news.163.com/domestic/','http://news.163.com/world/','http://news.163.com/air/','http://war.163.com/']: spider.bro.get(url=request.url) js = 'window.scrollTo(0,document.body.scrollHeight)' spider.bro.execute_script(js) time.sleep(2) #一定要给与浏览器一定的缓冲加载数据的时间 #页面数据就是包含了动态加载出来的新闻数据对应的页面数据 page_text = spider.bro.page_source #篡改响应对象 return HtmlResponse(url=spider.bro.current_url,body=page_text,encoding='utf-8',request=request) else: return response
六、项目的实际分析,详细代码示例(全)
配置文件:settings.py
BOT_NAME = 'wangyiPro' SPIDER_MODULES = ['wangyiPro.spiders'] NEWSPIDER_MODULE = 'wangyiPro.spiders' # UA伪装 USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36' # 关闭robots ROBOTSTXT_OBEY = False # 日志等级 LOG_LEVEL = "ERROR" # 开启下载中间件 DOWNLOADER_MIDDLEWARES = { 'wangyiPro.middlewares.WangyiproDownloaderMiddleware': 543, } # 开启管道 ITEM_PIPELINES = { 'wangyiPro.pipelines.WangyiproPipeline': 300, }
百度API接口:baiduapi.py
通过文章标题与文章内容,通过自然语言处理(nlp),获取(文章标签)和(文章分类)
# 标签类型 这里调用nlp自然语言处理(API文章标签接口) # AppID:16985987 # APIKey:dshTH2UtLWArRAKKAtR1RiOS from aip import AipNlp # 初始化API接口 def client_init(): """ 你的 APPID AK SK """ APP_ID = '169xxx87' API_KEY = 'dshTH2xxxKKAtR1RiOS' SECRET_KEY = 'gbkssDmmxxxxhI8utGqa96TS' client = AipNlp(APP_ID, API_KEY, SECRET_KEY) return client # 文章标签API def get_keyword(title, content): # 初始化api函数,创建一个aip接口对象 client = client_init() """ 调用文章标签 """ ret = client.keyword(title, content) try: return ret["items"][1]["tag"] except: pass # 文章分类API def get_topic(title, content): # 初始化api函数,创建一个aip接口对象 client = client_init() """ 调用文章分类 """ ret = client.topic(title, content) try: return ret["item"]["lv1_tag_list"][0]["tag"] except: pass
爬虫文件:对新闻数据做数据解析。wangyi.py
# -*- coding: utf-8 -*- import scrapy from ..items import WangyiproItem from selenium import webdriver from ..baiduapi import get_keyword, get_topic class WangyiSpider(scrapy.Spider): def __init__(self): # 重写__init__方法,实例化selenium的浏览器对象 self.dri = webdriver.Chrome( executable_path=r"C:\Users\Administrator\Desktop\json\spider\day10820190809\chromedriver.exe") name = 'wangyi' # allowed_domains = ['www.xx.com'] start_urls = ['https://news.163.com/'] # 创建一个全局url列表,存放标题url地址 title_urls = [] # 数据解析 def parse(self, response): li_list = response.xpath('//*[@id="index2016_wrap"]/div[1]/div[2]/div[2]/div[2]/div[2]/div/ul/li') # 获取国内,国际,军事,航空,无人机 # indexs = [3, 4, 6, 7, 8] indexs = [3] for index in indexs: # 获取标题地址 title_url = li_list[index].xpath('./a/@href').extract_first() # 将内容块标题地址url放入全局列表中,在中间件做动态数据请求 self.title_urls.append(title_url) # 手动请求标题url yield scrapy.Request(title_url, callback=self.parse_title) # 解析标题数据(国内,国际,军事,航空,无人机), 这里数据是动态加载,需要在中间件通过selenium请求返回的response对象 def parse_title(self, response): div_list = response.xpath('/html/body/div/div[3]/div[4]/div[1]/div/div/ul/li/div/div') for div in div_list: # 文章标题API title = div.xpath('.//div[@class="news_title"]/h3/a/text()').extract_first() # 文章内容详情页API detail_url = div.xpath('.//div[@class="news_title"]/h3/a/@href').extract_first() # 实例化item对象,存储title值 item = WangyiproItem() item["title"] = title.replace("\n", "").replace("\r", "").replace(" ", "") # 手动请求内容详情页 yield scrapy.Request(detail_url, callback=self.parse_detail, meta={"item": item}) # 内容详情页数据解析,这里静态页面 def parse_detail(self, response): # 接收请求参数item item = response.meta["item"] # 获取到内容是一个列表 content = response.xpath('//*[@id="endText"]/p/text()').extract() content = "".join(content).replace("\n", "").replace("\r", "").replace(" ", "") item["content"] = content # 文章标签API item["keyword"] = get_keyword(item['title'], content) # item["keyword"] = "11" # 文章分类API item["topic"] = get_topic(item['title'], content) # item["topic"] = "222" # 提交数据到管道 yield item # 爬虫结束之前,最后执行closed函数 def closed(self, spider): print('结束爬虫!!!') self.dri.quit()
配置items文件,创建item对象类,用于存储item对象。items.py
import scrapy class WangyiproItem(scrapy.Item): # define the fields for your item here like: title = scrapy.Field() content = scrapy.Field() keyword = scrapy.Field() topic = scrapy.Field()
配置中间件:在下载器中间中,处理动态请求的响应数据。middlewares.py
# -*- coding: utf-8 -*- # Define here the models for your spider middleware # # See documentation in: # https://doc.scrapy.org/en/latest/topics/spider-middleware.html from scrapy import signals from time import sleep from scrapy.http import HtmlResponse class WangyiproDownloaderMiddleware(object): # 拦截所有请求对象 def process_request(self, request, spider): return None # 拦截所有响应对象,由于请新闻版块的动态加载,通过request请求的静态页面不是我们想要的数据 # 这里我们通过selenium模拟请求,获取动态加载数据 # 这里我们需要实例化一次的浏览器对象,在spider应用中实例化 # request与response(一个请求对象对应一个响应对象) def process_response(self, request, response, spider): # 获取爬虫文件中,标题url列表 title_urls = spider.title_urls # 判断当前请求的url是否为标题url,只有标题url列表中的请求的动态请求 if request.url in title_urls: # 获取dri浏览器对象 dri = spider.dri # 通过selenium请求指定url dri.get(request.url) # 延时,等待浏览器请求响应的延迟 sleep(2) # js语法:向下滑动一页 js = "window.scrollTo(0, document.body.scrollHeight)" # 执行js代码,向下滑动一页 dri.execute_script(js) sleep(0.5) dri.execute_script(js) sleep(0.5) # 获取请求的动态加载数据 page_text = dri.page_source # 通过实例化构建新的响应对象 new_response = HtmlResponse(url=request.url, body=page_text, encoding="utf-8", request=request) return new_response # 其他静态页面响应的数据 return response # 拦截所有异常响应或者请求 def process_exception(self, request, exception, spider): pass
持久化存储:这里获取spider爬虫文件数据解析后数据做持久化存储。pipelines.py
import pymysql class WangyiproPipeline(object): # 初始化mysql连接与游标 conn = None cursor = None # 一般处理句柄或者数据库连接,函数只执行一次 def open_spider(self, spider): self.conn = pymysql.connect(host="127.0.0.1", port=3306, user="root", password="1234", db="spider") # 持久化存储 def process_item(self, item, spider): # 创建游标 self.cursor = self.conn.cursor() # 获取数据属性 title = item["title"].strip() content = item["content"].strip() keyword = item["keyword"] topic = item["topic"] print(title, content, keyword, topic) # sql语句 插入数据 sql = "insert into wangyi values('%s','%s','%s','%s')" % (title, content, keyword, topic) try: # 执行sql语句 self.cursor.execute(sql) # 事务提交 self.conn.commit() except Exception as e: # 打印错误信息 print(e) # 事务回滚 self.conn.rollback() self.cursor.close() # 返回item对象到管道,供下一个管道类接收 return item # 一般处理句柄或者数据库关闭,函数只执行一次 def close_spider(self, spider): self.conn.close()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号