
NoSQL -- Redis
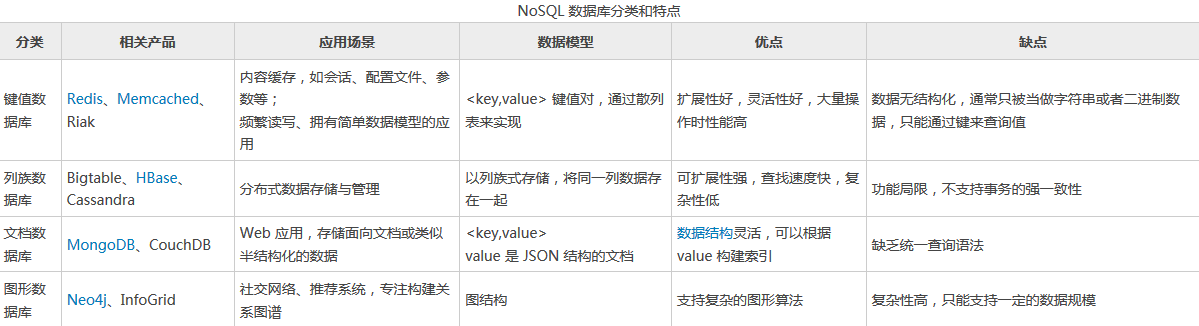
NoSQL简介
大批量用户同时访问后台数据, 数据库压力太大, 那么项目该如何调整才能抵抗这种大用户量访问的问题呢?
NoSQL 数据库的产生就是为了解决大规模数据集合, 多重数据种类带来的挑战。 NoSQL 的提出, 使得互联网应用三高(高并发、 高性能、 高可用) 问题有了一个更简单的解决方案。
NoSQL最常见的解释是“non-relational Structured Query Language” , 泛指非关系型的数据库,区别于关系数据库,它们不保证关系数据的ACID特性。

为什么要使用NoSql
传统的关系数据库具有不错的性能,高稳定型,久经历史考验,而且使用简单,功能强大 , 访问量一般都不大,用单个数据库完全可以轻松应付。在那个时候,更多的都是 静态网页,动态交互类型的网站不多。
(1) 高并发读写
Web2.0网站,数据库并发负载非常高,往往达到每秒上万次的读写请求
(2) 高容量存储和高效存储
Web2.0网站通常需要在后台数据库中存储海量数据,如何存储海量数据并进行高效的查询往往是一个 挑战
MySQL使用Query Cache,每次表的更新Cache就失效,是一种大粒度的 Cache ,Cache性能不高。
而NoSQL的Cache是记录级的,是一种细 粒度的Cache ,NoSQL无需事先为要存储的数据建立字段,随时可以存储自定义的数据格式。
NoSQL数据库都具有非常高的读写性能 ,得益于它的无关系性, 数据库的结构简单
(3) 高扩展性和高可用性
随着系统的用户量和访问量与日俱增,需要数据库能够很方便的进行扩展、维护
NoSQL去掉关系数据库的关系型特性。数据之间无关系,这样就非常容易扩展。也无形之间,在架构的层面上带来了可扩展的能力
NoSQL在不太影响性能的情况,就可以方便的实现高可用的架构。比如Cassandra,HBase模型,通过 复制模型也能实现高可用。
Redis数据库
REmote DIctionary Server(远程字典服务器)。开源免费, 遵守BCD协议。是 一个高性能的(key/value)分布式内存数据库, 基于内存运行并支持持久化的NoSQL数据库, 也被人们称为数据结构服务器。
(1) Redis支持数据的持久化,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用
(2) Redis不仅仅支持简单的key-value类型的数据,同时还提供list,set,zset,hash等数据结构的存储
(3) Redis支持数据的备份,即master-slave(主从)模式的数据备份
优势
(1) 性能极高 – Redis能读的速度是110000次/s,写的速度是81000次/s 。
(2) 丰富的数据类型 – Redis支持二进制案例的 Strings, Lists, Hashes, Sets 及 Ordered Sets 数据类型操作。
(3) 原子 – Redis的所有操作都是原子性的,同时Redis还支持对几个操作全并后的原子性执行。
(4) 丰富的特性 – Redis还支持 publish/subscribe, 通知, key 过期等等特性
(5) 采用单线程,避免了不必要的上下文切换和竞争条件,也不存在多进程或者多线程导致的切换而消耗 CPU,不
用去考虑各种锁的问题,不存在加锁释放锁操作,没有因为可能出现死锁而导致的性能消耗;
(6) 使用多路I/O复用模型,非阻塞IO;
应用场景
(1) 缓存(数据查询,短连接,新闻内容,商品内容等),使用最多
(2) 聊天室在线好友列表
(3) 任务队列(秒杀,抢购,12306等)
(4) 应用排行榜
(5) 网站访问统计
(6) 数据过期处理(可以精确到毫秒)
(7) 分布式集群架构中的session问题
Windows版Github下载地址:https://github.com/MicrosoftArchive/redis/releases
Linux版官网:https://redis.io/
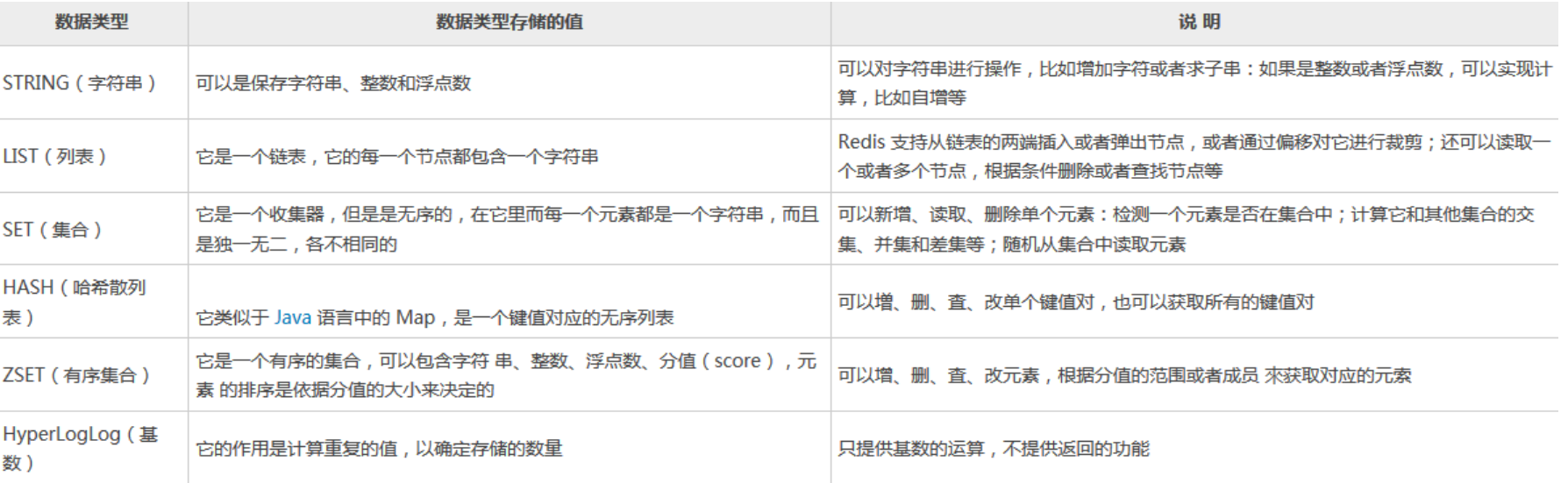
Redis 支持 6 种数据类型,它们分别是字符串(String)、列表(List)、集合(set)、哈希结构
(hash)、有序集合(zset)和基数(HyperLogLog)
Redis 命令参考:http://doc.redisfans.com/index.html
重点:Redis命令、Pub/Sub(发布/订阅)、Transaction(事务)
使用Jedis实现Java连接数据库
或使用jedis连接池连接, 后面会使用Spring的配置文件来整合。
Redis持久化
redis的值放在内存中,为防止突然断电等特殊情况的发生,需要对数据进行持久化备份。即将内存数据保存到硬盘。
RDB持久化 :
RDB 是以二进制文件,是在某个时间点将数据写入一个临时文件,持久化结束后,用这个临时文件替换上次持久化的文件,达到数据恢复。
优点:使用单独子进程来进行持久化,主进程不会进行任何 IO 操作,保证了 redis 的高性能
缺点:RDB 是间隔一段时间进行持久化,如果持久化之间 redis 发生故障,会发生数据丢失。所以这种方式更适合数据要求不严谨的时候
这里说的这个执行数据写入到临时文件的时间点是可以通过配置来自己确定的,通过配置redis 在 n 秒内如果超过m 个 key 被修改这执行一次 RDB 操作。这个操作就类似于在这个时间点来保存一次 Redis 的所有数据,一次快照数据。所有这个持久化方法也通常叫做 snapshots
RDB默认开启,修改redis.conf 中的具体配置参数 进行配置
AOF持久化 :
Append-Only File,将“操作 + 数据”以格式化指令的方式追加到操作日志文件的尾部,在 append 操作返回后(已经写入到文件或者将要写入),才进行实际的数据变更,“日志文件”保存了历史所有的操作过程;当 server 需要数据恢复时,可以直接 replay 此日志文件,即可还原所有的操作过程。AOF 相对可靠,AOF 文件内容是字符串,非常容易阅读和解析。
优点:可以保持更高的数据完整性,如果设置追加 file 的时间是 1s,如果 redis 发生故障,最多会丢失 1s 的数据;且如果日志写入不完整支持 redis-check-aof 来进行日志修复;AOF 文件没被 rewrite 之前(文件过大时会对命令进行合并重写),可以删除其中的某些命令(比如误操作的 flushall)。
缺点:AOF 文件比 RDB 文件大,且恢复速度慢。
我们可以简单的认为 AOF 就是日志文件,此文件只会记录“变更操作”(例如:set/del 等),如果 server 中持续的大量变更操作,将会导致 AOF 文件非常的庞大,意味着 server 失效后,数据恢复的过程将会很长;事实上,一条数据经过多次变更,将会产生多条 AOF 记录,其实只要保存当前的状态,历史的操作记录是可以抛弃的;因为 AOF持久化模式还伴生了“AOF rewrite”
AOF 的特性决定了它相对比较安全,如果你期望数据更少的丢失,那么可以采用 AOF 模式。如果 AOF 文件正在被写入时突然 server 失效,有可能导致文件的最后一次记录是不完整,你可以通过手工或者程序的方式去检测并修正不完整的记录,以便通过 aof 文件恢复能够正常;同时需要提醒,如果你的 redis 持久化手段中有 aof,那么在server 故障失效后再次启动前,需要检测 aof 文件的完整性。
AOF 是文件操作,对于变更操作比较密集的 server,那么必将造成磁盘 IO 的负荷加重;此外 linux 对文件操作采取了“延迟写入”手段,即并非每次 write 操作都会触发实际磁盘操作,而是进入了 buffer 中,当 buffer 数据达到阀值时触发实际写入(也有其他时机),这是 linux 对文件系统的优化,但是这却有可能带来隐患,如果 buffer 没有刷新到磁盘,此时物理机器失效(比如断电),那么有可能导致最后一条或者多条 aof 记录的丢失。
修改配置文件 redis.conf:appendonly yes 进行AOF开启
Redis 的持久化机制是什么?各自的优缺点?
Redis主从复制
持久化保证了即使redis服务重启也不会丢失数据,但是当redis服务器的硬盘损坏了可能会导致数据丢失,通过redis的主从复制机制就可以避免这种单点故障(单台服务器的故障)。
主redis中的数据和从上的数据保持实时同步,当主redis写入数据时通过主从复制机制复制到两个从服务上。主从复制不会阻塞master,在同步数据时,master 可以继续处理client 请求.主机master配置:无需配置
Ø 主机一旦发生增删改操作,那么从机会自动将数据同步到从机中
Ø 从机不能执行写操作,只能读
复制的过程原理
当从库和主库建立MS(master slaver)关系后,会向主数据库发送SYNC命令;
主库接收到SYNC命令后会开始在后台保存快照(RDB持久化过程),并将期间接收到的写命令缓存起来;
快照完成后,主Redis会将快照文件和所有缓存的写命令发送给从Redis;
从Redis接收到后,会载入快照文件并且执行收到的缓存命令;
主Redis每当接收到写命令时就会将命令发送从Redis,保证数据的一致;【内部完成,所以不支持客户端在从机人为写数据。】
哨兵模式:给Redis集群分配一个站岗的。
哨兵的作用就是对Redis系统的运行情况监控,它是一个独立进程,是一个特殊的Redis服务器,在启动一个普通 Redis 服务器时通过给定 --sentinel 选项来启动哨兵(sentinel)。
它的功能:
1. 监控主数据库和从数据库是否运行正常;
2. 主数据出现故障后自动将从数据库转化为主数据库;
如果主机宕机,开启选举工作,选择一个从做主机
Redis集群方案
redis-cluster架构图
(1)所有的redis节点彼此互联(PING-PONG机制),内部使用二进制协议优化传输速度和带宽.
(2)节点的fail是通过集群中超过半数的节点检测有效时整个集群才生效.
(3)客户端与redis节点直连,不需要中间proxy层.客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可
(4)redis-cluster把所有的物理节点映射到[0-16383]slot上,cluster 负责维护node<->slot<->value
Redis 集群中内置了 16384 个哈希槽,当需要在 Redis 集群中放置一个 key-value 时,redis 先对 key 使用 crc16
算法算出一个结果,然后把结果对 16384 求余数,这样每个 key 都会对应一个编号在 0-16383 之间的哈希槽,
redis 会根据节点数量大致均等的将哈希槽映射到不同的节点
redis-cluster投票——心跳机制:容错
(1)集群中所有master参与投票,如果半数以上master节点与其中一个master节点通信超过