
第四次作业
作业一:爬取当当网站图书数据
books.py
import scrapy
from ..items import BookItem
from bs4 import UnicodeDammit
class BooksSpider(scrapy.Spider):
name = 'books'
# allowed_domains = ['http://www.dangdang.com/']
start_urls = ['http://http://www.dangdang.com//']
def start_requests(self):
url = "http://search.dangdang.com/?key=小说&act=input"
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
try:
dammit = UnicodeDammit(response.body, ["utf-8", 'gbk'])
data = dammit.unicode_markup
selector = scrapy.Selector(text=data)
lis = selector.xpath("//ul[@class='bigimg']/li")
for li in lis:
title = li.xpath("./p[@class='name']/a/@title").extract_first()
author = li.xpath("./p[@class='search_book_author']/span[position()=1]/a/@title").extract_first()
price = li.xpath("./p[@class='price']/span[@class='search_now_price']/text()").extract_first()
date = li.xpath("./p[@class='search_book_author']/span[position()=last()-1]/text()").extract_first()
publisher = li.xpath("./p[@class='search_book_author']/span[position()=3]/a/@title").extract_first()
detail = li.xpath("./p[@class='detail']/text()").extract_first()
# print(title)
item = BookItem()
item["title"] = title.strip() if title else ""
item["author"] = author.strip() if author else ""
item['price'] = price.strip() if price else ""
item['date'] = date.strip()[1:] if price else ""
item['publisher'] = publisher.strip() if publisher else ""
item['detail'] = detail.strip() if detail else ""
yield item
except Exception as err:
print(err)
items.py
import scrapy
class BookItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
author = scrapy.Field()
publisher = scrapy.Field()
date = scrapy.Field()
price = scrapy.Field()
detail = scrapy.Field()
piplines.py
import pymysql
class BookPipeline:
def open_spider(self, spider):
print("opened")
try:
self.con = pymysql.connect(host="127.0.0.1", port=3306, user="root",
passwd="yang6106", db="test", charset="utf8")
self.cursor = self.con.cursor(pymysql.cursors.DictCursor)
self.cursor.execute("delete from my_book")
self.opened = True
self.count = 0
except Exception as err:
print(err)
self.opened = False
def close_spider(self, spider):
if self.opened:
self.con.commit()
self.con.close()
self.opened = False
print("closed")
print("总共爬取", self.count, "本书籍")
def process_item(self, item, spider):
try:
print(item["title"])
if self.opened:
self.cursor.execute(
"insert into my_book(bTitle,bAuthor,bPublisher,bDate,bPrice,bDetail) values (%s,%s,%s,%s,%s,%s)",
(item["title"], item["author"], item["publisher"], item["date"], item["price"], item["detail"]))
self.count += 1
except Exception as err:
print(err)
return item
结果:

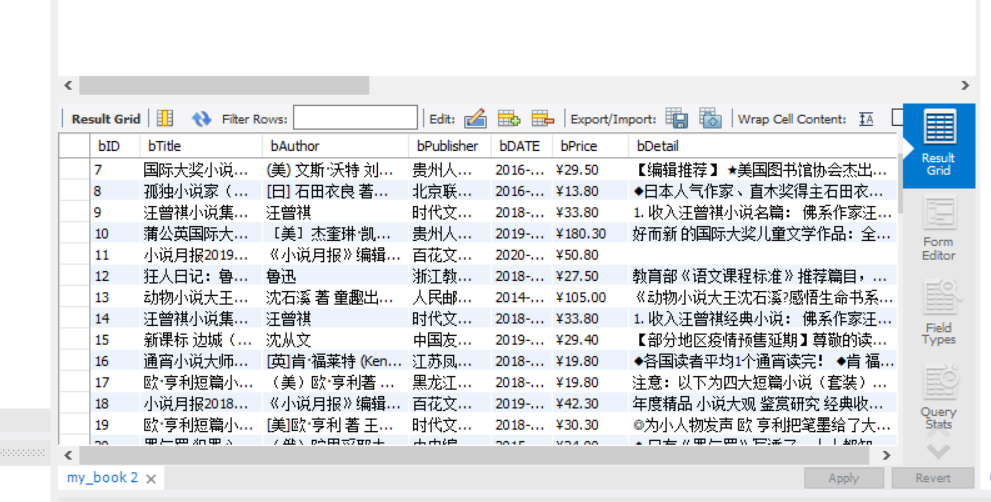
心得:参考书上的内容,学习mysql的保存方法,同时学习使用mysql软件的使用,并连通scrapy跟mysql
作业二
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;Scrapy+Xpath+MySQL数据库存储技术路线爬取股票相关信息
gupiaos.py
import scrapy
import re
import urllib.request
from bs4 import UnicodeDammit
from bs4 import BeautifulSoup
from ..items import GupiaoItem
class GupiaosSpider(scrapy.Spider):
name = 'gupiaos'
page = 1
# allowed_domains = ['http://quote.eastmoney.com/']
start_urls = ['http://quote.eastmoney.com/stock_list.html']
def parse(self, response):
while self.page <= 100:
url = "http://22.push2.eastmoney.com/api/qt/clist/get?cb=jQuery112406286903286457721_1602799759543&pn=%d&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&fid=f3&fs=m:0+t:6,m:0+t:13,m:0+t:80&fields=f12,f14,f2,f3,f4,f5,f6,f7,f15,f16,f17,f18&_=1602799759869" % (
self.page)
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) ""Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3775.400 QQBrowser/10.6.4209.400"}
req = urllib.request.Request(url, headers=headers)
data = urllib.request.urlopen(req)
data = data.read()
dammit = UnicodeDammit(data, ["utf-8", "gbk"])
data = dammit.unicode_markup
soup = BeautifulSoup(data, 'html.parser')
data = re.findall(r'"diff":\[(.*?)]', soup.text)
datas = data[0].strip("{").strip("}").split('},{')
for i in range(len(datas)):
item = GupiaoItem()
line = datas[i].replace('"', "").split(",")
item["f12"] = line[6][4:]
item["f14"] = line[7][4:]
item["f2"] = line[0][3:]
item["f3"] = line[1][3:]
item["f4"] = line[2][3:]
item["f5"] = line[3][3:]
item["f6"] = line[4][3:]
item["f7"] = line[5][3:]
item["f15"] = line[8][4:]
item["f16"] = line[9][4:]
item["f17"] = line[10][4:]
item["f18"] = line[11][4:]
yield item
self.page += 1
items.py
import scrapy
class GupiaoItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
data = scrapy.Field()
f12 = scrapy.Field()
f14 = scrapy.Field()
f2 = scrapy.Field()
f3 = scrapy.Field()
f4 = scrapy.Field()
f5 = scrapy.Field()
f6 = scrapy.Field()
f7 = scrapy.Field()
f15 = scrapy.Field()
f16 = scrapy.Field()
f17 = scrapy.Field()
f18 = scrapy.Field()
pipelines.py
import pymysql
class GupiaoPipeline:
def process_item(self, item, spider):
print(1)
try:
if self.opened:
self.cursor.execute(
"insert into storks (股票代码,股票名称,最新报价,涨跌幅,涨跌额,成交量,成交额,振幅,最高,最低,今开,昨收) values( % s, % s, % s, % s, % s, % s,% s, % s, % s, % s, % s, % s)",(item["f12"], item["f14"], item["f2"], item["f3"], item["f4"], item["f5"], item["f6"], item["f7"], item["f15"], item["f16"], item["f17"], item["f18"]))
# 编写插入数据的sql
self.count += 1
except Exception as err:
print(err)
return item
def open_spider(self, spider):
print("opened")
try:
self.con = pymysql.connect(host="127.0.0.1", port=3306, user="root", passwd="yang6106", db="test", charset="utf8")
# 创建连接
self.cursor = self.con.cursor(pymysql.cursors.DictCursor)
# 创建游标对象
self.cursor.execute("delete from storks")
self.opened = True
self.count = 0
except Exception as err:
print(err)
self.opened = False
def close_spider(self, spider):
if self.opened:
self.con.commit()
self.con.close()
self.opened = False
print("closed")
print("总共爬取", self.count, "条股票信息")
settings.py
BOT_NAME = 'gupiao'
SPIDER_MODULES = ['gupiao.spiders']
NEWSPIDER_MODULE = 'gupiao.spiders'
ITEM_PIPELINES = {
'gupiao.pipelines.GupiaoPipeline': 300,
}
run.py
from scrapy import cmdline
cmdline.execute("scrapy crawl gupiaos -s LOG_ENABLED=false".split())
结果: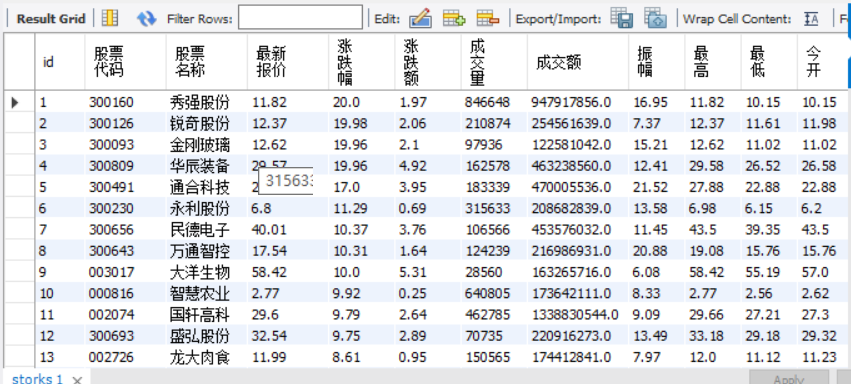
心得:开始的时候一直是爬取零支股票,后面检查发现管道没运行。然后数据库这边的话由于第一个作业挺顺利的就没遇到什么麻烦
作业三
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。
main.py:
import scrapy
from ..items import WaihuiItem
from scrapy.selector import Selector
class MainSpider(scrapy.Spider):
name = 'main'
allowed_domains = ['http://fx.cmbchina.com/hq']
start_urls = ['http://fx.cmbchina.com/hq/']
def parse(self, response):
try:
data = response.body.decode()
selector = Selector(text=data)
table = selector.xpath("//table[@class='data']/tr")
for t in table[1:]:
currency = t.xpath("./td[position()=1]/text()").extract_first()
tsp = t.xpath("./td[position()=4]/text()").extract_first()
csp = t.xpath("./td[position()=5]/text()").extract_first()
tbp = t.xpath("./td[position()=6]/text()").extract_first()
cbp = t.xpath("./td[position()=7]/text()").extract_first()
time = t.xpath("./td[position()=8]/text()").extract_first()
item = WaihuiItem()
item["Currency"] = currency.strip() if currency else ""
item["TSP"] = tsp.strip() if tsp else ""
item["CSP"] = csp.strip() if csp else ""
item["TBP"] = tbp.strip() if tbp else ""
item["CBP"] = cbp.strip() if cbp else ""
item["time"] = time.strip() if time else ""
yield item
except Exception as err:
print(err)
items.py
import scrapy
class WaihuiItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
Currency = scrapy.Field()
TSP = scrapy.Field()
CSP = scrapy.Field()
TBP = scrapy.Field()
CBP = scrapy.Field()
time = scrapy.Field()
pipelines.py
import pymysql
class WaihuiPipeline:
def process_item(self, item, spider):
try:
print(type(item["Currency"]))
print(type(item["TSP"]))
print(type(item["CSP"]))
print(type(item["TBP"]))
print(type(item["CBP"]))
print(type(item["time"]))
print()
if self.opened:
self.cursor.execute(
"insert into 外汇 (Currency,TSP,CSP,TBP,CBP,Time) value (%s,%s,%s,%s,%s,%s)",
(item['Currency'], item['TSP'], item['CSP'], item['TBP'], item['CBP'], item['time']))
self.count += 1
except Exception as err:
print(err)
return item
def open_spider(self, spider):
print('opened')
try:
self.con = pymysql.connect(host='localhost', port=3306, user='root', passwd='yang6106', db='test',
charset='utf8', autocommit=True)
self.cursor = self.con.cursor(pymysql.cursors.DictCursor)
self.cursor.execute('delete from 外汇')
self.opened = True
self.count = 0
except Exception as err:
print(err)
self.opened = False
def close_spider(self, spider):
if self.opened:
self.con.close()
self.opened = False
print('closed')
print('总共爬取', self.count, '种外汇')
settings.py
BOT_NAME = 'waihui'
SPIDER_MODULES = ['waihui.spiders']
NEWSPIDER_MODULE = 'waihui.spiders'
ITEM_PIPELINES = {
'waihui.pipelines.WaihuiPipeline': 300,
}
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'waihui (+http://www.yourdomain.com)'
# Obey robots.txt rules
ROBOTSTXT_OBEY = True
run.py
from scrapy import cmdline
cmdline.execute("scrapy crawl main -s LOG_ENABLED=False".split())
结果: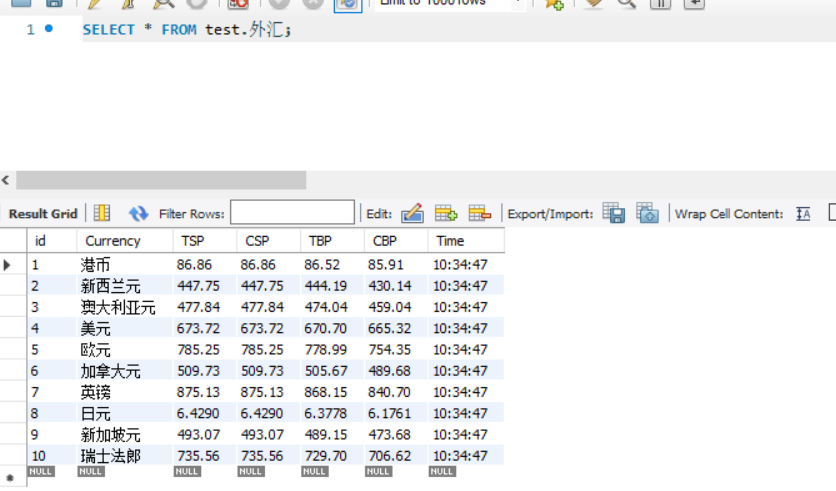
心得:通过这实验,我掌握了数据库的使用以及继续深入学习scrapy框架

