
第二次作业
作业1
实验要求:在中国气象网(http://www.weather.com.cn)给定城市集的7日天气预报,并保存在数据库。
实验代码:
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
import urllib.request
import sqlite3
class WeatherDB:
def openDB(self):
self.con = sqlite3.connect("weathers.db")
self.cursor = self.con.cursor()
try:
self.cursor.execute(
"create table weathers (wCity varchar(16),wDate varchar(16),wWeather varchar(64),wTemp varchar(32),constraint pk_weather primary key (wCity,wDate))")
except:
self.cursor.execute("delete from weathers")
def closeDB(self):
self.con.commit()
self.con.close()
def insert(self, city, date, weather, temp):
try:
self.cursor.execute("insert into weathers (wCity,wDate,wWeather,wTemp) values(?,?,?,?)",
(city, date, weather, temp))
except Exception as err:
print(err)
def show(self):
self.cursor.execute("select * from weathers")
rows = self.cursor.fetchall()
print("%-18s%-20s%-34s%-16s" % ("city", "data", "weather", "temp"))
for row in rows:
print("%-16s%-16s%-32s%-16s" % (row[0], row[1], row[2], row[3]))
class WeatherForecast:
def __init__(self):
self.headers = {
"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US;rv:1.9pre)Gecko/2008072421 Minefield/3.0.2pre"}
self.cityCode = {"北京": "101010100", "上海": "101020100", "广州": "101280101", "深圳": "101280601"}
def forecastCity(self, city):
if city not in self.cityCode.keys():
print(city + "code cannot be found")
return
url = "http://www.weather.com.cn/weather/" + self.cityCode[city] + ".shtml"
try:
req = urllib.request.Request(url, headers=self.headers)
data = urllib.request.urlopen(req)
data = data.read()
dammit = UnicodeDammit(data, ["utf-8", "gbk"])
data = dammit.unicode_markup
soup = BeautifulSoup(data, "lxml")
lis = soup.select("ul[class='t clearfix'] li")
for li in lis:
try:
date = li.select('h1')[0].text
weather = li.select('p[class="wea"]')[0].text
temp = li.select('p[class="tem"] span')[0].text + "/" + li.select('p[class="tem"] i')[0].text
self.db.insert(city, date, weather, temp)
except Exception as err:
pass
except Exception as err:
print(err)
def process(self, cities):
self.db = WeatherDB()
self.db.openDB()
for city in cities:
self.forecastCity(city)
self.db.show()
self.db.closeDB()
ws = WeatherForecast()
ws.process(["北京", "上海", "广州", "深圳"])
运行结果:
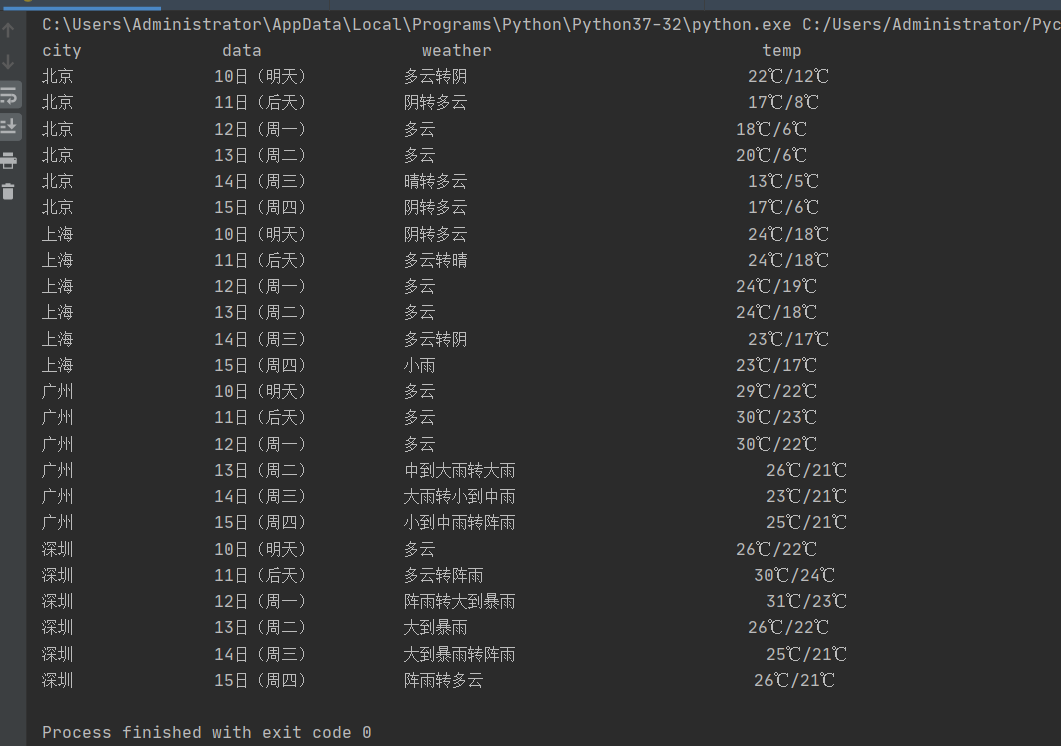
书本代码的实现,尝试了下爬取其他城市,刚开始,直接没输出了,也没什么bug,后面才发现是自己网址写错了..
作业2
要求:用requests和BeautifulSoup库方法定向爬取股票相关信息。
代码:
import requests
import re
# 用get方法访问服务器并提取页面数据
def getHtml(url):
r = requests.get(url)
r.encoding = 'utf-8'
data = re.findall(r'"diff":\[(.*?)]', r.text)
return data
def show(data):
data_one = data[0].strip("{").strip("}").split("},{")
data_get = []
f = 1
tplt = "{0:^8}\t{1:^4}\t{2:^18}\t{3:^15}\t{4:^6}\t{5:^10}\t{6:^12}\t{7:^12}\t{8:^8}\t{9:^8}\t{10:^5}\t{11:^4}\t{12:^4}"
form = "{0:^10}\t{1:{13}<10}\t{2:{13}<10}\t{3:{13}<10}\t{4:{13}<10}\t{5:{13}<10}\t{6:{13}<10}\t{7:{13}<10}\t" \
"{8:{13}^10}\t{9:{13}<5}\t{10:{13}<5}\t{11:{13}<5}\t{12:{13}<5}"
titles = ["序号", "股票代码", "股票名称", "最新报价", "涨跌幅", "涨跌额", "成交量", "成交额", "振幅", "最高", "最低", "今开", "昨收"]
print(tplt.format(titles[0], titles[1], titles[2], titles[3], titles[4], titles[5], titles[6], titles[7], titles[8],
titles[9], titles[10], titles[11], titles[12], chr(12288)))
for data_line in data_one: # 按行处理数据
item = data_line.split(",")
line = [f]
for it in item:
ite = it.split(":")[1]
line.append(ite)
f += 1
data_get.append(line)
print(form.format(line[0], line[7].strip('"'), line[8].strip('"'), line[1], line[2], line[3], line[4], line[5],
line[6], line[9], line[10], line[11], line[12], chr(12288)))
def main():
url = "http://69.push2.eastmoney.com/api/qt/clist/get?cb=jQuery1124034363182413478865_1601433325654&pn=1&pz=60&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&fid=f3&fs=m:0+t:6,m:0+t:13,m:0+t:80,m:1+t:2,m:1+t:23&fields=f2,f3,f4,f5,f6,f7,f12,f14,f15,f16,f17,f18&_=1601433325745"
data = getHtml(url)
show(data)
if __name__ == '__main__':
main()
结果:
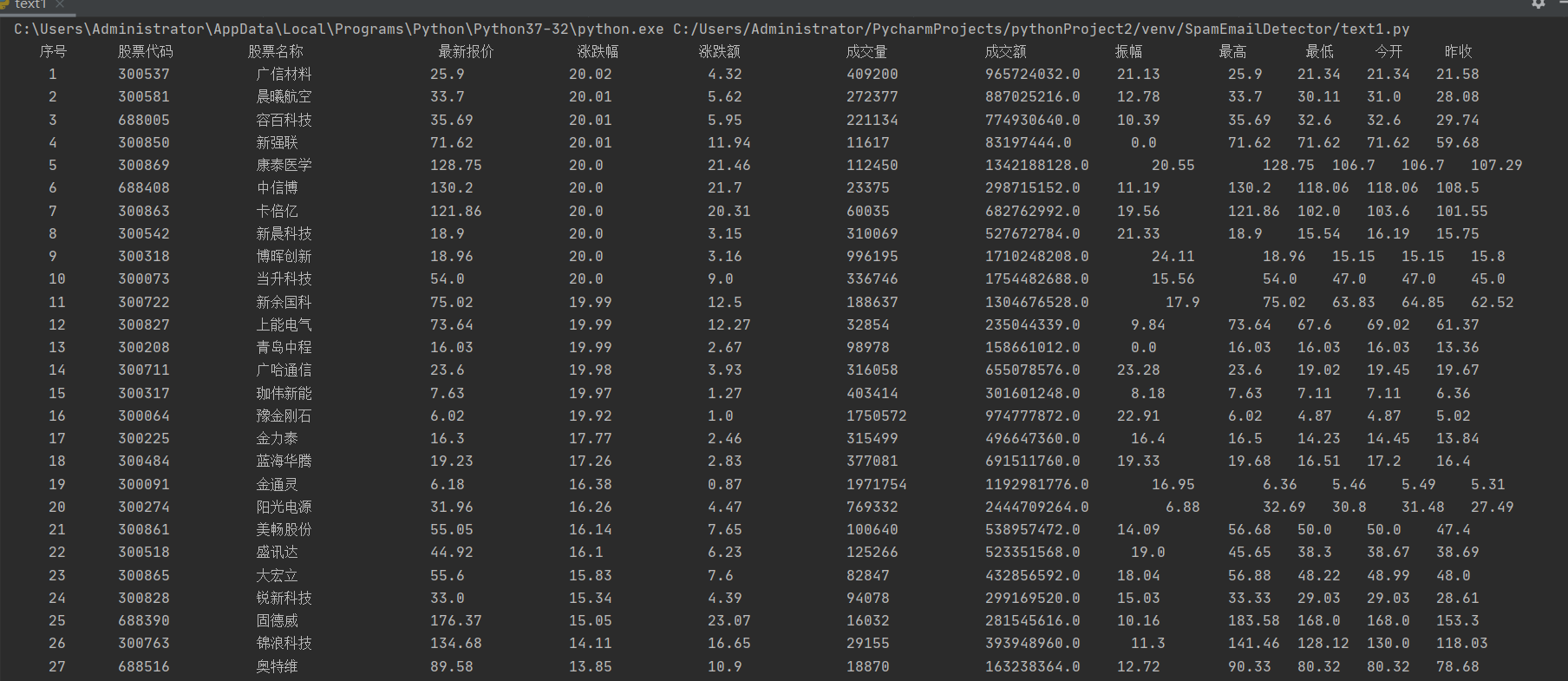
最麻烦的是定位,但根据老师给的那篇知乎上的文章,根据js文件爬取动态刷新的数据 ,感觉上还是比较轻松
作业3
要求:根据自选3位数+学号后3位选取股票,获取印股票信息。
代码:
import requests
import re
#用get方法访问服务器并提取页面数据
def getHtml(url):
r = requests.get(url)
r.encoding='utf-8'
data = re.findall(r'"data":{(.*?)}', r.text)
return data
def main():
share_no = "600133" # 所选股票查询的secid
form = "{0:^10}\t{1:^12}\t{2:^6}\t{3:^20}"
tilt = "{0:^8}\t{1:^8}\t{2:^14}\t{3:^2}"
url = "http://push2.eastmoney.com/api/qt/stock/get?ut=fa5fd1943c7b386f172d6893dbfba10b&invt=2&fltt=2&fields=f43,f57,f58,f169,f170,f46,f44,f51,f168,f47,f164,f163,f116,f60,f45,f52,f50,f48,f167,f117,f71,f161,f49,f530,f135,f136,f137,f138,f139,f141,f142,f144,f145,f147,f148,f140,f143,f146,f149,f55,f62,f162,f92,f173,f104,f105,f84,f85,f183,f184,f185,f186,f187,f188,f189,f190,f191,f192,f107,f111,f86,f177,f78,f110,f262,f263,f264,f267,f268,f250,f251,f252,f253,f254,f255,f256,f257,f258,f266,f269,f270,f271,f273,f274,f275,f127,f199,f128,f193,f196,f194,f195,f197,f80,f280,f281,f282,f284,f285,f286,f287,f292&secid=1.600133&cb=jQuery1124025754728717344966_1602248875285&_=1602248875286=" + share_no + "&cb=jQuery1124025754728717344966_1602248875285=1602248875286"
data = getHtml(url)
titles = ["股票代码", "股票名称", "今日开", "今日最高", "今日最低"]
print(tilt.format(titles[0], titles[1], titles[2], titles[3]))
item = data[0].split(",")
line = []
for it in item:
ite = it.split(":")[1]
line.append(ite)
print(form.format(line[3].strip('"'), line[4].strip('"'), line[2], line[0], line[1]))
if __name__ == '__main__':
main()
结果:
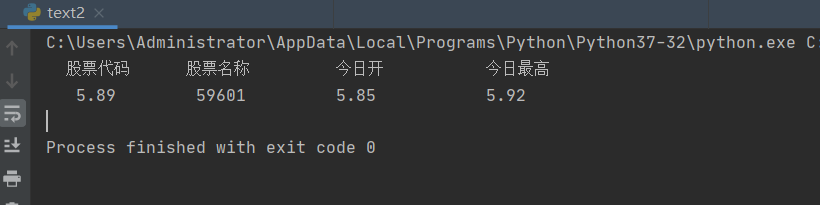
实验心得:刚开始是想在实验二所爬取的信息中遍历寻找有自己后三位学号的股票进行打印的结果却输出这个:
然后发现所爬取的股票信息没有以我学号结尾的股票信息,再改了一个爬取的信息,发现还是这个样子,就直接找了一个后缀为133的股票代码进行爬取
