九大排序算法
九大排序排序是数据结构体系中最重要的内容之一,这一块必须要非常熟练的掌握,应该做到可以立马写出每个排序的代码,有多种实现方法的必须多种都能很快写出来,当然对各个排序的性能的了解也是基础且重要的。我们先对排序这一块进行一个整体的把握。
这里先说明几个概念
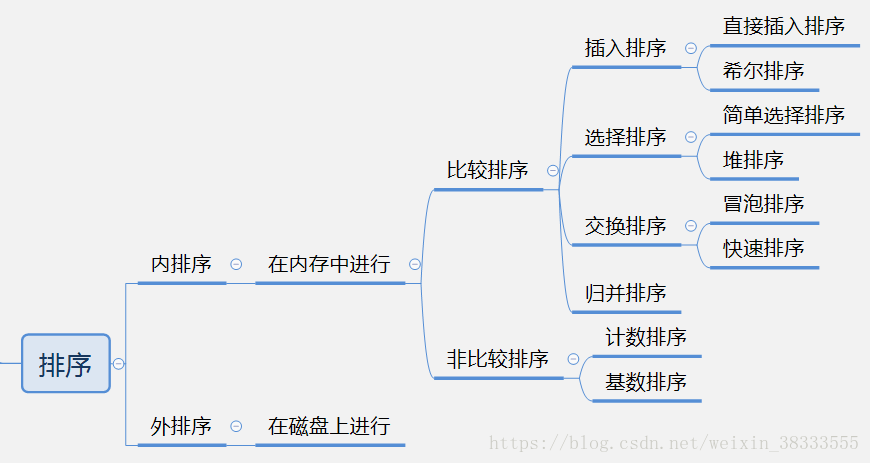
1 2 3 4 5 | 内排序:在对待排序数据存放在内存中进行的排序过程。是我们主要讨论与学习的重点。外排序:待排数据量太大,无法一次性将所有待排序数据放入内存中,在排序过程中需要对磁盘等外部储存器进行访问。不是我们谈论与学习的重点,但也要通过相关资料或书籍了解其基本原理。比较排序:排序过程中需要对数据关键字进行比较。非比较排序:排序过程中不需要对数据关键字进行比较。排序算法的稳定性:在每一次单趟排序后,相同关键字的相对顺序不变。(后面讲到了再具体解释) |
所有讲解都以升序为例(降序完全就是改个符号的问题啦),本篇先讲几个简单的,复杂些的后面每个单独写。
直接插入排序
直接插入排序是非常简单的,对于一个长度为n的关键字序列a1,a2,a3,a4,a5...an, 一句话来说:我们就是要把每个关键字都放到其之前的有序子序列中的合适位置。
具体是这样:你看,该序列的第一个元素a1之前不存在子序列因此不用考虑,故从第二个元素开始,先把a2的值保存到Key中,那么此时,a2如果大于等于a1,那么a2就不动,因为这就是它当前合适的位置,若是a2小于a1那么就把a1往后挪一个,把a2放到a1的位置。

对于一般的情况是这样:
在有序子序列中从后往前找,直到找到一个key小于等于key的数(每往前找一个,那么就往后挪一个),把key放在这个数后面,这就是key合适的位置(好好想明白),或者可能找完了整个序列也没找到我们要的合适的位置,那就放在该有序子序列的第一个元素的位置(此时有序子序列的所有元素已经后挪),同样,你想想,若有序子序列的最后一个元素就小于key,那么就不用挪了,当前的位置就是合适的位置。
那么接下来

当然,更常见的情况是这样,并不是简单的是需要移动多次的,但是没关系,核心思想都是一样的

前面四个关键字都调整好了,那么第五个呢?看到这你肯定心中有答案了
代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | void InsertSort(int* a,int len){ int begin = 1; int i = 0; while(begin < len) { int key = a[begin]; for(i = begin-1;i>=0;i--) { if(a[i]<=key) //稳定的 { a[i+1] = key; break; } a[i+1] = a[i]; } if(i<0) a[0] = key;//说明找完了整个有序子序列都没找到 begin++; }} |
其实在找关键字key合适位置时,从有序子序列前往后也是可以的,从时间复杂度上一样的,但是个人认为从后往前扫描的代码写出来非常简洁。
算法分析
1 2 3 4 5 6 | 平均时间复杂度:o(N^2)这是显然的,标准的内外两层循环最好时间复杂度:o(N),如果有序,那么每个元素都已经在在它的待排子序列的合适位置,不用找合适位置最坏时间复杂度:o(N^2)空间复杂度:o(1),因为需要常熟个临时变量稳定性:稳定的有人提出在定位关键字的合适位置的时候用二分查找,正好可以利用前面排好的结果(就是在把每个关键字放入到其前面的有序子序列中合适位置时,未必要一个个比较着来找,因为有序子序列是有序的,那么很自然的就可以想到用二分查找来降低时间复杂度),这样每次查找合适位置的时间复杂度就由o(n)降低到了o(log2n)了,但是对于找到后的插入这一操作,还是得挨个挪动数据,仍然为o(n)。这就很尴尬了,你会发现整体的时间复杂度还是o(n^2),并没有用,查找能快又怎么样呢,还是得一个一个挪数据,所以,普通的直接插入排序是没法再优化了。 |
希尔排序
希尔排序是一个叫希尔的数学家提出的一种优化版本直接插入排序
有必要先谈谈这个排序是怎么来的(主要基于以下两点)
在直接插入排序里,对于一组已经有序的关键字序列进行排序时间复杂度是o(n),因为每个元素的合适位置的查找都只需一次就能找到,因为左边的有序子序列的最后一个就小于等于该元素,那么就不需要挪动任何元素,每一趟都只用比较一次就结束了单趟排序。
放宽第一点的情况,我们不要求有序,其实只要待排序列的有序度越高,也就是逆序对越少,直接插入排序的时间复杂度肯定是越低的(这句话是希尔排序的核心)。
基于这两点希尔对直接插入排序进行了这样的优化:先将待排序列分为若干个稀疏的子序列(后面解释),对这些子序列分别进行直接插入排序。经过这一番调整,整个序列的有序度一定会被提高,逆序对一定会变少。最后,再对整个序列进行一趟直接插入排序。
首先选定子序列中各元素的距离,使待排数据中所有间距为为的数据被分成了一组,在各个组内进行直接插入排序,直到。此时我们最后一趟进行的就相当于一次完整的(但是效率很高的)直接插入排序。
过程如
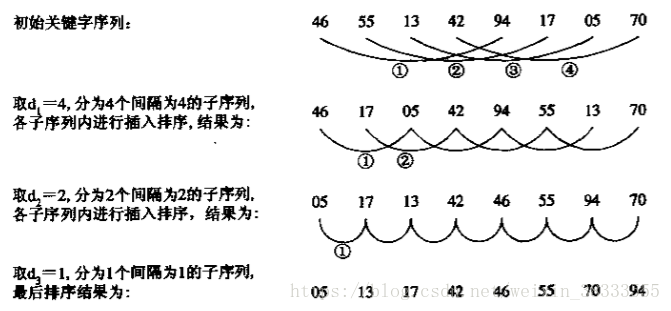
需要注意的是,虽然每次是对各组进行插入排序,但是写代码时候的思维当然不是直接单独对每个组那样直接插入排序依次,而仍然是从前往后扫描,那么显然,我们每次直接插入排序的key从每次的第一个子序列的第二个元素开始(与直接插入排序同理),然后挨个往后走,每个元素时属于哪个组,我们就把它在其所在组进行直接插入排序,上面的例子中,第一次排序中,我们实际进行时就是从94开始往后走的,第二次排序中,我们就是从05开始的,这样代码就非常好写了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | void ShellSort(int* a,int len){ int gap = len; while(gap > 1) { gap = gap/3 + 1; for(int i = gap;i < len;i++) { int key = a[i]; int start = i - gap; while(start >= 0 && key <= a[start])//对当前key进行一趟直接插入排序 { a[start+gap] = a[start]; start -= gap; } a[start + gap] = key; } } } |
希尔排序的时间复杂度相当不好分析,因为其时间复杂度很大程度上取决于增量序列,而的选取至今也没有人找出怎样的一个增量序列是对所有情况的数据分布都有非常不错的效率,我们在代码中选取是一种较为常用、对于大部分数据分布的平均时间复杂度都较为不错的增量序列。
算法分析
平均时间复杂度:o(N^1.3),大量数据研究表明在o(N^1.3)附近,事实上也不是严格论证的结果
最好时间复杂度:仍然和增量序列的选取有关
最坏时间复杂度:o(N^2)
空间复杂度:o(1)
稳定性:不稳定,例如待排序列(3,2,2,1),取时,显然就能看出是不稳定的
简单选择排序
简单选择排序是真的相当简单了,其思想概括来说就是每趟从当前待排序列中选出最小的放在已拍好序列的末尾

指针 记录待排序列的第一个的元素,指针用来找待排序列中最小的那个元素,当然是从i开始,遍历待排序列一趟后,把指针指向的元素与指针指向的元素交换,因为待排序列中又少了一个元素,已排序列末尾又多了一个,因此往后走一个,如此知道待排序列中只剩下一个元素。
这显然效率太低了点,我们忘了它吧。有个明显可以做的优化就是我们每趟遍历可以找出待排序序列中最小和最大的两个,放在待排序列两端,然后缩小待排序列,如此循环直到当前待排序列中只有一个元素。这样效率肯定能稍微好一些,但无疑仍然是平方级的时间复杂度。
代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 | void SelectSort(int* a,size_t len){ int begin = 0; int end = len - 1; int max = 0; int min = 0; while(begin < end) { max = begin,min = begin; for(int i = begin;i <= end;i++) { if(a[i]>=a[max]) //有相同元素时,最大的要找位置相对最后的一个最大的 { max = i; } if(a[i]<a[min]) //最小的要找位置相对最前的一个最小的,这样可以使选择排序算法稳定 { min = i; } } if(max == begin && min == end) { swap(a[max],a[end]); continue; } if(max == begin) { swap(a[max],a[end]); swap(a[min],a[begin]); continue; } if(min == end) { swap(a[min],a[begin]); swap(a[max],a[end]); continue; } swap(a[min],a[begin]); swap(a[max],a[end]); begin++; end--; } } |
注意:找到当前待排序列最大、最小的元素后,要判断是否为最小的在最后,最大的在最前这些情况的组合,稍微分析下就能知道应该怎么交换才是合适的。
算法分析
平均时间复杂度:o(N^2),嵌套双循环
最好时间复杂度:o(N^2),每次要找最大最小肯定是要遍历一遍的
最坏时间复杂度:o(N^2)
空间复杂度:o(1)
稳定性:稳定的(在注释中已解释)
冒泡排序
这应该是所有人在没系统的学习数据结构前就已经熟知的排序算法,它也很简单,而且它的名字非常形象,冒泡排序的思想就是每一趟排序都把大的元素往上浮,具体是这样:从当前待排序列第一个开始遍历,指针从第一个开始,如果当前元素大于下一个,那么二者交换,指针往后走,当走到待排序列末尾时,最大的一定被放到了最后(像冒泡泡一样上去了),然后缩小待排子序列(把最后一个从当前待排序序列删去),如此循环直到当前待排子序列只有一个元素。

有一定可以明显优化的是,如果在某次单趟排序中没有发生元素的交换,可以说明整个待排序列已经有序
代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | void BubbleSort(int* a,size_t len){ int end = len-1; while(end > 0) { bool exchange = false; for(int i = 0;i < end;i++) { if(a[i]>a[i+1]) { swap(a[i],a[i+1]); exchange = true; } } if(exchange == false) return; else exchange = false; end--; }} |
算法分析
- 平均时间复杂度:o(N^2),嵌套双循环
- 最好时间复杂度:o(N),若已经有序,那么第一趟就排好了
- 最坏时间复杂度:o(N^2)
- 空间复杂度:o(1)
- 稳定性:稳定的(在注释中已解释)






【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix