
小学二年级都能看懂的 KMP算法详解
介绍
先上一道模板题:P3375 【模板】KMP字符串匹配
(难以想象这只是一道黄题) (而manacher竟然是蓝题)
大意就是给你两个字符串,问其中一个在另一个里面出现过几次。至于border什么的,当你写出KMP时,你也就算出来了
为方便理解,提前定义一下:模式串表示被拿去匹配的字符串,而主串则是另一个串。如样例中,模式串为"ABA",主串为"ABABABC"
暴力?
(如果不想看暴力思想的可以直接跳到KMP介绍)
在样例解释中有这么一张图:
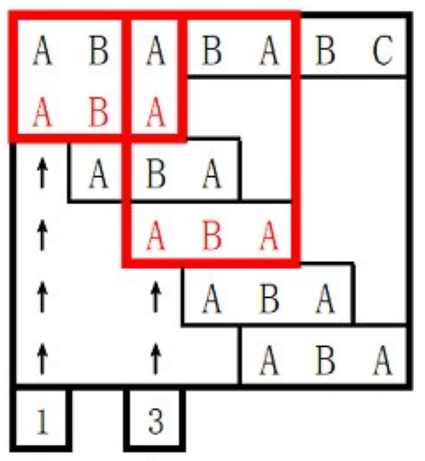
这张图展现的就是最朴素的暴力的过程:我们把模式串放在主串的每一位上,看看能不能匹配上。
具体实现就是维护两个指针:
假设模式串长度为
考虑优化:我们发现,第一次匹配完成之后,由于我们已知模式串第一位的A与主串第二位的B压根就不匹配,我们大可以直接跳过第二位,直接把模式串放在第三位上开始匹配。换言之,我们每一次在主串的
比如模式串"ACBCA"和主串"ACBCBCA",我们会在第五位 "A" 和 "B" 处匹配失败,这时候我们把上一位 "C" 上一次出现的位置拎过来,并继续匹配。等于在匹配"ACBCA"和"BCBCA"。
但是这么做有个问题:如果从 "C" 处开始往后匹配,我们会得到"ACBCA"与"BCBCA"能够匹配的错误答案。从开头处开始匹配,等于说每一次匹配失败又要从头开始匹配,稍微卡一卡数据(比如一串a),时间复杂度又退化成
看起来这个"拎过来"的思想可以继续优化,那么,我们有没有一种办法,可以使字符串不从头匹配的同时,还能精准“拎”到正确的位置呢?
过不去那道题?
事实:它数据很大
而暴力是
它最慢了!
介绍——KMP!
我们看这么一个例子:模式串 "ABBABA" 和主串 "ABBABBABA",用
显然,我们这时候会在
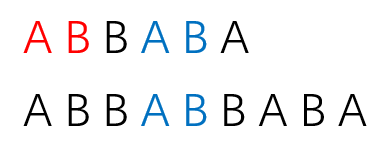
我们不难发现:对于每一个
我们可以用
我们用
第一种情况:

这时候就很愉快,直接让
第二种情况:

这时候该怎么办呢?可以发现:我们在求
kmp的核心思想就这些了,代码如下:
n=s1.size(),m=s2.size(); for(int i=1,j=0;i<m;i++){ while(j>0&&s2[i]!=s2[j]) j=nxt[j-1]; if(s2[i]==s2[j]) j++; nxt[i]=j; } for(int i=0,j=0;i<=n;){ if(j==m) j=nxt[j-1]; //此时匹配结束,也就相当于在这位匹配失败了,所以j=nxt[j-1] if(s1[i]==s2[j]) i++,j++; else if(j!=0) j=nxt[j-1]; else i++; }


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 地球OL攻略 —— 某应届生求职总结
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 提示词工程——AI应用必不可少的技术
· .NET周刊【3月第1期 2025-03-02】