

python核心编程
第一章
1. python定义
继承了传统编译语言的强大性和通用性,也借鉴了简单脚本和解释型语言的易用性
2. python起源
1989年底罗萨姆始创了python。他期望有一种工具可以完成日常系统管理任务,并能够访问Amoeba分布式操作系统的系统调用。罗萨姆为此创造出了一种通用的程序设计语言。1991年,python发布了第一个公开发行版。
3. python特点
3.1 高级
语言的升级:汇编语言→C→C++\Java等现代编译语言→可以进行系统调用的解释性脚本语言,perl、python等。
这些语言都有高级的数据结构:
- 比如python有列表(数组)和字典(哈希表)内建于语言本身。
- C中,混杂数组(python中的列表)和哈希表(python中的字典)没有标准库,需要重复实现。
- C++使用标准模板库改善了这一情况,但还是很难与python的列表和字典的简洁和易读相提并论的。
3.2 面向对象
python的面向对象特性是与生俱来的。python不仅是一门面向对象语言,它融合了多种编程风格,比如借鉴了像Lisp这样的函数语言的特性。
3.3 可升级
Python 提倡简洁的代码设计、高级的 数据结构和模块化的组件,这些特点可以让你在提升项目的范围和规模的同时,确保灵活性、 一致性并缩短必要的调试时间。
我们试图用“可升级”来传达一种观 念,这就是:Python 提供了基本的开发模块,你可以在它上面开发你的软件,而且当这些需要扩展和增长时,Python 的可插入性和模块化架构则能使你的项目生机盎然和易于管理
3.4 可移植性
在各种不同的系统上可以看到 Python。
因为 Python 是用 C 写的,又由于 C 的可移植性,使得 Python 可以运行 在任何带有 ANSI C 编译器的平台上。
尽管有一些针对不同平台开发的特有模块,但是在任何一个平台上用 Python 开发的通用软件都可以稍事修改或者原封不动的在其他平台上运行。这种可移植性既适用于不同的架构,也适用于不同的操作系统。
3.5 可扩展
就算项目中有大量的 Python 代码,也可以有条不紊地通过将其分离为多个文件或模块加以组织管理。而且你可以从一个模块中选取代码,而从另一个模块中读取属性。
对于所有模块,Python 的访问语法都是相同的。不管这个模块是标准库的还是自己创建的,哪怕是用其他语言写的扩展。
代码中的瓶颈,可能是在性能分析中总排在前面的那些热门或者一些特别强调性能的地方, 可以作为 Python 扩展用 C 重写。很多时候,使用编译型代码重写程序的瓶颈部分绝对是益处多多的,因为它能明显提升整体性能。
程序设计语言中的这种可扩展性使得工程师能够灵活附加或定制工具,缩短开发周期。
此外,还有像 PyRex 这样的工具,允许 C 和 Python 混合编程,使编写扩展更加轻而易举,因为它会把所有的代码都转换成 C 语言代码。
- Python 的标准实现是使用 C 语言完成的(也就是 CPython),所以要使用 C 和 C++ 编写 Python 扩展。
- Python 的 Java 实现被称作 Jython,要使用 Java 编写其扩展。
- IronPython,这是针对 .NET 或 Mono 平台的 C# 实现。可以使用 C# 或者 VB.Net 扩展 IronPython。
3.6 易学
Python 关键字少、结构简单、语法清晰。
可能感觉比较新鲜的东西可能就是 Python 的面向对象特点了。
3.7 易读
python没有其他语言通常用来访问变量、定义代码块和进行模式匹配的命令式符号。
Python 没有给你多少机会使你能够写出晦涩难懂的代码,而是让其 他人很快就能理解你写的代码,反之亦然。
3.8 易维护
Python 项目的成功很大程度上要归功于其源代码的易于维护。得出这个结论并不难,因为 Python 本身就是易于学习和阅读的。
3.9 健壮性
python允许程序员在错误发生的时候根据出错条件提供处理机制。
一旦程序由于错误崩溃,解释程序就会转出一个“堆栈跟踪”,那里面有可用到的全部信息,包括你程序崩溃的原因以及那段代码(文件名、行数、行数调用等等)出错了。这些错误被称为异常。如果在运行时发生这样的错误,Python 使你能够监控这些错误并进行处理。
这些异常处理可以采取相应的措施,例如解决问题、重定向程序流、执行清除或维护步骤、 正常关闭应用程序、亦或干脆忽略掉。
3.10 高效的快速原型开发工具
与那些封闭僵化的语言不同,Python 有许多面向其他系统的接口,它的功能足够强大和强壮,所以完全可以使用 Python 开发整个系统的原型。
显然, 传统的编译型语言也能实现同样的系统建模,但是 Python 工程方面的简洁性可以在同样的时间内游刃有余的完成相同的工作。
此外,大家已经为 Python 开发了为数众多的扩展库,无论你打算开发什么样的应用程序,都可能找到先行的前辈。你所要做的全部事情,就是来 个“即插即用”!
3.11 内存管理器
C 或者 C++最大的弊病在于内存管理是由开发者负责的。
Python 中,由于内存管理是由 Python 解释器负责的,所以开发人员就可以从内存事务中解放出来,全神贯注于最直接的目标,仅仅致力于开发计划中首要的应用程序。这会使错误更少、程序更健壮、开发周期更短。
3.12 解释器和(字节)变异性
Python 是一种解释型语言,这意味着开发过程中没有了编译这个环节。
由于不是以本地机器码运行,纯粹的解释型语言通常比编译型语言运行的慢。
然而,类似于 Java,Python 实际上是字节编译的,其结果就是可以生成一种近似机器语言的中间形式。这不仅改善了 Python 的性能,还同时使它保持了解释型语言的优点。
Python 源文件通常用.py 扩展名。当源文件被解释器加载或者显式地进行字节码编译的时候会被编译成字节码。由于调用解释器的方式不同,源文件会被编译成带有.pyc 或.pyo 扩展名的文件。
4. 下载和安装python
得到所有 Python 相关软件:去访问它的网站(http://python.org)
Python 的可应用平台非常广泛。可以将其划分成如下的几大类和可用平台:
- 所有 Unix 衍生系统(Linux,MacOS X,Solaris,FreeBSD 等等)
- Win32 家族(Windows NT,2000,XP 等等)
- 早期平台:MacOS 8/9,Windows 3.x,DOS,OS/2,AIX
- 掌上平台(掌上电脑/移动电话):Nokia Series 60/SymbianOS,Windows CE/PocketPC,Sharp Zaurus/arm-linux,PalmOS
- 游戏控制台:Sony PS2,PSP,Nintendo GameCube
- 实时平台:VxWorks,QNX
- 其他实现版本:Jython,IronPython,stackless
- 其他
一些平台有其对应二进制版本, 可以直接安装,另外一些则需要在安装前手工编译。
Unix 衍生系统(Linux,MacOS X,Solaris,FreeBSD 等等)
基于 Unix 的系统可能已经安装了 Python。通过命令行运行 Python,查看它是否在搜索路径中而且运行正常。
Windows/DOS 系统
首先从前文提到的 python.org 网站下载 msi 文件(例如,python-2.5.msi),之后执行该文件安装 Python。
如果打算开发 Win32 程序,例如使用 COM 或 MFC,或需要 Win32 库,强烈建议下载并安装 Python 的 Windows 扩展。
之后就可以通过 DOS 命令行窗口或者 IDLE 和 Pythonwin 中的一个来运行 Python 了,IDLE 是 Python 缺省的 IDE(Integrated Development Environment,集成开发环境),而 Pythonwin 则来自 Windows 扩展模块。
自己动手编译 Python
对绝大多数其它平台 , 下载 .tgz 文件, 解压缩这些文件, 执行以下操作以编译Python:
1. ./configure
2. make
3. make install
关于安装位置
如今,在系统上安装多种版本的 Python 比较常见。要设置好库文件的安装位置。
- Unix 中,可执行文件通常会将 Python 安装到/usr/local/bin 子目录下,而库文件则通常安装在/usr/local/lib/python2.x 子目录下,其中的 2.x 是你正在使用的版本号。
- MacOS X 系统中,Python 则安装在/sw/bin 以及/或者 /usr/local/bin 子目录下。而库文件则在/sw/lib,/usr/local/lib, 以及/或者 /Library/Frameworks/Python.framework/Versions子 目录下。
- Windows 中,默认的安装地址是 C:\Python2x。请避免将其安装在 C:\Program Files 目录下(虽然这是通常安装程序的文件夹)。DOS 是不支持“Program Files” 这样的长文件名的,它通常会被用“Progra~1”这个别名代替。这有可能给程序运行带来一些麻烦。所以,将 Python 安装在 C:\Python 目录下,这样标准库文件就会被安装在 C:\Python\Lib 目录下。
5. 运行python
有三种不同的办法来启动 Python:
- 最简单的方式就是交互式的启动解释器,每次输入一行Python 代码来执行。
- 另外一种启动 Python 的方法是运行 Python 脚本。这样会调用相关的脚本解释器。
- 最后一种办法就是用集成开发环境中的图形用户界面运行 Python。集成开发环境通常整合了其他的工具,例如集成的调试器、文本编辑器,而且支持各种像 CVS 这样的源代码版本控制工具。
5.1 命令行上的交互式解释器
在命令行上启动解释器,你马上就可以开始编写 Python 代码。
-
Unix 衍生系统(Linux,MacOS X,Solaris,FreeBSD 等等)
1.1 将 Python 所在路径添加到系统搜索路径之中就可以直接输入python启动python, 否则就必须输入Python的完整路径名才可以启动Python。Python一般安装在 /usr/bin 或/usr/local/bin子目录中。
1.2 如何将 Python 添加到搜索路径中:检查登录启动脚本, 找到以 set path 或 PATH= 指令开始,后面跟着一串目录的那行, 然后添加解释器的完整路径。更新一下 shell 路径变量。 -
Windoes/DOS 环境
2.1 如何将 Python 添加到搜索路径中:编辑 C:\autoexec.bat 文件并将完整的 Python 安装路径添加其中,一般是 C:\Python 或 C:\Program Files\Python(或者它在 DOS 中的简写 名字 C:\Progra~1\Python)。然后直接输入python就可以启动python
5.2 从命令行启动脚本
《Unix 衍生系统(Linux,MacOS X,Solaris,FreeBSD 等等)》
- 不管哪种 Unix 平台, Python 脚本都可以象下面这样,在命令行上通过解释器执行:
$ python script.py
- Unix 平台还可以在指定 Python 解释器的情况下,自动执行 Python 解释器。如果你使用的是类 Unix 平台, 可以 在脚本的第一行使用 shell 魔术字符串(“sh-bang”) ,在 #!之后写上 Python 解释器的完整路径:
#!/usr/local/bin/python
- 有一个更好的方案, 许多 Unix 系统有一个命令叫 env, 位于 /bin 或 /usr/bin 中。它会帮你在系统搜索路径中找到 python 解释器。如果你的系统拥有 env, 你的启动行就可以改为下面这样
#!/usr/bin/env python
或者, 如果你的 env 位于 /bin 的话,
#!/bin/env python
当你不能确定 Python 的具体路径或者 Python 的路径经常变化时(但不能挪到系统搜索路径之外), env 就非常有用。
在脚本首行书写了合适的启动指令之后, 这个脚本就能够直接执行。当调用脚本时, 会先载入 Python 解释器, 然后运行脚本:
script.py
注意, 在键入文件名之前, 必须先将这个文件的属性设置为可以执行。在文件列表中, 你的文件应该将它设置为自己拥有 rwx 权限。
《Windows/DOS 环境》
DOS 命令窗口不支持自动执行机制,不过至少在 WinXP 当中, 它能象在 Windows 中一样 做到通过输入文件名执行脚本: 这就是“文件类型”接口。这个接口允许 Windows 根据文件扩 展名识别文件类型, 从而调用相应的程序来处理这个文件。举例来说, 如果你安装了带有 PythonWin 的 Python, 双击一个带有 .py 扩展名的 Python 脚本就会自动调用 Python 或 PythonWin IDE(如果你安装了的话)来执行你的脚本。 运行以下命令就和双击它的效果一样:
C:\> script.py
这样无论是基于 Unix 操作系统还是 Win32 操作系统都可以无需在命令行指定 Python 解释器的情况下运行脚本,但是如果调用脚本时,得到类似“命令无法识别”之类的错误提示 信息,你也总能正确处理。
5.3 集成开发环境
TODO
5.4 其它的集成开发环境和执行环境
TODO
6. python文档
- 最便捷的方式就是从 Python 网站查看在线文档。
- 如果使用的是 Win32 系统,在 C:\Python2x\Doc\目录下会找到一个名为 Python2x.chm 的离线帮助文档。其他的离线文档包括 PDF 和 PostScript (PS)文件。
- 如果下载了 Python 发行版,你会得到 LaTeX 格式的源文件。
- 在本书的网站中,创建了一个包括绝大多数 Python 版本的文档,只要访问 http://corepython.com,单击左侧的“Documentation”就可以了。《都是英文的,可以找找对应的中文文档》

7. 比较python
TODO
8. 其他实现
TODO
第二章 python起步
在所有的交互示例中, 会看到 Python 的主提示符( >>> )和次提示符( ... )。主提示符是解释器告诉你它在等待你输入下一个语句,次提示符告诉你解释器正在等待你输入当前语句的其它部分。
- 语句:语句使用关键字来组成命令,类似告诉解释器一个命令。你告诉 Python 做什么,它就为你做什么,语句可以有输 出,也可以没有输出。eg:print 'Hello World!'
- 表达式(函数、算术表达式等):表达式没有关键字。它们可以是使用数学运算符构成的算术表达式,也可以是使用括号 调用的函数。它们可以接受用户输入,也可以不接受用户输入,有些会有输出,有些则没有。
本章中我们将分别介绍语句和表达式
2.1 程序输出,print语句及“HelloWorld!”
在交互式解释器中显示变量的值
在交互式解释器中, 用 print 语句显示变量的字符串表示,或者仅使用变量名查看该变量的原始值。
eg:把一个字符串赋值给变量 myString,先用 print 来显示变量的内容, 之后用变量名称来显示。
>>> myString = 'Hello World!'
>>> print myString
Hello World! # 在仅用变量名时,输出的字符串是被用单引号括起来了的。这是为了让非字符串对象也能以字符串的方式显示在屏幕上--即它显示的是该对象的字符串表示,而不仅仅是字符串本身
>>> myString
'Hello World!' # 引号表示你刚刚输入的变量的值是一个字符串
等你对 Python 有了较深入的了解之后, 你就知道 print 语句调用 str()函数显示对象,而交互式解释器则调用 repr()函数来显示对象。
2.2 程序输入和 raw_input()内建函数
下划线(_)在解释器中表示最后一个表达式的值。上面的代码执行之后, 下划线变量会包含字符串:
>>> _
Hello World!
Python的print语句,与字符串格式运算符( %)结合使用,可实现字符串替换功能
>>> print "%s is number %d!" % ("Python", 1)
Python is number 1!
- %s 表示由一个字符串来替换,而%d 表示由一个整数来替换,另外一个很常用的就是%f, 它 表示由一个浮点数来替换。
- Python 非常灵活,所以即使 你将数字传递给 %s,也不会像其他要求严格的语言一样引发严重后果。
Print 语句也支持将输出重定向到文件。符号 >> 用来重定向输出,下面这个例子将输出重定向到标准错误输出:
import sys
print >> sys.stderr, 'Fatal error: invalid input!'
# 下面是一个将输出重定向到日志文件的例子:
logfile = open('/tmp/mylog.txt', 'a')
print >> logfile, 'Fatal error: invalid input!'
logfile.close()
从用户那里得到数据输入的最容易的方法是使用 raw_input()内建函数。它读取标准输入,并将读取到的数据赋值给指定的变量。 可以使用 int() 内建函数将用户输入的字符串转换为整数。
# 文本输入
>>> user = raw_input('Enter login name: ')
Enter login name: root
# 数字输入
>> num = raw_input('Now enter a number: ')
Now enter a number: 1024
>>> print 'Doubling your number: %d' % (int(num) * 2)
Doubling your number: 2048
如果需要得到一个生疏函数的帮助,只需要对它调用内建函数help()。通过用函数名作为 help()的参数就能得到相应的帮助信息。
>>> help(raw_input)
Help on built-in function raw_input in module __builtin__:
raw_input(...) raw_input([prompt]) -> string
核心风格: 一直在函数外做用户交互操作
新手在需要显示信息或得到用户输入时, 很容易想到使用 print 语句和 raw_input()内建函数。不过在此建议函数应该保持其清晰性, 也就是它只应该接受参数,返回结果。从用户那里得到需要的数据, 然后调用函数处理, 从函数得到返回值,然后显示结果给用户。 这样你就能够在其它地方也可以使用你的函数而不必担心自定义输出的问题。这个规则的一个例外是,如果函数的基本功能就是为了得到用户输出, 或者就是为了输出信息,这时在函数体使 用 print 语句或raw_input() 也未尝不可。
更重要的,将函数分为两大类:
- 一类只做事,不需要返回值(比如与用户交互或设置变量的值),
- 另一类则执行一些运算,最后返回结果。
如果输出就是函数的目的,那么在函数体内使用 print 语句也是可以接受的选择。
2.3 注释
- Python 使用 # 符号标示注释;
- 有一种叫做文档字符串的特别注释。可以在模块、类或者函数的起始添加一个字符串,起到在线文档的功能;与普通注释不同,文档字符串可以在运行时访问,也可以用来自动生成文档;
def foo():
"This is a doc string."
return True
2.4 运算符
标准算术运算符
+ - * / // % **
Python 有两种除法运算符,单斜杠用作传统除法, 双斜杠用作浮点除法(对结果进行四舍五入)。
- 单斜杠:传统除法是指如果两个操作数都是整数的话, 它将执行是地板除(取比商小的最大整数);
- 双斜杠:浮点除法是真正的除法,不管操作数是什么类型,浮点除法总是执行真正的除法;
运算符的优先级和你想象的一样: + 和 - 优先级最低, *, /, //, %优先级较高, 单目运算符 + 和 - 优先级更高, 乘方的优先级最高。
标准比较运算符
比较运算根据表达式的值的真假返回布尔值:
< <= > >= == != <>
Python 支持两种“不等于”比较运算符, != 和 <> , 分别是 C 风格和 ABC/Pascal 风格。后者慢慢地被淘汰了。
逻辑运算符
and or not
使用逻辑运算符可以将任意表达式连接在一起,并得到一个布尔值。
>>> 3 < 4 < 5
True
# 这个例子在其他语言中通常是不合法的,不过 Python 支持这样的表达式, 既简洁又优美。
核心风格: 合理使用括号增强代码的可读性,在没用括号的话,会使程序得到错误结果,或使代码可读性降低,引起阅读者困惑。
2.5 变量和赋值
变量名命名规则:
- 字母开头的标识符--意指大写或小写字母,其它的字符可以是数字,字母, 或下划线。
- Python 变量名是大小写敏感的, 也就是说变量 "cAsE" 与 "CaSe" 是两个不同的变量。
Python 是动态类型语言,不需要预先声明变量的类型。 变量的类型和值在赋值那一刻被初始化。变量赋值通过=来执行。
Python 也支持增量赋值,也就是运算符和等号合并在一起。
n = n * 10
等同于
n *= 10
Python 不支持 C 语言中的自增 1 和自减 1 运算符, 这是因为 + 和 - 也是单目运算符, Python 会将 --n 解释为-(-n) 从而得到 n , 同样 ++n 的结果也是 n.
2.6 数字
Python 支持五种基本数字类型,其中有三种是整数类型:
- int (有符号整数)
- long (长整数)
- bool (布尔值)
- float (浮点值)
- complex (复数)
- Python 的长整数所能表达的范围远远超过 C 语言的长整数, Python 长整数仅受限于用户计算机的虚拟内存总数。
- 从 Python2.3 开始,再也不会报整型溢出错误, 结果会自动的被转换为长整数。
- 尽管布尔值由常量 True 和 False 来表示, 若将布尔值放到一个数值上下文环境中(比方将 True 与一个数字相加), True 会被当成整数值 1, 而 False 则会被当成整数值 0。
- 复数(包括-1 的平方根, 即所谓的虚数)在其它语言中通常不被直接支持(一般通过类来实现)。
- decimal, 用于十进制浮点数。不过它并不是内建类型,须先导入 decimal 模块才可以使用这种数值类型。
由于需求日渐强烈, Python 2.4 增加 了这种类型。举例来说,由于在二进制表示中有一个无限循环片段,数字 1.1 无法用二进制浮 点数精确表示。因此, 数字 1.1 实际上会被表示成:
>>> 1.1
1.1000000000000001
>>> print decimal.Decimal('1.1')
1.1
2.7 字符串
- Python 支持使用成对的单引号或双引号, 三引号(三个连续的单引号或者双引号)可以用来包含特殊字符。
- 使用索引运算符( [ ] )和切 片运算符( [ : ] )可以得到子字符串。
- 字符串有其特有的索引规则:第一个字符的索引是 0, 最后一个字符的索引是 -1。
- 加号( + )用于字符串连接运算。
- 星号( * )则用于字符串重复。
>>> pystr = 'Python'
>>> pystr[0]
'P'
>>> pystr[2:5]
'tho'
>>> pystr + iscool
'Pythonis cool!'
>>> pystr * 2
'PythonPython'
2.8 列表和元组
可以将列表和元组当成普通的“数组”,它能保存任意数量任意类型的 Python 对象。通过从 0 开始的数字索引访问元素,但是列表和元组可以存储不同类型的对象。
列表和元组有几处重要的区别:
- 列表元素用中括号( [ ])包裹,元素的个数及元素的值可以改变。
- 元组元素用小括号(( ))包裹,不可以更改(尽管他们的内容可以)。元组可以看成是只读的列表。
通过切片运算( [ ] 和 [ : ] )可以得到子集。
2.9 字典
字典是 Python 中的映射数据类型,工作原理类似 Perl 中的关联数组或者哈希表,由键- 值(key-value)对构成。
- 几乎所有类型的 Python 对象都可以用作键,不过一般还是以数字或者 字符串最为常用。
- 值可以是任意类型的 Python 对象,字典元素用大括号({ })包裹。
>> aDict = {'host': 'earth'} # create dict
>>> aDict['port'] = 80 # add to dict
>>> aDict
{'host': 'earth', 'port': 80}
>>> aDict.keys()
['host', 'port']
>>> aDict['host']
'earth'
>>> for key in aDict:
... print key, aDict[key] ...
2.10 代码块及缩进对齐
代码块通过缩进对齐表达代码逻辑而不是使用大括号,因为没有了额外的字符,程序的可读性更高。
2.11 if语句
标准 if 条件语句的语法如下:
if expression:
if_suite
else:
else_suite
如果表达式的值非 0 或者为布尔值 True, 则代码组 if_suite 被执行; 否则就去执行else_suit。
elif (意指 “else-if ”)语句,语法如下:
if expression1:
if_suite
elif expression2:
elif_suite
else:
else_suite
2.12 while 循环
语句 while_suite 会被连续不断的循环执行, 直到表达式的值变成 0 或 False; 接着 Python 会执行下一句代码。
while expression:
while_suite
2.13 for循环和range()内建函数
Python 中的 for 循环与传统的 for 循环(计数器循环)不太一样,Python 中的 for 接受可迭代对象(例如序列或迭代器)作为其参数,每次 迭代其中一个元素。
>> for item in ['e-mail', 'net-surfing', 'homework',
'chat']:
... print item
...
e-mail
net-surfing
homework
chat
- print 语句默认会给每一行添加一个换行符。只要在 print 语句的最后添加一个逗号(,), 就可以改变它这种行为
- 一个额外的没有任何参数的 print 语句, 它用来输出一个换行符
- 逗号的 print 语句输出的元素之间会自动添加一个空格.
>>> print()
>>> print("abc", "efg", "hij")
abc efg hij
>>>
Python 提供了一个 range()内建函数来生成列表.
>>> for eachNum in range(3):
... print eachNum
...
0
1
2
字符串迭代
>> foo = 'abc'
>>> for c in foo:
... print c
...
a
b
c
# range()函数经常和 len()函数一起用于字符串索引。 在这里我们要显示每一个元素及其索引值:
>>> foo = 'abc'
>>> for i in range(len(foo)):
... print foo[i], '(%d)' % i
...
a (0)
b (1)
c (2)
# enumerate() 函数可以同时循环索引和元素
>>> for i, ch in enumerate(foo):
... print ch, '(%d)' % i
...
a (0)
b (1)
c (2)
2.13 列表解析
可以在一行中使用一个 for 循环将所有值放到一个列表当中:
> squared = [x ** 2 for x in range(4)] >>> for i in squared:
... print i
0
1
4
9
列表解析甚至能做更复杂的事情, 比如挑选出符合要求的值放入列表:
>>> sqdEvens = [x ** 2 for x in range(8) if not x % 2]
>>>
>>> for i in sqdEvens:
... print i
0
4
16
36
2.15 文件和内建函数open()、file()
如何打开文件
handle = open(file_name, access_mode = 'r')
- access_mode 中 'r' 表示读取, 'w' 表示写入, 'a' 表示添加。其他:'+' 表示读写, 'b'表示二进制访 问。如果未提供 access_mode , 默认值为 'r'。
- 如果 open() 成功, 一个文件对象句柄会被返回。所有后续的文件操作都必须通过此文件句柄进行。当一个文件对象返回之后, 就可以访问它的一些方法, 比如 readlines() 和 close().
filename = raw_input('Enter file name: ')
fobj = open(filename, 'r')
for eachLine in fobj:
print eachLine,
fobj.close()
代码没有用循环一次取一行显示。而是一次读入文件的所有行, 然后关闭文件, 再迭代每一行输出。这样的好处是快速完整的访问文件,这样代码更清晰。
需要注意的是文件的大小。 上面的代码适用于文件大小适中的文件。对于很大的文件来说, 上面的代码会占用太多的内存, 这时最好一次读一行。
代码在 print 语句中使用逗号来抑制自动生成的换行符号, 因为文件中的每行文本已经自带了换行字符。
file()内建函数是最近才添加到 Python 当中的。它的功能等同于 open(), 不过 file() 这个名字可以更确切的表明它是一个工厂函数。(生成文件对象)类似 int()生成整数对象,dict()生成字典对象。
2.16 错误和异常
Python 允许在程序运行时检测错误。当检测到一个错误, Python 解释器就引发一个异常, 并显示异常的详细信息。可以根据这些信息迅速定位问题并进行调试, 并找出处理错误的办法。
要给代码添加错误检测及异常处理, 只要将它们封装在 try-except 语句当中。 try 之后的代码组, 就是要管理的代码。 except 之后的代码组, 则是处理错误的代码。
try:
filename = raw_input('Enter file name: ')
fobj = open(filename, 'r')
for eachLine in fobj:
print eachLine, fobj.close()
except IOError, e:
print 'file open error:', e
程序员也可以通过使用 raise 语句故意引发一个异常。
2.17 函数
Python 中的函数使用小括号( () )调用。函数在调用之前必须先定义。 如果函数中没有 return 语句, 就会自动返回 None 对象。
Python 是通过引用调用的。 这意味着函数内对参数的改变会影响到原始对象。不过事实上只有可变对象会受此影响, 对不可变对象来说, 它的行为类似按值调用。
如何定义函数
def function_name([arguments]):
"optional documentation string"
function_suite # 函数体的代码组
如何调用函数
def addMe2Me(x):
'apply + operation to argument'
return (x + x)
>>> addMe2Me(4.25)
8.5
>>>
>>> addMe2Me(10)
20
>>>
>>> addMe2Me('Python')
'PythonPython'
>>>
>>> addMe2Me([-1, 'abc'])
[-1, 'abc', -1, 'abc']
注意一下, + 运 算符在非数值类型中如何工作。
默认参数
函数的参数可以有一个默认值, 如果提供有默认值,在函数定义中, 参数以赋值语句的形式提供。事实上这仅仅是提供默认参数的语法,它表示函数调用时如果没有提供这个参数,它就取这个值做为默认值。
>>> def foo(debug=True):
... 'determine if in debug mode with default argument'
... if debug:
... print 'in debug mode'
... print 'done'
...
>>> foo()
in debug mode
done
>>> foo(False)
done
如果没有传递参数给函数 foo(), debug 自动拿到一个值, True. 在第二次调用 foo()时, 传递一个参数 False 给 foo(),默认参数就没有被使用。
2.18 类
类是面向对象编程的核心, 它扮演相关数据及逻辑的容器角色。它们提供了创建“真实” 对象(也就是实例)的蓝图。
如何定义类
class ClassName(base_class[es]):
"optional documentation string"
static_member_declarations
method_declarations
使用 class 关键字定义类。可以提供一个可选的父类或者说基类; 如果没有合适的基类,那就使用 object 作为基类。
class FooClass(object):
"""my very first class: FooClass"""
version = 0.1 # class (data) attribute
def __init__(self, nm='John Doe'):
"""constructor"""
self.name = nm # class instance (data) attribute
print 'Created a class instance for', nm
def showname(self):
"""display instance attribute and class name""" print 'Your name is', self.name
print 'My name is', self.__class__.__name__
def showver(self):
"""display class(static) attribute"""
print self.version # references FooClass.version def addMe2Me(self, x): # does not use 'self' """apply + operation to argument"""
return x + x
def addMe2Me(self, x): # does not use 'self' """apply + operation to argument"""
return x + x
该类定义了一个静态变量 version, 它将被所有实例及四个方法共享. _init_()方法是一个特殊名字, 所有名字开始和结束都有两个下划线的方法都是特殊方法。
当一个类实例被创建时, _init_()方法会自动执行, 在类实例创建完毕后执行, 类似构建函数。_init_()可以被当成构建函数, 不过不象其它语言中的构建函数, 它并不创建实例--它仅仅是对象创建后执行的第一个方法。它的目的是执行一些该对象的必要的初 始化工作。通过创建自己的 _init_()方法覆盖默认的_init_()方法(默认的方法什么也不做),从而能够修饰刚刚创建的对象。这个例子初始化了一个名为 name 的类实例属性(或者说成员)。这个变量仅在类实例中存在, 它并不是实际类本身的一部分。_init_()需要一个默认的参数。你也注意到每个方法都有 的一个参数, self。
什么是 self ? 它是类实例自身的引用。其他语言通常使用一个名为 this 的标识符。
如何创建类
>>> foo1 = FooClass()
Created a class instance for John Doe
>>> foo1.showname() Your name is John Doe
My name is __main__.FooClass
>>>
>>> foo1.showver()
0.1
>>> print foo1.addMe2Me(5)
10
>>> print foo1.addMe2Me('xyz')
屏幕上显示的字符串正是自动调用 __init__() 方法的结果。
在 showname()方法中,显示 self._class_._name_ 变量的值。对一个实例来说, 这个变量表示实例化它的 类的名字。(self.__class__引用实际的类)。
2.19 模块
模块是一种组织形式, 它将彼此有关系的 Python 代码组织到一个个独立文件当中。模块的名字就是不带 .py 后缀的文件名。一个模块创建之后, 你可以从另一个模块中使用 import 语句导入这个模块来使用。
# 导入模块
import module_name
# 一旦导入完成, 一个模块的属性(函数和变量)可以通过句点访问。
module.function()
module.variable
# 举例
>>> import sys
>>> sys.stdout.write('Hello World!\n')
Hello World!
>>> sys.platform
'win32'
>>> sys.version
'2.4.2 (#67, Sep 28 2005, 10:51:12) [MSC v.1310 32 bit
(Intel)]'
代码的输出与 print 语句完全相同。 唯一的区别在于这次调用了标准输出 的 write()方法,而且需要显式的在字符串中提供换行字符,write() 不会自动在字符串后面添加换行符号。
核心笔记:什么是“PEP”?
一个 PEP 就是一个 Python 增强提案(PythonEnhancement Proposal), 这也是在新版 Python 中增加新特性的方式。 它们不但提供了新特性的完整描述, 还有添加这些新特性的理由, 如果需要的话, 还会提供新的语法、 技术实现细节、向后兼容信息等等。在一个新特性被整合进 Python 之前,必须通过 Python 开发社区,PEP 作者及实现者,还有 Python 的创始人,Guido van Rossum(Python 终身的仁慈的独裁者)的一致同意。PEP1 阐述了 PEP 的目标及书写指南。 在 PEP0 中可以找到所有的 PEP。 PEP 索引的网址是: http://python.org/dev/peps.
2.19 实用的函数
本章实用的内建函数
表 2.1 对新 Python 程序员有用的内建函数
函数 描述
dir([obj]) 显示对象的属性,如果没有提供参数, 则显示全局变量的名字
help([obj]) 以一种整齐美观的形式 显示对象的文档字符串, 如果没有提供任何参 数, 则会进入交互式帮助。
int(obj) 将一个对象转换为整数
len(obj) 返回对象的长度
open(fn, mode) 以 mode('r' = 读, 'w'= 写)方式打开一个文件名为 fn 的文件
range([[start,]stop[,step]) 返回一个整数列表。起始值为 start, 结束值为 stop - 1; start 默认值为 0, step默认值为1。
raw_input(str) 等待用户输入一个字符串, 可以提供一个可选的参数 str 用作提示信 息。
str(obj) 将一个对象转换为字符串
type(obj) 返回对象的类型(返回值本身是一个 type 对象!
语句和语法
变量赋值
标识符和关键字
基本风格指南
内存管理
第一个 Python 程序
第三章
3.1 语句和语法
Python 语句中有一些基本规则和特殊字符:
- 井号(#)表示之后的字符为 Python 注释
- 换行 (\n) 是标准的行分隔符(通常一个语句一行)
- 反斜线 ( \ ) 继续上一行
- 分号 ( ; )将两个语句连接在一行中
- 冒号 ( : ) 将代码块的头和体分开
- 语句(代码块)用缩进块的方式体现
- 不同的缩进深度分隔不同的代码块
- Python文件以模块的形式组织
3.1.1 注释( # )
注释语句从 # 字符开始,注释可以在一行的任何地方开始,解释器会忽略掉该行 # 之后的所有内容。
3.1.2 继续( \ )
一行过长的语句可以使用反斜杠( \ ) 分解成几行,如下例:
# check conditions
if (weather_is_hot == 1) and \
(shark_warnings == 0):
send_goto_beach_mesg_to_pager()
有两种例外情况一个语句不使用反斜线也可以跨行。
- 在使用闭合操作符时,单一语句可以跨多行,例如:在含有小括号、中括号、花括号时可以多行书写。
- 三引号包括下的字符串也可以跨行书写。
# display a string with triple quotes
print'''hi there, this is a long message for you
that goes over multiple lines... you will find
out soon that triple quotes in Python allows
this kind of fun! it is like a day on the beach!'''
# set some variables
go_surf, get_a_tan_while, boat_size, toll_money = (1,'windsurfing', 40.0, -2.00)
如果要在使用反斜线换行和使用括号元素换行作一个选择,推荐使用括号,这样可读 性会更好。
3.1.3 多个语句构成代码组
缩进相同的一组语句构成一个代码块,我们称之代码组。像 if、while、def 和 class 这样 的复合语句,首行以关键字开始,以冒号( : )结束,该行之后的一行或多行代码构成代码组。 我们将首行及后面的代码组称为一个子句(clause)。
3.1.4 代码组由不同的缩进分隔
代码的层次关系是通过同样深度的空格或制表符缩进体现的。同一代码组的代码行必须严格左对齐(左边有同样多的空格或同样多的制表符),如果不严格遵守这个规则,同一组的代码就可能被当成另一个组,甚至 会导致语法错误。
核心风格:缩进四个空格宽度,避免使用制表符
缩进多大宽度才合适?两个太少,六到八个又太多,推荐使用四个空格宽度。不同的文本编辑器中制表符代表的空白宽度不一,如果你的代码要跨平台应用,或者会被不同的编辑器读写,建议不要使用制表符。使用空格或制表符这两种风格都得到了 Python 创始人 Guido van Rossum 的支持,并被收录到 Python 代码风格指南文档。
使用缩进对齐这种方式组织代码,风格优雅,大大提高了代码的可读性。 而且它有效的避免了"悬挂 else"(dangling-else)问题,和未写大括号的单一子句问题。
3.1.5 同一行书写多个语句
分号( ; )允许将多个语句写在同一行上,语句之间用;隔开,而这些语句也不能在这行开始一个新的代码块。
import sys; x = 'foo'; sys.stdout.write(x + '\n')
同一行上书写多个语句会大大降低代码的可读性,Python 虽然允许但不提倡你这么做。
3.1.6 模块
每一个 Python 脚本文件都可以被当成是一个模块。当一个模块变得过大,并且驱动了太多功能的话,就应该考虑拆一些代码出来另外建一个模块。模块里的代码可以是一段直接执行的脚本,也可以是一堆类似库函数的代码,从而可以被别的模块导 入(import)调用。
3.2 变量赋值
赋值运算符
等号(=)是主要的赋值运算符。
anInt = -12
aString = 'cart'
aFloat = -3.1415 * (5.0 ** 2)
anotherString = 'shop' + 'ping'
aList = [3.14e10, '2nd elmt of a list', 8.82-4.371j]
赋值并不是直接将一个值赋给一个变量。Python 语言中,对象是通过引用传递的。在赋值时,不管这个对象是新创建的,还 是一个已经存在的,都是将该对象的引用(并不是值)赋值给变量。如果此刻你还不是 100%理解清楚。 在本章的后面部分,我们还会再讨论这个话题。
>>> x = 1
>>> y = (x = x + 1) # assignments not expressions! File "<stdin>", line 1
y = (x = x + 1)
^
SyntaxError: invalid syntax
链式赋值没问题
>>> y = x = x + 1
>>> x, y
(2, 2)
增量赋值
+=
-=
*=
/=
%=
**=
<<=>>=
&=
^=
|=
等号可以和一个算术运算符组合在一起, 将计算结果重新赋值给左边的变量。这被称为增量赋值。
x=x+1
# 现在可以被写成:
x += 1
增量赋值相对普通赋值不仅仅是写法上的改变,最有意义的变化是第一个对象(我们例子中的 A)仅被处理一次。可变对象会被就地修改(无修拷贝引用)。不可变对象则和 A = A +B 的结果一样(分配一个新对象)
>>> m = 12
>>> m %= 7
>>> m
5
>>> m **= 2
>>> m
25
>>> aList = [123, 'xyz']
>>> aList += [45.6e7]
>>> aList
[123, 'xyz', 456000000.0]
Python 不支持类似 x++ 或 --x 这样的前置/后置自增/自减运算。
多重赋值
>>> x = y = z = 1
>>> x
1
>>> y
1
>>> z 1
一个值为 1 的整数对象被创建,该对象的同一个引用被赋值给 x、y 和 z 。也就是将一个对象赋给了多个变量。在 Python 当中,将多个对象赋给多个变量也是可以的。
“多元”赋值
采用这种方式赋值时, 等号两边的对象都是元组。
>>> x, y, z = 1, 2, 'a string'
>>> x
1
# 通常元组需要用圆括号(小括号)括起来,尽管它们是可选的。建议总是加上圆括号以使代码有更高的可读性。
>>> (x, y, z) = (1, 2, 'a string')
在其它类似 C 的语言中, 如果交换两个值, 使用一个临时变量比如 tmp 来临时保存其中一个值:
/* C 语言中两个变量交换 */ tmp = x;
x = y;
y = tmp;
Python 的多元赋值方式可以实现无需中间变量交换两个变量的值。
# swapping variables in Python
>>> x, y = 1, 2
>>> x
1
>>> y
2
>>> x, y = y, x
>>> x
2
>>> y
1
显然, Python 在赋值之前已经事先对 x 和 y 的新值做了计算。
3.3 标识符
标识符是语言中允许作为名字的有效字符串集合。有一部分是关键字,构成语言的标识符。这样的标识符是不能做它用的标识符的,否则会引起语法错误(SyntaxError 异常)。
Python 还有称为 built-in 标识符集合,虽然它们不是保留字,但不推荐使用这些特别的名字(见 3.3.3)。
3.3.1 合法的 Python 标识符
Python 标识符字符串规则和其他大部分用 C 编写的高级语言相似:
- 第一个字符必须是字母或下划线(_)
- 剩下的字符可以是字母和数字或下划线
- 大小写敏感
3.3.2 关键字
Python 的关键字列在下表中。任何语言的关键字应该保持相对的稳定,但Python 是一门不断成长和进化的语言,关键字列表和 iskeyword()函数都放入了 keyword 模块以便查阅。
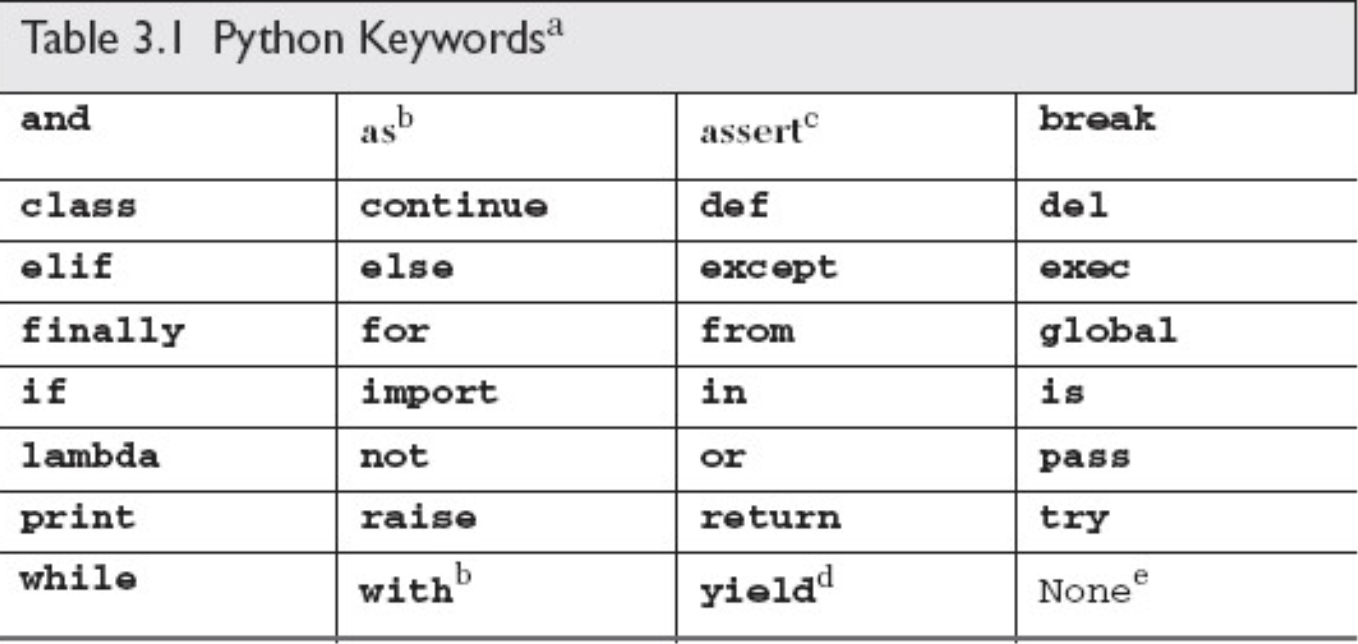
3.3.3 内建
除了关键字之外,Python 还有可以在任何一级代码使用的“内建”的名字集合,这些名字可以由解释器设置或使用。虽然 built-in 不是关键字,但是应该把它当作“系统保留字”,不做他用。然而,有些情况要求覆盖(也就是:重定义,替换)它们。Python 不支持重载标识符, 所以任何时刻都只有一个名字绑定。
built-in 是__builtins__模块的成员,在程序开始或在交互解释器中给出>>>提示之前,由解释器自动导入的。把它们看成适用在任何一级 Python 代码的全局变量。
3.3.4 专用下划线标识符
Python 用下划线作为变量前缀和后缀指定特殊变量。这里对 Python 中下划线的特殊用法做了总结:
- _xxx 不用'from module import *'导入
- __xxx__系统定义名字
- __xxx 类中的私有变量名
核心风格:避免用下划线作为变量名的开始
因为下划线对解释器有特殊的意义,而且是内建标识符所使用的符号,建议程序员避免用下划线作为变量名的开始。一般来讲,变量名_xxx 被看作是“私有的”,在模块或类外不可以使用。当变量是私有的时候,用_xxx 来表示变量是很好的习惯。因为变量名__xxx__对 Python 来说有特殊含义,对于普通的变量应当避免这种命名风格。
3.4 基本风格指南
1)注释:既不能缺少注释,也不能过度使用注释。尽可能使注释简洁明了,并放在最合适的地方,并确保注释的准确性。
2)文档:通过__doc__特别变量,动态获得文档字串。在模块,类声明,或函数声明中第一个没有赋值的字符串可以用属性 obj.__doc__来进行访问,其中 obj 是一个模块,类,或函数的名字。这在运行时刻也可以运行。
3)缩进:缩进对齐有非常重要的作用,得考虑用什么样的缩进风格才让代码容易阅读。在选择要空的格数的时候,常识也起着非常大的作用:
- 1 或 2 可能不够,很难确定代码语句属于哪个块
- 8 至 10 可能太多,如果代码内嵌的层次太多,就会使得代码很难阅读。
- 4个空格非常的流行。五和六个也不坏,但是文本编辑器通常不支持这样的设置,所以也不经常使用。三个和七个是边界情况。
- 当使用制表符 Tab 的时候,请记住不同的文本编辑器对它的设置是不一样。推荐您不要使用 Tab,如果您的代码会存在并运行在不同的平台上,或者会用不同的文本编辑器打开,推荐您不要使用 Tab。
4)选择标识符名称:请为变量选择短而意义丰富的标识符。虽然变量名的长度对于今天的编程语言不再是一个问题,但是使用简短的名字依然是个好习惯,这个原则同样使用于模块(Python 文件)的命名。
5)Python 风格指南:Guido van Rossum 在多年前写下 Python 代码风格指南。目前它已经被至少三个 PEP 代替: 7(C 代码风格指南)、8(Python 代码风格指南)和 257(文档字符串规范)。这些 PEP 被归档、维护并定期更新。
“Pythonic”这个术语指的是以 Python 的方式去编写代码、组织逻辑,及对象行为。PEP 20 写的是 Python 之禅, 你可以从那里开始你探索“Pythonic”真正含义的旅程。
如果你不能上网,但想看到这篇诗句, Python 解释器输入 import this 然后回车。下面是一些网上资源:
www.Python.org/dev/peps/pep-0007/
www.Python.org/dev/peps/pep-0008/
www.Python.org/dev/peps/pep-0020/
www.Python.org/dev/peps/pep-0257/
3.4.1 模块结构和布局
用模块来合理组织 Python 代码是简单又自然的方法。应该建立一种统一且容易阅读的结构,并将它应用到每一个文件中去。下面就是一种非常合理的布局:
(1) 起始行(Unix) :Unix 环境下才使用起始行,有起始行就能够仅输入脚本名字来执行脚本。
(2) 模块文档:简要介绍模块的功能及重要全局变量的含义,模块外可通过 module.doc 访问这些内容。
(3) 模块导入 :导入当前模块的代码需要的所有模块;每个模块仅导入一次(当前模块被加载时);函数内部的模块导入代码不会被执行, 除非该函数正在执行。
(4)变量定义:这里定义的变量为全局变量,本模块中的所有函数都可直接使用。除非必须,否则就要尽量使用局部变量代替全局变量。这样做,代码不但容易维护还可以提高性能并节省内存。
(5)类定义语句:所有的类都需要在这里定义。当模块被导入时 class 语句会被执行, 类也就会被定义。类的文档变量是 class.doc。
(6)函数定义语句:此处定义的函数可以通过 module.function()在外部被访问到,当模块被导入时 def 语句 会被执行, 函数也就都会定义好,函数的文档变量是 function.doc。
(7) 主程序:无论这个模块是被别的模块导入还是作为脚本直接执行,都会执行这部分代码。通常这里不会有太多功能性代码,而且根据执行的模式调用不同的函数。
图 3–1 一个典型模块的内部结构图解。
TODO
3.5 内存管理
本节的主题是变量和内存管理的细节, 包括:
- 变量无须事先声明
- 变量无须指定类型
- 程序员不用关心内存管理
- 变量名会被“回收”
- del 语句能够直接释放资源
3.5.1 变量定义
大多数编译型语言,变量在使用前必须先声明:
- 严苛的C 语言:变量声明必须位于代码块最开始,且在任何其他语句之前。
- 像 C++和 Java:允许“随时随地”声明变量,不过仍必须在变量被使用前声明变量的名字和类型。
Python 中,无需此类显式变量声明语句,变量在第一次被赋值时自动声明。和其他大多数语言一样,变量只有被创建和赋值后才能被使用。
3.5.2 动态类型
不但变量名无需事先声明,而且也无需类型声明,对象的类型和内存占用都是运行时确定的。尽管代码被编译成字节码,Python 仍然是一种解释型语言。在创建--也就是赋值时,解释器会根据语法和右侧的操作数来决定新对象的类型。 在对象创建后,一个该对象的应用会被赋值给左侧的变量。
3.5.3 内存分配
在为变量分配内存时,是在借用系统资源,用完之后, 应该释放借用的系统资源。Python 解释器承担了内存管理的复杂任务, 这大大简化了应用程序的编写。
3.5.4 引用计数
要保持追踪内存中的对象, Python 使用了引用计数这一简单技术。Python 内部记录着所有使用中的对象各有多少引用。一个内部跟踪变量,称为一个引用计数器。至于每个对象各有多少个引用, 简称引用计数。当对象被创建时, 就创建了一个引用计数, 当这个对象不再需要时, 也就是说, 这个对象的引用计数变为 0 时, 它被垃圾回收。(严格来说这不是 100%正确,不过现阶段你可以就这么认为)
增加引用计数
当对象被创建并(将其引用)赋值给变量时,该对象的引用计数就被设置为 1。
当同一个对象(的引用)又被赋值给其它变量时,或作为参数传递给函数, 方法或类实例时, 或者被赋值为一个窗口对象的成员时,该对象的一个新的引用,或者称作别名,就被创建 (则该对象的引用计数自动加 1)。
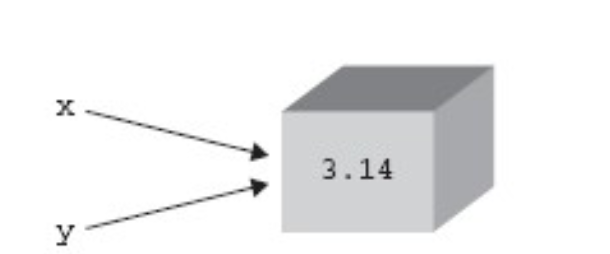
请看以下声明:
x = 3.14 # x 是第一个引用,该对象的引用计数被设置为 1。
y= x # 语句 y=x 创建了一个指向同一对象的别名 y。事实上并没有为 Y 创建一个新对象, 而是该对象的引用计数增加了 1 次(变成了2)。这是对象引用计数增加的方式之一。还有一些其它的方式也能增加对象的引用计数,如下总结。
总之,对象的引用计数在
-
对象被创建 ,x = 3.14
-
或另外的别名被创建 ,y= x
-
或被作为参数传递给函数(新的本地引用) foobar(x)
-
或成为容器对象的一个元素 myList = [123, x, 'xyz']
减少引用计数
当对象的引用被销毁时,引用计数会减小。最明显的例子就是当引用离开其作用范围时, 这种情况最经常出现在函数运行结束时,所有局部变量都被自动销毁,对象的引用计数也就随之减少。
当变量被赋值给另外一个对象时,原对象的引用计数也会自动减 1:
foo = 'xyz' # 当字符串对象"xyz"被创建并赋值给 foo 时, 它的引用计数是 1
bar = foo # 当增加了一个别名 bar 时, 引用计数变成了 2
foo = 123 # foo 被重新赋值给整数对象 123 时, xyz 对象的引用计数自动减 1,又重新变成了 1
其它造成对象的引用计数减少的方式包括使用 del 语句删除一个变量, 或者当一个对象被移出一个窗口对象时(或该容器对象本身的引用计数变成了 0 时)。总结一下, 一个对象的引用计数在以下情况会减少:
- 一个本地引用离开了其作用范围。比如 foobar()函数结束时。
- 对象的别名被显式的销毁。 del y # or del x
- 对象的一个别名被赋值给其它的对象,x = 123
- 对象被从一个窗口对象中移除 myList.remove(x)
- 窗口对象本身被销毁 del myList # or goes out-of-scope 参阅 11.8 了解更多变量作用范围的信息。
del 语句
Del 语句会删除对象的一个引用,它的语法是: del obj1[, obj2[,... objN]]
例如,在上例中执行 del y
会产生两个结果: 从现在的名字空间中删除y & x的引用计数减一
引申一步, 执行 del x 会删除该对象的最后一个引用, 也就是该对象的引用计数会减为 0, 这会导致该对象从此“无法访问”或“无法抵达”。 从此刻起, 该对象就成为垃圾回收机制的回收对象。 注意任何追踪或调试程序会给一个对象增加一个额外的引用, 这会推迟该对象被回收的时间。
3.5.5 垃圾收集
不再被使用的内存会被一种称为垃圾收集的机制释放。虽然解释器跟踪对象的引用计数, 但垃圾收集器负责释放内存。垃圾收集器是一块独立代码, 它用来寻找引用计数为 0 的对象。它也负责检查那些虽然引用计数大于 0 但也应该被销毁的对象。 特定情形会导致循环引用。
一个循环引用发生在当你有至少两个对象互相引用时, 也就是说所有的引用都消失时, 这些引用仍然存在, 这说明只靠引用计数是不够的。Python 的垃圾收集器实际上是一个引用计数器和一个循环垃圾收集器。 当一个对象的引用计数变为 0,解释器会暂停,释放掉这个对象和仅有这个对象可访问(可到达)的其它对象。作为引用计数的补充, 垃圾收集器也会留心被分配的总量很大(及未通过引用计数销毁的那些)的对象。 在这种情况下, 解释器会暂停下来, 试图清理所有未引用的循环。
3.6 第一个Python程序
- makeTextFile.py, 创建一个文本文件。 它提示用户输入每一行文本, 然后将结果写到文件中。
- readTextFile.py 读取并 显示该文本文件的内容。
创建文件(makeTextFile.py):用户输入一个(尚不存在的)文件名, 然后由用户输入该文件的每一行。最后将所有文本写入文本文件。
#!/usr/bin/env python
'makeTextFile.py -- create text file' # UNIX 启动行之后是模块的文档字符串。
import os
ls = os.linesep # 为 os.linesep 属性取了一个新别名。一方面缩短变量名,另一方面改善访问该变量的性能。
while True:
filename = input("please input the file name:")
if os.path.exists(filename):
print("the filename exists, please input another filename")
else:
break
all = []
while True:
entry = input('> ')
if entry == '':
break
all.append(entry + ls) # +ls 为每一行添加行结束符,对 Unix 平台,是'\n', 对 DOS 或 win32 平台,则是 '\r\n'。通过使用 os.lineseq,不必关心程序运行在什么平台,也不必要根据不同的平台决定使用哪种行结束符。
with open(filename, "w") as f:
f.writelines(all)
#!/usr/bin/env Python
'readTextFile.py -- read and display text file'
import os.path
while True:
filename = input("please input the filename:")
if os.path.exists(filename) is False:
print("the file doesn't exit")
else:
break
try:
fobj = open(filename, "r")
except IOError as e:
print("file open error", str(e))
else:
for each_line in fobj:
print(each_line.strip())
# try-except-else 语句。
# try 子句是一段希望监测错误的代码块。尝试打开用户输入的文件。
# except 子句是处理错误的地方。检查 open() 是否失败-通常是 IOError 类型 的错误。
# else 子句在 try 代码块运行无误时执行
3.6 相关模块和开发工具
Python 代码风格指南(PEP8), Python 快速参考和 Python 常见问答都是开发者很重要的 “工具”。另外, 还有一些模块会帮助你成为一个优秀的 Python 程序员。
Debugger: pdb
Logger: logging
Profilers: profile, hotshot, cProfile
调试模块 pdb 允许你设置(条件)断点,代码逐行执行,检查堆栈。它还支持事后调试。
logging 模块是在 Python2.3 中新增的, 它定义了一些函数和类帮助你的程序实现灵活的日志系统。共有五级日志级别: 紧急, 错误,警告,信息和调试。
因为不同的人们为了满足不同的需求重复实现了很多性能测试器,Python 也有好几个性能测试模块。
- 最早的 Python profile 模块是 Python 写成的,用来测试函数的执行时间,及每次脚本执行的总时间,既没有特定函数的执行时间也没有被包含的子函数调用时间。 在三个 profile 模块中,它是最老的也是最慢的,尽管如此, 它仍然可以提供一些有价值的性能信息。
- hotshot 模块是在 Python2.2 中新增的,它的目标是取代 profile 模块, 它修复了 profile 模块的一些错误, 因为它是用 C 语言写成,所以它有效的提高了性能。 注意 hotshot 重点解决了性能测试过载的问题, 但却需要更多的时间来生成结果。Python2.5 版修复了 hotshot 模块的一个关于时间计量的严重 bug。
- cProfile 模块是 Python2.5 新增的, 它用来替换掉已经有历史的 hotshot 和 profile 模 块。被作者确认的它的一个较明显的缺点是它需要花较长时间从日志文件中载入分析结果, 不支持子函数状态细节及某些结果不准。它也是用 C 语言来实现的。
第四章
首先了解什么是 Python 对象→然后讨论内建类型(标准类型)→讨论标准类型运算符和内建函数→给出对标准类型的不同分类方式。最后提一提 Python 目前还不支持的类型(这对那些有其他高级语言经验的人会有所帮助)。
4.1 Python 对象
Python 使用对象模型来存储数据。
所有的 Python 对像都拥有三个特性:身份,类型和值。
- 身份:每一个对象都有唯一的身份标识自己,任何对象的身份可以使用内建函数 id()来得到。这个值可以被认为是该对象的内存地址。
- 类型:对象的类型决定了该对象可以保存什么类型的值,可以进行什么样的操作,以及遵循什么样的规则。可以用内建函数 type()查看 Python 对象的类型。因为在 Python 中类型也是对象,所以 type()返回的是对象而不是简单的字符串。
- 值:对象表示的数据项
上面三个特性在对象创建的时候就被赋值,除了值之外,其它两个特性都是只读的。对于新风格的类型和类, 对象的类型也是可以改变的。
对象的值是否可以更改被称为对象的可改变性(mutability),小节 4.7 中会讨论这个问题。
Python 有一系列的基本(内建)数据类型,必要时也可以创建自定义类型来满足应用程序的需求。
4.1.1 对象属性
某些 Python 对象有属性、值或相关联的可执行代码(方法)。Python 用点(.) 标记法来访问属性。属性包括相应对象的名字等等。最常用的属性是函数和方法,不过有一些 Python 类型也有数据属性。含有数据属性的对象包括(但不限于):类、类实例、模块、复数和文件。
4.2 标准类型
- 数字(分为几个子类型,其中有三个是整型)
- 整型
- 布尔型
- 长整型
- 浮点型
- 复数型
- 字符串
- 列表
- 元组
- 字典
把标准类型也称作“基本数据类型”,因为这些类型是 Python 内建的基本数据类型。
4.3 其他内建类型
- 类型(Type)
- Null 对象 (None)
- 文件
- 集合/固定集合
- 函数/方法
- 模块
- 类
这些是做 Python 开发时可能会用到的一些数据类型。这里先讨论 Type 和 None 类型的使用,其他类型将在其他章节中讨论。
4.3.1 类型对象和 type 类型对象
虽然看上去把类型本身也当成对象有点特别。对象的一系列固有行为和特性(比如支持哪些运算,具有哪些方法)必须事先定义好。从这个角度看,类型正是保存这些信息的最佳位置。描述一种类型所需要的信息不可能用一个字符串来搞定,所以类型不能是一个简单的字符串,这些信息不能也不应该和数据保存在一起, 所以将类型定义成对象。
下面来正式介绍内建函数 type()。通过调用 type()函数你能够得到特定对象的类型信息:
>>> type(42)
<type 'int'>
type 函数有,输出结果<type 'int'>。不过你应当意识到它并不是一个简简单单的告诉你 42 是个整数这样 的字符串。<type 'int'>实际上是一个类型对象,碰巧它输出了一个字符串来告诉你它是个 int 型对象。
那么类型对象的类型是什么?
>>> type(type(42))
<type 'type'>
所有类型对象的类型都是 type,它也是所有 Python 类型的根和所有 Python 标准类的默认元类(metaclass)。
随着 Python 2.2 中类型和类的统一,类型对象在面向对象编程和日常对象使用中扮演着更加重要的角色。从现在起, 类就是类型,实例是对应类型的对象。
4.3.2 None, Python 的 Null 对象
Python有一个特殊的类型,被称作 Null 对象或者 NoneType,它只有一个值,那就是 None。 它不支持任何运算也没有任何内建方法。和 None 类型最接近的 C 类型就 是 void,None 类型的值和 C 的 NULL 值非常相似(其他类似的对象和值包括 Perl 的 undef 和 Java 的 void 类型与 null 值)。
None 没有什么有用的属性,它的布尔值总是 False。
所有标准对象均可用于布尔测试,同类型的对象之间可以比较大小。每个对象天生具有布尔 True 或 False 值。空对象、值为零的任何数字或者 Null 对象 None 的布尔值都是 False。
下列对象的布尔值是 False:
- None
- False (布尔类型)
- 所有的值为零的数
- 0 (整型)
- (浮点型)
- 0L (长整型)
- 0.0+0.0j (复数)
- "" (空字符串)
- [] (空列表)
- () (空元组)
- {} (空字典)
值不是上面列出来的任何值的对象的布尔值都是 True,例如 non-empty、non-zero 等等。
用户创建的类实例如果定义了 nonzero(nonzero())或 length(len())且值为 0,那 么它们的布尔值就是 False。
4.4 内部类型
- 代码
- 帧
- 跟踪记录
- 切片
- 省略
- Xrange
一般的程序员通常不会直接和这些对象打交道。不过为了这一章的完整性,还是在这里介绍一下它们。请参阅源代码或者 Python 的内部文档和在线文档获得更详尽的信息。
你如果对异常感到迷惑的话,可以告诉你它们是用类来实现的。
4.4.1 代码对象
代码对象是编译过的 Python 源代码片段,它是可执行对象。通过调用内建函数 compile() 可以得到代码对象。代码对象可以被 exec 命令或 eval()内建函数来执行。在第 14 章将详细研究代码对象。
代码对象本身不包含任何执行环境信息, 它是用户自定义函数的核心, 在被执行时动态获得上下文。(事实上代码对象是函数的一个属性)一个函数除了有代码对象属性以外,还有一 些其它函数必须的属性,包括函数名,文档字符串,默认参数,及全局命名空间等等。
4.4.2 帧对象
帧对象表示 Python 的执行栈帧。帧对象包含 Python 解释器在运行时所需要知道的所有信息。它的属性包括指向上一帧的链接,正在被执行的代码对象(参见上文),本地及全局名字空间字典以及当前指令等。每次函数调用产生一个新的帧,每一个帧对象都会相应创建一个 C 栈帧。用到帧对象的一个地方是跟踪记录对象(参见下一节)
4.4.3 跟踪记录对象
当你的代码出错时, Python 就会引发一个异常。如果异常未被捕获和处理, 解释器就会退出脚本运行,显示类似下面的诊断信息:
Traceback (innermost last):
File "<stdin>", line N?, in ???
ErrorName: error reason
当异常发生时,一个包含针对异常的栈跟踪信息的跟踪记录对象被创建。如果一个异常有自己的处理程序,处理程序就可以访问这个跟踪记录对象。
4.4.4 切片对象
当使用 Python 扩展的切片语法时,就会创建切片对象。扩展的切片语法允许对不同的索引切片操作,包括步进切片,多维切片,及省略切片。
多维切片语法是 sequence[start1 : end1, start2 : end2], 或使用省略号, sequence[...,start1 : end1 ]. 切片对象也可以由内建函数 slice()来生成。
步进切片允许利用第三个切片元素进行步进切片,它的语法为 sequence[起始索引 : 结束索引 : 步进值]。
下面是几个步进切片的例子:
>> foostr = 'abcde'
>> foostr[::-1]
'edcba'
>> foostr[::-2]
'eca'
>>> foolist = [123, 'xba', 342.23, 'abc']
>>> foolist[::-1]
['abc', 342.23, 'xba', 123]
4.4.5 省略对象
省略对象用于扩展切片语法中,起记号作用。 这个对象在切片语法中表示省略号。类似Null 对象 None, 省略对象有一个唯一的名字 Ellipsis, 它的布尔值始终为 True.
4.4.6 XRange 对象
调用内建函数 xrange() 会生成一个 Xrange 对象,xrange()是内建函数 range()的兄弟版本, 用于需要节省内存使用或 range()无法完成的超大数据集场合。在第 8 章你可以找到更多关于 range() 和 xrange() 的使用信息。
4.5 标准类型运算符
4.5.1 对象值的比较
比较运算符用来判断同类型对象是否相等,所有的内建类型均支持比较运算,比较运算返回布尔值 True 或 False。
注意:实际进行的比较运算因类型而异。比如数字类型根据数值的大小和符号比较, 字符串按照字符序列值进行比较,等等。
>>> 2 == 2
True
>>> 2.46 <= 8.33
True
>>> 5+4j >= 2-3j
True
>>> 'abc' == 'xyz'
False
>>> 'abc' > 'xyz'
False
>>> 'abc' < 'xyz'
True
>>> [3, 'abc'] == ['abc', 3]
False
>>> [3, 'abc'] == [3, 'abc']
True
# 不同于很多其它语言,多个比较操作可以在同一行上进行,求值顺序为从左到右。
>>> 3<4<7 #sameas(3<4)and(4<7) True
>>> 4>3==3 #sameas(4>3)and(3==3) True
>>> 4 < 3 < 5 != 2 < 7
False
比较操作是针对对象的值进行的,比较的是对象的数值而不是对象本身。后面会研究对象身份的比较。
表 4.1 标准类型值比较运算符
运算符 功能
expr1 < expr2 expr1 小于 expr2
expr1 > expr2 expr1 大于 expr2
expr1 <= expr2 expr1 小于等于 expr2
expr1 >= expr2 expr1 大于等于 expr2
expr1 == expr2 expr1 等于 expr2
expr1 != expr2 expr1 不等于 expr2 (C 风格)
expr1 <> expr2 expr1 不等于 expr2 (ABC/Pascal 风格)
注: 未来很有可能不再支持 <> 运算符,建议您一直使用 != 运算符。
4.5.2 对象身份比较
对象可以被赋值到另一个变量(通过引用)。因为每个变量都指向同一个(共享的)数据对象,只要任何一个引用发生改变,该对象的其它引用也会随之改变。
为了方便理解,最好先别考虑变量的值,而是将变量名看作对象的一个链接。看以下三个例子:
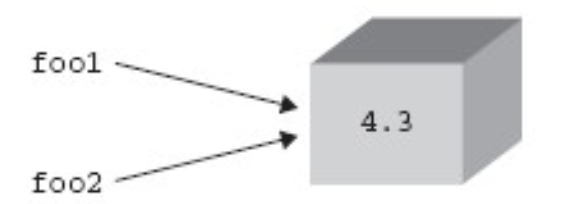
例 1: foo1 和 foo2 指向相同的对象
foo1 = foo2 = 4.3
多重赋值,将 4.3 这个值赋给了 foo1 和 foo2 这两个变量。它还有另一层含义,事实是一个值为 4.3 的数字对象被创建,然后这个对象的引用被赋值给 foo1 和 foo2, 结果就是 foo1 和 foo2 指向同一个对 象。如下图
例 2: foo1 和 foo2 指向相同的对象
foo1 = 4.3
foo2 = foo1
一个值为 4.3 的数值对象被创建,然后赋给一个变量,当执行 foo2 = foo1 时, foo2 被指向 foo1 所指向的同一个对象, 这是因为 Python 通过传递引用来处理对象。foo2 就成为原始值 4.3 的一个新的引用。 这样 foo1 和 foo2 就都指向了同一个对 象。和上图一样。
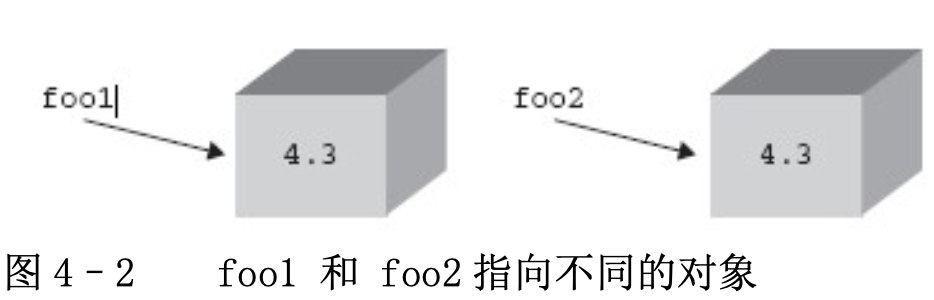
例 3: foo1 和 foo2 指向不同的对象
foo1 = 4.3
foo2 = 1.3 + 3.0
这个例子有所不同。首先一个数字对象被创建,赋值给 foo1。然后第二个数值对象被创建并赋值给 foo2. 尽管两个对象保存的是同样大小的值,但事实上系统中保存的都是两个独立的对象,其中 foo1 是第一个对象的引用, foo2 则是第二个对象的引用。如下图。 对象就象一个装着内容的盒子。当一个对象被赋值到一个变量,就象在这个盒子上贴了一个标签,表示创建了一个引用。每当这个对象有了一个新的引用,就会在盒子上新贴一张标签。当一个引用被销毁时, 这个标签就会被撕掉。当所有的标签都被撕掉时, 这个盒子就会被回收。那么,Python 是怎么知道这个盒子有多少个标签呢?
每个对象都天生具有一个计数器,记录它自己的引用次数。这个数目表示有多少个变量指向该对象(引用计数)。
Python 提供了 is 和 is not 运算符来测试两个变量是否指向同一个对象。
a is b
# 这个表达式等价于下面的表达式
id(a) == id(b)
对象身份比较运算符拥有同样的优先级,表 4.2 列出了这些运算符。下面的例子创建了一个变量,然后将第二个变量指向同一个对象。
>>> a = [ 5, 'hat', -9.3]
>>> b = a
>>> a is b
True
>>> a is not b
False
>>> b = 2.5e-5
>>> b
2.5e-005
>>> a
[5, 'hat', -9.3]
>>> a is b
False
>>> a is not b
True
表4.2 标准类型对象身份比较运算符(is 与 not 标识符都是 Python 关键字。)
运算符 功能
obj1 is obj2 obj1 和 obj2 是同一个对象
obj1 is not obj2 obj1 和 obj2 不是同一个对象
上面的例子使用的是浮点数而不是整数。整数对象和字符串对象是不可变对象,所以Python会很高效的缓存它们。这会造成我们认为Python应该创建新对象时,它却没有创建新对象的假象。eg:
>>> a = 1
>>> id(a)
8402824
>>> b = 1
>>> id(b)
8402824
>>>c = 1.0
>> id(c)
8651220
>> d = 1.0
>> id(d)
8651204
a 和 b 指向了相同的整数对象,但是 c 和 d 并没有指向相同的浮点数对象。我们可能会希望 a 与 b 能和 c 与 d 一样,因为我们本意就是为了创建两个整数对象,而不是像 b = a 这样的结果。
Python 仅缓存简单整数,因为它认为在 Python 应用程序中这些小整数会经常被用到。在写作本书的时候,Python 缓存的整数范围是(-1, 100),不过这个范围是会改变的,所以不要在你的应用程序使用这个特性。
Python 2.3 中决定,在预定义缓存字符串表之外的字符串,如果不再有任何引用指向它, 那这个字符串将不会被缓存。也就是说, 被缓存的字符串将不会象以前那样永生不灭,对象回收器一样可以回收不再被使用的字符串。
4.5.3 布尔类型
布尔逻辑运算符 and, or 和 not,这些运算符的优先级按从高到低的顺序列于表 4.3. not 运算符拥有最高优先级,只比所有比较运算符低一级。 and 和 or 运算符则相应的再低一级。
表4.3 标准类型布尔运算符
运算符 功能
not expr expr 的逻辑非 (否)
expr1 and expr2 expr1 和 expr2 的逻辑与
expr1 or expr2 expr1 和 expr2 的逻辑或
>>> x, y = 3.1415926536, -1024
>>> x < 5.0
True
>>> not (x < 5.0) False
>>> (x < 5.0) or (y > 2.718281828) True
>>> (x < 5.0) and (y > 2.718281828) False
>>> not (x is y)
True
4.6 标准类型内建函数
除了这些运算符,Python 提供了一些内建函数用于这些基本对象类型: cmp(), repr(), str(), type(), 和等同于 repr()函数的单反引号(``) 运算符。
表 4.4 标准类型内建函数
函数 功能
cmp(obj1, obj2) 比较 obj1 和 obj2, 根据比较结果返回整数 i:
i < 0 if obj1 < obj2
i > 0 if obj1 > obj2
i == 0 if obj1 == obj2
repr(obj) 或 obj 返回一个对象的字符串表示 str(obj) 返回对象适合可读性好的字符串表示
type(obj) 得到一个对象的类型,并返回相应的 type 对象
4.6.1 type()
在 Python2.2 以前, type() 是内建函数。不过从那时起,它变成了一个“工厂函数”。
type() 的用法:type(object) ,接受一个对象做为参数,并返回它的类型。它的返回值是一个类型对象。
>>> type(4) # int type
<type 'int'>
>>> type('Hello World!')
<type 'string'>
# string type
>>> type(type(4)) # type type
<type 'type'>
通过内建函数 type() 得到了一个整数和一个字符串的类型;为了确认一下类型本身也是类型,对 type()的返回值再次调用 type()。
注意 type()的输出, 它看上去不象一个典型的 Python 数据类型,比如一个整数或一个字符串,一些东西被 <和>包裹着。这种语法是为了告诉你它是一个对象。每个对象都可以实现一 个可打印的字符串表示。
不过并不总是这样, 对那些不容易显示的对象来说, Python 会以一 个相对标准的格式表示这个对象,格式通常是这种形式:<object_something_or_another>,以这种形式显示的对象通常会提供对象类别,对象 id 或位置, 或者其它合适的信息。
4.6.2 cmp()
用于比较两个对象 obj1 和 obj2:
- 如果 obj1 小于 obj2, 则返回一个负整 数
- 如果 obj1 大于 obj2 则返回一个正整数
- 如果 obj1 等于 obj2, 则返回 0。
它的行为非常类似于 C 语言的 strcmp()函数。比较是在对象之间进行的,不管是标准类型对象还是用户自定 义对象。如果是用户自定义对象,cmp()会调用该类的特殊方法__cmp__()。在第 13 章会详细介绍类的这些特殊方法。下面是几个使用 cmp()内建函数的对数值和字符串对象进行比较的例子。
>>> a, b = -4, 12
>>> cmp(a,b)
-1
>>> cmp(b,a)
1
>>> b = -4
>>> cmp(a,b)
0
>>>
>>> a, b = 'abc', 'xyz'
>>> cmp(a,b)
-23
>>> cmp(b,a)
23
>>> b = 'abc'
>>> cmp(a,b)
0
后面我们会研究 cmp()用于其它对象的比较操作。
4.6.3 str()和 repr() (及 `` 运算符)
内建函数 str() 和 repr() 或反引号运算符(``) 可以方便的以字符串的方式获取对象的内容、类型、数值属性等信息。
- str()函数得到的字符串可读性好
- 而 repr()函数得到的字符串通常可以用来重新获得该对象, 通常情况下 obj == eval(repr(obj)) 这个等式是成立的。
这两个函数接受一个对象做为其参数,返回适当的字符串。下面随机取一些 Python 对象来查看他们的字符串表示。
>>> str(4.53-2j)
'(4.53-2j)'
>>>
>>> str(1)
'1'
>>>
>>> str(2e10)
'20000000000.0'
>>>
>>> str([0, 5, 9, 9])
'[0, 5, 9, 9]'
>>>
>>> repr([0, 5, 9, 9])
'[0, 5, 9, 9]'
>>>
>>> `[0, 5, 9, 9]`
'[0, 5, 9, 9]'
尽管 str(),repr()和运算在特性和功能方面都非常相似,repr() 和 做的是完全一样的事情,它们返回的是一个对象的“官方”字符串表示, 即绝大多数情况下可以通过求值运算(eval()内建函数)重新得到该对象,但 str()不同,str() 致力于生成一个对象的可读性好的字符串表示,它的返回结果通常无法用于 eval()求值, 但很适合用于 print 语句输出。但并不是所有 repr()返回的字符串都能够用eval()内建函数得到原来的对象:
>>> eval(`type(type))`)
File "<stdin>", line 1 eval(`type(type))`)
^
SyntaxError: invalid syntax
也就是说 repr() 输出对 Python 比较友好, 而 str()的输出对人比较友好。虽然如此,很多情况下这三者的输出仍然都是完全一样的。
核心笔记:为什么有了 repr()还需要``?
你偶尔会遇到某个运算符和某个函数是做同样一件事情。之所以如此是因为某些场合函数会比运算符更适合使用。举个例子,当处理类似函数这样的可执行对象或根据不同的数据项调用不同的函数处理时,函数就比运算符用起来方便。另一个例子就是双星号(****)乘方运算和 pow()内建函数,x **** y 和 pow(x,y) 执行的都是 x 的 y 次方。
译者注:Python 社区目前已经不鼓励继续使用``运算符。
4.6.4 type() 和 isinstance()
Python 不支持方法或函数重载,因此你必须自己保证调用的就是你想要的函数或对象。 (参阅 Python 常见问答 4.75 节)。幸运的是,type()内建函数可以帮助你确认这一点。一个名字里究竟保存的是什么?相当多,尤其是这是一个类型的名字时。
确认接收到的类型对象的身份有很多时候都是很有用的。为了达到此目的,Python 提供了一个内建函数 type(). type()返回任意 Python 对象对象的类型,而不局限于标准类型。来看几个使用 type()内建函数返回多种对象类型的例子:
>>> type('')
<type 'str'>
>>>
>>> s = 'xyz'
>>> type(s)
<type 'str'>
>>>
>>> type(100)
<type 'int'>
>>> type(0+0j)
<type 'complex'>
>>> type(0L)
<type 'long'>
>>> type(0.0)
<type 'float'>
>>>
>>> type([])
<type 'list'>
>>> type(())
<type 'tuple'>
>>> type({})
<type 'dict'>
>>> type(type)
<type 'type'>
>>>
>>> class Foo: pass
...
>>> foo = Foo()
>>> class Bar(object): pass
...
>>> bar = Bar()
>>>
>>> type(Foo)
<type 'classobj'>
>>> type(foo)
<type 'instance'>
>>> type(Bar)
<type 'type'>
>>> type(bar)
<class '__main__.Bar'>
Python2.2 统一了类型和类, 如果你使用的是低于 Python2.2 的解释器,你可能看到不一样的输出结果。
>>> type('')
<type 'string'>
>>> type(0L)
<type 'long int'>
>>> type({})
<type 'dictionary'>
>>> type(type)
<type 'builtin_function_or_method'>
>>>
>>> type(Foo) # assumes Foo created as in above
<type 'class'>
>>> type(foo) # assumes foo instantiated also
<type 'instance'>
除了内建函数 type(), 还有一个内建函数叫 isinstance()。会在第 13 章(面向对象编程)正式研究这个函数,不过还是要简要介绍一下如何利用它来确认一个对象的类型。
下面脚本演示在运行时环境使用 isinstance() 和 type()函数。 随后讨论 type()的使用以及怎么将这个例子移植为改用 isinstance()。
运行 typechk.py, 我们会得到以下输出:
-69 is a number of type: int
9999999999999999999999 is a number of type: int
98.6 is a number of type: float
(-5.2+1.9j) is a number of type: complex
xxx is not a number at all!!
函数 displayNumType() 接受一个数值参数,它使用内建函数 type()来确认数值的类型 。
def displayNumType(num):
# print(num)
if isinstance(num, (int, float, complex)):
print('a number of type:', type(num).__name__)
else:
print('not a number at all!!')
displayNumType(-69)
displayNumType(9999999999999999999999)
displayNumType(98.6)
displayNumType(-5.2+1.9j)
displayNumType('xxx')
例子进阶
原始这个完成同样功能的函数与本书的第一版中的例子已经大不相同:
def displayNumType(num):
print(num)
if type(num) == type(0):
print('an integer')
elif type(num) == type(0.0):
print('a float')
elif type(num) == type(0+0j):
print('a complex number')
else:
print('not a number at all!!')
减少函数调用的次数
仔细研究一下上面代码,会看到调用了两次 type()。要知道每次调用函数都会付出性能代价, 如果我们能减少函数的调用次数, 就会提高程序的性能。
利用在本章我们前面提到的 types 模块, 我们还有另一种比较对象类型的方法,那就是将检测得到的类型与一个已知类型进行比较。如果这样, 我们就可以直接使用 type 对象而不用每次计算出这个对象来。那么我们现在修改一下代码,改为只调用一次 type()函数:
>>> import types
>>> if type(num) == types.IntType...
对象值比较 VS 对象身份比较
在这一章的前面部分我们讨论了对象的值比较和身份比较, 如果你了解其中的关键点,你就会发现我们的代码在性能上还不是最优的.在运行时期,只有一个类型对象来表示整数类型. 也就是说,type(0),type(42),type(-100) 都是同一个对象: <type 'int'>(types.IntType 也 是这个对象)
如果它们是同一个对象, 我们为什么还要浪费时间去获得并比较它们的值呢(我们已经知道它们是相同的了!)? 所以比较对象本身是一个更好地方案.下面是改进后的代码:
if type(num) is types.IntType... # or type(0)
这样做有意义吗? 我们用对象身份的比较来替代对象值的比较。如果对象是不同的,那意味着原来的变量一定是不同类型的。(因为每一个类型只有一个类型对象),我们就没有必要去检查(值)了。 一次这样的调用可能无关紧要,不过当很多类似的代码遍布在你的应用程序中的 时候,就有影响了。
减少查询次数
这是一个对前一个例子较小的改进,如果你的程序像我们的例子中做很多次比较的话,程序的性能就会有一些差异。为了得到整数的对象类型,解释器不得不首先查找 types 这个模块的名字,然后在该模块的字典中查找 IntType。通过使用 from-import,你可以减少一次查询:
from types import IntTyp
if type(num) is IntType...
惯例和代码风格
Python2.2 对类型和类的统一导致 isinstance()内建函数的使用率大大增加。我们将在 第 13 章(面向对象编程)正式介绍 isinstance(),在这里我们简单浏览一下。
这个布尔函数接受一个或多个对象做为其参数,由于类型和类现在都是一回事, int 现在 既是一个类型又是一个类。我们可以使用 isinstance() 函数来让我们的 if 语句更方便,并具 有更好的可读性。
if isinstance(num, int)...
在判断对象类型时也使用 isinstance() 已经被广为接受,我们上面的 typechk.py 脚本
最终与改成了使用 isinstance() 函数。值得一提的是, isinstance()接受一个类型对象的元 组做为参数, 这样我们就不必像使用 type()时那样写一堆 if-elif-else 判断了。
4.6.5 Python类型运算符和内建函数总结
表 4.5 列出了所有运算符和内建函数,其中运算符顺序是按优先级从高到低排列的。同一 种灰度的运算符拥有同样的优先级。注意在 operator 模块中有这些(和绝大多数 Python)运算符相应的同功能的函数可供使用。
表 4.5 标准类型运算符和内建函数。
4.7 类型工厂函数
Python 2.2 统一了类型和类, 所有的内建类型现在也都是类, 在这基础之上, 原来的所谓内建转换函数象 int(), type(), list() 等等, 现在都成了工厂函数。 也就是说虽然他们看上去有点象函数, 实质上他们是类。当你调用它们时, 实际上是生成了该类型的一个实例, 就象工厂生产货物一样。
下面这些大家熟悉的工厂函数在老的 Python 版里被称为内建函数:
-
int(), long(), float(), complex()
-
str(), unicode(), basestring()
-
list(), tuple()
-
type()
以前没有工厂函数的其他类型,现在也都有了工厂函数。除此之外,那些支持新风格的类的全新的数据类型,也添加了相应的工厂函数。下面列出了这些工厂函数:
-
dict()
-
bool()
-
set(), frozenset()
-
object()
-
classmethod()
-
staticmethod()
-
super()
-
property()
-
file()
4.8 标准类型的分类
“标准类型”是 Python 的“基本内建数据对象原始类型”。
-
“基本”:是指这些类型都是Python提供的标准或核心类型。
-
“内建”,是由于这些类型是Python默认就提供的
-
“数据”,因为他们用于一般数据存储
-
“对象”,因为对象是数据和功能的默认抽象
-
“原始”,因为这些类型提供的是最底层的粒度数据存储 “类型”,因为他们就是数据类型
上面这些描述实际上并没有告诉你每个类型如何工作以及它们能发挥什么作用。事实上, 几个类型共享某一些的特性,比如功能的实现手段,另一些类型则在访问数据值方面有一些共同之处。我们感兴趣的还有这些类型的数据如何更新以及它们能提供什么样的存储。 有三种不同的模型可以对基本类型进行分类,每种模型都展示这些类型之间的相互关系。这些模型可以帮助理解类型之间的相互关系以及他们的工作原理。
4.8.1 存储模型
分类的第一种方式:看这种类型的对象能保存多少个对象。一个能保存单个字面对象的类型称它为原子或标量存储,那些可容纳多个对象的类型,称之为容器存储。(容器对象有时会在文档中被称为复合对象,不过这些对象并不仅仅指类型,还包括类似类实例这样的对象)
容器类型又带来一个新问题,那就是它是否可以容纳不同类型的对象。所有的 Python 容器对象都能够容纳不同类型的对象。表 4.6 按存储模型对 Python 的类型进行了分类。
字符串看上去像一个容器类型,因为它“包含”字符,不过由于 Python 并没有字符类型,所以字符串是一个自我包含的文字类型。
表 4.6 以存储模型为标准的类型分类
分类 Python 类型
标量/原子类型 数值(所有的数值类型),字符串(全部是文字)
容器类型 列表、元组、字典
4.8.2 更新模型
另一种分类的方式:针对每一个类型问一个问题:“对象创建成功之 后,它的值可以进行更新吗?” 可变对象允许他们的值被更新,而不可变对象则不允许他们的值被更改。表 4.7 列出了支持更新和不支持更新的类型。
x = 'Python numbers and strings'
x = 'are immutable?!? What gives?'
i=0
i=i+1
你可能会疑问,“字符串和数字不可变吗?”。没错,是这样,不过你还没有搞清楚幕后的真相。上面的例子中,事实上是一个新对象被创建,然后它取代了旧对象。
新创建的对象被关联到原来的变量名, 旧对象被丢弃,垃圾回收器会在适当的时机回收这些对象。你可以通过内建函数 id()来确认对象的身份在两次赋值前后发生了变化。
表 4.7 以更新模型为标准的类型分类
分类 Python 类型
可变类型 列表, 字典
不可变类型 数字、字符串、元组
在上面的例子里加上 id()调用, 就会清楚的看到对象实际上已经被替换了:
>>> x = 'Python numbers and strings'
>>> print id(x)
16191392
>>> x = 'are immutable?!? What gives?'
>>> print id(x)
16191232
>>> i = 0
>>> print id(i)
7749552
>>> i = i + 1
>>> print id(i)
7749600
另一类对象, 列表可以被修改而无须替换原始对象, 看下面的例子:
>>> aList = ['ammonia', 83, 85, 'lady']
>>> aList
['ammonia', 83, 85, 'lady']
>>>
>>> aList[2]
85
>>>
>>> id(aList)
135443480
>>>
>>> aList[2] = aList[2] + 1
>>> aList[3] = 'stereo'
>>> aList
['ammonia', 83, 86, 'stereo']
>>>
>>> id(aList)
135443480
>>>
>>> aList.append('gaudy')
>>> aList.append(aList[2] + 1)
>>> aList
['ammonia', 83, 86, 'stereo', 'gaudy', 87]
>>>
>>> id(aList)
135443480
列表的值不论怎么改变, 列表的 ID 始终保持不变。
4.8.3 访问模型
根据访问存储的数据的方式对数据类型进行分类。在访问模型中共有三种访问方式:直接存取,顺序,和映射。表 4.8 按访问方式对数据类型进行了分类。
- 对非容器类型可以直接访问。所有的数值类型都归到这一类。
- 序列类型是指容器内的元素按从 0 开始的索引顺序访问。一次可以访问一个或多个元素(切片(slice))。字符串, 列表和元组都归到这一类。虽然字符串是简单文字类型,因为它有能力按照顺序访问子字符串,所以也将它归到序列类型。
- 映射类型类似序列的索引属性,不过它的索引并不使用顺序的数字偏移量取值, 它的元素无序存放, 通过一个唯一的 key 来访问,这就是映射类型, 它容纳的是哈希键-值对的集合。字典
以后的章节中将主要使用访问模型,详细介绍各种访问模型的类型,以及某个分类的类型之间有哪些相同之处(比如运算符和内建函数), 然后讨论每种 Python 标准类型。所有类型的特殊运算符,内建函数, 及方法都会在相应的章节特别说明。
为什么要对同样的数据类型再三分类呢?
- 因为 Python 提供了高级的数据结构,我们需要将那些原始的类型和功能强大的扩展类型区分开来。
- 有助于搞清楚某种类型应该具有什么行为。
- 最后,搞清楚某些分类中的所有类型具有哪些相同的特性。
为什么要用这么多不同的模型或从不同的方面来分类?
所有这些数据类型看上去是很难分类的。它们彼此都有着错综复杂的关系,所有类型的共同之处最好能揭示出来,而且我们还想揭示每种类型的独到之处。没有两种类型横跨所有的分类。(当然,所有的数值子类型做到了这一点, 所以我们将它们归纳到一类当中)。你对每种类型的了解越多,你就越能在自己的程序中使用恰当的类型以达到最佳的性能。
下面汇总表中列出了所有的标准类型, 使用的三个模型, 以及每种类型归入的分类。
标准类型的分类
数据类型 存储模型 更新模型 访问模型
数字 Scalar 不可更改 直接访问
字符串 Scalar 不可更改 顺序访问
列表 Container 可更改 顺序访问
元组 Container 不可更改 顺序访问
字典 Container 可更改 映射访问
4.9 不支持的类型
Python 目前还不支持的数据类型:
- char 或 byte:没有 char 或 byte 类型来保存单一字符或 8 比特整数。可以使用长度为 1 的字符串表示字符或 8 比特整数。
- 指针 :Python 替你管理内存,因此没有必要访问指针。可以使用 id()函数得到一个对象的身份号,这是最接近于指针的地址。其实在 Python 中, 一切都是指针。
- int vs short vs long :Python 的普通整数相当于标准整数类型,不需要类似 C 语言中的 int, short, long 这三 种整数类型。事实上 Python 的整数实现等同于 C 语言的长整数。 由于 Python 的整型与长整型密切融合, 用户几乎不需要担心什么。 你仅需要使用一种类型, 就是 Python 的整型。即便数值超出整型的表达范围, 比如两个很大的数相乘, Python 会自动的返回一个长整数给你而不会报错。
- float VS double :C 语言有单精度和双精度两种浮点类型。 Python 的浮点类型实际上是 C 语言的双精度浮点类型。Python 认为同时支持两种浮点类型的好处与支持两种浮点类型带来的开销不成比例, 所以Python 决定不支持单精度浮点数。对那些宁愿放弃更大的取值范围而需要更高精确度的用户来说, Python 还有一种十进制浮点数类型 Decimal。浮点数总是不精确的。Decimals 则拥有任意的精度。在处理金钱这类确定的值时, Decimal 类型就很有用。 在处理重量,长度或其它度量单位的场合, float 足够用了。
第五章
本章主题
- 数的简介
- 整型
- 布尔型
- 标准的整型
- 长整型
- 浮点型实数
- 复数
- 操作符
- 内建函数
- 其它数字类型
- 相关模块
本章会详细介绍每一种数字类型,它们适用的各种运算符, 以及用于处理数字的内建函数。简单介绍几个标准库中用于处理数字的模块。
5.1 数字类型
数字提供了标量贮存和直接访问。它是不可更改类型。
Python 支持多种数字类型:整型、长整型、布尔型、双精度浮点型、十进制浮点型和复数。
1. 如何创建数值对象并用其赋值 (数字对象)
创建数值对象和给变量赋值一样同样简单:
anInt = 1
aLong = -9999999999999999L
aFloat = 3.1415926535897932384626433832795
aComplex = 1.23+4.56J
2. 如何更新数字对象
通过给数字对象(重新)赋值, 可以“更新”一个数值对象。给更新加上引号,是因为实际上并没有更新该对象的原始数值。Python 的对象模型与常规对象模型有些不同。你所认为的更新实际上是生成了一个新的数值对象,并得到它的引用。
Python 中,变量更像一个指针指向装变量值的盒子。 对不可改变类型来说, 你无法改变盒子的内容, 但你可以将指针指向一个新盒子。每次将另外的数字赋给变量的时候,实际上创建了一个新的对象并把它赋给变量。(所有的不可变类型都是这样)
anInt += 1
aFloat = 2.718281828
3. 如何删除数字对象
按照 Python 的法则, 你无法真正删除一个数值对象, 你仅仅是不再使用它而已。如果你实际上想删除一个数值对象的引用, 使用 del 语句。如果使用一个已经被删除的对象引用, 会引发 NameError 异常。
del anInt
del aLong, aFloat, aComplex
来看下 Python 的四种主要数字类型。
5.2 整型
Python 有几种整数类型:
- 布尔类型是只有两个值的整型。
- 常规整型是绝大多数现代系统都能识别的整型。
- Python 也有长整数类型。然而,它表示的数值大小远超过 C 语言的长整数 。
5.2.1 布尔型
该类型的取值范围:布尔值True 和布尔值 False。
5.2.2 标准整数类型
Python 的标准整数类型是最通用的数字类型。在大多数 32 位机器上,标准整数类型的取值范围是-231 到 231-1,也就是-2,147,483,648 到 2,147,483,647。如果在 64 位机器上使用 64 位编译器编译 Python,那么在这个系统上的整数将是 64 位。下面是一些 Python 标准整数类型对象的例子:
0101 84 -237 0x80 017 -680 -0X92
Python 标准整数类型等价于 C 的(有符号)长整型。整数一般以十进制表示,但是 Python 也支持八进制或十六进制来表示整数。如果八进制整数以数字“0”开始, 十六进制整数则以 “0x” 或“0X” 开始。
5.2.3 长整型
C语言的长整数典型的取值范围是 32 位或 64 位。Python 的长整数类型能表达的数值仅仅与你的机器支持的(虚拟)内存大小有关, 换句话说, Python 能轻松表达很大很大很大的整数。
长整数类型是标准整数类型的超集,当需要使用比标准整数类型更大的整数时,就用长整数类型。在一个整数值后面加个 L(大写或小写),表示这个整数是长整数。这个整数可以是十进制,八进制, 或十六进制。eg:
16384L -0x4E8L 017L-2147483648l 052144364L 299792458l 0xDECADEDEADBEEFBADFEEDDEAL -5432101234L
核心风格:用大写字母 “L”表示长整数
推荐使用大写的“L”标记长整型, 能避免数字l和小写L的混淆。目前整型和长整型正在逐渐缓慢的统一,只有在对长整数调用 repr()函数时才有机会看到“L”,如果对长整数对象调用 str()函数就看不到 L 。eg:
>>> aLong = 999999999l
>>> aLong
999999999L
>>> print aLong 999999999
5.2.4 整型和长整型的统一
这两种整数类型正在逐渐统一为一种。
5.3 双精度浮点数
Python 中的浮点数类似 C 语言中的 double 类型,是双精度浮点数,可以用直接的十进制或科学计数法表示。每个浮点数占 8 个字节(64 比特),完全遵守 IEEE754 号规范(52M/11E/1S), 其中 52 个比特用于表示底,11 个比特用于表示指数(可表示的范围大约是正负 10 的 308.25 次方), 剩下的一个比特表示符号。这看上去相当完美,然而,实际精度依赖于机器架构和创建 Python 解释器的编译器。
浮点数值通常都有一个小数点和一个可选的后缀 e(大写或小写,表示科学计数法)。在 e 和指数之间可以用正(+)或负(-)表示指数的正负(正数的话可以省略符号)。eg:
0.0
-777.
1.6
-5.555567119
4.3e25
9.384e-23
-2.172818
float(12)
3.1416
4.2E-10
-90.
6.022e23
96e3 * 1.0
1.000000001
-1.609E-19
5.4 复数
现在虚数已经广泛应用于数值和科学计算应用程序中。一个实数和一个虚数的组合构成一个复数。一个复数是一对有序浮点数(x, y)。表示为 x + yj, 其中 x 是实数部分,y 是虚数部分。
下面是 Python 语言中有关复数的几个概念:
-
虚数不能单独存在,它们总是和一个值为0.0的实数部分一起来构成一个复数。
-
复数由实数部分和虚数部分构成
-
表示虚数的语法: real+imagj
-
实数部分和虚数部分都是浮点数
-
虚数部分必须有后缀j或J
下面是一些复数的例子:
64.375+1j 4.23-8.5j 0.23-8.55j 1.23e-045+6.7e+089j 6.23+1.5j -1.23-875J 0+1j 9.80665-8.31441J -.0224+0j
5.4.1 复数的内建属性
复数对象拥有数据属性, 分别为该复数的实部和虚部。复数还拥有 conjugate 方法, 调用它可以返回该复数的共轭复数对象。(两头牛背上的架子称为轭,轭使两头牛同步行走。共轭即为按一定的规律相配的一对——译者注)
表 5.1 复数属性
属性 描述
num.real 该复数的实数
num num.imag 该复数的虚数
num.conjugate() 返回该复数的共轭复数
>>> aComplex = -8.333-1.47j
>>> aComplex
(-8.333-1.47j)
>>> aComplex.real
-8.333
>>> aComplex.imag
-1.47
>>> aComplex.conjugate()
(-8.333+1.47j)
5.5 运算符
数值类型可进行多种运算。从标准运算符到数值运算符,甚至还有专门的整数运算符。
5.5.1 混合模式运算符
- 当两个整数相加时, + 号表示整数加法;
- 当两个浮点数相加时, + 表示浮点数加法;
- 依此类推。
在 Python 中, 非数字类型也可以使用 + 运算符。eg:字符串 A + 字符 串 B 表示把这两个字符串连接起来, 生成一个新的字符串。关键之处在于支持 + 运算符的每种数据类型, 必须告诉 Python, + 运算符应该如何去工作。 这也体现了重载概念的具体应用。
Python 确实支持不同的数字类型相加。 当一个整数和一个浮点数相加时,系统会决定使用整数加法还是浮点数加法(实际上并不存在混合运算)。Python 使用数字类型强制转换的方法来解决数字类型不一致的问题, 也就是说它会强制将一个操作数转换为同另一个操作数相同的数据类型。这种操作不是随意进行的, 它遵循以下基本规则:
- 如果两个操作数都是同一种数据类型,没有必要进行类型转换。
- 仅当两个操作数类 型不一致时, Python 才会去检查一个操作数是否可以转换为另一类型的操作数。如果可以, 转换它并返回转换结果。由于某些转换是不可能的,比如如果将一个复数转换为非复数类型, 将一个浮点数转换为整数等等,因此转换过程必须遵守几个规则。
要将一个整数转换为浮点数,只要在整数后面加个.0 就可以了。 要将一个非复数转换为复数,则只需要要加上一个 “0j” 的虚数部分。这些类型转换的基本原则是: 整数转换为浮点数, 非复数转换为复数。 在 Python 语言参考中这样描述 coerce() 方法:
-
如果有一个操作数是复数, 另一个操作数被转换为复数。
-
否则,如果有一个操作数是浮点数, 另一个操作数被转换为浮点数。
-
否则, 如果有一个操作数是长整数,则另一个操作数被转换为长整数;
-
否则,两者必然都是普通整数,无须类型转换。(参见下文中的示意图)
数字类型之间的转换是自动进行的,程序员无须自己编码处理类型转换。不过在确实需要明确指定对某种数据类型进行特殊类型转换的场合, Python 提供了 coerce() 内建函数来帮助你实现这种转换。(见 5.6.2 小节)
下面演示一下 Python 的自动数据类型转换。为了让一个整数和一个浮点数相加, 必须使二者转换为同一类型。因为浮点数是超集,所以在运算开始之前, 整数必须强制转换为一个浮点数,运算结果也是浮点数:
>>> 1 + 4.5
5.5
5.5.2 标准类型运算符
第四章中讲到的标准运算符都可以用于数值类型。上文中提到的混合模式运算问题, 也就是不同数据类型之间的运算,在运算之前,Python 内部会将两个操作数转换为同一数据类型。
下面是一些数字标准运算的例子:
>>> 5.2 == 5.2
True
>>> -719 >= 833
False
>>> 5+4e >= 2-3e
True
>>> 2 < 5 < 9 # same as ( 2 < 5 ) and ( 5 < 9 )
True
>>> 77 > 66 == 66 # same as ( 77 > 66 ) and ( 66 == 66 )
True
>>> 0. < -90.4 < 55.3e2 != 3 < 181
False
>>> (-1 < 1) or (1 < -1)
True
5.5.3 算术运算符
- 单目运算符正号(+)和负号(-)
- 双目运算符, +,-,*,/,%,还有 ** , 分别表示加法,减法, 乘法, 除法, 取余, 和幂运算。
- 从 Python2.2 起,还增加了一种新的整除运算符 // 。
除法
传统除法― 对整数操作数,会执行“地板除” (floor,取比商小的最大整数。例如 5 除以 2 等于 2.5,其中“2”就称为商的“地板”,即“地板除”的结果)。对浮点操作数会执行真正的除法。
在未来的 Python 版本中,Python 开发小组已经决定改变 / 运算符的行为。/ 的行为将变更为真正的除法, 会增加一种新的运算来表示地板除。
下面总结一下 Python 现在的除法规则, 以及未来的除法规则:
传统除法
如果是整数除法,传统除法会舍去小数部分,返回一个整数(地板除)。如果操作数之一是浮点数,则执行真正的除法。包括 Python 语言在内的很多语言都是这种行为。
>> 1 / 2 # perform integer result (floor) # 地板除 0
>> 1.0 / 2.0 # returns actual quotient#真正除法 0.5
真正的除法
除法运算总是返回真实的商, 不管操作数是整数还是浮点数。在未来版本的 Python 中, 这将是除法运算的标准行为。现阶段通过执行 from future import division 指令, 也可以做到这一点。
>>> from __future__ import division
>>>
>>> 1 / 2 # returns real quotient
0.5
>>> 1.0 / 2.0 # returns real quotient 0.5
地板除
从 Python 2.2 开始, 一个新的运算符 // 已经被增加进来, 以执行地板除: // 除法不管操作数何种数值类型,总是舍去小数部分,返回数字序列中比真正的商小的最接近的数字。
>>> 1 // 2 # floors result, returns integer # 地板除, 返回整数
0
>>> 1.0 // 2.0 # floors result, returns float # 地板除, 返回浮点数
0.0
>>> -1 // 2 # move left on number line# 返回比 –0.5 小的整数, 也就是 -1
-1
取余
整数取余相当容易理解, 浮点数取余就略复杂些。
商取小于等于精确值的最大整数的乘积之差. 即: x - (math.floor(x/y) * y) 或者
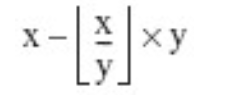
对于复数,取余的定义类似于浮点数,不同之处在于商仅取其实数部分,即: x - (math.floor((x/y).real) * y)。
幂运算
幂运算操作符比其左侧操作数的一元操作符优先级低,比起右侧操作数的一元操作符的优先级高,由于这个特性你会在算术运算符表中找到两个 ** .下面举几个例子:
>>> 3 ** 2
9
>>> -3 ** 2 # ** 优先级高于左侧的 -,先计算 3**2 再取其相反数
-9
>>> (-3) ** 2 # 加括号提高 -的优先级
9
>>> 4.0 ** -1.0# ** 优先级低于右侧的 - 0.25,4**(-1)
总结
表 5.3 总结了所有的算术运算符, 从上到下, 计算优先级依次降低。 这里列出的所有运算符都比即将在 5.5.4 小节讲到的位运算符优先级高。
注:** 运算符优先级高于单目运算符
5.5.4 *位运算符(只适用于整数)
Python 整数支持标准位运算:取反(~),按位 与(&), 或(|) 及 异或(^) 及左移(<<)和右 移(>>)。Python 这样处理位运算:
-
负数会被当成正数的2进制补码处理。
-
左移和右移 N 位等同于无溢出检查的 2 的 N 次幂运算: 2**N。
-
对长整数来说, 位运算符使用一种经修改的 2 进制补码形式,使得符号位可以无限的
向左扩展。
取反(~)运算的优先级与数字单目运算符相同, 是所有位操作符中优先级最高的一个。 左移和右移运算的优先级次之,但低于加减法运算。与, 或, 异或 运算优先级最低。所有位运 算符按优先级高低列在表 5.4 中。
表 5.4 整型位运算符

下面是几个使用整数 30(011110),45(101101),60(111100)进行位运算的例子:
>>> 30 & 45
12
>>> 30 | 45
63
>>> 45 & 60
44
>>> 45 | 60
61
>>> ~30
-31
>>> ~45
-46
>>> 45 << 1
90
>>> 60 >> 2
15
>>> 30 ^ 45
51
5.6 内建函数与工厂函数
5.6.1 标准类型函数
cmp(), str() 和 type() 内建函数。 这些函数可以用于所有的标准类型。
比较两个数的大小, 将数字转换为字符串, 以及返回数字对象的类型。
>>> cmp(-6, 2)
-1
>>> cmp(-4.333333, -2.718281828)
-1
>>> cmp(0xFF, 255)
0
>>> str(0xFF) # 非十进制转成十进制进行字符串显示
'255'
>>> str(55.3e2)
'5530.0'
>>> type(0xFF)
<type 'int'>
>>> type(98765432109876543210L)
<type 'long'>
>>> type(2-1j)
<type 'complex'>
5.6.2 数字类型函数
Python 现在拥有一系列针对数字类型的内建函数。
转换工厂函数
函数 int(), long(), float() 和 complex() 用来将其它数值类型转换为相应的数值类型。这些函数也接受字符串参数, 返回字符串所表示的数值。
int() 和 long() 在转换字符串时,接受一个进制参数。如果是数字类型之间的转换,则这个进制参数不能使用。
内建函数 bool()用来将整数值 1 和 0 转换为标准布尔 值 True 和 False。
另外, 由于 Python 2.2 对类型和类进行了整合(这里指 Python 的传统风格类和新风格类 ——译者注), 所有这些内建函数现在都转变为工厂函数。所谓工厂函数就是指这些内建函数都是类对象,调用它们时,实际上是创建了一个类实例。
eg:
>>> int(4.25555)
4
>>> long(42)
42L
>>> float(4)
4.0
>>> complex(4)
(4+0j)
>>>
>>> complex(2.4, -8)
(2.4-8j)
>>>
>>> complex(2.3e-10, 45.3e4)
(2.3e-10+453000j)
表 5.5 数值工厂函数总结

功能函数
五个运算内建函数用于数值运算: abs(), coerce(), divmod(), pow(), pow() 和 round()。
abs()返回给定参数的绝对值。如果参数是一个复数,返回math.sqrt(num.real2 +num.imag2)。
>>> abs(-1)
1
>>> abs(10.)
10.0
>>> abs(1.2-2.1j)
2.41867732449
>>> abs(0.23 - 0.78)
0.55
函数 coerce(),从技术上讲它是一个数据类型转换函数,不过它的行为更像一个运算符,因此将它放到了这一小节。函数 coerce()为程序员提供了不依赖 Python 解释器, 而是自定义两个数值类型转换的方法。 对一种新创建的数值类型来说, 这个特性非常有用。函数 coerce()仅回一个包含类型转换完毕的两个数值元素的元组。eg:
>>> coerce(1, 2)
(1, 2)
>>>
>>> coerce(1.3, 134L)
(1.3, 134.0)
>>>
>>> coerce(1, 134L)
(1L, 134L)
>>>
>>> coerce(1j, 134L)
(1j, (134+0j))
>>>
>>> coerce(1.23-41j, 134L)
((1.23-41j), (134+0j))
divmod()内建函数把除法和取余运算结合起来, 返回一个包含商和余数的元组。对整数来说,它的返回值就是地板除和取余操作的结果。对浮点数来说, 返回的商部分是math.floor(num1/num2),对复数来说, 商部分是 ath.floor((num1/num2).real)。
>>> divmod(10,3)
(3, 1)
>>> divmod(3,10)
(0, 3)
>>> divmod(10,2.5)
(4.0, 0.0)
>>> divmod(2.5,10)
(0.0, 2.5)
>>> divmod(2+1j, 0.5-1j)
(0j, (2+1j))
函数 pow() 和双星号 (**) 运算符都可以进行指数运算。区别并不仅仅在于一个是运算符,一个是内建函数。内建函数 pow()还接受第三个可选的参数,一个余数参数。如果有这个参数的, pow() 先进行指数运算,然后将运算结果和第三个参数进行取余运算。这个特性主要用于密码运算,并且比 pow(x,y) % z 性能更好, 因为该函数的实现类似于 C 函数 pow(x,y,z)。
>>> pow(2,5)
32
>>>
>>> pow(5,2)
25
>>> pow(3.141592,2)
9.86960029446
>>>
>>> pow(1+1j, 3)
(-2+2j)
内建函数 round()用于对浮点数进行四舍五入运算。它有一个可选的小数位数参数。如果不提供小数位参数, 它返回与第一个参数最接近的整数(但仍然是浮点类型)。第二个参数将结果精确到小数点后指定位数。
>>> round(3)
3.0
>>> round(3.45)
3.0
>>> round(3.4999999)
3.0
>>> round(3.4999999, 1)
3.5
>>> round(-3.5)
-4.0
>>> round(-3.4)
-3.0
>>> round(-3.49)
-3.0
>>> round(-3.49, 1)
-3.5
round() 函数是按四舍五入的规则进行取整。round(0.5)得到 1, round(-0.5)得到-1。int(), round(), math.floor() 这几个函数好像做的是同一件事, 很容易将它们弄混,下面列出它们之间的不同之处:
- 函数int()直接截去小数部分。(返回值为整数)
- 函数floor()得到最接近原数但小于原数的整数。(返回值为浮点数)
- 函数round()得到最接近原数的整数。(返回值为浮点数)
下面例子用四个正数和四个负数作为这三个函数的参数,将返回结果做个比较
(为了便于比较,将 int()函数的返回值也转换成了浮点数)。
>>> import math
>>> for eachNum in (.2, .7, 1.2, 1.7, -.2, -.7, -1.2, -1.7):
... print "int(%.1f)\t%+.1f" % (eachNum, float(int(each-
Num)))
... print "floor(%.1f)\t%+.1f" % (eachNum,... math.floor(eachNum))
... print "round(%.1f)\t%+.1f" % (eachNum, round(eachNum))
... print '-' * 20
...
int(0.2) +0.0
floor(0.2) +0.0
round(0.2) +0.0
--------------------
int(0.7) +0.0
floor(0.7) +0.0
round(0.7) +1.0
--------------------
int(1.2) +1.0
floor(1.2) +1.0
round(1.2) +1.0
--------------------
int(1.7) +1.0
floor(1.7) +1.0
round(1.7) +2.0
--------------------
int(-0.2) +0.0
floor(-0.2) -1.0
round(-0.2) +0.0
--------------------
int(-0.7) +0.0
floor(-0.7) -1.0
round(-0.7) -1.0
--------------------
int(-1.2) -1.0
floor(-1.2) -2.0
round(-1.2) -1.0
--------------------
int(-1.7) -1.0
floor(-1.7) -2.0
round(-1.7) -2.0
表 5.6 数值运算内建函数

5.6.3 仅用于整数的函数
除了适应于所有数值类型的内建函数之外,Python 还提供一些仅适用于整数的内建函数(标准整数和长整数)。这些函数分为两类,一类用于进制转换,另一类用于 ASCII 转换。
进制转换函数
除了十进制,Python 整数也支持八进制和 16 进制整数。 有两个内建函数返回字符串表示的8进制和16进制整数:oct() 和 hex()。它们都接受一个整数(任意进制的)对象,并返回一个对应值的字符串对象。eg:
>>> hex(255)
'0xff'
>>> hex(23094823l)
'0x1606627L'
>>> hex(65535*2)
'0x1fffe'
>>>
>>> oct(255)
'0377'
>>> oct(23094823l)
'0130063047L'
>>> oct(65535*2)
'0377776'
ASCII 转换函数
Python 提供了 ASCII(美国标准信息交换码)码与其序列值之间的转换函数。每个字符对应一个唯一的整数(0-255)。函数 chr()接受一个单字节整数值,返回一个字符串,其值为对应的字符。函数 ord()则相反,它接受一个字符,返回其对应的整数值。
>>> ord('a')
97
>>> ord('A')
65
>>> ord('0')
48
>>> chr(97)
'a'
>>> chr(65L)
'A'
>>> chr(48)
'0'
表 5.7 仅适用于整数的内建函数
hex(num) 将数字转换成十六进制数并以字符串形式返回 oct(num) 将数字转换成八进制数并以字符串形式返回
chr(num) 将ASCII值的数字转换成ASCII字符,范围只能是0 <= num <= 255。
ord(chr) 接受一个 ASCII 或 Unicode 字符(长度为1的字符串),返回相应的ASCII 或Unicode 值。
unichr(num) 接受Unicode码值,返回 其对应的Unicode字符。所接受的码值范围依赖于 你的Python是构建于UCS‐2还是UCS‐4。
5.7 其他数字类型
5.7.1 布尔“数”
布尔值对应整数的 1 和 0。下面是有关布尔类型的主要概念:
- 有两个永不改变的值 True 或 False。
- 布尔型是整型的子类,但是不能再被继承而生成它的子类。
- 没有__nonzero__()方法的对象的默认值是True。
- 值为零的任何数字或空集(空列表、空元组和空字典等)在Python中的布尔值都是 False。
- 在数学运算中,Boolean 值的 True 和 False 分别对应于 1 和 0。
- 以前返回整数的大部分标准库函数和内建布尔型函数现在返回布尔型。
- True和False现在都不是关键字,但是在Python将来的版本中会是。
所有 Python 对象都有一个内建的 True 或 False 值。下面是使用内建类型布尔值的一些例子:
# intro
>>> bool(True) True
>>> bool(0) False
>>> bool('0') True
>>> bool([]) False
# 使用布尔数
>>> foo = 42
>>> bar = foo < 100
>>> bar
True
>>> print bar + 100
101
>>> print '%s' % bar
True
>>> print '%d' % bar
1
# 无 __nonzero__()
>>> class C: pass
>>> c = C()
>>> bool(c)
True
>>> bool(C)
True
# 重载 __nonzero__() 使它返回 False
>>> class C:
... def __nonzero__(self):
... return False
...
>>> c = C()
>>> bool(c) False
>>> bool(C) True
# 哦,别这么干!! (无论如何不要这么干!)
>>> True, False = False, True
>>> bool(True)
False
>>> bool(False)
True
5.7.2 十进制浮点数
从 Python2.4 起(参阅 PEP327)十进制浮点制成为一个 Python 特性。主要是因为下面的语句经常会让程序员抓狂:为什么会这样?这是因为语言绝大多数 C 语言的双精度实现都遵守 IEEE 754 规范,其中
>>> 0.1
0.1000000000000001
52 位用于底。因此浮点值只能有 52 位精度,类似这样的值的二进制表示只能象上面那样被截断。0.1 的二进制表示是 0.11001100110011 . . .
因为最接近的二进制表示就是.0001100110011...或 1/16 +1/32 + 1/256 + . . .
这些片断不停的重复直到舍入出错。如果我们使用十进制来做同样的事情, 感觉就会好很多,看上去会有任意的精度。注意下面,你不能混用十进制浮点数和普通的浮点 数。你可以通过字符串或其它十进制数创建十进制数浮点数。你必须导入 decimal 模块以便使用 Decimal 类:
>>> from decimal import Decimal
>>> dec = Decimal(.1)
Traceback (most recent call last): File "<stdin>", line 1, in ?
File "/usr/local/lib/python2.4/decimal.py", line 523, in __new__
raise TypeError("Cannot convert float to Decimal. " +
TypeError: Cannot convert float to Decimal. First convert the float to a string
>>> dec = Decimal('.1')
>>> dec
Decimal("0.1")
>>> print dec
0.1
>>> dec + 1.0
Traceback (most recent call last): File "<stdin>", line 1, in ?
File "/usr/local/lib/python2.4/decimal.py", line 906, in __add__
other = _convert_other(other)
File "/usr/local/lib/python2.4/decimal.py", line 2863, in _convert_other
raise TypeError, "You can interact Decimal only with int, long or
Decimal data types."
TypeError: You can interact Decimal only with int, long or Decimal data types.
>>>
>>> dec + Decimal('1.0') Decimal("1.1")
>>> print dec + Decimal('1.0')
1.1
可以从 Python 文档中读取相关的 PEP 以了解十进制数。十进制数和其它数值类型样, 可以使用同样的算术运算符。由于十进制数本质上是一种用于数值计算的特殊类, 在本章的剩余部分将不再专门讲解十进制数。
5.8 相关模块
Python 标准库中有不少专门用于处理数值类型对象的模块,它们增强并扩展了内建函数的功能和数值运算的功能。 表 5.8 列出了几个比较核心的模块。要详细了解这些模块,请参阅这些模块的文献或在线文档。
对高级的数字科学计算应用来说,你会对著名的第三方包 Numeric(NumPy) 和 SciPy 感兴趣。关于这两个包的详细请访问下面的网址。http://numeric.scipy.org/ & http://scipy.org/
表 5.8数字类型相关模块
模块 介绍
decimal 十进制浮点运算类Decimal
array 高效数值数组(字符,整数,浮点数等等)
math/cmath标准C库数学运算函数。常规数学运算在match模块,复数运算在cmath模块
operator 数字运算符的函数实现。比如 tor.sub(m,n)等价于m-n
random 多种伪随机数生成器
核心模块: random
需要随机数功能时,可以使用random 模块。该模块包含多个伪随机数发生 器,它们均以当前的时间戳为随机数种子。该模块中最常用的函数如下:两个整数参数,返回二者之间的随机整数
- randrange() 它接受和 range()函数一样的参数, 随机返回 range([start,]stop[,step])结果的一项
- uniform() 几乎和 randint()一样,不过它返回的是二者之间的一个浮点数(不包括范围上限)。
- random()类似 uniform() 只不过下限恒等于 0.0,上限恒等于 1.0
- choice()随机返回给定序列的一个元素
表 5.9 总结了数值类型的所有内建函数和运算符。
- 结果为 number 表示可以为所有四种数值类型,可能与操作数相同
- 与单目运算符有特殊关系,参阅 5.5.3 小节和表 5.2
- 单目运算符
练习


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· AI技术革命,工作效率10个最佳AI工具