
后缀自动机(Suffix Automaton)
后缀自动机(Suffix Automaton)
一个基于后缀自动机的另一种统计子串出现次数的方法
定义
一个字符串的后缀自动机(SAM)是一个 DAG(Directed Acyclic Graph),边(或者说转移)带权,权值是一个字符,除了起始节点 ,节点分为两种,一种是中间节点,只是为了连边而新建的节点,一种是结束节点,表示从 到它的路径上边的字符连起来是字符串的一个后缀。最容易被忽视的,每个节点一种边只能有一条,也就是说,从某个节点向外连接两条字符为 的边是不被允许的。 在所有合法的 DAG 中,后缀自动机是规模最小的一个。
从后缀自动机的 点出发,任何一条到达某结束节点的路径上,边的字符连成的字符串都是原字符串的一个后缀。
这样就可以推得后缀自动机的一个性质。
因为一个字符串的任意字串都能表示成它的某个后缀的前缀,而且从 出发到任意节点的路径都是从 点到某个结束节点路径的一部分。也就是说任意从 出发的路径都表示原字符串的后缀的一个前缀, 即原字符串的子串。
举例
这是字符串 sdflk 的后缀自动机:
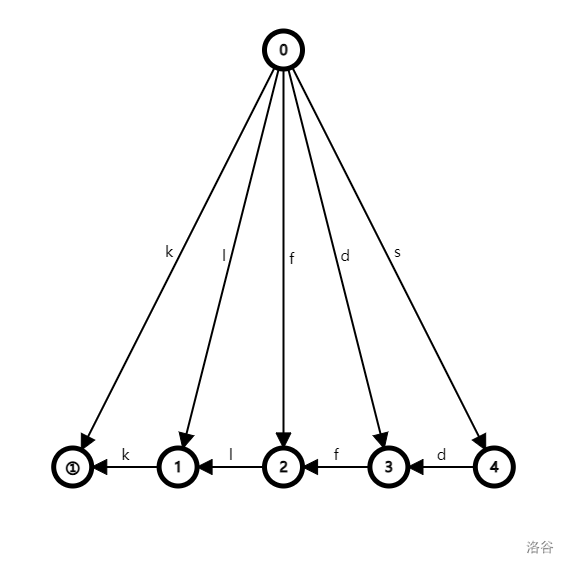
其中,节点 是结束节点,点 是起始节点。
引入一个概念,一个字符串的子串 的 就是它每次在字符串中出现时的末尾字符位置的集合。
对于 有两个引理显而易见:
对于两个子串 , ,假设 。
-
若有 ,则 是 的后缀。
-
如果 是 的后缀,则 ; 否则
引入一个 等价类的概念,所有满足 相等的字符串 组成一个 的等价类。
所以两个引理的意思是,两个 只有一个包含另一个和交集为空两种关系。
推广第一个定理,易知一个等价类中的字符串,短的是长的的后缀。
等价类还有一个重要且实用的性质,可以通过反证法推得。等价类中的子串长度是连续的区间,且不存在长度相等的两个字符串。这就是说,一个等价类的每个字符串都是比它短 的字符串前面加一个字符得到的。
等价类树
由于一个 等价类中的字符串是由最短的字符串在前面一个一个加字符得到的,那么增加字符的边界就是等价类中最长的字符串。当在一个等价类最长的字符串 前面加一个字符,如果得到了一个原字符串的子串 ,那么 一定是 的子集, 成为新的等价类的最短的字符串。
因为只要 出现的地方, 必然出现,但是在出现的所有的 前面加一个字符得到的一定不全是同一个字符串,否则 就不是等价类中最长的字符串了。在这些出现的 前面,只要有字符,就能组成一个以 为后缀,长度比 大 的字符串。根据前面得到的结论,所有这些字符串所在的等价类都是 的真子集。
根据前面的引理得, 前加字符得到的所有的这些字符串的 交集为空。所以对于 的子串的所有的 等价类根据包含关系组成一个树形结构。这个树以空串的 为根,以不同的等价类为节点。
后缀链接(),指从一个等价类代表的节点连向这个等价类最短字符串 去掉它的左端字符得到的字符串 所在节点的指针。也就是从一个节点到它的 树上的父亲所在节点的指针。易知 是等价类 中最长的字符串。这里的 是 的子集,因为 是 的后缀,所以 出现时, 必然出现, 出现时, 可以不出现。
严格来说, 是 的真子集,如果 , 就不是等价类中的最短字符串了,因为 也在这个等价类中,且 比 更短。
由于 是 的后缀,所以称为后缀链接。
容易发现,后缀链接由下到上组成一个树形结构,而这棵树恰恰就是 等价类组成的树形结构。
后缀链接树的节点表示的字符串是这个 等价类的最长字符串。总结来说,后缀链接树的节点和 等价类一一对应。每一条边都是在一个等价类 和满足 的等价类 之间连接的。
构造 SAM
如果把规模大小限制去掉,仅构造一个无大小限制的 SAM,可以很容易想到,枚举所有后缀,插入一个 Trie,每个后缀的尾字符是一个终止节点,根是 点,把节点上的字符放到它和父亲之间的边上。这样,只要从根走到一个结束节点,就能表示一个后缀。
考虑优化规模,发现对于 ababab 这种字符串,Tire 有两条链,但是如果构造一条链
其中 , , 是终止节点,再从 到 连一条 的边,那么这就是一个 ababab 的后缀自动机了。
但是这种优化是没有章法的,所以接下来尝试利用后缀链接树来构造 SAM。
大体思想是和后缀链接树共用节点,SAM 中 点到某个节点的路径表示的字符串属于同一个 等价类,最短的字符串是等价类的公共后缀。所以一个节点的入边必然是同一个字符,否则这个节点表示的字符串就不具有公共后缀了。也就是说 SAM 中每个节点和 等价类树上的节点一一对应,也和后缀链接树上的节点一一对应。
以后缀链接树的节点为 SAM 的节点,后缀链接树的节点表示的字符串作为 SAM 中 走到这个节点的路径表示的所有字符串的最长字符串,SAM 节点的 是这个节点表示的最长字符串的长度。以后缀链接树中所有 中有元素 的节点为 SAM 的结束节点,因为这些节点的等价类中的字符串都是 的后缀。后缀链接树的根是空串,也是 SAM 的起点 。
考虑递推地构造 SAM。
从边界情况开始,空串的后缀自动机是一个起始节点,后缀链接树只有一个根节点。接下来尝试在空串后面一个一个加字符,同时一边构造后缀自动机,一边维护后缀链接树,因为后缀链接树在后面的构造中会用到。
设新的字符是 ,加入字符 之前的字符串是 ,代表 等价类的节点设为 。一个字符加入时,整个字符串长度增加,新字符串 的节点长度为 ,只能从唯一的长度为 的 通过一条边 转移过来。 等价类中 的元素这时只有 。
希望找到 对应的节点的后缀链接,这个点的字符串是 的后缀,且在所有这些点中满足 是最长的一个。满足是 后缀的节点,必然是由一个 的后缀节点通过出边 连过来的。 的后缀节点都是后缀链接树中 的祖先,而前面已经把 的后缀链接连好了,所以只要顺着 的后缀链接往上走就能遍历所有可能满足条件的点了。
一个字符的加入后,在后缀链接树上中从 往上跳时(跳到的节点的等价类包含的字符串都是 的后缀),有两种情况。
设目前跳到的节点为 ,其表示的字符串是 。
-
有出边
这时根据 再次细分为两种情况。
-
这时 (指 点通过出边 转移到的节点)的字符串是 , 是所有转移到 中的节点中 最长的,即 等价类中最长字符串去掉最后的 后得到的字符串在等价类 中。因为等价类中所有字符串都是这个等价类最长的字符串的后缀,所以 中其它的字符串都是 的后缀,更是 的后缀。
从 往上跳的过程中, 是目前找到的 的后缀链接树上的最深的满足 的等价类中所有字符串都是 的后缀的祖先。这时找到的 是最长的,因为再往上找, 的长度越来越小, 的长度也越来越小。
这时 是后缀链接树上 节点的父亲。
-
在众多有出边 连向 的节点中, 的 不是最长的。设通过 转移到 的节点中 最长的点是 ,其对应字符串是 ; 的字符串是 ,则 。又因为 和 在同一个等价类,所以 是 的后缀。
后缀链接树中,一个节点的 一定比它的祖先长,所以 不是 的祖先。又因为 在后缀链接树中不是已经访问到的 的比 小的祖先,所以 不是 的祖先。也就是说, 不是 的后缀。
这时要想找 的后缀,已知 是 的后缀,所以 和 不是一个等价类的。原来的 节点分裂成两个,一个是 节点,其等价类包含原等价类中比 长的字符串,也就是那些不是 的后缀的字符串;另一个是新的 ,其等价类包含的是原等价类中长度小于等于 的长度的字符串,它们是 的后缀。因为是从一个等价类分裂出来的,所以后者 只比前者的多一个元素 。
这时的 应当具有 的所有转移,因为字符串有后缀 的也一定会有后缀 。因为 的节点的 是目前找到的最长的 的后缀长度,所以 节点的后缀链接树父亲是 。又因为 是 的后缀,所以 又是 后缀链接树上的父亲, 原来的父亲变成 的父亲。
最后,由于 是刚被复制出来的,所以对于 后缀链接树上的祖先,这时它们的转移 仍然指向 ,而 的等价类中只剩下长度大于等于 的字符串了, 和它的祖先也就不能转移到 了,所以把 和它的原先转移 指向 的祖先的转移 连向 。
-
-
对应节点没有出边
这个点的字符串 虽然是 的后缀,但是 ,也就是 的后缀,暂时不存在。所以继续往上跳,直到找到有 的转移的节点为止。因为新加入的 产生了一个字符串 ,所以 的转移 连向 ,表示新出现的第一个 子串。
跳到根节点 都没找到,说明 中一个 都没有,而新加入的 是第一个。因为我们要找的是 的后缀链接,必须找到一个节点的等价类中的字符串都是 的后缀,这时根节点恰好满足这个条件。所以如果跳到最后都没找到,后缀链接直接连向根。
在将 个节点全部插入后,后缀自动机和后缀链接树就都建好了,接下来对这种方法构造的时空复杂度和正确性进行证明。
正确性
容易发现,只要 的后缀 , 不在同一个等价类,, 也不在同一个等价类。所以对于新节点的建立,只要找出所有 的后缀的等价类。
SAM 中的边,终点的公共后缀是在起点的公共后缀后加了一个字符(即这条边表示的字符)得到的字符串的后缀(因为有多个点连向这个终点,每个点公共后缀长度不同,但是一定有一个最短的公共后缀,它的后面加上连向终点的边表示的字符后得到的字符串即为终点的公共后缀)。所以 SAM 中在两点 , 间连边,设它们表示的字符串(公共后缀)分别为 , ,且 。必须满足 去掉一个字符后是 的后缀。
从 点出发,走到某个节点 ,由于 的字符串去掉最后一个字符 后是连向 的所有转移的起点的字符串的后缀,所以这些转移相同,都为 。
接下来看起点到结束节点的路径表示的字符串是否表示了 的所有后缀。
首先,证明 到结束节点的任何路径都表示 的一个后缀。所有的结束节点的等价类的字符串都是 的后缀,这是我们前面已经说明了的。每个点的等价类中的所有字符串都是这个点的字符串的后缀。换个角度,因为每个结束节点都在一条后缀链接链上,也就是说每个节点的祖先的字符串是它的后缀,即这条链上所有等价类的所有字符串是它的链底节点的字符串的后缀。又因为链底节点是 表示的节点,所以 到这个点的所有路径表示的字符串都是 的后缀。
接下来,证明没有后缀被漏掉。因为等价类内部的字符串是连续的,所以只要证明链上等价类的最长字符串 和这个节点儿子等价类中最短的字符串 是否满足 即可。如果存在 , 使得 ,且 是 的后缀, 是 的后缀,那么 所在的节点应该是 所在节点的父亲, 所在节点的儿子。但是 所在节点的儿子是 所在节点的父亲,所以假设不成立,原命题得证。
接下来证明时空复杂度时,将字符集的规模都暂时视为常数。
空间复杂度分析
先分析点数的复杂度。由于每次加入一个字符时必然加入一个节点,而且有一定概率会添加第二个节点,所以后缀自动机最多有 个节点。由于前两个字符加入时只会加入一个节点,再加上空串的一个节点,所以可以得到更紧确的上界 。
SAM 的所有信息都是直接存在点对应的结构体中的,一个点包含的内容是一些指针和一些属性值,只要将字符集看作常数,则一个点的空间是常数。因为有线性数量的点,所以空间复杂度为线性,。
时间复杂度分析
总的时间复杂度一定是 ,所以分析每次加入字符的复杂度。
加入一个字符的时间取决于每个节点加入时寻找 点( 有转移 的最小祖先)的向上跳的次数,还有每次新建节点时将 的转移 连到 上的祖先的 连回 上要更换转移的节点数。
先分析向上跳的次数,这取决于从 往上有多少没有转移 的祖先。节点数是线性的,它们的转移只能产生不能消失,所以一共有线性的节点没有转移 ,所以总共最多添加线性数量的转移 。又因为字符集视为常数,所以所有的向上跳的次数为线性。
接下来是修改转移的时候,设从 到空串的后缀链接链为 ,其节点(除了空串节点)都是由 到空串节点的后缀链接链 上的点转移来的。每个节点只有一条转移 ,所以 上向 转移的节点最多有 个(无需连根节点)。也就是说如果 的 个节点被修改转移,则 ,所以总的修改转移的节点数为节点数 + 转移数,两者都是线性,所以这一步总复杂的也是线性。
模板 (Luogu3804)
给一个字符串,求这个字符串出现次数大于 的子串的长度和出现次数的积的最大值。
现在普遍的做法是构造后缀自动机,在表示前缀的节点(也就是每次加入字符首先创建的节点)上进行标记,然后在后缀链接树上跑 DFS,进行子树查询,但是这样需要邻接表记录一个节点的后缀链接入边,显然我是懒得打的,于是我在做题的时候想到了一种新的做法。
我一开始尝试找规律,发现可以在自动机的转移边上跑 DFS,在结束节点上打标记,统计每个点 DFS 树上的子树和,能走到结束点的路径数,这便是这个节点的等价类的字符串出现的次数。
这样做的原因也很简单,一个子串必然是一个后缀的前缀,所以这个子串的出现次数,就是这个子串作为前缀的后缀的出现次数之和。这个子串做前缀的后缀必然可以从这个子串转移到。从某个点搜起,它搜索树上儿子出现一次,它也会出现一次,所以只要统计搜索树上子树和即可。
既然知道了一个 等价类的出现次数,统计最大值只要考虑这个等价类中最长字符串即可,所以用这个等价类出现的次数乘这个节点的 即可尝试更新答案。
代码
首先是算法主体
#include <algorithm>
#include <cmath>
#include <cstdio>
#include <cstdlib>
#include <cstring>
#include <ctime>
#include <iostream>
#include <map>
#include <queue>
#include <vector>
#define Wild_Donkey 0
using namespace std;
unsigned m, n, Cnt(0), t, Ans(0), Tmp(0);
short nowCharacter;
char s[1000005];
struct Node {
unsigned Length, Times; // 长度(等价类中最长的), 出现次数
char endNode; // 标记 (char 比 bool 快)
Node *backToSuffix, *SAMEdge[26];
}N[2000005], *CntN(N), *Last(N), *now(N), *A, *C_c;
int main() {
scanf("%s", s);
n = strlen(s);
for (register unsigned i(0); i < n; ++i) {
Last = now; // Last 指针往后移
A = Last; // s 对应的节点
nowCharacter = s[i] - 'a'; // 取字符, 转成整数
now = (++CntN); // s + c 对应的节点
now->Length = Last->Length + 1; // len[s + c] = len[s]
while (A && !(A->SAMEdge[nowCharacter])) { // 跳到 A 有转移 c 的祖先
A->SAMEdge[nowCharacter] = now; // 没有转移 c, 创造转移 (Endpos = {len_s + 1})
A = A->backToSuffix;
}
if(!A) { // c 首次出现
now->backToSuffix = N; // 后缀链接连根
continue; // 直接进入下一个字符的加入
}
if (A->Length + 1 == A->SAMEdge[nowCharacter]->Length) {
now->backToSuffix = A->SAMEdge[nowCharacter]; // len[a] + 1 = len[a->c] 无需分裂
continue;
}
(++CntN)->Length = A->Length + 1; // 分裂出一个新点
C_c = A->SAMEdge[nowCharacter]; // 原来的 A->c 变成 C->c
memcpy(CntN->SAMEdge, C_c->SAMEdge, sizeof(CntN->SAMEdge));
CntN->backToSuffix = C_c->backToSuffix; // 继承转移, 后缀链接
C_c->backToSuffix = CntN; // C -> c 是 A -> c 后缀链接树上的儿子
now->backToSuffix = CntN; // 连上 s + c 的后缀链接
while (A && A->SAMEdge[nowCharacter] == C_c) { // 这里要将 A 本来转移到 C->c 的祖先重定向到 A->c
A->SAMEdge[nowCharacter] = CntN; // 连边
A = A->backToSuffix; // 继续往上跳
}
}
while (now != N) { // 打标记
now->endNode = 1; // 从 s 向上跳 (从 s 到 root 这条链上都是结束点)
now = now->backToSuffix;
}
DFS(N); // 跑 DFS, 统计 + 更新 Ans
printf("%u\n", Ans);
return Wild_Donkey;
}
最后补充一个普普通通的 DFS(),记忆化搜索
inline unsigned DFS(Node *x) {
unsigned tmp(0);
if(x->endNode) {
tmp = 1;
}
for (register unsigned i(0); i < 26; ++i) {
if(x->SAMEdge[i]) { // 有转移 i
if(x->SAMEdge[i]->Times > 0) { // 被搜索过
tmp += x->SAMEdge[i]->Times; // 直接统计
}
else { // 未曾搜索
tmp += DFS(x->SAMEdge[i]); // 搜索
}
}
}
if (tmp > 1) { // 出现次数不为 1
Ans = max(Ans, tmp * x->Length); // 尝试更新答案
}
x->Times = tmp; // 存储子树和
return tmp; // 子树和用于搜索树上的父亲的统计
}
小结
这次后缀自动机的学习时间线拉的很长,从 Apr.1st 2021 学完后缀数组,本以为是后缀自动机的前置知识,结果没想到根本没用上,只能从零开始。
一开始漏了一个条件,以为一个点可以有多个不同转移,认为一个超级源点连向 个点, 个点再连成一条链,简单粗暴,突破了 的点数下界,得到了图灵奖级别的成果,结果被成功自我否定。
后来写代码,出现了很多匪夷所思的问题,最后写好了 DFS,运行发现输出 ,找了好久才意识到 DFS() 在 main() 没调用。
第一次交发现没看见 "出现次数不为 ",害得我对着代码看了好久,我真是憨得过分。
最后找到了问题,过了模板以后把递归跳边改成了 main() 里面循环跳边,怎么都调不动,发现是打标记时没有初始化有问题。
收尾博客时证明打标记和搜索的正确性,证不动了去看题解,猛然发现自己的方法和他们不一样,收获了意外之喜,于是自己口胡了一个证明,如有问题希望指正。
经常有在机房对着电脑一晚上抓耳挠腮的歇斯底里,也有文化课上拿着打印的材料偷偷研究,博客也是像挖隧道一样艰难推进,代码更是最后两天才动工,直到今天 Apr.9th 2021 一周多的跌跌撞撞,终于算是结束了这个节点的学习。
然后在我因为搞出新做法,花了一晚上审稿,将我熟悉的半角标点改成全角,满怀信心地交题解的时候,因题解过多被禁止提交该题题解。(最后交上了)


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 探究高空视频全景AR技术的实现原理
· 理解Rust引用及其生命周期标识(上)
· 浏览器原生「磁吸」效果!Anchor Positioning 锚点定位神器解析
· DeepSeek 开源周回顾「GitHub 热点速览」
· 记一次.NET内存居高不下排查解决与启示
· 物流快递公司核心技术能力-地址解析分单基础技术分享
· .NET 10首个预览版发布:重大改进与新特性概览!
· .NET10 - 预览版1新功能体验(一)