p
1. 为什么要学习linux基础
公司会有以下职位:
- 运维工程师:比如linux上搭建服务,维护服务,维护软件等。
- 网络工程师:处理网络状况等。
- 软件开发工程师:开发应用程序的。开发开发完,运维工程师将应用放到服务器上,比如linux。所以要对linux的构造、运行原理、命令要有所了解。
2. python开发学习内容
1)python基础:汉字→词语→作文。(基础打好了,才能写出好作文)
基本数据类型(词语)
→函数(名言名句)
→面向对象(名言名句)
会让程序更优美。
2)网络编程:消息放到网络,对方收到,通过网络传输消息。(socket)
3)web框架:用于写网站。比如你用20行写出来一个网站,你知道为什么吗?不知道,只是死记硬背。学web框架,其实就是在网络编程的基础上来实现的。本质就是网络请求服务。
4)设计模式和算法:【设计模式】决定程序写的好不好。基础知识都一样的时候,设计模式不一样,写出来的代码决定漂不漂亮。 23个设计模式,23个规则,什么场景用什么设计模式。设计时间 > 编码时间。【算法】如果关注算法,不再看谁能不能完成,而是看谁能更快更准。初级程序员平常用不上算法,但面试的时候是有的。
5)项目阶段:实战,使用上面的东西做一个应用。
https://www.cnblogs.com/wupeiqi/articles/5433893.html3. 编程语言介绍
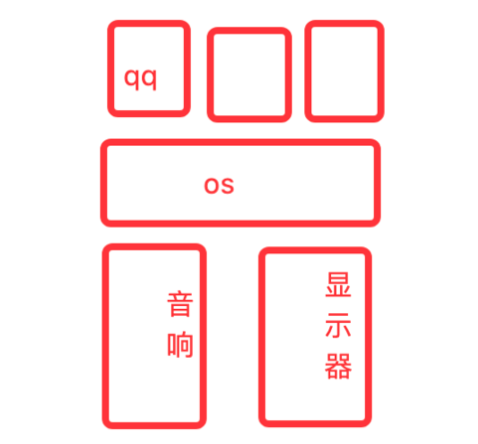
QQ语音(应用程序)→运行在操作系统(微软人开发OS)→调用音响、调用显示器等等
-
一开始没有编程语言时,用0101来编码。后来“mini红”制定了一个规则。比如A就是1010。那么就不用写0101了,写A就可以了。以此类推。
但我们写的语言,计算机无法直接识别→那么就得把我们写的语言转换成0101→再交给操作系统。 -
后来,小红感觉还是效率不高,不如直接写成中文,比如“你去打开浏览器”。
计算机更识别不了了,那就得小红语言→经过翻译→mini红语言→经过翻译→翻译成0101→再交给操作系统。
类比就是高级语言→低级语言→操作系统。
高级语言开发效率高。但执行效率不高(需要转换成0101)。
3.1 程序编程语言
- 高级语言:python、java、C#、php、C++、GO、RUby等
- 低级语言:C、汇编。
3.2 语言的区分
- 机器码:0101,计算机能够直接识别的。
- 字节码:高级语言转换成字节码,字节码转换成机器码。
为什么要有字节码呢?TODO
3.3 C语言一定要自学
如果想走高级别,要学,它是根源。高级语言是低级语言的又一个封装,了解底层实现原理,会更清楚怎么使用好高级语言。
但是C开发效率低,比如自己控制内存(申请内存,释放内存)。一旦忘记释放,就内存泄漏了。
高级语言一般不需要程序员关心内存。开发python的人已经把内存管理写完了,集成到python语言里了。开发效率高。小公司或者大公司一般用python开发,开发快,抢占市场。随着公司发展壮大,就会C开发底层的东西,跑的快。
3.4 各种语言的应用
- PHP:适用于网站,页面。比如阿法狗它就不能做。php现在已经在排行榜上下来了。其他python、java、c#都能做,既能写应用,又能写网站。
- Java优势:Java执行效率比python高。
- python优势:10行代码,java需要100行代码,实现周期短,开发效率高。
摩尔定律:硬件的发展速度比软件快。硬件资源越来越便宜。python加一台服务器也可以等同于java。
其实程序之间快慢差异其实不大。还要看程序员的能力。
3.5 python的种类
- JPython
- IronPython
- CPython
- JavascriptPython
- RubyPython
- pypy:用于CPython开发的Python,python的变种和升级。 最快,但不是主流。功能还不够完善稳定。
若要执行python文件,将文件交给python软件,python将文件内容读取出来,转换成字节码,执行,最终获取结果。
3.6 python解释器
windows\linux 操作系统内部已经有C语言了。
python安装在OS上→按照python规则写代码文件→文件交给python应用程序,python将文件内容读取出来,转换成字节码和执行(中间会调用C)→获取结果。
python软件我们一般称为python解释器。把文件交给python解释器(内存管理:内存申请,内存销毁,垃圾回收机制)。
3.7 python安装
python2→python3
python2的代码要在python3运行,需要改一些代码。
一般升级后的功能会多。但可能会有python2的功能在python3没有了。
python2继续更新,更新目的是越来越像python3。实现慢慢过渡。
python3也在继续更新。
windows里面,安装python2和python3,C:/python2 C:/python3两个安装目录。
linux里面,安装python2和python3。python2和python3。
windows安装
1、下载安装包
https://www.python.org/downloads/
2、安装
默认安装路径:C:\python27
3、配置环境变量
【右键计算机】--》【属性】--》【高级系统设置】--》【高级】--》【环境变量】--》【在第二个内容框中找到 变量名为Path 的一行,双击】 --> 【Python安装目录追加到变值值中,用 ; 分割】
如:原来的值;C:\python27,切记前面有分号
如果不配置环境变量,就需要每次运行python.exe的时候都需要写完整的python路径。
C:\Users\Adminstrator>C:\Python35-32\python.ext D:\1.py
配置环境变量,直接运行python就会去路径下去找。
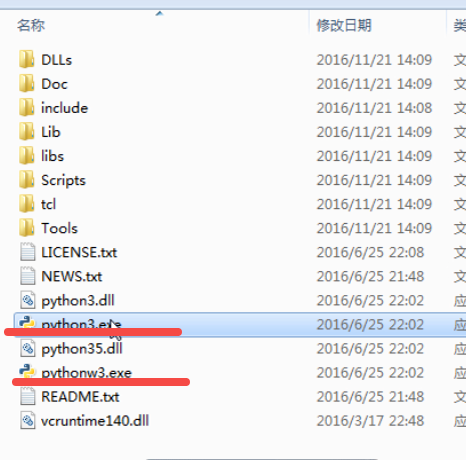
有一个问题,比如python3和python2下面的exe都叫python,python3和python2都配置环境变量的情况下,去终端执行python,到底用的哪一个python版本呢?
解决方案:给python.exe和pythonw.exe 重新命名。
linux安装
无需安装,原装Python环境
ps:如果自带2.6,请更新至2.7
更新python
windows: 卸载重装即可
linux: Linux的yum依赖自带Python,为防止错误,此处更新其实就是再安装一个Python,不删除原有的python。
查看默认Python版本
python -V
1、安装gcc,用于编译Python源码
yum install gcc
2、下载源码包,https://www.python.org/ftp/python/
3、解压并进入源码文件
4、编译安装
./configure
make all
make install
5、查看版本
/usr/local/bin/python2.7 -V
6、修改默认Python版本
mv /usr/bin/python /usr/bin/python2.6
ln -s /usr/local/bin/python2.7 /usr/bin/python
7、防止yum执行异常,修改yum使用的Python版本
vi /usr/bin/yum
将头部 #!/usr/bin/python 修改为 #!/usr/bin/python2.6
python 初始及变量
python文件后缀名
- 文件的后缀名是什么都可以运行,eg:python 1.txt
- 但假如功能较多,文件之间需要进行模块导入,这个文件名必须是.py,否则无法导入。
- 为了保持一致和标准,而且根据后缀很容易判断是python文件,文件后缀名要是.py。
python代码两种执行方式
- python解释器 py文件路径
- 输入python(不传入py文件名),进入解释器。解释器等待用户输入什么,然后解释什么,解释器在实时的做处理。
#!/usr/bin/env python
#!/usr/bin/env python
print("hello world!")
- 这句代码在windows上没有任何影响
- D:\python35\python 2.py
- 加上环境变量,简便成python 2.py
- 这句代码可以在linux上以简便方式执行
- python 2.py
- ./2.py 没有指定python解释器,如果不告诉,执行报错,#!/usr/bin/env python就是告诉要用的python解释器。这是linux独有的方式
中文编码
-*- coding:utf8 -*-
print("中文")
若是英文,在python2和python3执行是一样的。
若是中文,在python2不能执行,在python3可以执行。
为什么呢?计算机最开始只认英文,ASCII码,不包括中文,在python2的解释器内部,默认使用ASCII码编码。按照ASCII码来解释中文的时候,解释不通,会报错。
怎么办呢?-*- coding:utf8 -*-告诉解释器,读取py文件的时候,用utf-8编码来解释。
编码的发展历史:
- 最开始只有ASCII码,8位,最多表示256种,但是越来越多国家开始使用计算机,远远不满足使用。
- 计算机界开始出现所有国家都能用的万国码,unicode,至少用16位。
- asciii 00000001; unicode 000000000000001 (浪费内存和磁盘空间,其实8位就可以表示了,从而有了utf-8);utf8(能用多少表示就用多少表示,能少就少。)
因此,假如文件中有中文,python3无需关注,python2必须要加上utf8编码。
变量
# 提醒用户输入用户名和密码,用于检测账号。等待用户输入,值赋值给n
n1 = input("请输入用户名:")
n2 = input("请输入密码:")
print(n1)
print(n2)
# n是变量,代指某个变化的值
变量定义的规则:
- 变量名只能是字母、数字或下划线的任意组合
- 变量名的第一个字符不能是数字
- 以下关键字不能声明为变量名。 ['and', 'as', 'assert', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'exec', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'not', 'or', 'pass', 'print', 'raise', 'return', 'try', 'while', 'with', 'yield']
- 最好不用和python内置的名字重合(内置方法,内置类,eg:sum())。
- 变量名要有意义,eg:user_id, 单词之间用下划线连接。每种语言的命名格式不同。
>>> sum([1,2,3])
6
>>> sum=3
>>> sum([1,2,3])
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'int' object is not callable
>>>
怎么避免变量名取了关键字呢?
- 多写。
- pycharm会有自动提示。
a12_b1="葵花宝典"
print(a12_b1)
print(a12_b1)
print(a12_b1)
======
print("葵花宝典")
print("葵花宝典")
print("葵花宝典")
在解释道C语言层面,上面相当于下面。
>>> print(a12_b1)
葵花宝典
>>> print(a12_b1)
葵花宝典
>>> print(a12_b1)
葵花宝典
>>> print(id(a12_b1))
139876182616456
>>> print(id(a12_b1))
139876182616456
>>> print(id(a12_b1))
139876182616456
>>> print("葵花宝典")
葵花宝典
>>> print("葵花宝典")
葵花宝典
>>> print("葵花宝典")
葵花宝典
>>> print(id("葵花宝典"))
139876056207824
>>> print(id("葵花宝典"))
139876056207824
>>> print(id("葵花宝典"))
139876056207824
>>> print(id("葵花宝典"))
139876056207824
流程控制和缩进
python代码块,按照缩进来判断是不是代码块,缩进一般是4个空格。IDE里面一般用一个tab生成4个空格。
1. if else
import getpass
name = raw_input('请输入用户名:')
pwd = getpass.getpass('请输入密码:')
if name == "alex" and pwd == "cmd":
print "欢迎,alex!"
else:
print "用户名和密码错误"
2. if else 嵌套
3. if elseif else 多条件判断
# alex --> 超级管理员
# eric --> 普通管理员
# tony,rain --> 业务主管
# 其他 --> 普通用户
name = raw_input('请输入用户名:')
if name == "alex":
print "超级管理员"
elif name == "eric":
print "普通管理员"
elif name == "tony" or name == "rain":
print "业务主管"
else:
print "普通用户"
4. pass 表示什么都不执行
if 1 == 1:
pass
else:
print("1!=1")
5. 基础数据类型-字符串
字符串:引号引起来的,每一个组成部分叫字符。
name = "alex"
name = 'alex'
name = """alex"""
name = '''alex'''
# 字符串加法
n1 = "alex"
n2= "good"
n4 = "db"
n3 = n1 + n2 + n4 # "alexgooddb"
# 字符串乘法
n1 = "alex"
n2 = n1 * 10 # 字符串重复10次
6. 基础数据类型-数字
age = 13
a1 = 10
a2 = 20
a3 = a1 + a2
a3 = a1 - a2
a3 = a1 * a2
a3 = a1 / a2
a3 = 4**4
a3 = 39 % 8 # 获取余数
>>> a = 39 / 8
>>> a
4.875 # 真实的结果
>>> a = 39 // 8
>>> a
4 # 取商
>>> a = 39 % 8
>>> a
7 # 去余
7. while 基本循环
while 条件:
# 循环体
# 如果条件为真,那么循环体则执行
# 如果条件为假,那么循环体不执行
count = 0
while count < 10:
print(count)
count += 1
print("ok")
8. break & continue
# break用于退出所有循环
while True:
print "123"
break
print "456"
# continue用于退出当前循环,继续下一次循环
while True:
print "123"
continue
print "456"
实现用户登陆(三次机会重试)
right_name = "root"
right_pass = "123456"
count = 0
while count < 3:
user_name = input("please input user name")
password = input("please input password")
if right_pass == password and right_name == user_name:
break
else:
print("error")
count += 1
pycharm 安装
pycharm:开发python的IDE
- 专业版:需要交钱
- 学习班:免费用
- 其他
pycharm 创建项目的时候,要告诉它解释器用哪个
更改代码大小
滚轮调整代码大小
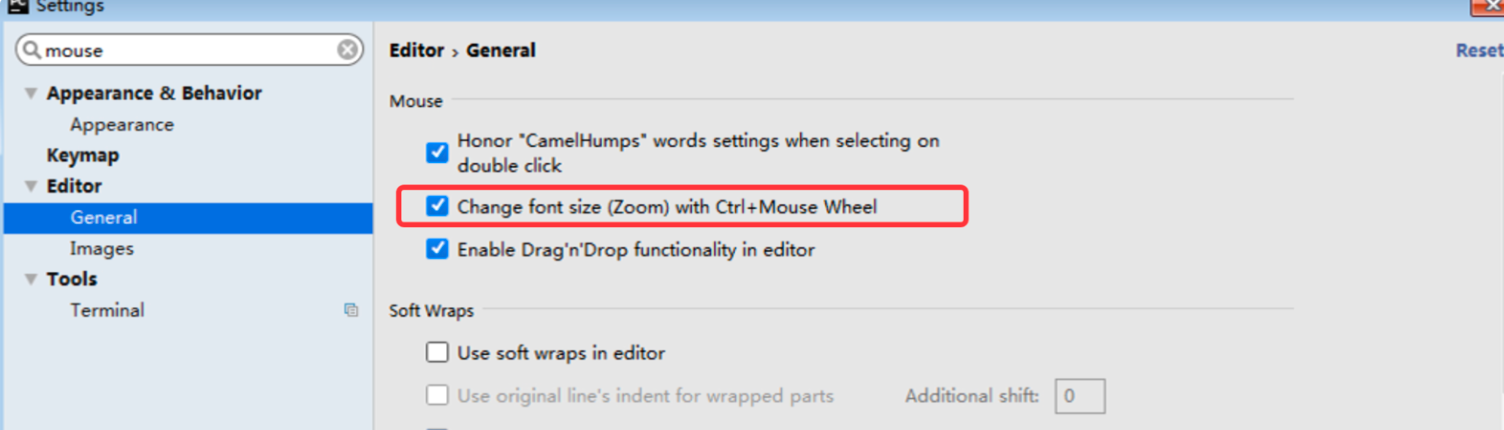
预定义python文件头
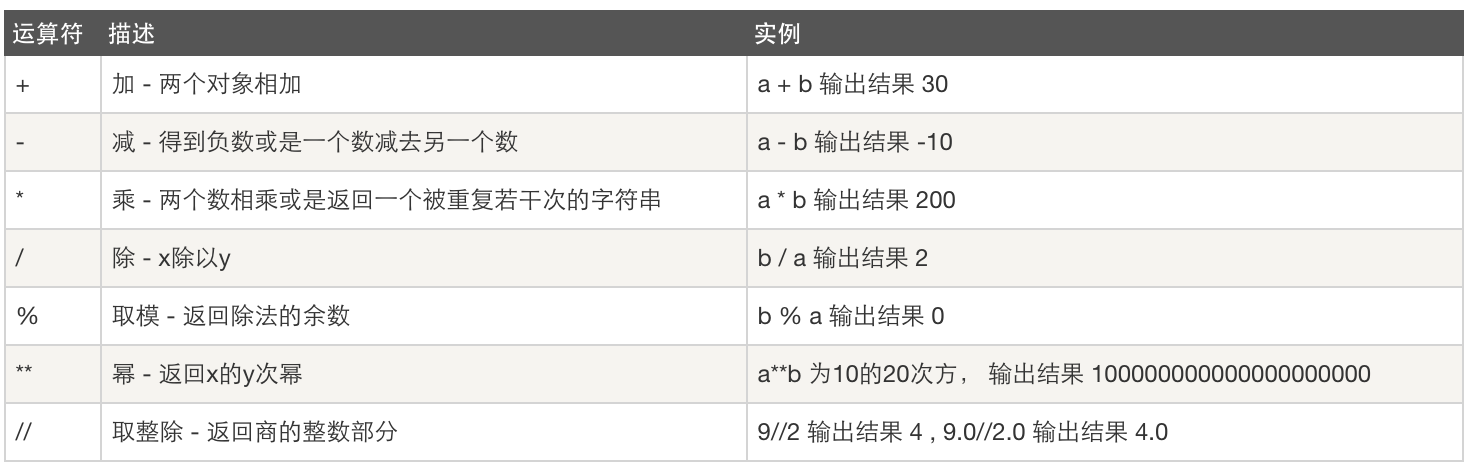
运算符
1.算数运算
2.比较运算

3. 赋值运算:
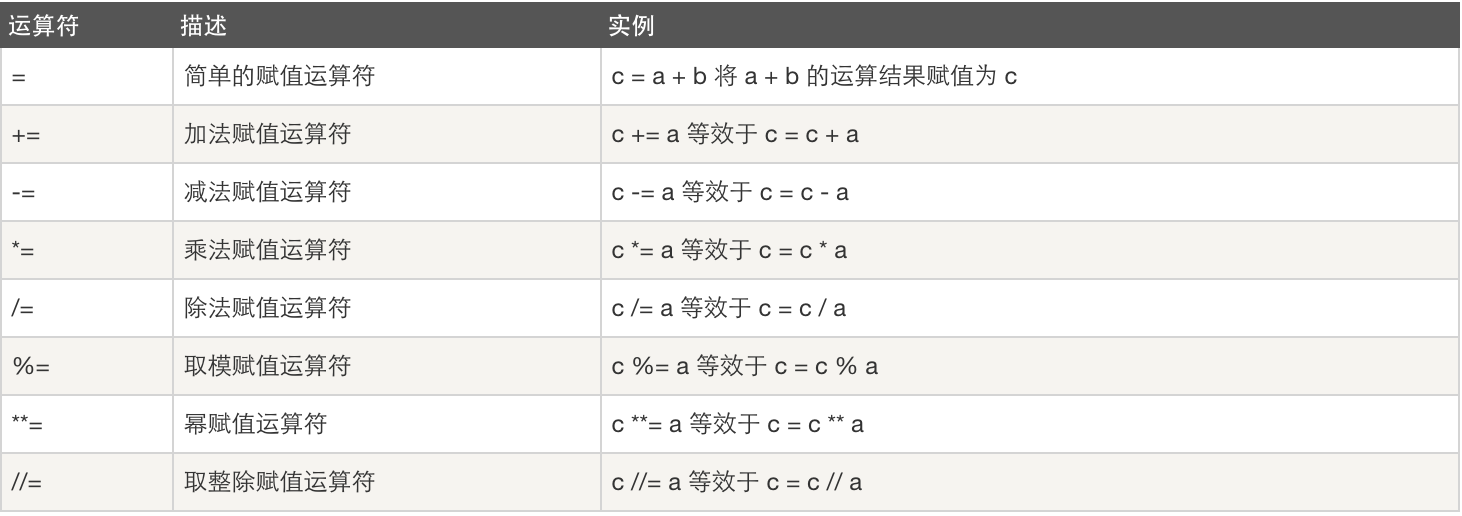
4. 逻辑运算:

5. 成员运算

6. or and 运算符优先级
- 括号,加括号比较清晰
- 没有括号,从左到右
- 遇到or ,前面是真的,就不会执行后面的。
- 遇到or ,前面是假的,继续执行后面的。
- 遇到and,前面是true,也会继续执行。
- 遇到and,前面是false,不会继续执行,返回false。
总结:
执行顺序:
- 从前到后
- 结果
- True OR -》True
- True AND -》继续走
- False OR -》 继续走
- Flase AND -》False
user = "alex"
pwd = "123"
user == "alex" and pwd == "123" or 1==1 and pwd=="456" # true
user == "alex" and pwd != "123" or 1==1 and pwd=="456" # false
user == "alex" and pwd != "123" or 1==1 and pwd=="123" # true
基本数据类型介绍
数字有数字的功能。
字符串有字符串的功能。
每一种数据类型都有各自的功能,且不同。
基本数据类型有以下几种,并同时介绍他们具有的魔法。
数字 int
python3里面,无论多大的数字,永远都是int类型。
python2里面,int是有范围的,超过范围之后叫long,长整型。
int(整型)
- 在32位机器上,整数的位数为32位,取值范围为-231~231-1,即-2147483648~2147483647
- 在64位系统上,整数的位数为64位,取值范围为-263~263-1,即-9223372036854775808~9223372036854775807
int都有哪些功能呢?都在int里面,可以查看int的定义。
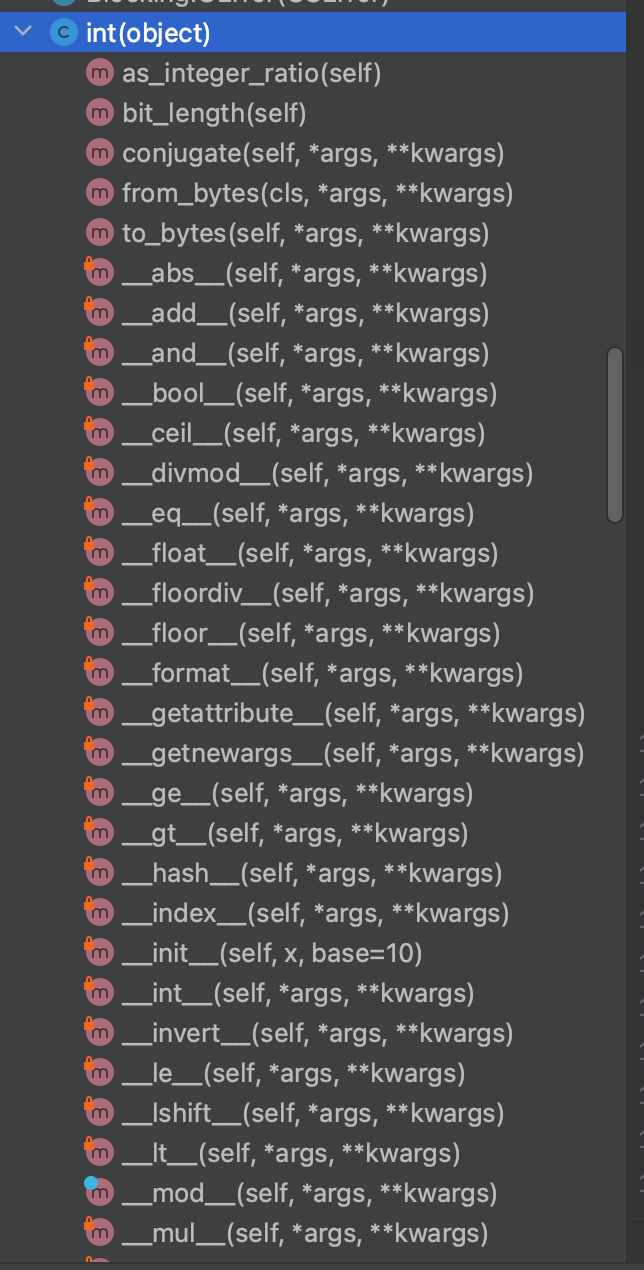
# 将字符串转换成int
a = "123"
print(type(a)) # <class 'str'>
b = int(a)
print(type(b)) # <class 'int'>
print(b) # 123
# 无法从字符串转成int的,会报错
a = "123a"
print(int(a))
# 将a以16进制的方式转成十进制,没看懂,TODO
a = "a"
v = int(a, base=16)
print(v)
# 数字的二进制至少用几位来表示
age = 1 # 01
print(age.bit_length()) # 1
age = 10 #
print(age.bit_length()) # 4
age = 100
print(age.bit_length()) # 7
字符串 str
str都有哪些功能呢?都在str里面,可以查看str的定义。
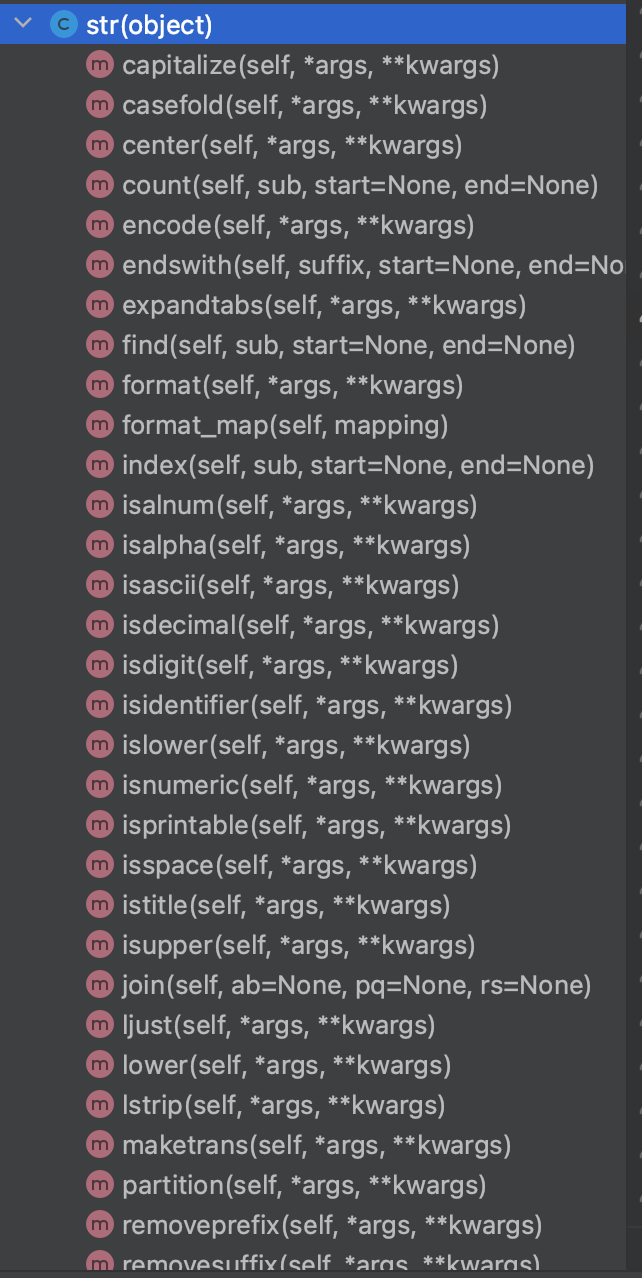
test = "alex"
print(test.capitalize()) # 首字母大写
print(test.upper()) # 全部大写
print("abcEFG".swapcase()) # 大小写转换, ABCefg
print("aLex".swapcase()) # 大小写转换,大写转成小写,小写转成大写。
print("Alex".islower()) # 判断是不是全部小写
print("Alex".lower().islower()) # 转变成小写
print("Alex".isupper()) # 判断是不是全部大写
print("Alex".upper()) # 转变成大写
# title 转换,转成首字母大写
# istitle判断是否首字母大写
test = "you are good"
print(test.istitle()) # False
print(test.title()) # You Are Good
print(test.title().istitle()) # True
test = "aLex"
print(test.casefold()) # 全部小写,但比lower强大,很多未知的也可以小写,比如阿尔法。
print(test.lower()) # 全部小写
print(test.center(20)) # 一共20个位置,alex放中间
print(test.center(20, "*")) # 一个20个位置,alex放中间,空白处放*,且第二个参数只能是一个字符
test = "alex alex"
# count(self, sub, start=None, end=None), 计算子序列在字符串中出现的次数,支持多字符,start和end表示寻找的起始位置
print(test.count('e'))
print(test.count('ex'))
print(test.count('ex', start=1)) # start从第几个位置开始找, 这个报错,不知道为什么,TODO
test = "alex"
# endswith(self, suffix, start=None, end=None)
print(test.endswith("a")) # 以什么结尾,返回布尔值
print(test.startswith("a")) # 以什么开始,返回布尔值
# find,从开始往后找,找到第一个后,获取其位置。
test = "alexalex"
print(test.find("ex"))
print(test.find("ex", 5, 7)) # 找不到,返回-1
print(test.find("ex", 5, 8)) # 找得到,开区间
# index,同find返回位置
print(test.index("ex"))
print(test.index("xx")) # find返回-1,index会抛出异常
# format & format_map,将字符串中的占位符替换为指定的值
print("I am {name}, age is {age}".format(name="alex", a=19))
# 另一种占位符方式
print("I am {0}, age is {1}".format("alex", 19))
print("I am {name}, age is {age}".format_map({"name": "alex", "a": 19}))
# isalnum,判断字符串中是否只包含字母和数字
test = "uaf890"
print(test.isalnum())
test = "uaf890_"
print(test.isalnum())
# expandtabs, 每6位进行截取处理,如果遇到\t,减去\t前面的字符位数,剩余就是\t的位数
test = "1234567\t89"
print(test.expandtabs(6)) # 1234567 89
# 有啥用呢
test = "username\temail\tpassword\t\nalex\talex@qq.com\t123\nalex\talex@qq.com\t123\nalex\talex@qq.com\t123\n"
print(test.expandtabs(20))
test = "asdf"
print(test.isalpha()) # 是否是字母,True
test = "123"
print(test.isdigit()) # 是否是数字,True
test = "②"
print(test.isdigit()) # 是否是数字,True
# isidentifier, 是不是合法标识符(包含字母、数字、下划线,非数字开头)
print("class".isidentifier()) # True
print("_123".isidentifier()) # True
# 是否是关键字判断
import keyword
print(keyword.iskeyword("class")) # True
print(keyword.iskeyword("def")) # True
print(keyword.iskeyword("xxx")) # False
# 判断是否数字
test = "二"
test = "②"
print(test.isdecimal()) # False,②以及中文都不支持
print(test.isdigit()) # False,②支持,中文不支持
print(test.isnumeric()) # True, 中文也支持,②也支持
test = "aaaa"
print(test.isprintable())
print("aaa\tbbb".isprintable()) # 字符串有不可显示字符,返回False
# 是否全部是空格,可以多个空格
print("abc".isspace())
print(" ".isspace())
print("".isspace()) # False
test = "锄禾日当午"
print("_".join(test)) # 锄_禾_日_当_午
print("alex".ljust(20, "*")) # 左边填充,用*填充,alex****************
print("alex".rjust(20, "*")) # 右边填充,用*填充,****************alex
print("alex".zfill(20)) # 默认用0在左边填充,0000000000000000alex
print(" alex ".lstrip()) # 去掉左侧的空格 \n \t \r
print(" alex ".rstrip()) # 去除右侧的空格
print(" alex ".strip()) # 去除两边的空格
print("\nalex ".lstrip())
print("xalex".lstrip("9lexxa8")) # 也可以指定具体的内容,去掉里面的所有匹配的子串,最多匹配, 结果:""
test1 = "测试一下替换字符"
test2 = "看看能不能生效啊"
m = str.maketrans(test1, test2) # 创建一个对应关系,逐一替换
origin_str = "测试一下替换字符,嗯"
new_str = origin_str.translate(m)
print(new_str) # 看看能不能生效啊,嗯
print("testvstevst".partition("v")) # 用v进行分割,分成三份,值包括v,('test', 'v', 'stevst')
print("testvstevst".rpartition("v")) # 分成三份,('testvste', 'v', 'st')
print("testvstevst".split("v")) # 全分了,['test', 'ste', 'st']
print("testvstevst".split("v", 1)) # 一次分割,值不包括v, ['test', 'stevst']
# 正则表达式是这partition和split的合集。
print("test1\ntest2\ntest3".splitlines()) # 按换行进行分割,['test1', 'test2', 'test3']
print("test1\ntest2\ntest3".splitlines(True)) # 按换行进行分割,参数表示是否保留换行符,['test1\n', 'test2\n', 'test3']
print("test".startswith("a")) # 判断是否以xx开始
print("test".endswith("a")) # 判断是否以xx结尾
# 索引,在其他数据类型也可以用
test = "abcdefg"
print(test[0]) # 下标方式获取字符元素, a
# 切片,在其他数据类型也可以用
print(test[0:1]) # 切片方式获取子字符串,右侧开区间,a
print(test[0:-1]) # -1表示最后一个,也是开区间,abcdef
print(test[0:]) # 获取全部,abcdefg
# 长度,在其他数据类型也可以用
test = "中国"
print(len(test)) # 2,在python2里面返回2 * 3(一个汉字3个字节),返回多少个字节。
# for 循环字符串,在其他数据类型也可以用
test = "中华人民共和国"
for i in test:
print(i)
# replace 替换
print("student is good1, good2, good3".replace("good", "best")) # student is best1, best2, best3
print("student is good1, good2, good3".replace("good", "best", 2)) # 替换第几个,student is best1, best2, good3
# 一旦创建,不可修改。一旦修改字符串,或者拼接字符串,都是生成一块新的内存。
name = "xiaoming" # 第一个内存块,存储xiaoming
age = "18" # 第二个内存块,存储18
info = name + age # # 第三个内存块,存储xiaoming18
print(info)
test = "小明"
for item in test:
print(item)
break
test = "小明"
for item in test:
continue
print(item)
# range 创建连续的数字
# 如果在python2.7里面,range会在内存中立即创建出来。
print(range(100)) # 输出range(0, 100):python3里面进行了优化,在内存里面还没有创建,节省内存。只有进行for循环的时候才进行逐个创建。
v = range(0, 100, 5) # 设置步长,创建非连续数字
作业
列表 list
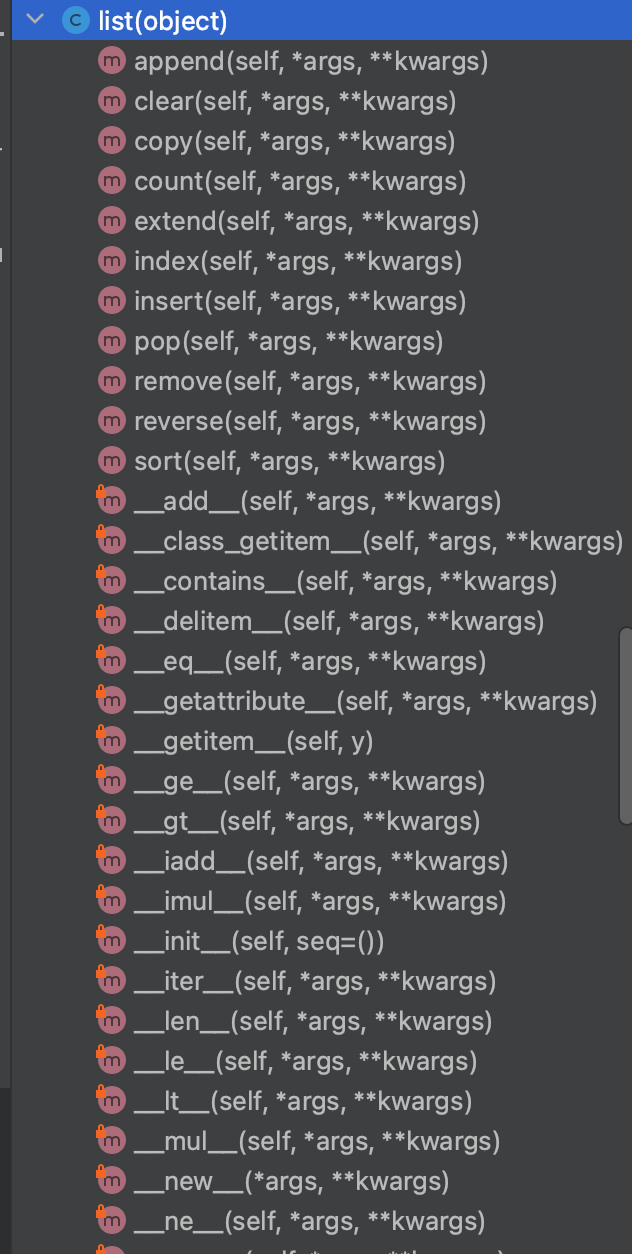
list_demo = [1, 2, 3, 4]
print(list_demo.index(2))
list # 列表类
li = [1, 12, "age", ["school", [10, 9], "telephone"], "alex"] # 通过list类创建一个对象li
# 列表中的元素可以是数字、字符串、列表、布尔值等学过的所有的都可以作为元素。
# ================深灰魔法================
# 索引
print(li[3])
# 切片
print(li[3:5])
# for、while 循环
for item in li:
print(item)
# 字符串不可以被修改,但list可以被修改
# list的内部实现是链表,因此元素是可以修改的。
# 索引修改元素
li[2] = "age_new"
print(li) # [1, 12, 'age_new', ['school', [10, 9], 'telephone'], 'alex']
# 索引删除元素
del li[3]
print(li) # [1, 12, 'age_new', 'alex']
# 切片修改元素
li[1:3] = [13, "age_new2"]
print(li) # [1, 13, 'age_new2', 'alex']
# 切片删除元素
del li[2:4] # [1, 13]
print(li)
# in 操作
print(13 in li)
# list嵌套取值
li = [1, 12, "age", ["school", [10, 9], "telephone"], "alex"]
print(li[3][1][0])
# 字符串转列表
s = "aaaxfsdfsfds"
list_s = list(s) # 字符串转列表,内部是使用for循环
# 列表转字符串
s = ""
li_s = [12, 34, "age", "alex"]
for value in li_s:
s += str(value)
print(s)
# 列表转字符串,如果list里面的元素都是str,可以直接使用join
list_s2 = ["age", "name", "alex"]
print(" ".join(list_s2))
# ================ list类提供的方法 ================
# append,添加元素
list1 = [1, 2, 3, 4]
list1.append(5)
print(list1) # [1, 2, 3, 4],也侧面说明了list可修改
# 清空list1
list1.clear()
print(list1)
# 浅拷贝
list1 = [1, 2, 3, 4]
v = list1.copy()
print(v) # [1, 2, 3, 4]
# 元素出现的个数
v = list1.count(1)
print(v) # 1
# 扩展原列表,参数是可迭代对象
list1.extend([4, 5, 6]) # Extend list by appending elements from the iterable
print(list1) # [1, 2, 3, 4, 4, 5, 6]
# 根据值找元素位置(只找第一个),也可以指定起始位置
print(list1.index(2))
# 在指定位置插入元素
list1.insert(0, 99)
print(list1) # [99, 1, 2, 3, 4, 4, 5, 6]
# 把最后一个元素删除,返回被删除的值
v = list1.pop()
print(v) # 6
print(list1) # [99, 1, 2, 3, 4, 4, 5]
# 删除某个索引位置的值,并返回被删除的值
v = list1.pop(1)
print(v) # 1
print(list1) # [99, 2, 3, 4, 4, 5]
# 删除元素
list1.remove(3)
list1.remove(4) # 只删除第一个
print(list1) # [99, 2, 4, 5]
# 将列表翻转
list1.reverse()
print(list1) # [5, 4, 2, 99]
# 排序,正向排序 & 反向排序
list1.sort()
print(list1) # [2, 4, 5, 99]
list1.sort(reverse=True)
print(list1) # [99, 5, 4, 2]
关于字符串和list的修改问题
v2 = "abc"
v2.replace("a", "d") # v2指向了另一个字符串,字符串不可修改
print(v2)
li = [1, 2, 3]
li[1] = 4 # list元素可修改
print(li)
str1 = "abc"
str1[0] = "d" # str元素不可修改,报错,str 作为一个整体不可修改。
元组 tuple
list
li = [11,24,556,4]
list是有序的,内部结构是链表,因此每次输出都是相同的,元素的顺序不会改变。但list是可变的。
tuple
tu = (11,24,556,4,) # 建议:元组最后加个逗号,表示这是元组。
元组是list的二次加工,元组是不可变的。
元组的元素可以是任意。元组的元素也可以是元组
元组取值:
1. 索引
2. 切片
# 不可修改:
# 1. 不支持del\不支持append\不能修改元素值。
# 可for循环,是可迭代对象。
tu = (11, 24, 556, 4,)
for item in tu:
print(item)
# 字符串、list、tuple都是可迭代对象,因此他们之间可以内部通过for循环原理进行转换
s = "aaaaaa"
li = ["bbb", "ccc"]
tu = ("bbb", "ccc")
print(tuple(s)) # ('a', 'a', 'a', 'a', 'a', 'a')
print(tuple(li)) # ('bbb', 'ccc')
print(list(tu)) # ['bbb', 'ccc']
# 若元组的元素全部是str,也可以通过join转换成字符串
print("_".join(tu)) # bbb_ccc
# list的extend内部实现原理也是循环,tuple也可以循环,因此也可以作为extend传参
s = "aaaaaa"
li = ["bbb", "ccc"]
li.extend(s) # ['bbb', 'ccc', 'a', 'a', 'a', 'a', 'a', 'a']
print(li)
li.extend([11, 22, 33]) # ['bbb', 'ccc', 'a', 'a', 'a', 'a', 'a', 'a', 11, 22, 33]
print(li)
li.extend(("bbb", "ccc",)) # ['bbb', 'ccc', 'a', 'a', 'a', 'a', 'a', 'a', 11, 22, 33, 'bbb', 'ccc']
print(li)
tu = (11, 22, 33, (44, 55,), ["aa", "bb"], True,)
print(tu[0])
# tu[0] = 123 # 报错,元组一级元素不允许修改
tu[4][0] = "cc" # 元组的元素list的元素可以修改
print(tu) # (11, 22, 33, (44, 55), ['cc', 'bb'], True)
# ===== tuple 类的方法 ======
class tuple(object):
"""
Built-in immutable sequence.
If no argument is given, the constructor returns an empty tuple.
If iterable is specified the tuple is initialized from iterable's items.
If the argument is a tuple, the return value is the same object.
"""
def count(self, *args, **kwargs): # real signature unknown
""" Return number of occurrences of value. """
pass
def index(self, *args, **kwargs): # real signature unknown
"""
Return first index of value.
Raises ValueError if the value is not present.
"""
pass
# 仅仅两个
tu = (11, 22, 33, (44, 55,), ["aa", "bb"], True,)
print(tu.index(33)) # 获取某个值的索引,获取第一个,也可以指定起始位置
print(tu.count(22)) # 获取某个值出现的次数
字典 dict
1. value可以是任意类型。想嵌套多少层都是可以的。
2. key:数字、字符串、元组、布尔值可以,字典不可以,list不可以。notes:true和1 这两个key是重复的。
字典保存的时候,是hash表,list、字典不可以进行hash。
3. 字典是无序的,每次输出结果都不一样。
4. list和元组,是python自动给了个计数器,可以通过索引取值。字典是根据我们已经定义好的索引,通过key取值。
5. 删除键值对
del info["k1"]
6. for循环
dict_demo = {
"k1": "abc",
2: "efg",
True: 123,
"k2": {
"aa": 1,
"bb": 2,
"cc": [1, 2, 3],
},
"k3": (1, 2, 3, 4,),
(1, 2, 3): 10,
}
# 默认输出key
for item in dict_demo:
print(item)
# 输出 key
for key in dict_demo.keys():
print(key)
# 输出 value
for value in dict_demo.values():
print(value)
# 输出key和value
for key in dict_demo.keys():
print(key)
print(dict_demo[key])
# 输出key和value
for key, value in dict_demo.items():
print(key)
print(value)
############### dict类的方法 ###############
# 1. 根据序列创建字典,并指定value,这个是静态方法,dict类直接调用
demo = dict.fromkeys([1, 2, 3])
print(demo) # {1: None, 2: None, 3: None}
demo = dict.fromkeys([1, 2, 3], "this is value")
print(demo) # {1: 'this is value', 2: 'this is value', 3: 'this is value'}
# 2. get,即使key不存在,也不报错,也可以指定默认返回值。
demo_dict = {"abc": 1, "efg": 2}
# print(demo_dict["ddd"]) # 报错
print(demo_dict.get("ddd", 3))
# 3. keys、items
# 4. pop,将数据移除,同时返回被移除的key的value。如果key不存在,可以指定一个默认的值。
demo_dict = {"abc": 1, "efg": 2}
v = demo_dict.pop("abc")
print(v) # 1
v = demo_dict.pop("ddd", 3)
print(v) # 3
# 5. popitem,随机从dict删除一个键值对,返回被删除的键值对
demo_dict = {"abc": 1, "efg": 2}
k, v = demo_dict.popitem()
print(demo_dict, k, v) # {'abc': 1} efg 2
# 6. setdefault设置值;如果key存在,不设置值,返回当前值;如果key不存在,设置该key的值为指定的值。
demo_dict = {"abc": 1, "efg": 2}
v = demo_dict.setdefault("abc", 3)
print(demo_dict) # {'abc': 1, 'efg': 2}
print(v) # 1
v = demo_dict.setdefault("ddd", 3)
print(demo_dict) # {'abc': 1, 'efg': 2, 'ddd': 3}
print(v) # 3
# 7. update, 更新key的值,有这个key,就更新对应的值;没有这个key,就新增key-value键值对。
demo_dict = {"abc": 1, "efg": 2}
demo_dict.update({"abc": 3, "ddd": 4})
print(demo_dict) # {'abc': 3, 'efg': 2, 'ddd': 4}
# 也可以这么使用。其实内部很简单,内部再进行一个数据格式的转换就可以了。
demo_dict = {"abc": 1, "efg": 2}
demo_dict.update(abc=3, ddd=4) # **kwargs
print(demo_dict) # {'abc': 3, 'efg': 2, 'ddd': 4}
# clear 清空
# copy 浅拷贝
布尔值 bool
print(bool("abc"))
# 哪些转变成布尔值是false。
print(bool([]))
print(bool(None))
print(bool(""))
print(bool({}))
print(bool(()))
print(bool(0))
可变与不可变
# 字符串不可变
name = "alex"
print(id(name)) # 140580990573936
name = "alex2"
print(id(name)) # 140580990562928
# 数字不可变
age = 18
print(id(age)) # 140581527415632
age = 28
print(id(age)) # 140581527415952
# list可变
li = [1, 2, 3]
print(id(li)) # 140581529993152
li[2] = 333
print(id(li)) # 140581529993152
# 元组不可变
# dict可变
dict_demo = {"abc": 1, "efg": 2}
print(id(dict_demo)) # 140581259199424
dict_demo["abc"] = 3
dict_demo["ddd"] = 4
print(id(dict_demo)) # 140581259199424
集合
定义:由不同元素组成的集合,集合中是一组无序排列的可hash值,可以作为字典的key
特性:1.集合的目的是将不同的值存放到一起,不同的集合间用来做关系运算,无需纠结于集合中单个值
- 无序
- 不同元素组成
- 集合中元素必须是不可变类型
# 集合元素是唯一的,不重复的
a = {1, 10, 9, 5, 5, 5, 5}
print(type(a))
print(a)
# 元素是无序的,因此无法通过下标去访问元素
demo_s = {"alex", "name", 19, (1, 2, 3)}
for demo in demo_s:
print(demo) # 每次输出顺序不一样
# 集合中元素必须是不可变类型,可hash类型
demo_s = {"alex", "name", 19, (1, 2, 3), [1, 2, 3]}
# 报错如下
Traceback (most recent call last):
File "/Users/chengqianli/PycharmProjects/chengqianli/StarRocksTest/tes.py", line 12, in <module>
demo_s = {"alex", "name", 19, (1, 2, 3), [1,2,3]}
TypeError: unhashable type: 'list'
# 可迭代对象转成set,内部原理是for循环,遇到重复元素去掉。
s = set("hello")
print(s) # {'l', 'o', 'h', 'e'}
s = set([1, 2, 3, "alex", "alex"])
print(s) # {'alex', 1, 2, 3}
s = set((1, 2, 3, "alex", "alex",))
print(s) # {1, 2, 3, 'alex'}
# ==================== set的方法 =========================
# 添加元素,如果元素重复会忽略
s = {"alex", "name", 19, (1, 2, 3), 3, "a"}
s.add(3)
s.add('3')
print(s) # {3, 'name', 19, 'alex', 'a', '3', (1, 2, 3)}
# 清空
v = s.clear()
print(v) # None
print(s) # set()
# copy拷贝
s = {"alex", "name", 19, (1, 2, 3), 3, "a"}
s1 = s.copy()
print(s1) # {3, 'name', 19, 'alex', 'a', (1, 2, 3)}
# 集合是无序的,pop时是随机的
s.pop()
print(s) # {'name', 19, 'alex', 'a', (1, 2, 3)}
# remove,可指定删除某个值,但删除不存在的会报错
s = {"alex", "name", 19, (1, 2, 3), 3, "a"}
v = s.remove(3)
print(v) # None
print(s) # {19, 'alex', 'a', (1, 2, 3), 'name'}
s.remove(333) # 删除不存在的,报错
# discard,删除不存在元素不报错。
s.discard(3)
s.discard(333) # 删除不存在元素不报错。
# 很丑陋的实现方式,集合有现有的方法可以实现
linux_l = ["lcg", "ming", "hong"]
python_l = ["ming", "hong", "zhang"]
python_linux_l = []
for python in python_l:
if python in linux_l:
python_linux_l.append(python)
# 交集、并集、差集
linux_s = set(linux_l)
python_s = set(python_l)
print(linux_s, python_s) # {'lcg', 'ming', 'hong'} {'zhang', 'ming', 'hong'}
print(linux_s.intersection(python_s)) # 求交集, {'ming', 'hong'}
print(linux_s & python_s) # 求交集,{'ming', 'hong'}
print(linux_s.union(python_s)) # 求并集, {'lcg', 'zhang', 'hong', 'ming'}
print(linux_s | python_s) # 求并集, {'lcg', 'zhang', 'hong', 'ming'}
print(linux_s.difference(python_s)) # 求差集,{'lcg'}
print(linux_s - python_s) # 求差集,存在于左边,不存在于右边,{'lcg'}
print(python_s.difference(linux_s)),{'zhang'}
print(python_s - linux_s) # 求差集,存在于左边,不存在于右边,{'zhang'}
# -
# ^
# &
# |
# > < >= <=
linux_l = ["lcg", "ming", "hong"]
python_l = ["ming", "hong", "zhang"]
linux_s = set(linux_l)
python_s = set(python_l)
# 交叉补集:合并,然后去掉公共部分
print(linux_s.symmetric_difference(python_s)) # 交叉补集
print(linux_s ^ python_s)
# 求差集,然后更新到linux_s中
print(linux_s.difference_update(python_s))
# 相当于
linux_s = set(linux_l)
python_s = set(python_l)
linux_s = linux_s - python_s
# 求交集,然后更新到linux_s中
print(linux_s.intersection_update(python_s))
# 相当于
linux_s = set(linux_l)
python_s = set(python_l)
linux_s = linux_s & python_s
# 求交叉补集,然后更新到linux_s中
print(linux_s.symmetric_difference_update(python_s))
# 如果两个set没有交集,返回false,有交集,返回true
print(linux_s.isdisjoint(python_s))
# issubset,判断s1是s2的子集
s1 = {1, 2}
s2 = {1, 2, 3}
print(s1.issubset(s2))
# issuperset,判断s1是s2的父集
print(s1.issuperset(s2))
print(s1 >= s2)
# update,更新多个值
s1 = {1, 2}
s2 = {3, 4, 5}
s1.update(s2)
print(s1)
s1.update((5, 6)) # 也可以传入元组,可迭代对象
s1.update((7, 8))
# 集合可增加,可删除,是可变类型
# frozenset 不可变集合
s = frozenset("hello")
print(s)
# 去重,再转变为list,但是顺序可能会发生变化
names = ["alex", "alex", "wpq"]
li = set(list(s))
字符串格式化
Python的字符串格式化有两种方式: 百分号方式、format方式
百分号的方式相对来说比较老,而format方式则是比较先进的方式,企图替换古老的方式,目前两者并存
1. 百分号方式
%[(name)][flags][width].[precision]typecode
(name) 可选,用于选择指定的key
flags 可选,可供选择的值有:
- + 右对齐;正数前加正好,负数前加负号;
- - 左对齐;正数前无符号,负数前加负号;
- 空格 右对齐;正数前加空格,负数前加负号;
- 0 右对齐;正数前无符号,负数前加负号;用0填充空白处
width 可选,占有宽度
.precision 可选,小数点后保留的位数
typecode 必选
s,获取传入对象的__str__方法的返回值,并将其格式化到指定位置
r,获取传入对象的__repr__方法的返回值,并将其格式化到指定位置
c,整数:将数字转换成其unicode对应的值,10进制范围为 0 <= i <= 1114111(py27则只支持0-255);字符:将字符添加到指定位置
o,将整数转换成 八 进制表示,并将其格式化到指定位置
x,将整数转换成十六进制表示,并将其格式化到指定位置
d,将整数、浮点数转换成 十 进制表示,并将其格式化到指定位置
e,将整数、浮点数转换成科学计数法,并将其格式化到指定位置(小写e)
E,将整数、浮点数转换成科学计数法,并将其格式化到指定位置(大写E)
f, 将整数、浮点数转换成浮点数表示,并将其格式化到指定位置(默认保留小数点后6位)
F,同上
g,自动调整将整数、浮点数转换成 浮点型或科学计数法表示(超过6位数用科学计数法),并将其格式化到指定位置(如果是科学计数则是e;)
G,自动调整将整数、浮点数转换成 浮点型或科学计数法表示(超过6位数用科学计数法),并将其格式化到指定位置(如果是科学计数则是E;)
%,当字符串中存在格式化标志时,需要用 %%表示一个百分号
注:Python中百分号格式化是不存在自动将整数转换成二进制表示的方式
tpl = "i am %s" % "alex"
tpl = "i am %s age %d" % ("alex", 18)
tpl = "i am %(name)s age %(age)d" % {"name": "alex", "age": 18} # 用了key
tpl = "percent %.2f" % 99.97623
# 打印浮点数,保留2位
tpl = "i am %(pp).2f" % {"pp": 123.425556, }
# 打印百分号
tpl = "i am %.2f %%" % {"pp": 123.425556, }
# 左对齐
tpl = "I am %(name)-10s, I am 18" % {"name": "alex"}
print(tpl) # I am alex , I am 18
# 右对齐
tpl = "I am %(name)+10s, I am 18" % {"name": "alex"}
print(tpl) # I am alex, I am 18
# 加颜色
tpl = "I am \033[45;1m%(name)+10s\033[0m, I am 18" % {"name": "alex"}
print(tpl)
# 分隔符拼接
print("root", "12345", sep=";")
# 等同于
print("root" + ";" + "123456")
2. format
[[fill]align][sign][#][0][width][,][.precision][type]
fill 【可选】空白处填充的字符
align 【可选】对齐方式(需配合width使用)
- <,内容左对齐
- >,内容右对齐(默认)
- =,内容右对齐,将符号放置在填充字符的左侧,且只对数字类型有效。 即使:符号+填充物+数字
- ^,内容居中
sign 【可选】有无符号数字
- +,正号加正,负号加负;
- -,正号不变,负号加负;
- 空格 ,正号空格,负号加负;
# 【可选】对于二进制、八进制、十六进制,如果加上#,会显示 0b/0o/0x,否则不显示
, 【可选】为数字添加分隔符,如:1,000,000
width 【可选】格式化位所占宽度
.precision 【可选】小数位保留精度
type 【可选】格式化类型
- 传入” 字符串类型 “的参数
- s,格式化字符串类型数据
- 空白,未指定类型,则默认是None,同s
- 传入“ 整数类型 ”的参数
- b,将10进制整数自动转换成2进制表示然后格式化
- c,将10进制整数自动转换为其对应的unicode字符
- d,十进制整数
- o,将10进制整数自动转换成8进制表示然后格式化;
- x,将10进制整数自动转换成16进制表示然后格式化(小写x)
- X,将10进制整数自动转换成16进制表示然后格式化(大写X)
- 传入“ 浮点型或小数类型 ”的参数
- e, 转换为科学计数法(小写e)表示,然后格式化;
- E, 转换为科学计数法(大写E)表示,然后格式化;
- f , 转换为浮点型(默认小数点后保留6位)表示,然后格式化;
- F, 转换为浮点型(默认小数点后保留6位)表示,然后格式化;
- g, 自动在e和f中切换
- G, 自动在E和F中切换
- %,显示百分比(默认显示小数点后6位)
常用格式化:
tpl = "i am {}, age {}, {}".format("seven", 18, 'alex')
tpl = "i am {}, age {}, {}".format(*["seven", 18, 'alex'])
tpl = "i am {0}, age {1}, really {0}".format("seven", 18)
tpl = "i am {0}, age {1}, really {0}".format(*["seven", 18])
tpl = "i am {name}, age {age}, really {name}".format(name="seven", age=18)
tpl = "i am {name}, age {age}, really {name}".format(**{"name": "seven", "age": 18})
tpl = "i am {0[0]}, age {0[1]}, really {0[2]}".format([1, 2, 3], [11, 22, 33])
tpl = "i am {:s}, age {:d}, money {:f}".format("seven", 18, 88888.1)
tpl = "i am {:s}, age {:d}".format(*["seven", 18])
tpl = "i am {name:s}, age {age:d}".format(name="seven", age=18)
tpl = "i am {name:s}, age {age:d}".format(**{"name": "seven", "age": 18})
tpl = "numbers: {:b},{:o},{:d},{:x},{:X}, {:%}".format(15, 15, 15, 15, 15, 15.87623, 2)
tpl = "numbers: {:b},{:o},{:d},{:x},{:X}, {:%}".format(15, 15, 15, 15, 15, 15.87623, 2)
tpl = "numbers: {0:b},{0:o},{0:d},{0:x},{0:X}, {0:%}".format(15)
tpl = "numbers: {num:b},{num:o},{num:d},{num:x},{num:X}, {num:%}".format(num=15)
更多格式化操作:https://docs.python.org/3/library/string.html
函数
初中数学函数定义:一般的,在一个变化过程中,如果有两个变量x和y,并且对于x的每一个确定的值,y都有唯一确定的值与其对应,那么我们就把x称为自变量,把y称为因变量,y是x的函数。自变量x的取值范围叫做这个函数的定义域
例如y=2*x。
python中函数定义:函数是逻辑结构化和过程化的一种编程方法。
def test(x):
"The function definitions"
x+=1
return x
def:定义函数的关键字
test:函数名
():内可定义形参
"":文档描述(非必要,但是强烈建议为你的函数添加描述信息)
x+=1:泛指代码块或程序处理逻辑
return:定义返回值调用运行:可以带参数也可以不带函数名()
1.编程语言中的函数与数学意义的函数是截然不同的俩个概念,编程语言中的函数是通过一个函数名封装好一串用来完成某一特定功能的逻辑,数学定义的函数就是一个等式,等式在传入因变量值x不同会得到一个结果y,这一点与编程语言中类似(也是传入一个参数,得到一个返回值),不同的是数学意义的函数,传入值相同,得到的结果必然相同且没有任何变量的修改(不修改状态),而编程语言中的函数传入的参数相同返回值可不一定相同且可以修改其他的全局变量值(因为一个函数a的执行可能依赖于另外一个函数b的结果,b可能得到不同结果,那即便是你给a传入相同的参数,那么a得到的结果也肯定不同)
2.函数式编程就是:先定义一个数学函数(数学建模),然后按照这个数学模型用编程语言去实现它。至于具体如何实现和这么做的好处,且看后续的函数式编程。
为何使用函数
使用函数的好处:
- 代码重用
- 保持一致性,易维护
- 可扩展性
函数和过程
过程定义:过程就是简单特殊没有返回值的函数
但当一个函数/过程没有使用return显示的定义返回值时,python解释器会隐式的返回None。
所以在python中即便是过程也可以算作函数。
def test01():
pass
def test02():
return 0
def test03():
return 0, 10, 'hello', ['alex', 'lb'], {'WuDaLang': 'lb'}
t1 = test01()
t2 = test02()
t3 = test03()
print('from test01 return is [%s]: ' % type(t1), t1) # from test01 return is [<class 'NoneType'>]: None
print('from test02 return is [%s]: ' % type(t2), t2) # from test02 return is [<class 'int'>]: 0
print('from test03 return is [%s]: ' % type(t3), t3) # from test02 return is [<class 'int'>]: 0
总结:
- 返回值数=0:返回None
- 返回值数=1:返回object
- 返回值数>1:返回tuple
函数参数
- 形参变量只有在被调用时才分配内存单元,在调用结束时,即刻释放所分配的内存单元。因此,形参只在函数内部有效。函数调用结束返回主调用函数后则不能再使用该形参变量
- 实参可以是常量、变量、表达式、函数等,无论实参是何种类型的量,在进行函数调用时,它们都必须有确定的值,以便把这些值传送给形参。因此应预先用赋值,输入等办法使参数获得确定值。
def cal(x, y): # x,y形参
res = x ** y
print(a)
print(b)
return res
# print(x, y) # 报错,函数结束,xy已经不在内存了
a = 1
b = 2
c = cal(a, b) # a,b 实参
print(c)
- 位置参数和关键字(标准调用:实参与形参位置一一对应;关键字调用:位置无需固定)
def test_func(x, y, z):
print(x, y, z)
test_func(1, 2, 3) # 1 2 3,实参与形参位置一一对应
test_func(z=11, x=22, y=33) # 22 33 11,关键字调用:位置无需固定
test_func(11, y=22, 33) # 报错,位置参数一定在传参的右边
test_func(11, 22, z=33)
test_func(11, y=22, z=33)
- 默认参数
def handle(x, type="mysql"):
print(x, type)
handle("hello") # hello mysql
handle("hello", "sqlite") # hello sqlite
handle("hello", type="sqlite") # hello sqlite
- 参数组-*args
# 非固定参数的场景
def test(x, y, *args):
# 接受剩余的所有参数
print(x, y, args)
test(1, 2, 3, 4, 5, 6) # 1 2 (3, 4, 5, 6)
test(1, 2) # 1 2 ()
test(1, 2, [3, 4, 5, 6]) # 1 2 ([3, 4, 5, 6],) 把列表也当成一个整体元素
test(1, 2, {"name": "alex"}) # 1 2 ({'name': 'alex'},) # 把dict也当成一个整体元素
- 如果想传的是列表,args也能得元组呢?
def test(x, y, *args):
# 接受剩余的所有参数
print(x, y, args)
# 当你有一个列表(或元组),并且想要将这个序列中的所有元素作为独立的参数传递给函数时,可以在序列前加上星号。这被称为参数解包。
args = [1, 2, 3]
print(*args) # 等价于 print(1, 2, 3)
def add(a, b):
return a + b
numbers = [1, 2]
result = add(*numbers) # 这会将numbers解包,传递1作为a,2作为b
print(result) # 输出 3
# ------------------
test(1, *[1, 2, 3]) # 1 1 (2, 3)
test(1, *(1, 2, 3)) # 1 1 (2, 3)
- 参数组-**kwargs
def test(x, y, *args):
# 接受剩余的所有参数
print(x, y, args)
# test(1, y=2, z=3) # 报错
# 一个*是位置参数,处理成列表
# 关键字参数需要用**
def test2(x, y, **kwargs):
print(x, y, kwargs)
test2(1, 2, a=1, b=2) # 1 2 {'a': 1, 'b': 2}
- 参数组-*args和**kwargs
def test(x, y, *args, **kwargs):
print(x, y, args, kwargs)
test(1, 2, 3, 5, 6, a=1, b=2) # 1 2 (3, 5, 6) {'a': 1, 'b': 2}
test(1, 2, *[1, 2, 3], **{"a": 1, "b": 2}) # 1 2 (1, 2, 3) {'a': 1, 'b': 2}, 相当于解包
全局变量与局部变量
在子程序中定义的变量称为局部变量,在程序的一开始定义的变量称为全局变量。
全局变量作用域是整个程序,局部变量作用域是定义该变量的子程序。
当全局变量与局部变量同名时:
- 在定义局部变量的子程序内,局部变量起作用;
- 在其它地方全局变量起作用。
name = "global"
list_demo = ["jack", "mary"]
def print_name1():
print(name) # 全局变量
def print_name2():
name = "session" # 定义一个局部变量
print(name) # 局部变量
def print_name3():
global name # 声明使用全局变量
name = "global2" # 对全局变量进行修改
print(name) # 全局变量
print_name1() # global
print_name2() # session
print_name3() # global2
def print_list1():
print(list_demo)
def print_list2():
list_demo = "session_abc" # 这里没有生命global,因此定义了一个新的局部变量。
print(list_demo)
def print_list3():
list_demo.append("ella") # 对于可变变量的一些方法使用,即使这里没有生命global,操作的也是全局变量。
print(list_demo)
def print_list4():
global list_demo
list_demo = "global_abc"
print(list_demo)
print_list1() # ['jack', 'mary']
print_list2() # session_abc
print_list3() # ['jack', 'mary', 'ella']
print_list4() # global_abc
总结:
- 如果没有声明局部变量,使用全局变量;如果声明了局部变量,使用局部变量
- 如果在函数内要对全局变量进行重新赋值,需要声明global,表示要对全局变量进行修改,而不是要定义一个局部变量
- 如果全局变量是可变类型,可以在函数直接对全局变量进行内容的变更(调用对象的方法),而不需要声明global。
嵌套函数
# 函数嵌套的全局变量和局部变量
# 可以把每个函数想象成一个箱子,箱子嵌套箱子,如果箱子里有这个变量的新定义(也就是局部变量),那就用这个局部变量。
# 如果箱子里没有这个变量的新定义,那就去找箱子外面的全局变量。
name = "康熙"
def test1():
print(name) # 康熙
def test2():
name = "雍正"
print(name) # 雍正,这个箱子里重新定义了一个局部变量,使用局部变量
def test3():
name = "乾隆"
print(name) # 这个子箱子里重新定义了一个局部变量,使用局部变量
test3()
print(name)
test2()
print(name) # 康熙
test1()
另一种场景
name = "康熙"
def test1():
print(name) # 康熙
def test2():
name = "雍正"
print(name) # 雍正,这个箱子里重新定义了一个局部变量,使用局部变量
def test3():
global name
name = "乾隆"
print(name) # 这个箱子说,我不想用=重新定义局部变量,我想用=给全局变量修改值。那就是用global,这里操作的就是全局变量了。
test3()
print(name) # 这个是test2箱子里的局部变量。test2没说要用全局变量。
test2()
print(name) # 康熙
test1()
风湿理论(函数即变量)
# 将函数的代码当成普通的字符串,放到内存中,foo指向它
def foo():
print("from foo")
bar()
# 将函数的代码当成普通的字符串,放到内存中,bar指向它
def bar():
print("from bar")
foo() # 执行不报错:找foo的代码进行执行。运行bar的时候,通过bar去找指定的代码运行。因此不报错。
def foo():
print("from foo")
bar()
foo() # 执行报错:执行foo的代码进行执行,运行bar的时候,此时还没有bar的指向代码
def bar():
print("from bar")
递归
古之欲明明德于天下者,先治其国;欲治其国者,先齐其家;欲齐其家者,先修其身;欲修其身者,先正其心;欲正其心者,先诚其意;欲诚其意者,先致其知,致知在格物。物格而后知至,知至而后意诚,意诚而后心正,心正而后身修,身修而后家齐,家齐而后国治,国治而后天下平。
在函数内部,可以调用其他函数。如果在调用一个函数的过程中直接或间接调用自身本身
def calc(n):
print(n)
if int(n / 2) == 0:
return n
return calc(int(n / 2))
calc(10)
输出:
10
5
2
1
递归特性:
- 必须有一个明确的结束条件
- 每次进入更深一层递归时,问题规模相比上次递归都应有所减少
- 递归效率不高,递归层次过多会导致栈溢出(在计算机中,函数调用是通过栈(stack)这种数据结构实现的,每当进入一个函数调用,栈就会加一层栈帧,每当函数返回,栈就会减一层栈帧。由于栈的大小不是无限的,所以,递归调用的次数过多,会导致栈溢出)
递归问路demo理解递归
def ask_way(person_list):
print('-' * 60)
if len(person_list) == 0:
return '没人知道'
person = person_list.pop(0)
# if person == 'linhaifeng':
# return '%s说:我知道,老男孩就在沙河汇德商厦,下地铁就是' % person
print('hi 美男[%s],敢问路在何方' % person)
print('%s回答道:我不知道,但念你慧眼识猪,你等着,我帮你问问%s...' % (person, person_list))
time.sleep(2)
res = ask_way(person_list)
# print('%s问的结果是: %res' %(person,res))
return res
res = ask_way(person_list)
print(res)
堆栈扫盲http://www.cnblogs.com/lln7777/archive/2012/03/14/2396164.html
尾递归优化:优化递归的效率
