

更多的bash shell命令
更多的bash shell命令
1. 监测程序
对Linux系统管理员而言,最难缠的一项任务是跟踪运行在系统中的程序,尤其是现在,图形化桌面集成了大量的程序来生成一个完整的桌面环境。系统中始终运行着大量的程序。
1.1 探查进程 ps
当程序在系统中运行时,它被称为进程(process)。要想监测这些进程,必须熟悉 ps 命令的用法。ps 命令堪比工具中的瑞士军刀,能够输出系统中运行的所有程序的大量信息。
在默认情况下,ps命令并没有提供太多的信息:
[root@Wesuiliye ~]# ps PID TTY TIME CMD 9638 pts/1 00:00:00 bash 9932 pts/1 00:00:00 ps
也没什么特别之处。ps命令默认只显示运行在当前终端中属于当前用户的那些进程。在这个例子中,只有bash shell在运行(记住,shell只是运行在系统中的另一个程序而已),当然ps命令本身也在运行。
ps命令的基本输出显示了程序的进程ID(process ID,PID)、进程运行在哪个终端(TTY)及其占用的CPU时间。
注意 ps命令令人头疼的地方(也正是它如此复杂的原因)在于它曾经有两个版本。每个版本都有自己的一套命令行选项,控制着显示哪些信息以及如何显示。最近,Linux开发人员已经将这两种ps命令格式合并到单个ps命令中(当然,同时也加入了他们自己的风格)。
Linux系统中使用的GNU ps命令支持以下3种类型的命令行选项:
·Unix风格选项,选项前加单连字符;
·BSD 风格选项,选项前不加连字符;
·GNU 长选项,选项前加双连字符。
1.Unix风格选项
Unix风格选项源自贝尔实验室开发的AT&T Unix系统中的ps命令。
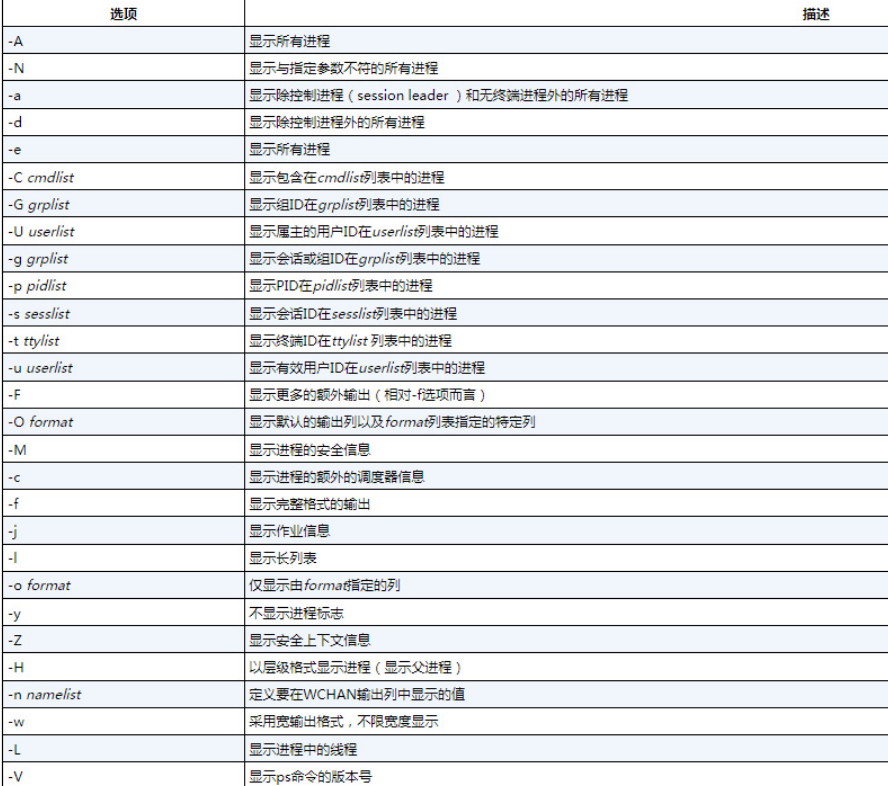
上面的选项已经不少了,但没列出的还有很多。
使用ps命令的关键不在于记住所有可用的选项,而在于记住对你来说最有用的那些。
大多数Linux系统管理员会牢记自己的一组常用选项,以用来提取有用的进程信息。
如果需要查看系统中运行的所有进程,可以使用 -ef 选项(显示所有进程并按完整格式输出)组合(ps命令允许像这样把选项合并在一起)。
[root@Wesuiliye ~]# ps -ef | head UID PID PPID C STIME TTY TIME CMD root 1 0 0 Apr09 ? 00:00:06 /usr/lib/systemd/systemd --switched-root --system --deserialize 22 root 2 0 0 Apr09 ? 00:00:00 [kthreadd] root 4 2 0 Apr09 ? 00:00:00 [kworker/0:0H] root 6 2 0 Apr09 ? 00:00:19 [ksoftirqd/0] root 7 2 0 Apr09 ? 00:00:00 [migration/0] root 8 2 0 Apr09 ? 00:00:00 [rcu_bh] root 9 2 0 Apr09 ? 00:04:31 [rcu_sched] root 10 2 0 Apr09 ? 00:00:00 [lru-add-drain] root 11 2 0 Apr09 ? 00:00:02 [watchdog/0]
-e选项指定显示系统中运行的所有进程;-f选项则扩充输出内容以显示一些有用的信息列。
·UID:启动该进程的用户。
·PID:进程ID。
·PPID:父进程的PID(如果该进程是由另一个进程启动的)。
·C:进程生命期中的CPU利用率。
·STIME:进程启动时的系统时间。
·TTY:进程是从哪个终端设备启动的。
·TIME:运行进程的累计CPU时间。
·CMD:启动的程序名称。
如果还想获得更多的信息,可以使用-l选项,产生长格式输出。
[root@Wesuiliye ~]# ps -l F S UID PID PPID C PRI NI ADDR SZ WCHAN TTY TIME CMD 4 S 0 9638 9634 0 80 0 - 29223 do_wai pts/1 00:00:00 bash 0 R 0 10149 9638 0 80 0 - 38332 - pts/1 00:00:00 ps
注意使用了-l选项之后多出的那几列。
·F:内核分配给进程的系统标志。
·S:进程的状态
O代表正在运行;
S代表在休眠;
R代表可运行,正等待运行;
Z代表僵化,已终止但找不到其父进程;
T代表停止
·PRI:进程的优先级(数字越大,优先级越低)。
·NI:谦让度(nice),用于决定优先级。
·ADDR:进程的内存地址。
·SZ:进程被换出时所需交换空间的大致大小。
·WCHAN:进程休眠的内核函数地址。
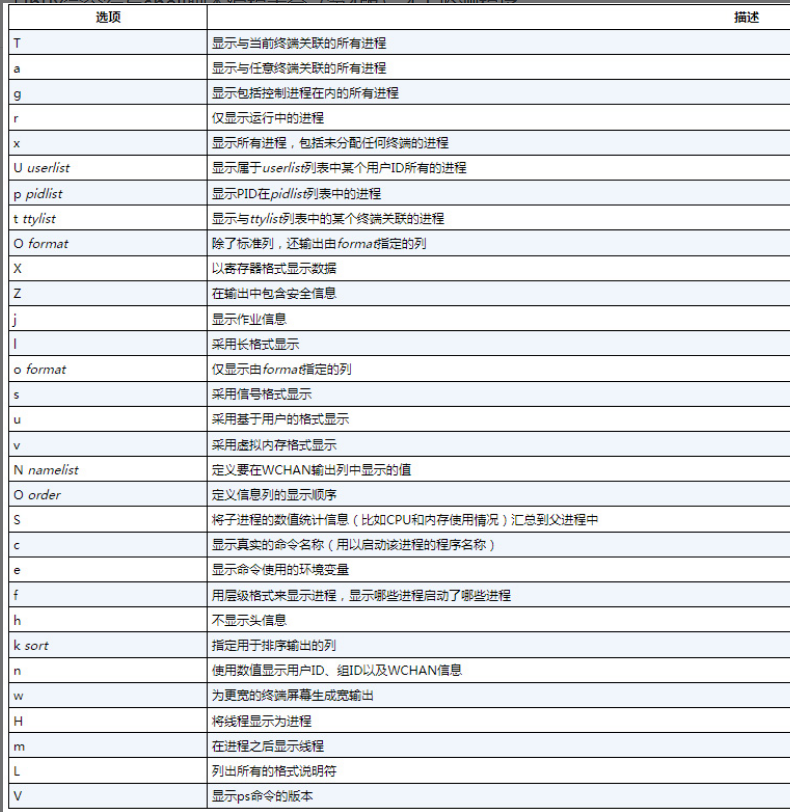
2.BSD风格选项
伯克利软件发行版(Berkeley Software Distribution,BSD)是加州大学伯克利分校开发的一个Unix版本。BSD与AT&T Unix系统有许多细微的差别,由此引发了多年来的诸多Unix纷争。
在使用BSD风格的选项时,ps命令会自动改变输出以模仿BSD格式。
[root@Wesuiliye ~]# ps l F UID PID PPID PRI NI VSZ RSS WCHAN STAT TTY TIME COMMAND 4 0 2505 1 20 0 110208 872 n_tty_ Ss+ ttyS0 0:00 /sbin/agetty --keep-baud 115200,38400,9600 ttyS0 vt220 4 0 2515 2503 20 0 319680 18172 ep_pol Ssl+ tty1 0:00 /usr/bin/X :0 -background none -noreset -audit 4 -verbose 4 0 9638 9634 20 0 116892 3440 do_wai Ss pts/1 0:00 -bash 0 0 10224 9638 20 0 153328 1524 - R+ pts/1 0:00 ps l
注意,尽管上述很多输出列跟使用Unix风格选项时是一样的,但还是有一些不同之处。
·VSZ:进程占用的虚拟内存大小(以KB为单位)。
·RSS:进程在未被交换出时占用的物理内存大小。
·STAT:代表当前进程状态的多字符状态码。
多字符状态码能比Unix风格输出的单字符状态码更清楚地表明进程的当前状态。
第一个字符采用了与Unix风格的S输出列相同的值,表明进程是在休眠、运行还是等待。第二个字符进一步说明 了进程的状态。
·<:该进程以高优先级运行。
·N:该进程以低优先级运行。
·L:该进程有锁定在内存中的页面。
·s:该进程是控制进程。
·l:该进程拥有多线程。
·+:该进程在前台运行。
从先前展示的简单例子中可以看出,bash命令处于休眠状态,但同时它也是一个控制进程(会话中的主进程),而ps命令则运行在系统前台。
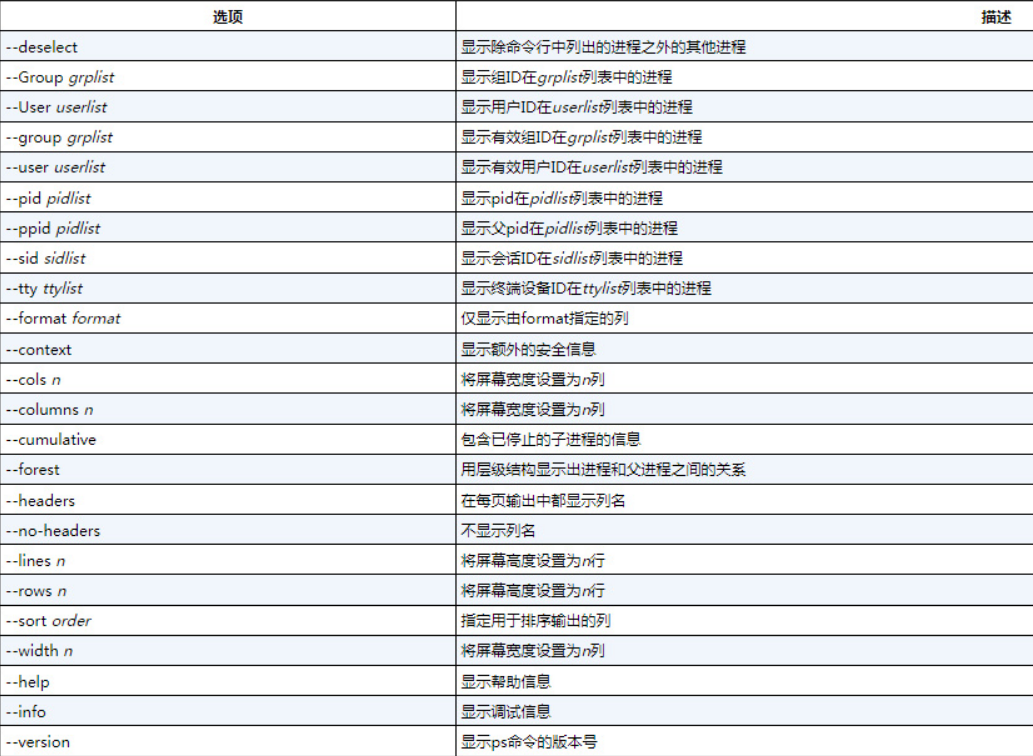
3.GNU长选项
GNU开发人员在经过改进的新ps命令中加入了另外一些选项,其中一些GNU长选项复制了现有的Unix或BSD风格选项的效果,而另外一些则提供了新功能。
可以混用GNU长选项和Unix或BSD风格的选项来定制输出。作为一个GNU长选项,--forest选项着实讨人喜欢。该选项能够使用ASCII字符来绘制可爱的图表以显示进程的层级信息:
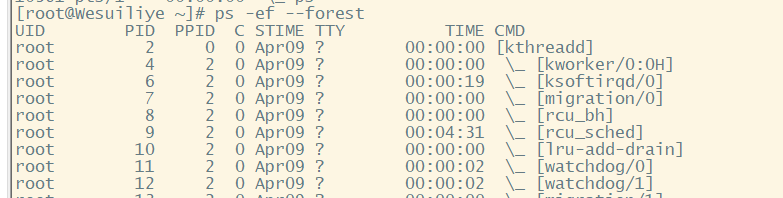
这种格式可以轻而易举地跟踪子进程和父进程。
1.2 实时监测进程 top
ps命令虽然在收集系统中运行进程的信息时非常有用,但也存在不足之处:只能显示某个特定时间点的信息。如果想观察那些被频繁换入和换出内存的进程,ps命令就不太方便了。
这正是top命令的用武之地。与ps命令相似,top命令也可以显示进程信息,但采用的是实时方式。
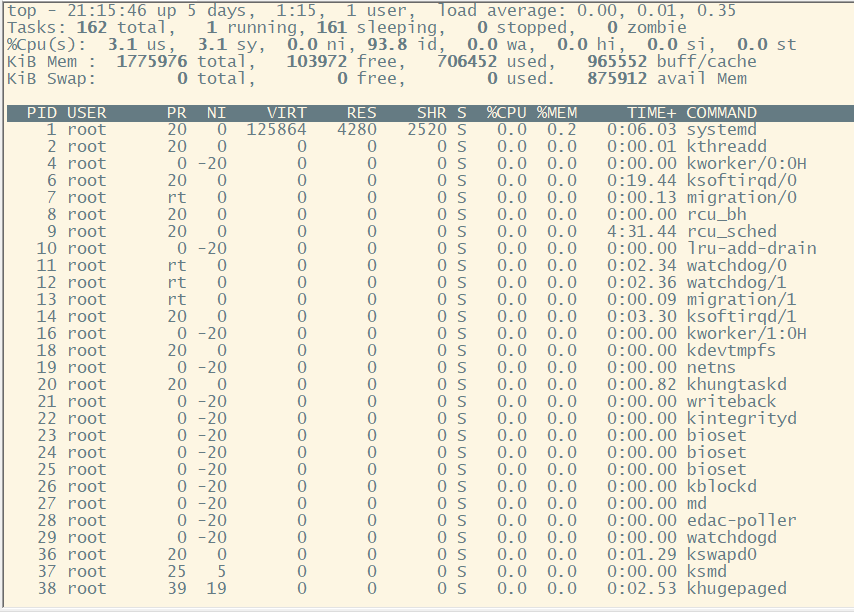
输出的第一部分显示的是系统概况:
top - 21:19:49 up 5 days, 1:19, 1 user, load average: 0.00, 0.01, 0.27
第一行显示了当前时间、系统的运行时长、登录的用户数以及系统的平均负载。
平均负载有3个值,分别是最近1分钟、最近5分钟和最近15分钟的平均负载。
值越大说明系统的负载越高。由于进程短期的突发性活动,出现最近1分钟的高负载值也很常见。
但如果近15分钟内的平均负载都很高,就说明系统可能有问题了。
注意 Linux系统管理的难点在于定义究竟到什么程度才算是高负载。这个值取决于系统的硬件配置以及系统中通常运行的程序。某个系统的高负载可能对其他系统来说就是普通水平。最好的做法是注意在正常情况下系统的负载情况,这样将更容易判断系统何时负载不足。
Tasks: 162 total, 1 running, 161 sleeping, 0 stopped, 0 zombie
第二行显示了进程(top称其为task)概况:多少进程处于运行、休眠、停止以及僵化状态(僵化状态指进程已结束,但其父进程没有响应)。
%Cpu(s): 0.7 us, 0.8 sy, 0.0 ni, 98.5 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
下一行显示了CPU概况。top会根据进程的属主(用户或是系统)和进程的状态(运行、空闲或等待)将CPU利用率分成几类输出。
0.7 us【user space】— 用户空间占用CPU的百分比。
0.8 sy【sysctl】— 内核空间占用CPU的百分比。
0.0 ni【】— 改变过优先级的进程占用CPU的百分比
98.5 id【idolt】— 空闲CPU百分比
0.0 wa【wait】— IO等待占用CPU的百分比
0.0 hi【Hardware IRQ】— 硬中断占用CPU的百分比
0.0 si【Software Interrupts】— 软中断占用CPU的百分比
0.0 st 实时
KiB Mem : 1775976 total, 100864 free, 708840 used, 966272 buff/cache KiB Swap: 0 total, 0 free, 0 used. 873524 avail Mem
紧跟其后的两行详细说明了系统内存的状态。前一行显示了系统的物理内存状态:总共有多少内存、当前多少空闲,以及用了多少。后一行显示了系统交换空间(如果分配了的话)的状态。
buff/cache 缓存的内存量
avail Mem 缓冲的交换区总量
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
最后一部分显示了当前处于运行状态的进程的详细列表,有些列跟ps命令的输出类似。
·PID:进程的PID。
·USER:进程属主的用户名。
·PR:进程的优先级。
·NI:进程的谦让度。
·VIRT:进程占用的虚拟内存总量。
·RES:进程占用的物理内存总量。
·SHR:进程和其他进程共享的内存总量。
·S:进程的状态(D代表可中断的休眠,R代表运行,S代表休眠,T代表被跟踪或停止,Z代表僵化)。
·%CPU:进程使用的CPU时间比例。
·%MEM:进程使用的可用物理内存比例。
·TIME+:自进程启动到目前为止所占用的CPU时间总量。
·COMMAND:进程所对应的命令行名称,也就是启动的程序名。
其他使用技巧
1.多U多核CPU监控
在top基本视图中,按键盘数字“1”,可监控每个逻辑CPU的状况:逻辑上有2个,实际中只有1个,参见上下图

2.高亮显示当前运行进程
敲击键盘“b”(打开/关闭加亮效果),top的视图变化如下:
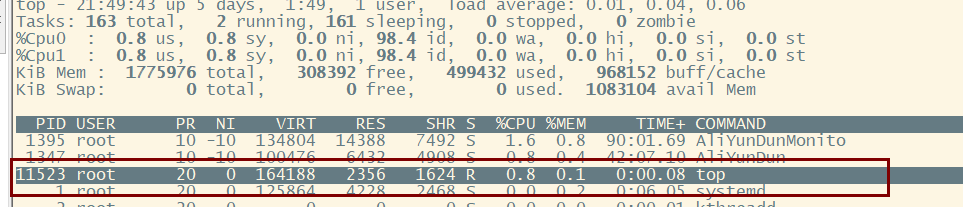
我们发现进程id为11523的“top”进程被加亮了,top进程就是视图第二行显示的唯一的运行态(runing)的那个进程,可以通过敲击“y”键关闭或打开运行态进程的加亮效果。
3.进程字段排序
在默认情况下,top命令在启动时会按照%CPU值来对进程进行排序.
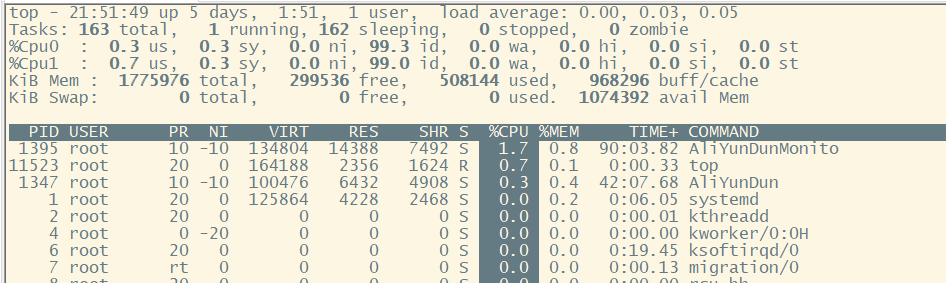 敲击键盘“x”(打开/关闭排序列的加亮效果)
敲击键盘“x”(打开/关闭排序列的加亮效果)
4.通过”shift + >”或”shift + <”可以向右或左改变排序列
按一次”shift + >”的效果图,视图现在已经按照%MEM来排序,再按一次按时间排
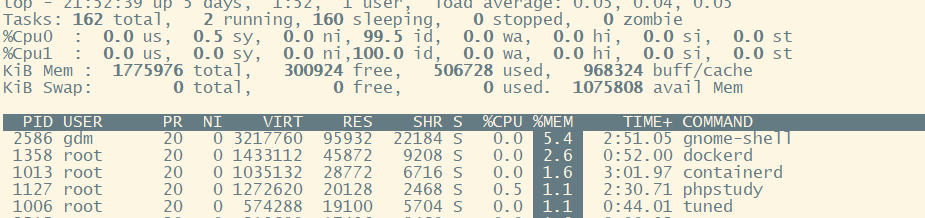
5.top交互命令
每个交互式命令都是单字符,在top命令运行时键入可改变top的行为。
h 显示帮助画面,给出一些简短的命令总结说明 k 终止一个进程。 i 忽略闲置和僵死进程。这是一个开关式命令。 q 退出程序 r 重新安排一个进程的优先级别 S 切换到累计模式 s 改变两次刷新之间的延迟时间(单位为s f或者F 从当前显示中添加或者删除项目 o或者O 使用 o 命令实现的过滤器是对数据忽略大小写的。使用 O 命令实现的过滤器对大小写敏感 l 切换显示平均负载和启动时间信息 m 切换显示内存信息 t 切换显示进程和CPU状态信息 c 切换显示命令名称和完整命令行 M 根据驻留内存大小进行排序 P 根据CPU使用百分比大小进行排序 T 根据时间/累计时间进行排序 W 将当前设置写入~/.toprc文件中
1.3 结束进程
身为系统管理员,所需掌握的一项关键技能是知道何时以及如何结束一个进程。有时候,进程会被挂起,此时只需动动手让进程重新运行或结束就行了。有时候,进程会霸占着CPU且拒绝让出。在这两种情景下,都需要能够控制进程的命令。Linux沿用了Unix的进程间通信方法。
在Linux中,进程之间通过信号来通信。进程的信号是预定义好的一个消息,进程能识别该消息并决定忽略还是做出反应。进程如何处理信号是由开发人员通过编程来决定的。大多数编写完善的应用程序能接收和处理标准Unix进程信号。
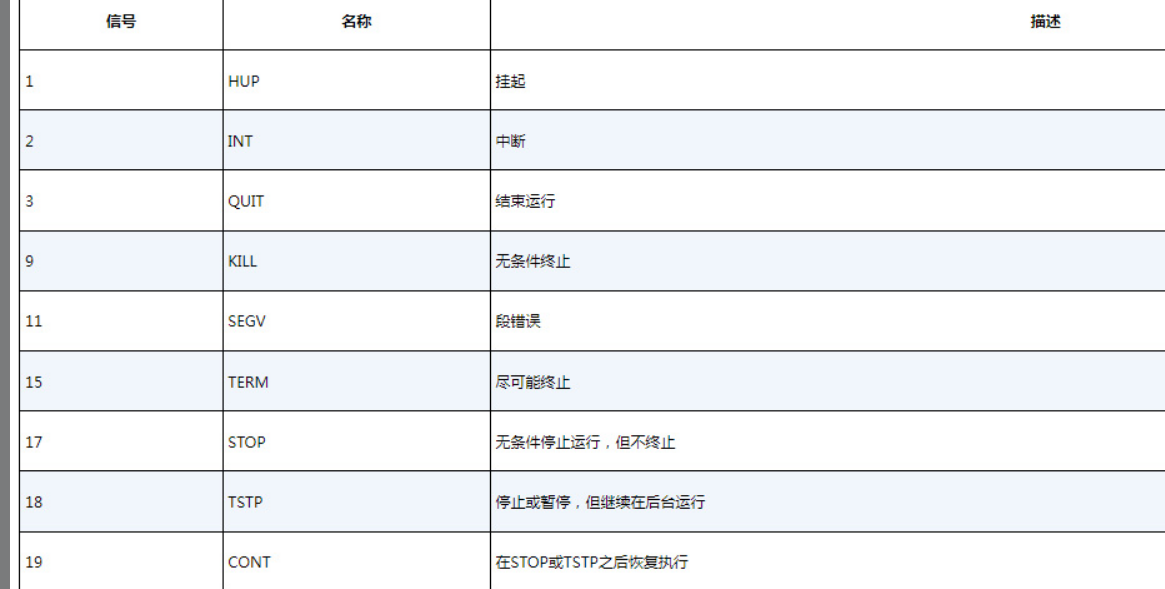
在Linux中有两个命令可以向运行中的进程发出进程信号:kill和pkill。
1.kill命令
kill命令可以通过PID向进程发送信号。
在默认情况下,kill命令会向命令行中列出的所有PID发送TERM信号。
遗憾的是,你只能使用进程的PID而不能使用其对应的程序名,这使得kill命令有时并不好用。
要发送进程信号,必须是进程的属主或root用户:
[root@Wesuiliye ~]# kill 12345 -bash: kill: (12345) - Operation not permitted
TERM信号会告诉进程终止运行。但不服管教的进程通常会忽略这个请求。
如果要强制终止,则-s选项支持指定其他信号(用信号名或信号值)。
[root@Wesuiliye ~]# kill -s HUP 588
-HUP参数来发送挂断信号,系统会重启进程进行复位操作重新读取配置文件
2.pkill命令
pkill命令可以使用程序名代替PID来终止进程,这就方便多了。
除此之外,pkill命令也允许使用通配符,当系统出问题时,这是一个非常有用的工具:
[root@Wesuiliye ~]# pkill http*
该命令将“杀死”所有名称以http起始的进程,比如Apahce Web Server的httpd服务。
警告 以root身份使用pkill命令时要格外小心。命令中的通配符很容易意外地将系统的重要进程终止。这可能会导致文件系统损坏。
2. 监测磁盘空间
系统管理员的另一项重要任务是监测系统磁盘的使用情况。不管运行的是简单的Linux桌面还是大型的Linux服务器,你都需要知道还有多少磁盘空间可供应用程序使用。
2.1 挂载存储设备
Linux文件系统会将所有的磁盘都并入单个虚拟目录。
在使用新的存储设备之前,需要将其放在虚拟目录中。这项工作称为挂载(mounting)。
在今天的图形化桌面环境中,大多数Linux发行版能自动挂载特定类型的可移动存储设备。所谓可移动存储设备(显然)指的是那种可以从PC中轻易移除的媒介,比如DVD和U盘。
如果你使用的发行版不支持自动挂载和卸载可移动存储设备,则只能手动操作了。
1.mount命令
用于挂载存储设备的命令叫作mount。
在默认情况下,mount命令会输出当前系统已挂载的设备列表。
也可以使用命令:
cat /proc/mounts
但是,除了标准存储设备,较新版本的内核还会挂载大量用作管理目的的虚拟文件系统。
这使得mount命令的默认输出非常杂乱,让人摸不着头脑。
如果知道设备分区使用的文件系统类型,可以像下面这样过滤输出。
[root@Wesuiliye ~]# mount -t ext4 /dev/vda1 on / type ext4 (rw,relatime,data=ordered)
-t vsftype:指定要挂载的设备上的文件系统类型;
mount命令提供了4部分信息。
·设备文件名
·设备在虚拟目录中的挂载点
·文件系统类型
·已挂载设备的访问状态
要手动在虚拟目录中挂载设备,需要以root用户身份登录,或是以root用户身份运行sudo命令。
下面是手动挂载设备的基本命令:
mount [-t vfstype] [-o options] device dir
其中,vfstype参数指定了磁盘格式化所使用的文件系统类型。Linux可以识别多种文件系统类型。如果与Windows PC共用移动存储设备,那么通常需要使用下列文件系统类型。
·vfat:Windows FAT32文件系统,支持长文件名。
·ntfs:Windows NT及后续操作系统中广泛使用的高级文件系统。
·exfat:专门为可移动存储设备优化的Windows文件系统。
·iso9660:标准CD-ROM和DVD文件系统。
大多数U盘会使用vfat文件系统格式化。如果需要挂载数据CD或DVD,则必须使用iso9660文件系统类型。
-o选项允许在挂载文件系统时添加一系列以逗号分隔的额外选项。常用选项如下。
·ro:以只读形式挂载。
·rw:以读写形式挂载。
·user:允许普通用户挂载该文件系统。
·check=none:挂载文件系统时不执行完整性校验。
·loop:挂载文件。
后面两个参数指定了该存储设备的设备文件位置以及挂载点在虚拟目录中的位置。
例如,手动将U盘/dev/sdb1挂载到/media/disk,可以使用下列命令:
mount -t vfat /dev/sdb1 /media/disk
一旦存储设备被挂载到虚拟目录,root用户就拥有了对该设备的所有访问权限,而其他用户的访问则会被限制。可以通过目录权限指定用户对设备的访问权限。
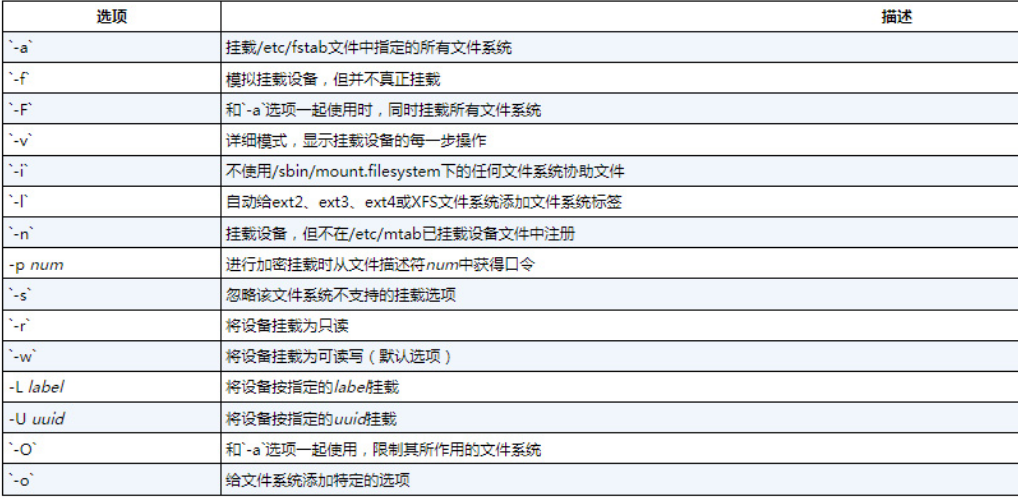
如果需要使用mount命令的一些高级特性,可以参见表中列出的相关选项。
2.umount命令
移除可移动设备时,不能直接将设备拔下,应该先卸载。
提示 Linux不允许直接弹出已挂载的CD或DVD。如果在从光驱中移除CD或DVD时遇到麻烦,那么最大的可能是它还在虚拟目录中挂载着。应该先卸载,然后再尝试弹出。
umount命令的格式非常简单:
umount [directory | device ]
umount命令支持通过设备文件或者挂载点来指定要卸载的设备。如果有任何程序正在使用设备上的文件,则系统将不允许卸载该设备。
# umount /home/rich/mnt umount: /home/rich/mnt: device is busy umount: /home/rich/mnt: device is busy # cd /home/rich # umount /home/rich/mnt # ls -l mnt total 0 #
在本例中,因为命令行提示符仍然位于已挂载设备的文件系统中,所以umount命令无法卸载该镜像文件。一旦命令提示符移出其镜像文件系统,umount命令就能成功卸载镜像文件了。
如果在卸载设备时,系统提示设备繁忙,无法卸载,那么通常是有进程还在访问该设备或使用该设备上的文件。这时可用Isof命令获得相关进程的信息,然后将进程终止。
2.2 使用df命令
有时需要知道在某台设备上还有多少磁盘空间。df命令可以方便地查看所有已挂载磁盘的使用情况:
[root@Wesuiliye ~]# df -t ext4 Filesystem 1K-blocks Used Available Use% Mounted on /dev/vda1 41152812 14016140 25232964 36% /
df命令会逐个显示已挂载的文件系统。与mount命令类似,df命令会输出内核挂载的所有虚拟文件系统,因此可以使用-t选项来指定文件系统类型,进而过滤输出结果。该命令的输出如下。
·设备文件位置
·包含多少以1024字节为单位的块
·使用了多少以1024字节为单位的块
·还有多少以1024字节为单位的块可用
·已用空间所占的百分比
·设备挂载点
df命令的大部分选项你根本不会用到。常用选项之一是-h,该选项会以人类易读(human-readable)的形式显示磁盘空间,通常用M来替代兆字节,用G来替代吉字节:
[root@Wesuiliye ~]# df -h -t ext4 Filesystem Size Used Avail Use% Mounted on /dev/vda1 40G 14G 25G 36% /
注意 记住,Linux系统后台一直有进程在处理文件。df命令的出值反映的是Linux系统认为的当前值。正在运行的进程有可能创建或删除了某个文件,但尚未释放该文件。这个值是不会被计算进闲置空间的。
2.3 使用du命令
通过df命令,很容易发现哪个磁盘存储空间不足。系统管理员面临的下一个问题是如何应对这种情况。
另一个能助你一臂之力的是du命令。du命令可以显示某个特定目录(默认情况下是当前目录)的磁盘使用情况。这有助于你快速判断系统中是否存在磁盘占用“大户”。
在默认情况下,du命令会显示当前目录下所有的文件、目录和子目录的磁盘使用情况,并以磁盘块为单位来表明每个文件或目录占用了多大存储空间。对标准大小的目录来说,输出内容可不少。下面是du命令的部分输出:
[root@Wesuiliye ~]# du 4 ./New_dir 8 ./.cache/pip/selfcheck 20 ./.cache/pip/http/c/f/d/1/5 24 ./.cache/pip/http/c/f/d/1 28 ./.cache/pip/http/c/f/d 32 ./.cache/pip/http/c/f 48 ./.cache/pip/http/c/7/7/7/a 52 ./.cache/pip/http/c/7/7/7 56 ./.cache/pip/http/c/7/7 60 ./.cache/pip/http/c/7 96 ./.cache/pip/http/c
每行最左侧的数字是每个文件或目录所占用的磁盘块数。注意,这个列表是从目录层级的最底部开始,然后沿着其中包含的文件和子目录逐级向上的。
单纯的du命令作用并不大。我们更想知道每个文件和目录各占用了多大的磁盘空间,但如果还需逐页翻找的话就没什么意义了。
下面这些选项能让du命令的输出更加清晰易读。
·-c:显示所有已列出文件的总大小。
·-h:按人类易读格式输出大小,分别用K表示千字节、M表示兆字节、G表示吉字节。
·-s:输出每个参数的汇总信息。
例子:
查看root下面的文件所占磁盘空间大小
[root@Wesuiliye ~]# du -h /root 4.0K /root/New_dir 8.0K /root/.cache/pip/selfcheck 20K /root/.cache/pip/http/c/f/d/1/5 24K /root/.cache/pip/http/c/f/d/1 28K /root/.cache/pip/http/c/f/d 32K /root/.cache/pip/http/c/f
3. 处理数据文件
当有大量数据时,处理这些数据并从中提取有用信息通常不是件容易事。通过上一节的du命令可知,系统命令很容易输出让人难以招架的过量信息。
Linux系统提供了一些可以帮助你管理大量数据的命令行工具。
3.1 数据排序sort
处理大量数据时的一个常用命令是sort。顾名思义,这是用来对数据进行排序的命令。
在默认情况下,sort命令会依据会话所指定的默认语言的排序规则来对文本文件中的数据行进行排序:
[root@Wesuiliye ~]# cat test hello,world1 h1ello,world2 hello,world10 hello,world10 hello,world10 hello,world10 123 [root@Wesuiliye ~]# sort test 123 h1ello,world2 hello,world1 hello,world10 hello,world10 hello,world10 hello,world10
非常简单。但事情往往并不像看起来那么简单。来看下面这个例子:
[root@Wesuiliye ~]# cat num 123 412 44 1 4 24 [root@Wesuiliye ~]# sort num 1 123 24 4 412 44
如果希望这些数字按值排序,那你就要失望了。在默认情况下,sort命令会将数字视为字符并执行标准的字符排序,这种结果可能不是你想要的。可以使用-n选项来解决这个问题,该选项会告诉sort命令将数字按值排序:
[root@Wesuiliye ~]# sort -n num 1 4 24 44 123 412
现在好多了。另一个常用的选项是-M,该选择可以将数字按月排序。Linux的日志文件经常在每行的起始位置有一个时间戳,以表明事件是什么时候发生的:
Apr 13 07:10:09 testbox smartd[2718]: Device: /dev/sda, opened
如果将含有时间戳日期的文件按默认的排序方法来排序,则会得到如下结果:
[root@Wesuiliye ~]# sort file3 Apr Aug Dec Feb Jan Jul Jun Mar May Nov Oct Sep
这并不是你想要的结果。如果加入-M选项,那么sort命令就能识别三字符的月份名并正确排序。
[root@Wesuiliye ~]# sort -M file3 Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec
sort命令选项
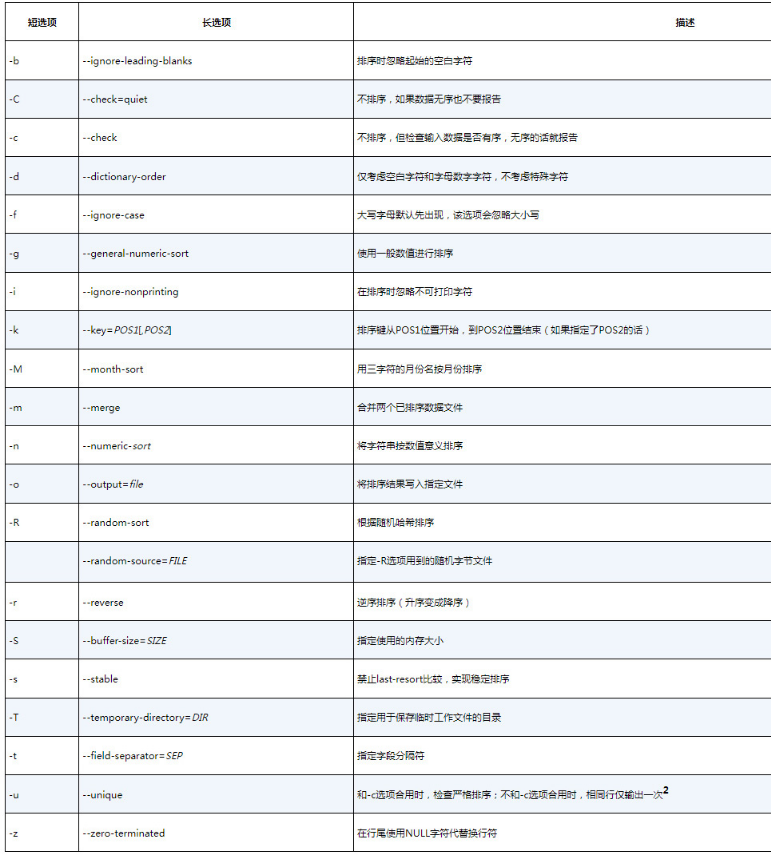
在对按字段分隔的数据(比如/etc/passwd文件)进行排序时,-k选项和-t选项非常方便。先使用-t选项指定字段分隔符,然后使用-k选项指定排序字段。例如,要根据用户ID对/etc/passwd按数值排序,可以这么做:
[root@Wesuiliye ~]# sort -t ':' -k 3 -n /etc/passwd root:x:0:0:root:/root:/bin/bash bin:x:1:1:bin:/bin:/sbin/nologin daemon:x:2:2:daemon:/sbin:/sbin/nologin adm:x:3:4:adm:/var/adm:/sbin/nologin lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
现在数据已经按第三个字段(用户ID的数值)排序妥当了。
-n选项适合于排序数值型输出,比如du命令的输出:
[root@Wesuiliye ~]# du -sh * | sort -nr 4.0K test2 4.0K test 4.0K num 4.0K New_dir 4.0K file3 0 test_2 0 test_1
注意,-r选项对数值按照降序排列,这样便能轻而易举地看出目录中的哪些文件占用磁盘空间最多。
注意 本例中的管道命令(|)用于将du命令的出传入sort命令
3.2 数据搜索
你经常需要在大文件中查找位于文件中间部分某处的数据行。与其手动翻找整个文件,不如使用grep命令来帮助查找。grep命令的格式如下:
grep [options] pattern [file]
grep命令会在输入或指定文件中逐行搜索匹配指定模式的文本。
该命令的输出是包含了匹配模式的行。
下面的例子演示了使用grep命令:
[root@Wesuiliye ~]# grep hello test hello,world1 hello,world10 hello,world10 hello,world10 hello,world10
如果要进行反向搜索(输出不匹配指定模式的行),可以使用-v选项:
[root@Wesuiliye ~]# grep -v hello test h1ello,world2 123
如果要显示匹配指定模式的那些行的行号,可以使用-n选项:
[root@Wesuiliye ~]# grep -vn hello test 2:h1ello,world2 7:123
如果只想知道有多少行含有匹配的模式,可以使用-c选项:
[root@Wesuiliye ~]# grep -vc hello test 2
如果要指定多个匹配模式,可以使用-e选项来逐个指定:
[root@Wesuiliye ~]# grep -e a -e b file3 Feb Jan Mar May
在默认情况下,grep命令使用基本的Unix风格正则表达式来匹配模式。
Unix风格正则表达式使用特殊字符来定义如何查找匹配模式。
[root@Wesuiliye ~]# grep [ta] file3 Jan Mar May Oct
正则表达式中的方括号表明grep应该搜索包含t字符或者a字符的匹配。如果不用正则表达式,则grep搜索的是匹配字符串ta的文本。
egrep命令是grep的一个衍生,支持POSIX扩展正则表达式,其中包含更多可用于指定匹配模式的字符。fgrep则是另外一个版本,支持将匹配模式指定为以换行符分隔的一系列固定长度的字符串。这样就可以将这些字符串放入一个文件中,然后在fgrep命令中使用其搜索大文件中的字符串。
3.3 数据压缩
Linux包含多种文件压缩工具。虽然听上去不错,但实际上这经常会在用户下载文件时造成混淆。
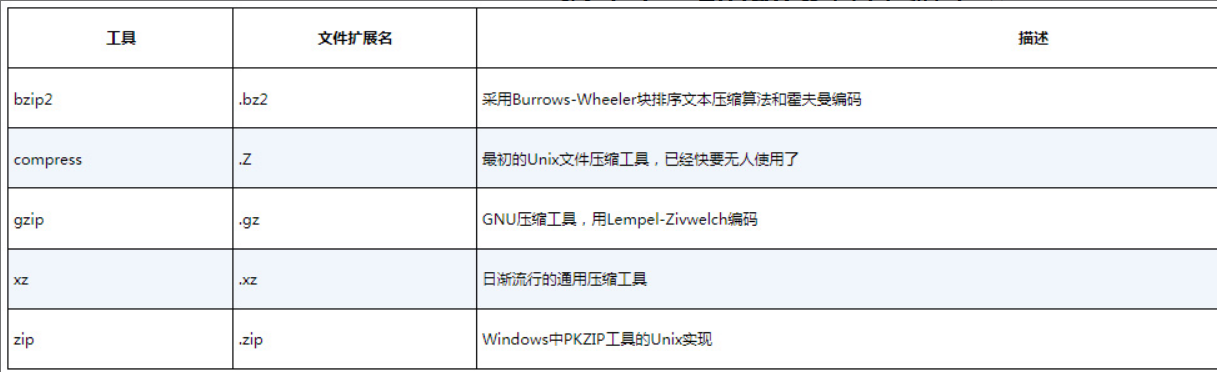
文件压缩工具compress在Linux系统中并不常见。如果下载了扩展名为.Z的文件,那么通常可以用软件包安装方法来安装compress包(在很多Linux发行版中叫ncompress),然后再用uncompress命令来解压文件。
1. gzip
gzip是Linux中最流行的压缩工具。
gzip软件包是GNU项目的产物,旨在编写一个能够替代原先Unix中compress工具的免费版本。这个软件包包括以下文件。
gzip [选项] 源文件
| 选项 | 含义 |
|---|---|
| -c | 将压缩数据输出到标准输出中,并保留源文件。 |
| -d | 对压缩文件进行解压缩。 |
| -r | 递归压缩指定目录下以及子目录下的所有文件。 |
| -v | 对于每个压缩和解压缩的文件,显示相应的文件名和压缩比。 |
| -l | 对每一个压缩文件,显示以下字段:压缩文件的大小;未压缩文件的大小;压缩比;未压缩文件的名称。 |
| -数字 | 用于指定压缩等级,-1 压缩等级最低,压缩比最差;-9 压缩比最高。默认压缩比是 -6。 |
[root@Wesuiliye ~]# gzip test [root@Wesuiliye ~]# ls -l test.gz -rw-r--r-- 1 root root 54 Apr 14 23:38 test.gz
注意 gzip 命令只能用来压缩文件,不能压缩目录,即便指定了目录,也只能压缩目录内的所有文件。
gunzip
·gunzip:用于解压文件。
gunzip [选项] 文件
| 选项 | 含义 |
|---|---|
| -r | 递归处理,解压缩指定目录下以及子目录下的所有文件。 |
| -c | 把解压缩后的文件输出到标准输出设备。 |
| -f | 强制解压缩文件,不理会文件是否已存在等情况。 |
| -l | 列出压缩文件内容。 |
| -v | 显示命令执行过程。 |
| -t | 测试压缩文件是否正常,但不对其做解压缩操作。 |
zcat
zcat用于查看压缩过的文本文件的内容。
如果我们压缩的是一个纯文本文件,则可以直接使用 zcat 命令在不解压缩的情况下查看这个文本文件中的内容
2. zip
zip [选项] 压缩包名 源文件或源目录列表
| 选项 | 含义 |
|---|---|
| -r | 递归压缩目录,及将制定目录下的所有文件以及子目录全部压缩。 |
| -m | 将文件压缩之后,删除原始文件,相当于把文件移到压缩文件中。 |
| -v | 显示详细的压缩过程信息。 |
| -q | 在压缩的时候不显示命令的执行过程。 |
| -压缩级别 | 压缩级别是从 1~9 的数字,-1 代表压缩速度更快,-9 代表压缩效果更好。 |
| -u | 更新压缩文件,即往压缩文件中添加新文件。 |
[root@Wesuiliye ~]# zip aaa.zip test* adding: test_1 (deflated 92%) adding: test_2 (deflated 92%) adding: test_2.gz (deflated 19%) adding: test2.gz (stored 0%) adding: test.gz (deflated 39%) adding: test.gz~ (stored 0%) [root@Wesuiliye ~]# ll aaa.zip -rw-r--r-- 1 root root 3391 Apr 15 09:53 aaa.zip
unzip
unzip [选项] 压缩包名
| 选项 | 含义 |
|---|---|
| -d 目录名 | 将压缩文件解压到指定目录下。 |
| -n | 解压时并不覆盖已经存在的文件。 |
| -o | 解压时覆盖已经存在的文件,并且无需用户确认。 |
| -v | 查看压缩文件的详细信息,包括压缩文件中包含的文件大小、文件名以及压缩比等,但并不做解压操作。 |
| -t | 测试压缩文件有无损坏,但并不解压。 |
| -x 文件列表 | 解压文件,但不包含文件列表中指定的文件。 |
Archive: aaa.zip Length Method Size Cmpr Date Time CRC-32 Name -------- ------ ------- ---- ---------- ----- -------- ---- 10240 Defl:N 839 92% 04-15-2023 09:24 e0b16084 test_1 10240 Defl:N 839 92% 04-15-2023 09:24 e0b16084 test_2 27 Defl:N 22 19% 04-09-2023 10:05 4a7fcbed test_2.gz 75 Stored 75 0% 04-14-2023 23:37 354c6ea1 test2.gz 884 Defl:N 540 39% 04-15-2023 00:05 20abc466 test.gz 54 Stored 54 0% 04-14-2023 23:38 69eb117e test.gz~ 0 Stored 0 0% 04-09-2023 09:55 00000000 New_dir/ -------- ------- --- ------- 21520 2369 89% 7 files
3.4 数据归档
虽然zip命令能够很好地将数据压缩并归档为单个文件,但它并不是Unix和Linux中的标准归档工具。目前,Unix和Linux中最流行的归档工具是tar命令。
tar命令最开始是用于将文件写入磁带设备以作归档,但它也可以将输出写入文件,这种用法成了在Linux中归档数据的普遍做法。
tar命令
使用tar程序打出来的包我们常称为tar包,tar包文件的命令通常都是以.tar结尾的。生成tar包后,就可以用其它的程序来进行压缩了,tar命令本身不进行数据压缩,但可以在打包或解包的同时调用其它的压缩程序,比如调用gzip、bzip2
tar [选项] [-f 压缩包名] 源文件或目录 -c 创建.tar格式包文件 -x 解开.tar格式包文件 -v 显示详细信息 -f 使用归档文件。归档,也称为打包,指的是一个文件或目录的集合。 -p 保留原始文件权限 -C 解压到目标文件夹 -z 调用gzip进行压缩或解压 -j 调用bzip2进行压缩或解压 -t 列出tar归档文件的内容
打包示例:
tar -cvf /root/Desktop/aa.tar bb.txt 打包文件
打包并压缩示例:
tar -zcvf /root/Desktop/aa.tar.gz bb.txt 压缩文件
解压缩示例:
tar -zxvf /root/Desktop/aa.tar.gz -C /aa/bb 解压文件
列出了(但不提取)tar文件test.tar的内容:
tar -tf abcd.tar.gz
提示 在下载开源软件时经常会看到文件名以.tgz结尾,这是经gzip压缩过的tar文件,可以用命令tar -zxvf filename.tgz来提取其中的内容。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 25岁的心里话
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列01:轻松3步本地部署deepseek,普通电脑可用
· 按钮权限的设计及实现