Python-爬虫基础九-urllib下载资源、urllib 请求对象的定制
1. urllib下载资源
可以将爬取到的数据下载到本地,例如视频、音频、图片等
下载的方法是urllib.request.urlretrieve(url,fileName),retrieve是取回的意思
- 参数url表示的是数据的url地址
- 参数fileName表示的是保存到本地的文件名称
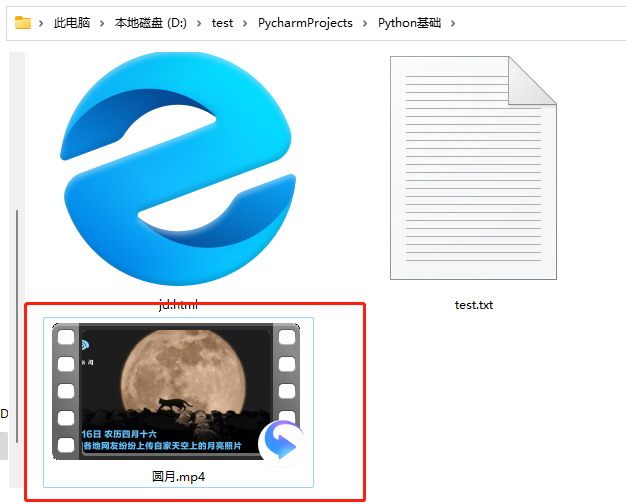
①、爬取网页
import urllib.request
# 下载网页 京东
url_page = 'https://www.jd.com/'
# url代表的是下载的路径 filename文件的名字
urllib.request.urlretrieve(url_page,'jd.html')
默认下载到当前项目文件夹
运行jd.html结果: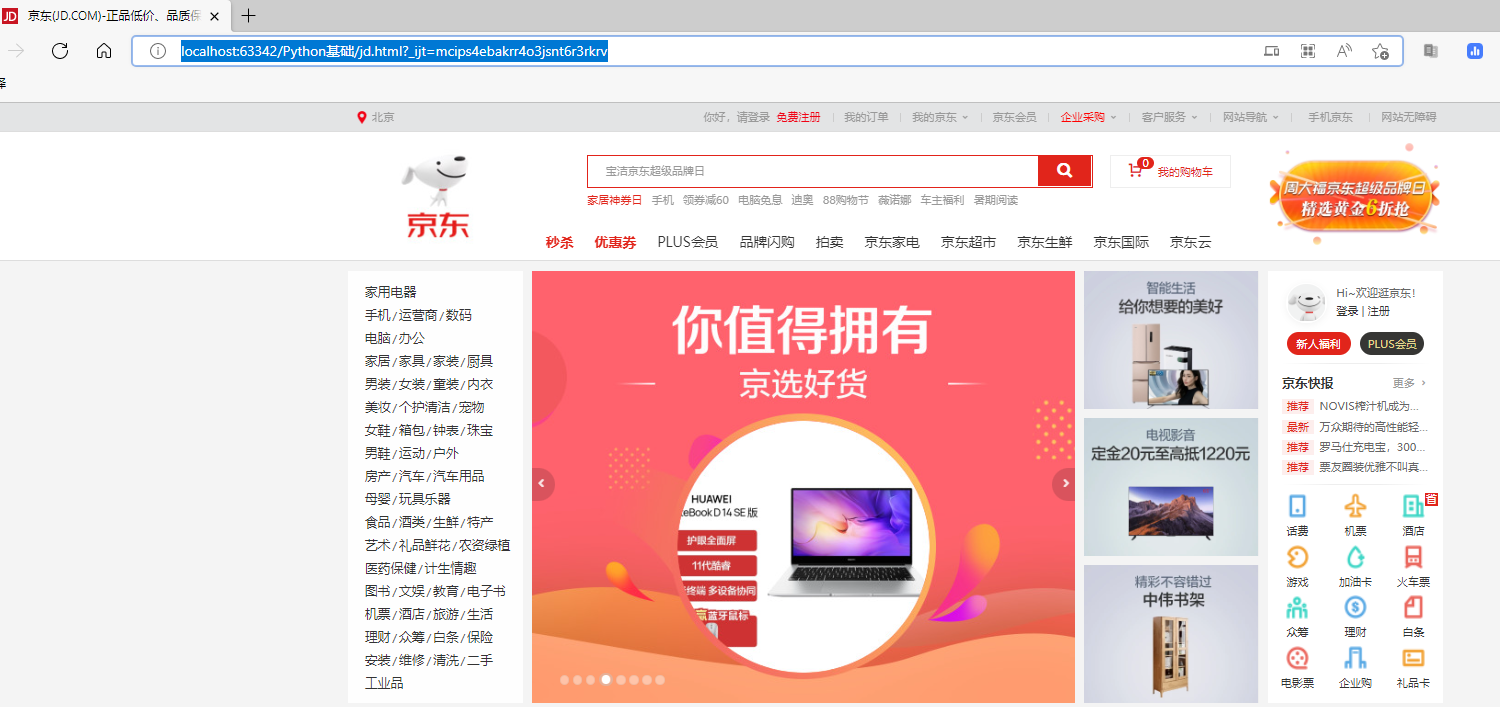
②、下载图片
在网页找一张图片,复制图片地址粘贴到代码里
import urllib.request # 下载图片 url_img = 'https://img11.360buyimg.com/babel/s320x320_jfs/t1/191498/27/24162/96568/627e0850E48735562/5f38da213d429d9b.jpg!cc_320x320.webp' urllib.request.urlretrieve(url=url_img, filename='3060.jpg')

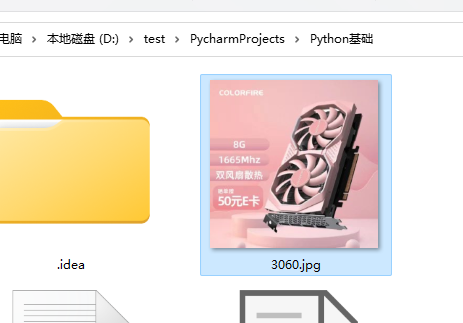
③、下载视频
如果网页无法直接复制视频,可以按F12进入开发者模式,选择元素,鼠标点击到视频,右侧灰色src中就是视频地址
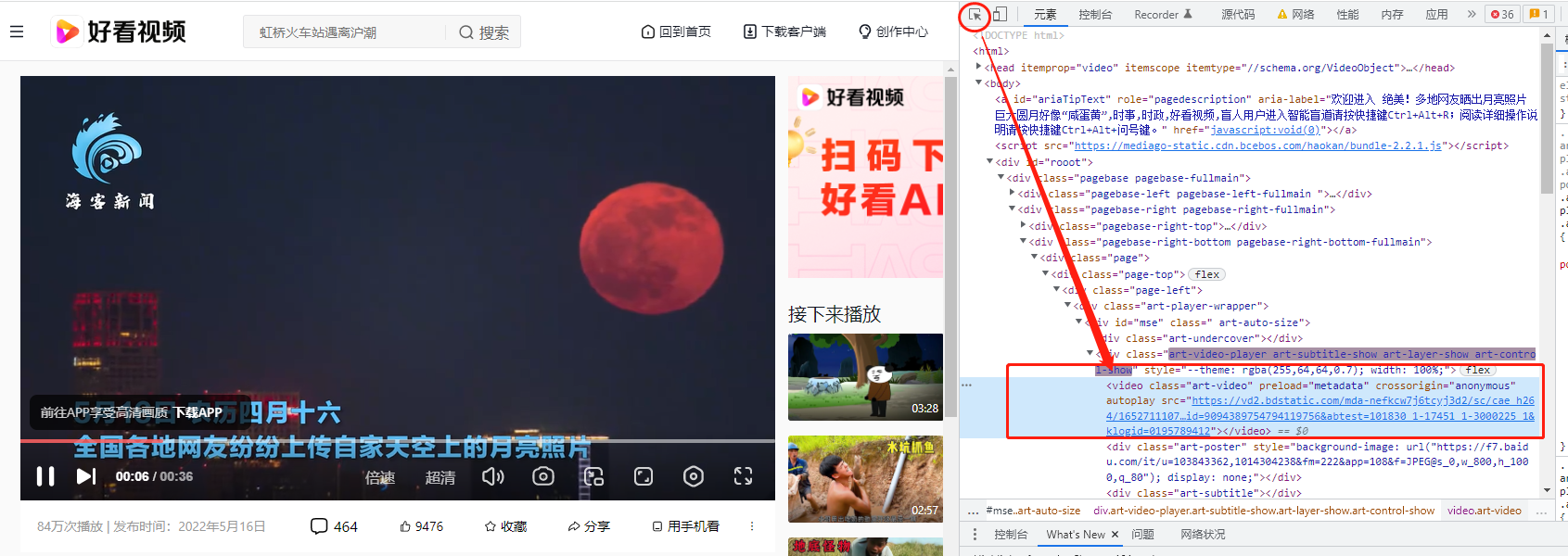
import urllib.request # 下载视频 url_video = 'https://vd2.bdstatic.com/mda-nefkcw7j6tcyj3d2/sc/cae_h264/1652711107788893391/mda-nefkcw7j6tcyj3d2.mp4?v_from_s=hkapp-haokan-nanjing&auth_key=1652715195-0-0-c40f2fec27593bd750198ba84d34f2d5&bcevod_channel=searchbox_feed&pd=1&cd=0&pt=3&logid=0195789412&vid=9094389754794119756&abtest=101830_1-17451_1-3000225_1&klogid=0195789412' urllib.request.urlretrieve(url_video, '圆月.mp4')
2. url完整组成
UA介绍:User Agent中文名为用户代理,简称 UA,它是一个特殊字符串头,使得服务器能够识别客户使用的操作系统 及版本、CPU 类型、浏览器及版本。浏览器内核、浏览器渲染引擎、浏览器语言、浏览器插件等
url 的组成:

- 协议 通信协议(scheme)
- 协议部分为“http:”,这代表网页使用的是HTTP协议。在Internet中可以使用多种协议,如HTTP,FTP等等本例中使用的是HTTP协议。在"HTTP"后面的“//”为分隔符‘
- HTTP协议和HTTPS的区别:HTTPS更加安全
- HTTP协议:HTTP协议也就是超文本传输协议,是一种使用明文数据传输的网络协议。一直以来HTTP协议都是最主流的网页协议,HTTP协议被用于在Web浏览器和网站服务器之间传递信息,以明文方式发送内容,不提供任何方式的数据加密,如果攻击者截取了Web浏览器和网站服务器之间的传输报文,就可以直接读懂其中的信息。
-
HTTPS协议:为了解决HTTP协议的这一缺陷,需要使用另一种协议:安全套接字层超文本传输协议HTTPS,为了数据传输的安全,HTTPS在HTTP的基础上加入了SSL/TLS协议,SSL/TLS依靠证书来验证服务器的身份,并为浏览器和服务器之间的通信加密。HTTPS协议可以理解为HTTP协议的升级,就是在HTTP的基础上增加了数据加密。在数据进行传输之前,对数据进行加密,然后再发送到服务器。这样,就算数据被第三者所截获,但是由于数据是加密的,所以你的个人信息仍然是安全的。这就是HTTP和HTTPS的最大区别。
- http默认使用的是80端口,https默认使用的是443端口
- 域名 主机(host)
- 也可以使用IP地址作为域名使用
- 端口号(port)
- 域名和端口之间使用“:”作为分隔符。端口不是一个URL必须的部分,如果省略端口部分,将采用默认端口
- 虚拟路径(path)
- 从域名后的第一个“/”开始到最后一个“/”为止,是虚拟目录部分。虚拟目录也不是一个URL必须的部分。
- 文件名
- 从域名后的最后一个“/”开始到“?”为止,是文件名部分,如果没有“?”,则是从域名后的最后一个“/”开始到“#”为止,是文件部分,如果没有“?”和“#”,那么从域名后的最后一个“/”开始到结束,都是文件名部分
- 参数
- 从“?”开始到“#”为止之间的部分为参数部分,又称搜索部分、查询部分。
- 参数可以允许有多个参数,参数与参数之间用“&”作为分隔符。
- 锚
- 从“#”开始到最后,都是锚部分。锚部分也不是一个URL必须的部分
3、请求对象的定制
这里复制百度的UA,放入到代码里

import urllib.request url = 'https://www.baidu.com' headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36u' } # 因为urlopen方法中不能存储字典 所以headers不能传递进去 # 请求对象的定制 #注意 英文参数顺序的问题 不能直接写url 和 headers 中间还有data 所以要使用关键字传参 request = urllib.request.Request(url=url,headers=headers) response = urllib.request.urlopen(request) content = response.read().decode('utf8') print(content)
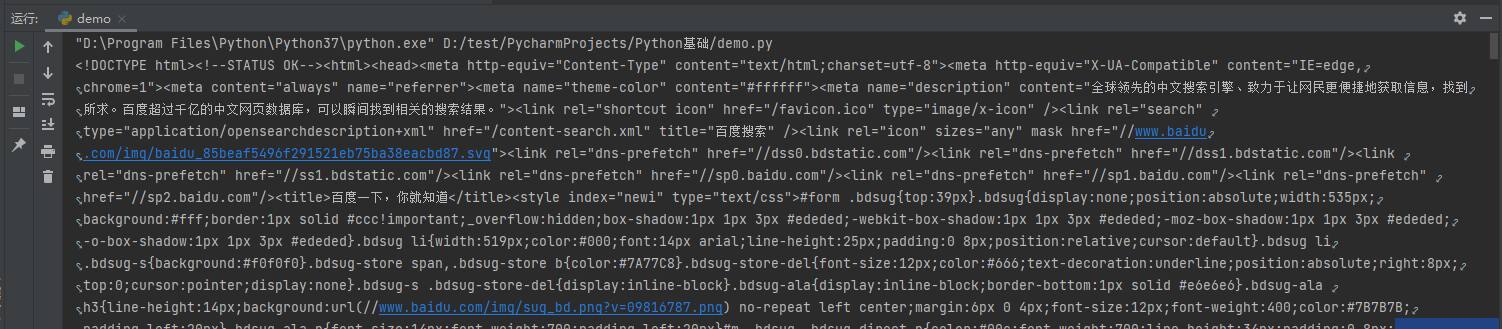
说明:UA是模仿从游览器发起的请求,这样才可以获取完整的数据。
不定制请求对象的情况
import urllib.request url = 'https://www.baidu.com' headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36' } #不定制请求对象 request = urllib.request.Request(url=url) response = urllib.request.urlopen(request) content = response.read().decode('utf8') print(content)
输出结果:
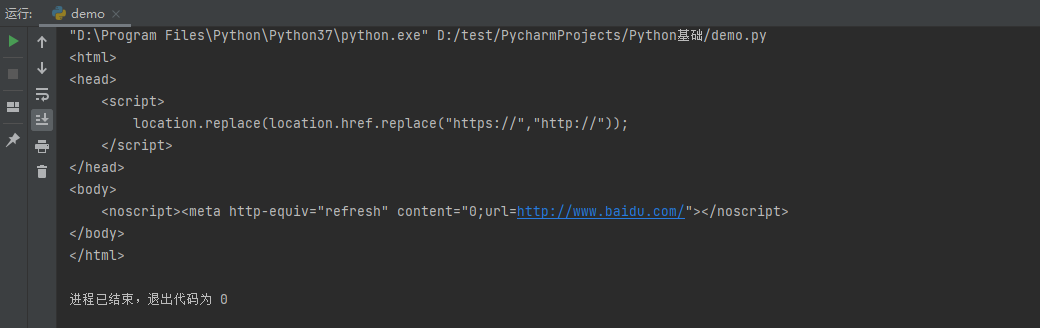
https协议是一个更加安全的协议,UA就是其中一种反爬的手段。如果请求没有携带UA,则获取到的数据不完整。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号