
第三次作业
作业①
单线程/多线程爬取图片:
要求:指定一个网站,爬取这个网站中的所有的所有图片,例如中国气象网(http://www.weather.com.cn)。分别使用单线程和多线程的方式爬取。
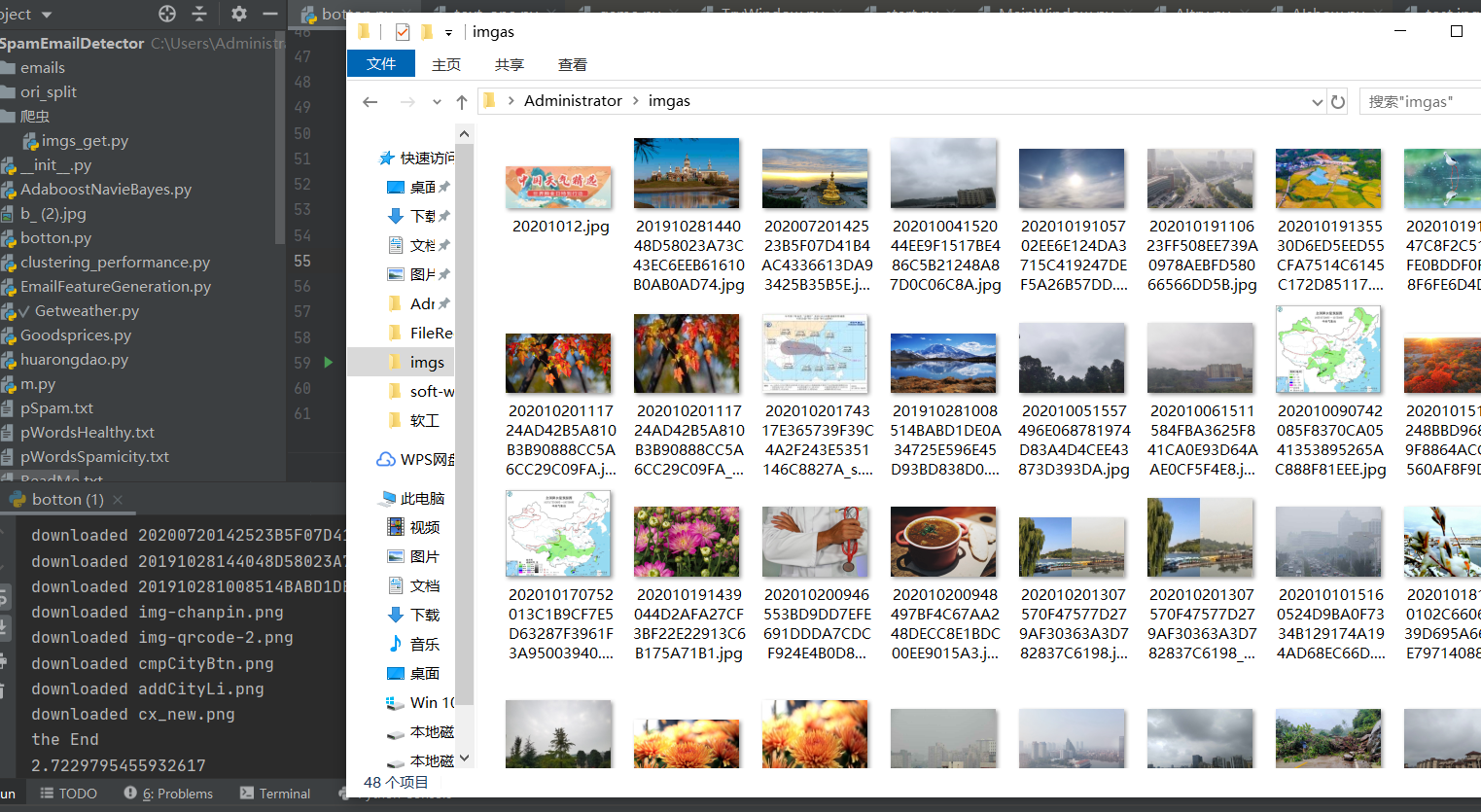
输出信息:将下载的Url信息在控制台输出,并将下载的图片存储在images子文件中,并给出截图。
单线程代码:
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
import urllib.request
import time
headers = {
"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US;rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"}
thread = []
def imageSpider(url):
global thread
try:
urls = []
req = urllib.request.Request(url, headers=headers)
data = urllib.request.urlopen(req)
data = data.read()
dammit = UnicodeDammit(data, ["utf-8", "gbk"])
data = dammit.unicode_markup
soup = BeautifulSoup(data, "lxml")
images1 = soup.select("img")
for image in images1:
try:
src = image["src"]
url = urllib.request.urljoin(url, src)
if url not in urls:
urls.append(url)
download(url)
except Exception as err:
print(err)
except Exception as err:
print(err)
def download(url):
try:
if url[-4] == ".":
name = url.split("/")[-1]
req = urllib.request.Request(url, headers=headers)
data = urllib.request.urlopen(req, timeout=100)
data = data.read()
fobj = open('C:/Users/Administrator/imgas/' + name, "wb") #创建打开文件夹
fobj.write(data)
fobj.close()
print("downloaded " + name)
except Exception as err:
print(err)
def main():
Url = "http://www.weather.com.cn/weather1d/101280501.shtml"
imageSpider(Url)
print("End")
if __name__ == '__main__':
main()
结果:
多线程:
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
import urllib.request
import time
import threading
headers = {
"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US;rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"}
thread = []
def imageSpider(start_url, Path):
global thread
try:
urls = []
req = urllib.request.Request(start_url, headers=headers)
data = urllib.request.urlopen(req)
data = data.read()
dammit = UnicodeDammit(data, ["utf-8", "gbk"])
data = dammit.unicode_markup
soup = BeautifulSoup(data, "lxml")
images1 = soup.select("img")
for image in images1:
try:
src = image["src"]
url = urllib.request.urljoin(start_url, src)
if url not in urls:
urls.append(url)
T = threading.Thread(target=download, args=(url, Path))
T.setDaemon(False)
T.start()
thread.append(T)
except Exception as err:
print(err)
except Exception as err:
print(err)
def download(url, save_path):
try:
if url[-4] == ".":
name = url.split("/")[-1]
req = urllib.request.Request(url, headers=headers)
data = urllib.request.urlopen(req, timeout=100)
data = data.read()
fobj = open(save_path + name, "wb")
fobj.write(data)
fobj.close()
print("downloaded " + name)
except Exception as err:
print(err)
def main():
Url = "http://www.weather.com.cn/weather1d/101280501.shtml"
path = 'C:/Users/Administrator/imgas/'
time_start = time.time() # 开始计时
imageSpider(Url,path)
print("the End")
time_end = time.time() # 计时结束
print(time_end - time_start) # 输出耗时
if __name__ == '__main__':
main()
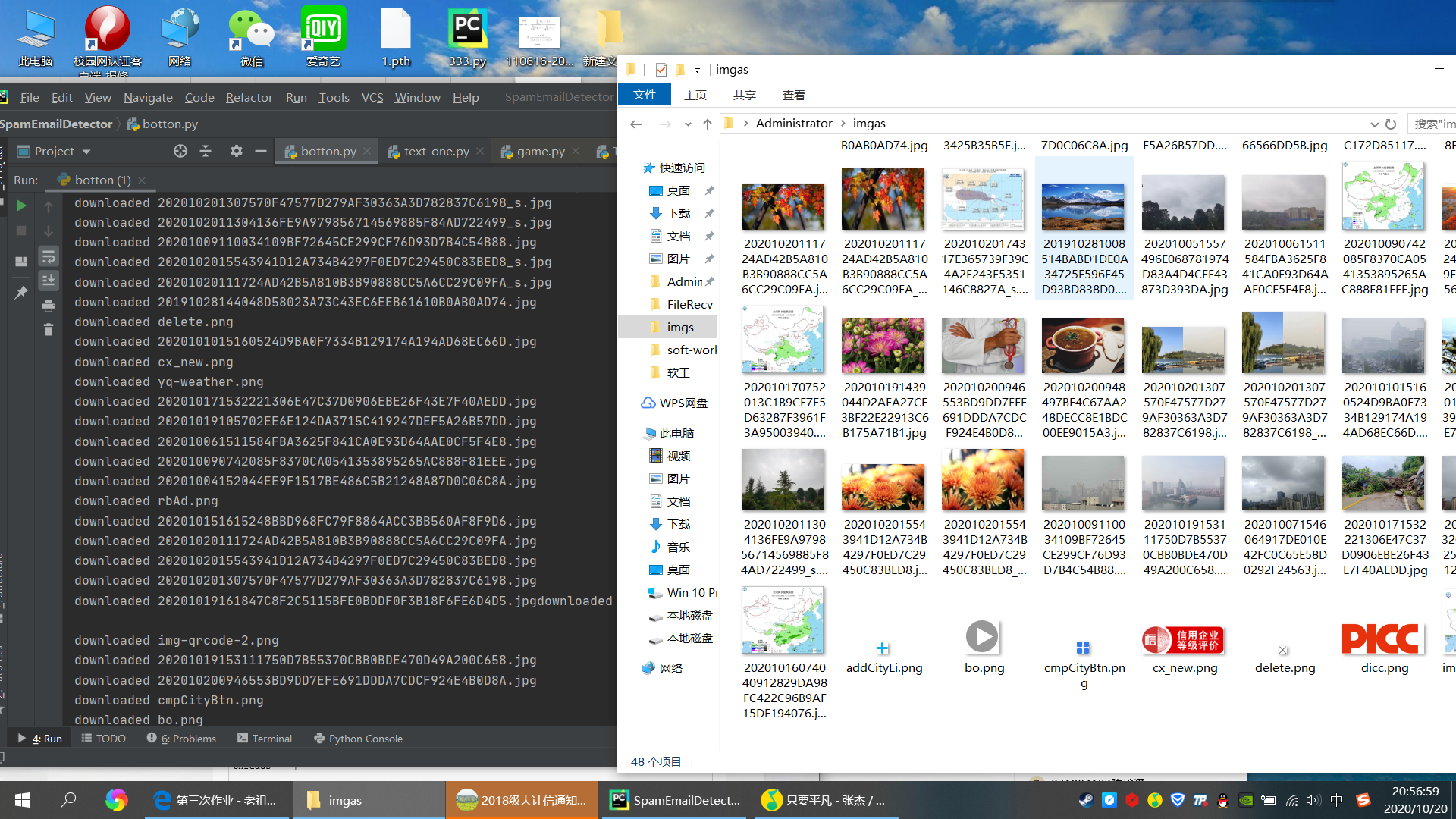
结果:
作业②
scrapy框架实现作业①:
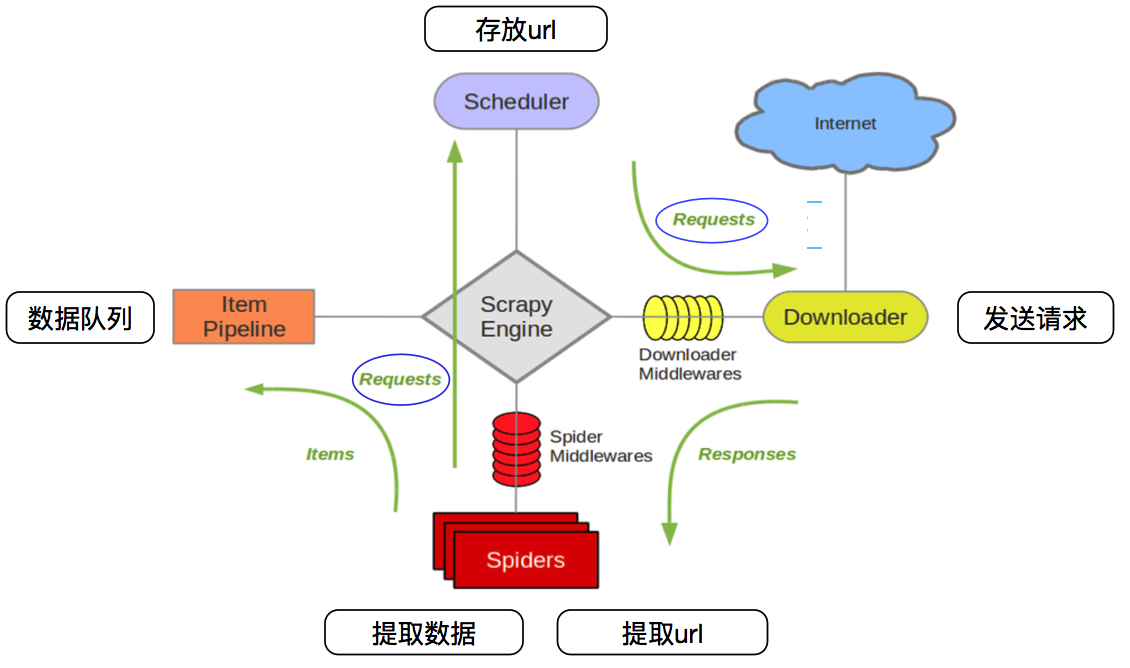
scrapy框架:Scrapy是用纯Python实现一个为了爬取网站数据、提取结构性数据而编写的应用框架,用途非常广泛
框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非常之方便
参考:
作者:changzj
链接:https://www.jianshu.com/p/8e78dfa7c368
来源:简书
(1)使用scrapy框架复现作业①:
main.py:
import scrapy
from ..items import WeaherJpgItem
from scrapy.selector import Selector
class Spider_weatherimages(scrapy.Spider):
name = "main"
start_urls = ["http://www.weather.com.cn/"]
def parse(self, response):
try:
data = response.body.decode()
selector = Selector(text=data)
srclist = selector.xpath("//img/@src").extract() #图片地址
for src in srclist:
item = WeaherJpgItem()
item["jpg"] = [src]
yield item
except Exception as err:
print(err)
Item.py:
import scrapy
class WeaherJpgItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
jpg = scrapy.Field()
pass
settings.py:
BOT_NAME = 'weaher_jpg'
SPIDER_MODULES = ['weaher_jpg.spiders']
NEWSPIDER_MODULE = 'weaher_jpg.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'weaher_jpg (+http://www.yourdomain.com)'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
pipelines.py:
class WeaherJpgPipeline:
def process_item(self, item, spider):
return item
结果: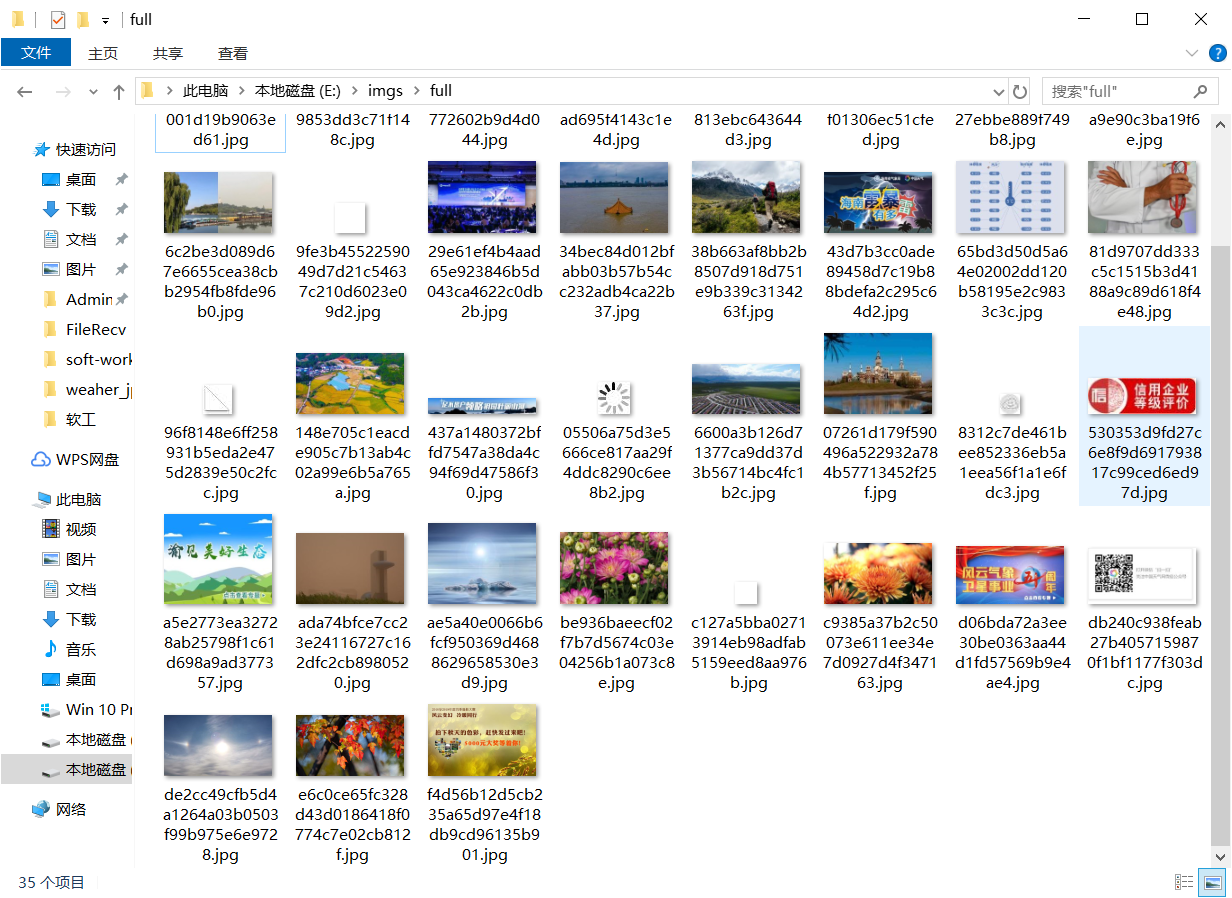
心得:试了好多遍直接运行main.py的话一直提示:ValueError: attempted relative import beyond top-level package
后面查了一下发现原来是:https://blog.csdn.net/suiyueruge1314/article/details/102683546?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-2.edu_weight&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-2.edu_weight
还是看不大懂
(2)使用scrapy框架爬取股票相关信息。
main.py:
import scrapy
import re
import json
from ..items import GupiaoItem
import math
class MainSpider(scrapy.Spider):
name = 'main'
start_urls = ['http://69.push2.eastmoney.com/api/qt/clist/get?cb=jQuery1124034363182413478865_1601433325654&pn=1&pz=60&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&fid=f3&fs=m:0+t:6,m:0+t:13,m:0+t:80,m:1+t:2,m:1+t:23&fields=f2,f3,f4,f5,f6,f7,f12,f14,f15,f16,f17,f18&_=1601433325745']
def parse(self, response):
try:
data = response.body.decode()
datas = re.findall("{.*?}", data[re.search("\[", data).start():])
for i in range(len(datas)):
data_get = json.loads(datas[i]) # 文本解析成json格式
item = GupiaoItem() # 获取相应的变量
item['rank'] = i + 1
item['number'] = data_get['f12']
item['name'] = data_get['f14']
item['price'] = data_get['f2']
item['udRange'] = data_get['f3']
item['udValue'] = data_get['f4']
item['tradeNumber'] = data_get['f5']
item['tradeValue'] = data_get['f6']
item['Range'] = data_get['f7']
item['mmax'] = data_get['f15']
item['mmin'] = data_get['f16']
item['today'] = data_get['f17']
item['yesterday'] = data_get['f18']
yield item
all_page = math.ceil(eval(re.findall('"total":(\d+)', response.body.decode())[0]) / 20) # 获取页数
page = re.findall("pn=(\d+)", response.url)[0] # 当前页数
if int(page) < all_page: # 判断页数
url = response.url.replace("pn=" + page, "pn=" + str(int(page) + 1)) # 跳转下一页
yield scrapy.Request(url=url, callback=self.parse) # 函数回调
except Exception as err:
print(err)
Item.py:
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class GupiaoItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
rank = scrapy.Field()
number = scrapy.Field()
name = scrapy.Field()
price = scrapy.Field()
udRange = scrapy.Field()
udValue = scrapy.Field()
tradeNumber = scrapy.Field()
tradeValue = scrapy.Field()
Range = scrapy.Field()
mmax = scrapy.Field()
mmin = scrapy.Field()
today = scrapy.Field()
yesterday = scrapy.Field()scrapy.Field()
pass
settings.py:
BOT_NAME = 'gupiao'
SPIDER_MODULES = ['gupiao.spiders']
NEWSPIDER_MODULE = 'gupiao.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'gupiao (+http://www.yourdomain.com)'
# Obey robots.txt rules
ROBOTSTXT_OBEY =False
ITEM_PIPELINES = {
'gupiao.pipelines.GupiaoPipeline': 300,
}
pipelines.py:
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
class GupiaoPipeline:
count = 0
r = None
num = 0
def process_item(self, item, spider):
tplt = "{0:^8}\t{1:^4}\t{2:^18}\t{3:^15}\t{4:^6}\t{5:^10}\t{6:^12}\t{7:^12}\t{8:^8}\t{9:^8}\t{10:^5}\t{11:^4}\t{12:^4}"
form = "{0:^10}\t{1:{10}<10}\t{2:{13}<10}\t{3:{13}<10}\t{4:{13}<10}\t{5:{13}<10}\t{6:{13}<10}\t{7:{13}<10}\t" \
"{8:{13}^10}\t{9:{13}<5}\t{10:{13}<5}\t{11:{13}<5}\t{12:{13}<5}"
if GupiaoPipeline.count == 0:
GupiaoPipeline.count += 1
print("打开文件,开始写入数据")
self.r = open("E:/imgs/gupiao.txt", 'w')
self.r.write(tplt.format("序号", "股票代码", "股票名称", "最新报价", "涨跌幅", "涨跌额", "成交量", "成交额", "振幅", "最高", "最低", "今开", "昨收"))
print(tplt.format("序号", "股票代码", "股票名称", "最新报价", "涨跌幅", "涨跌额", "成交量", "成交额", "振幅", "最高", "最低", "今开", "昨收", chr(12288)))
GupiaoPipeline.num += 1
try:
self.r.write((form.format(GupiaoPipeline.num, item['number'], item['name'], item['price'], item['udRange'], item['udValue'],
item['tradeNumber'], item['tradeValue'], item['Range'], item['mmax'], item['mmin'],
item['today'], item['yesterday'], chr(12288))))
self.r.write("\n")
return item
except Exception as err:
print(err)
return item

应该是没开盘,前几次跑都有的。。

