一文读懂C++
基础内容
为什么要学习C++?
- 开发效率快,语法层面支持面向对象编程思想
Visual Studio 2015新建空项目
C++对C的语法的改进
1.1 C++ 类型检查更严格
int main() {
//C写法
int n1 = 3;
int n2 = 3.2f;
int n3 = 3.2;
//C++写法
int n4 = {6};
int n5 = { 3.2 };//需要类型严格的匹配【这里会报错】
return 0;
}
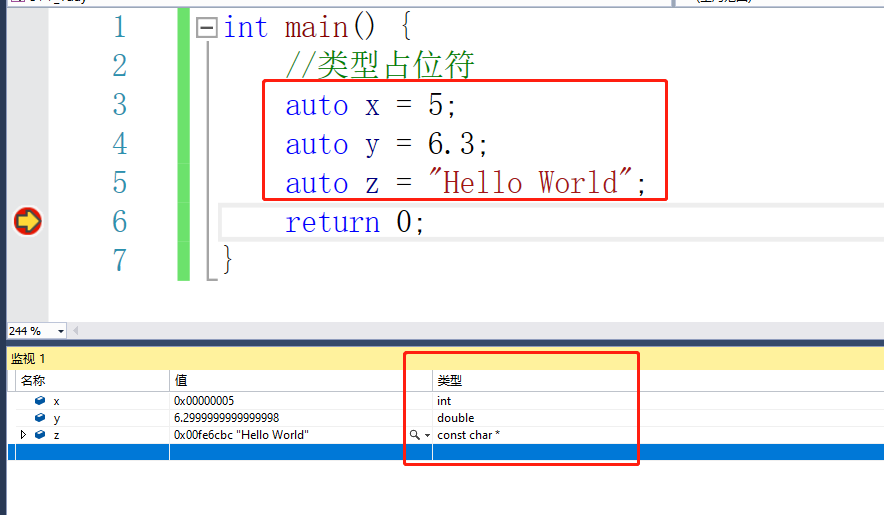
1.2 类型占位符 - 类型推导
根据=号右边的数值的类型,推导出左侧变量的类型
auto x = 5;
auto y = 6.3;
auto z = "Hello World";
auto t;//这里会报错,因为没有数值可以来给t推导类型
decltype(x) x1 = 5;//根据x的类型推导出int,相当于int x1 =5;
decltype(y) y1 = 6.5;
decltype(z) z1 = "aaa";
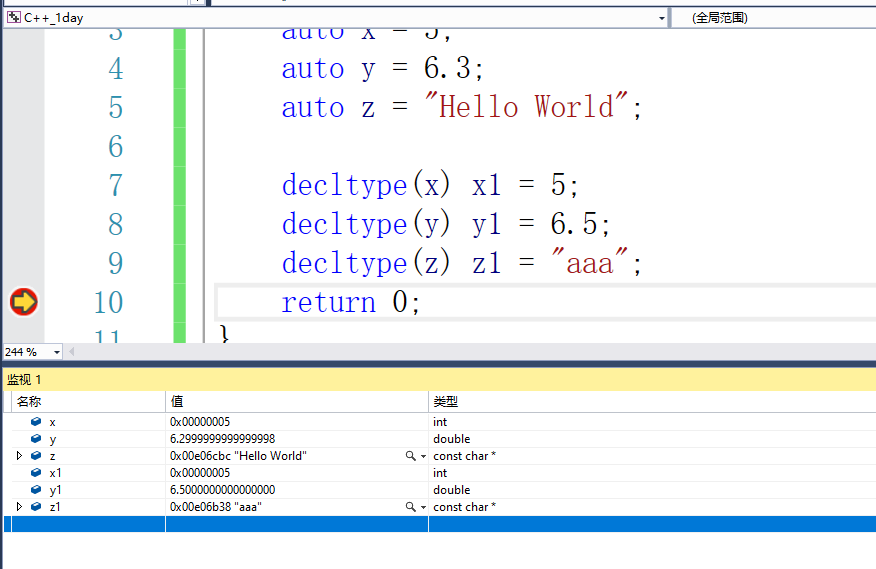
这些一般都是在类型比较复杂的情况下使用。
1.3 空指针
在C++中自带了空指针的定义了类型:nullptr
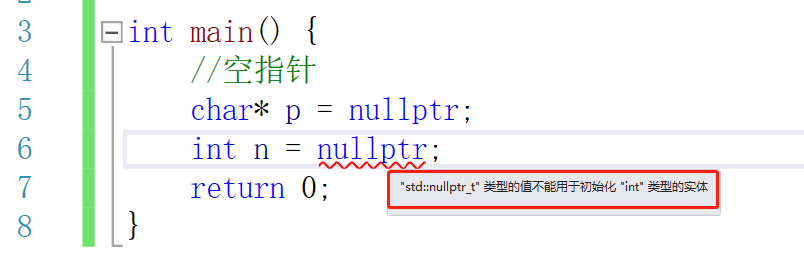
为什么要引入nullptr呢?我们来看一下C语言对NULL的定义:#define NULL ((void *)0),这里我们可以看出来实际上是一个空指针,C语言中把空指针赋值给int和char指针的时候做了一个隐式的类型转换,将void指针做了转换.
我们继续来看一下在C++中NULL的定义:
#ifdef __cplusplus
#define NULL 0
#else
#define NULL ((void *)0)
#endif
在C++中,NULL实际上是0,因为C++中不能把void*类型的指针隐式转换成其他类型的指针,所以为了解决空指针的表示问题,C++引入了0来表示空指针,这样就有了上述代码中的NULL宏定义。
详细的解释:https://blog.csdn.net/reasonyuanrobot/article/details/100022574
1.4 范围迭代
//正常遍历数组
char arr[] = { 1,2,3,4,5,6,7,8,9 };
for (int i =0;i<sizeof(arr)/sizeof(arr[0]);i++)
{
printf("%d",arr[i]);
}
printf("\r\n");
//范围迭代
for (int val:arr)
{
printf("%d", val);
}
输入输出流
C++里的输出流
C++中需要包含一个头文件:#include <iosteam>
#include <stdio.h>
#include <iostream>
int main() {
std::cout << "Hello" << std::endl;
std::cout << 2 << std::endl;
std::cout << 2.3f << std::endl;
std::cout << 22.33 << std::endl;
return 0;
}
我们可以发现这样写起来很麻烦,要一直写std,可以直接引用命名空间:using namespace std;
#include <iostream>
using namespace std;
int main() {
cout << "Hello" << endl;
cout << 2 << endl;
cout << 2.3f << endl;
cout << 22.33 << endl;
return 0;
}
其实还可以更简单的写为一行
#include <iostream>
using namespace std;
int main() {
cout << "Hello" << endl << 2 << endl << 2.3f << endl << 22.33 << endl;
return 0;
}
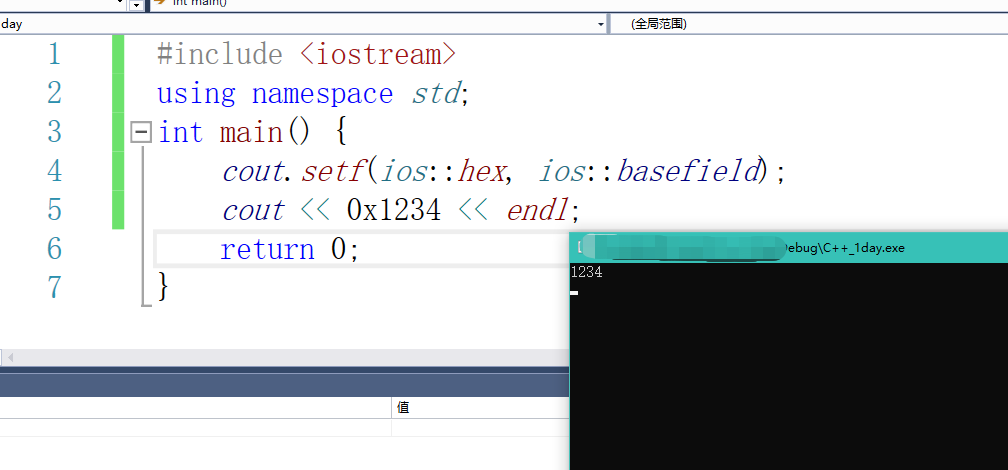
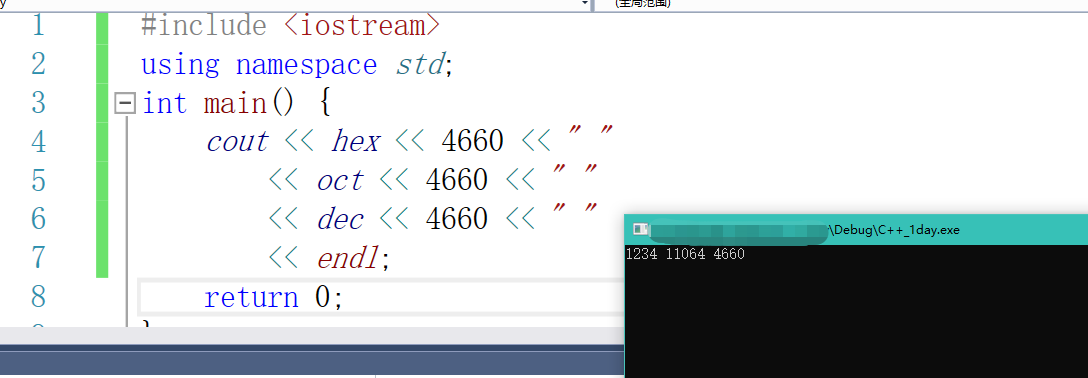
cout默认输出的是十进制,哪怕你写的是一个0x1234他输出的依然是十进制数。那么我们需要修改一下代码,
第一种方式:
使用setf可以设置其他进制,使用unsetf可以取消其他进制,并恢复默认的十进制显示。cout.setf(ios::hex, ios::basefield);
第二种方式:调用函数设置数值进制
#include <iostream>
using namespace std;
int main() {
cout << hex << 4660 << " "
<< oct << 4660 << " "
<< dec << 4660 << " "
<< endl;
return 0;
}
科学计数法:scientific
cout << scientific << 2.356 << endl;
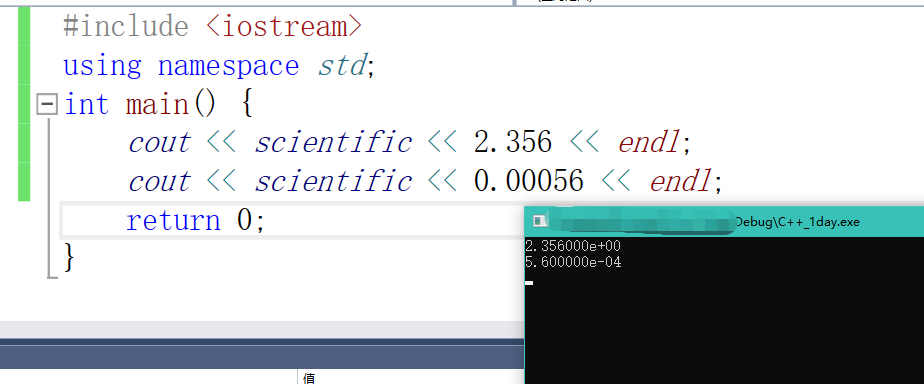
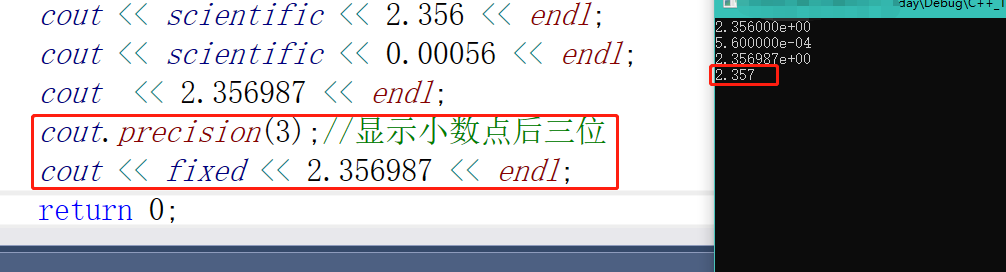
我们在打印浮点精度的时候,如果被打印成科学计数法,我们可以使用定点计数法

那么我们只想输出小数点后几位怎么设置呢?
cout.precision(3);//显示小数点后三位
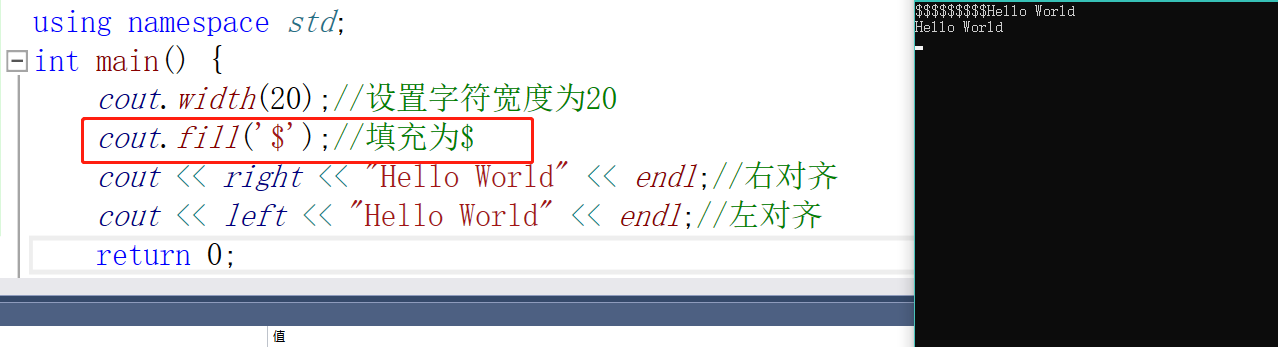
对齐和宽度:
#include <iostream>
using namespace std;
int main() {
cout.width(20);//设置字符宽度为20
cout << right << "Hello World" << endl;//右对齐
cout << left << "Hello World" << endl;//左对齐
return 0;
}

这里发现右对齐前面填充的是空格,我们可以使用fill来填充内容
其他:
-
为整数输出指示数字的前缀(showbase)
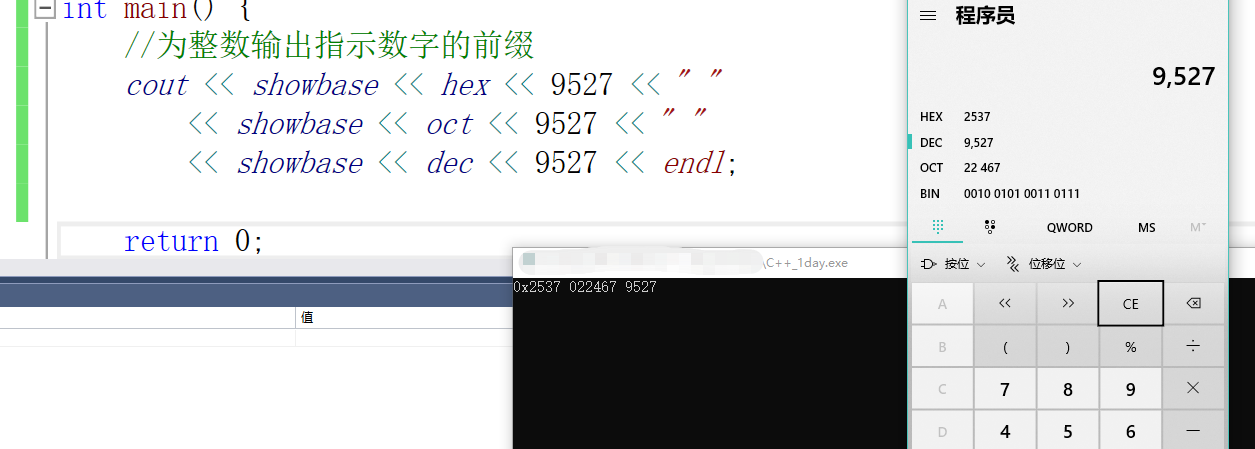
-
启用浮点和十六进制整数输出中大写字符的使用(uppercase)
对字符串没有效果,对数值显示有效果

C++里的输入流
测试一下各种类型的接收。
#include <iostream>
using namespace std;
int main() {
int nVal;
float fVal;
double dbVal;
char szBuff[256];
cin >> nVal >> fVal >> dbVal >> szBuff;
cout << "nVal: " << nVal << " fVal: " << fVal << " dbVal: " << dbVal << " szBuff: " << szBuff;
return 0;
}

这里用空格或者换行都可以拿到输入的内容
这里我们可以看出来一个很明显的问题,如果我们的输入字符串中有空格,是不是就截断了,我们写个demo测试一下
#include <iostream>
using namespace std;
int main() {
char szBuff[256];
int nVal;
cin >> szBuff >> nVal;
cout << szBuff << " " << nVal;
return 0;
}

这里经过测试,发现空格、回车、tab键都会被截断,那么如何去解决这个问题?
第一种方法:清除缓冲区
#include <iostream>
using namespace std;
int main() {
char szBuff[256];
int nVal;
cin >> szBuff;
//清除掉cin缓冲区中的数据
int nCount = cin.rdbuf()->in_avail();
cin.ignore(nCount);
cin >> nVal;
cout << szBuff << " " << nVal;
return 0;
}
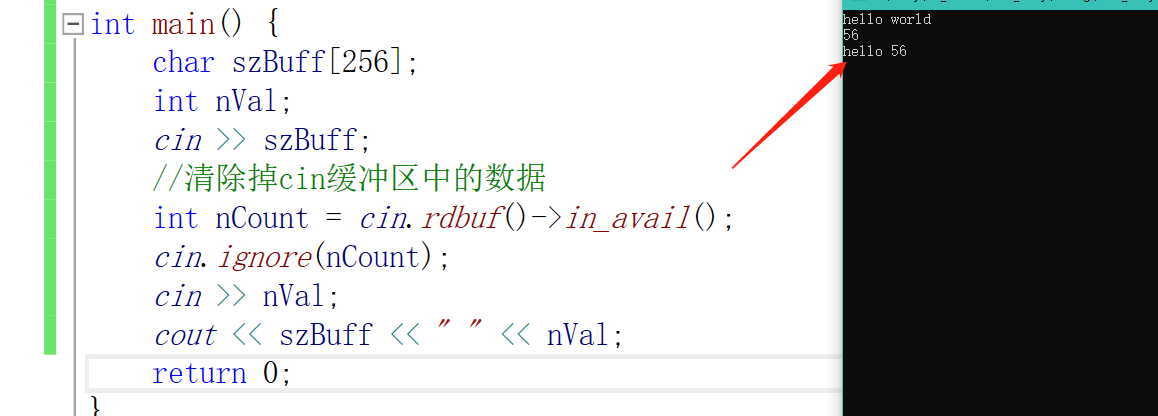
但是这样会造成空格后的字符串会丢失。
第二种方法:读一行
#include <iostream>
using namespace std;
int main() {
char szBuff[256];
int nVal;
cin.getline(szBuff,sizeof(szBuff));//从控制台读取一行
cin >> nVal;
cout << szBuff << " " << nVal;
return 0;
}
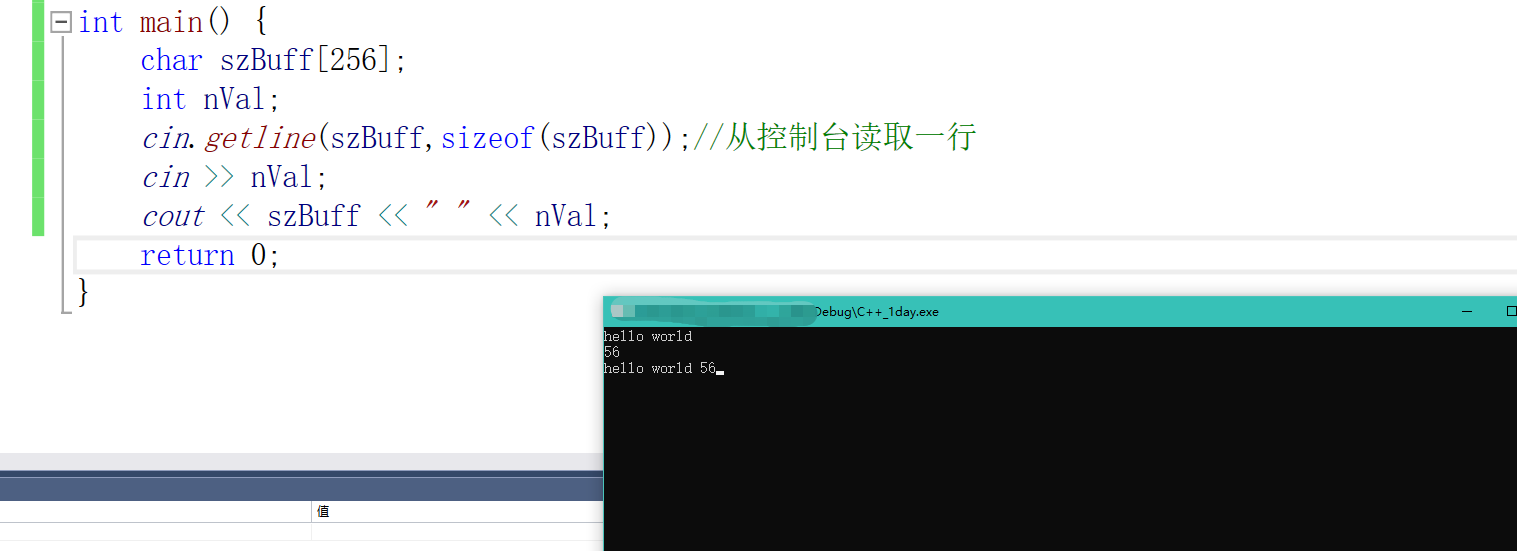
这样就不会丢失掉空格后的数据了。
布尔类型
在老的C语言中其实是没有BOOL类型的,我们来看一下他其实在引入头文件的时候也只是一个宏定义。
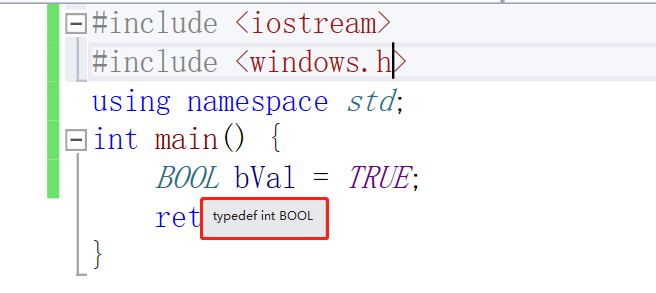
那么我们是不是可以自己也来typedef和define这个数据类型呢?
#include <iostream>
typedef int BOOL;
#define TRUE 1
#define FALSE 0
using namespace std;
int main() {
BOOL bVal = TRUE;
return 0;
}
但是这里面有个不严谨的操作,因为我们的BOOL是typedef的int,所以我们给bVal赋值其他整数也是没问题的,这样我们就显得非常不严谨
在C++中,可以使用小写的bool:bool bVal = true;
这样虽然显示的内容是true或者false,但是我们来观察一下内存,看看里面到底存的是什么?
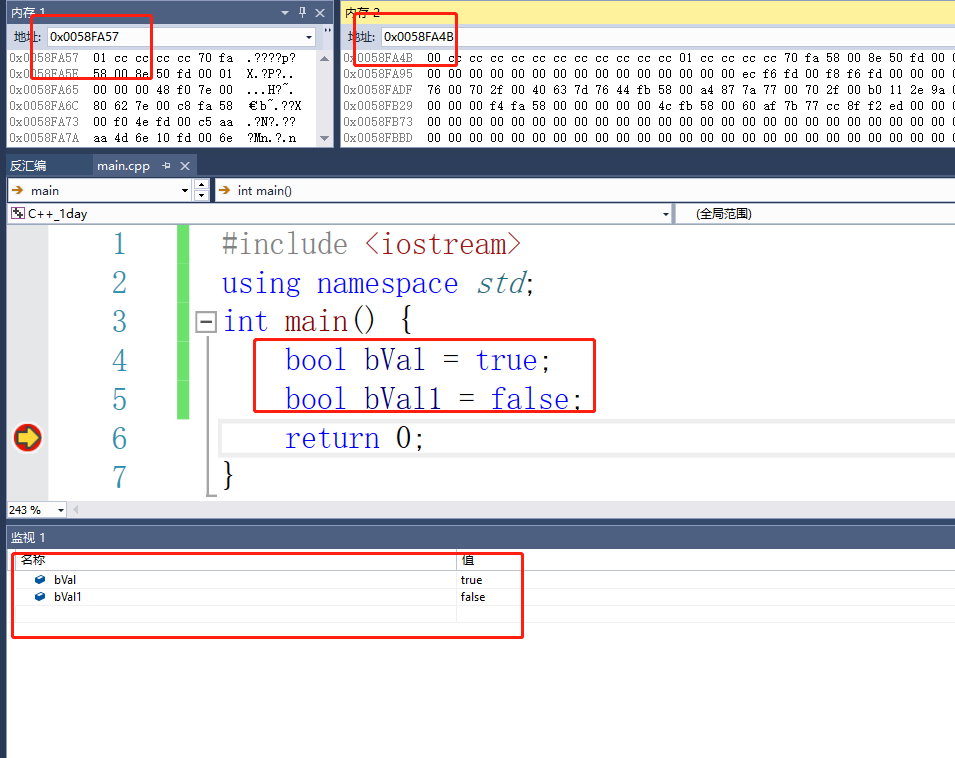
我们可以看出来分别是在内存中存储了1和0,长度只有一个字节。我们来把bool类型的值修改为其他int型的值看一下
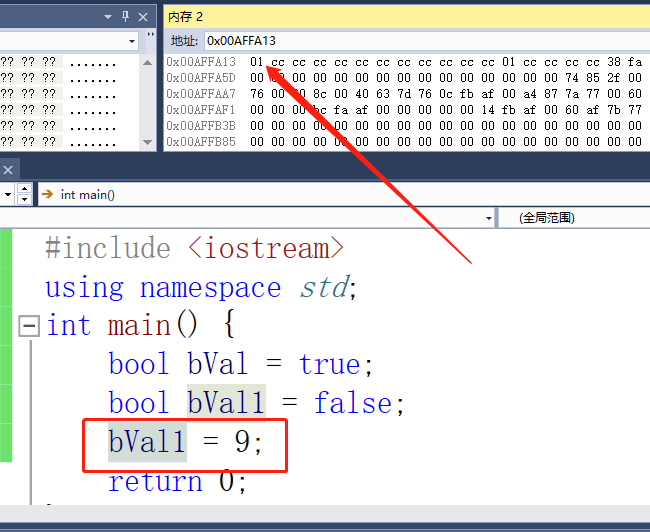
我们可以发现,在内存中依然是1,但是可读性依然不是很好,这里c++没有提供严格的类型检查。
- tips:bool值是非0为真,0为假
const
在程序中有一个常量值在程序各个位置都用得到,我们应该怎么来写呢?
- 定义一个无参宏:
#define VALUE 1000
但是无参宏是有缺陷的,我们的无参宏是文本替换,不会进行类型检查,我们来写个demo看一下。

这里为什么会输出16呢?我们来看一下,char中可以放得下10000吗?所以在这里肯定会造成隐式转换,而且在调试的时候是看不到类型信息的。
为了解决这个问题,c++提供了const语法,我们可以通过const来定义一个常量,这样就可以在调试的时候看到这个常量信息了。但是这个常量真的不可以修改掉吗?我们调试的时候发现const定义的常量是有地址的,我们来试一下
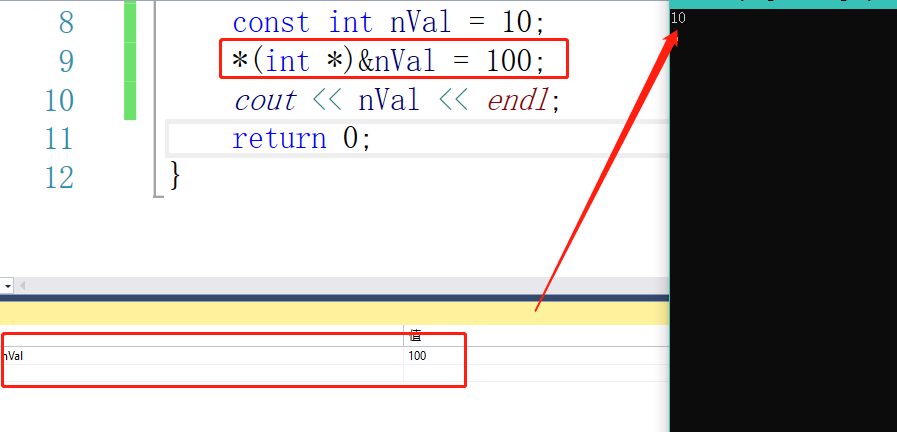
我们可以发现,虽然内存中已经修改,但是cout打印居然还是10。
这里C++会在使用nVal的时候判断nVal前面有没有const,如果有的话会直接拿定义时候的值来用。
对比C语言和C++的const
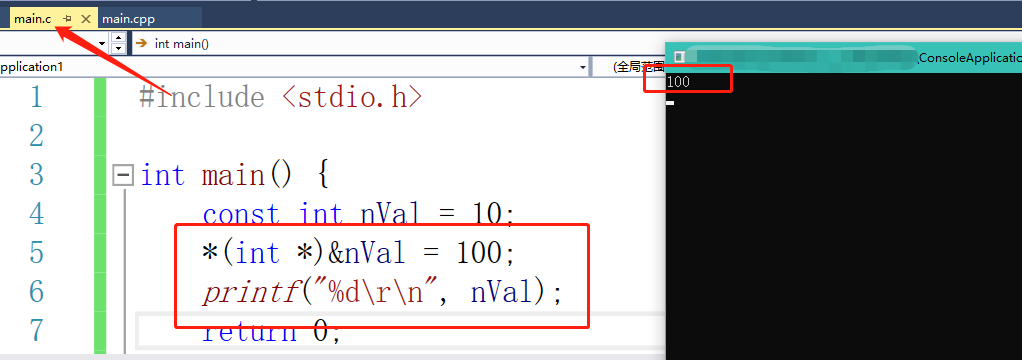
在C语言中,我们是可以通过指针修改掉const常量内容的。【C语言是假const、C语言是六耳猕猴,C++是齐天大圣】
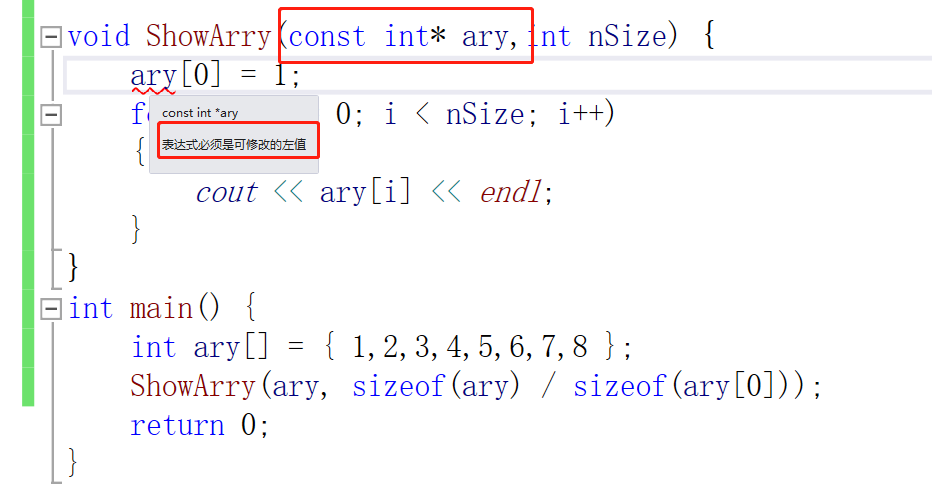
一般情况下const都在修饰指针,举个例子我们来写一个输出数组的函数
#include <iostream>
using namespace std;
void ShowArry(int* ary,int nSize) {
for (int i = 0; i < nSize; i++)
{
cout << ary[i] << endl;
}
}
int main() {
int ary[] = { 1,2,3,4,5,6,7,8 };
ShowArry(ary, sizeof(ary) / sizeof(ary[0]));
return 0;
}
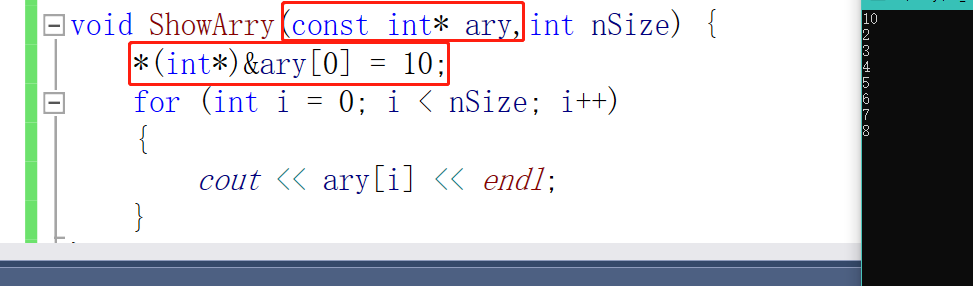
但是有时候我们会在无意间在函数中修改掉原始数组的值。我们就可以使用const来防止这种误操作
但是其实我们还是可以修改的
const修饰的指针之间的转换
#include <iostream>
using namespace std;
int main() {
const int* p1 = nullptr;//不能修改p1指向的内容
int* const p2 = p1;//p1指向的内容不能够被修改,如果成功赋值给p2,那么就可以通过p2去修改p1指向的内容,所以p1的const的限制就废掉了
const int* const p3 = p2;//这个相当于是对p2增加了限制,所以是可以的
const int* p4 = p3;//p3是两个都不能修改
int* const p5 = p3;//这里不可以
return 0;
}
所以从上面的代码可以总结出来一个结论:限制少的向限制多的转换是可以的,只能加限制,不能减限制
引用
指针的缺点:空指针、野指针
空指针是不能够操作指针所指向的对象的
野指针是没有赋初值
引用就是来解决这个问题的。
我们先来写一个交换函数
#include <iostream>
using namespace std;
void Swap(int* p1, int* p2) {
int nTmp = *p1;
*p1 = *p2;
*p2 = nTmp;
}
int main() {
int nVal1 = 8;
int nVal2 = 0;
Swap(&nVal1,&nVal2);
cout << nVal1 << " " << nVal2 << endl;
return 0;
}
但是如果给交换函数的是一个野指针。

这里就会出问题,我们修改成使用引用
#include <iostream>
using namespace std;
void Swap(int& p1, int& p2) {
int nTmp = p1;
p1 = p2;
p2 = nTmp;
}
int main() {
int nVal1 = 8;
int nVal2 = 0;
Swap(nVal1,nVal2);
cout << nVal1 << " " << nVal2 << endl;
return 0;
}
引用的基础语法:
int nVal = 10;
int& nValRet = nVal;//引用相当于给nVal取了个别名
nValRet = 8;
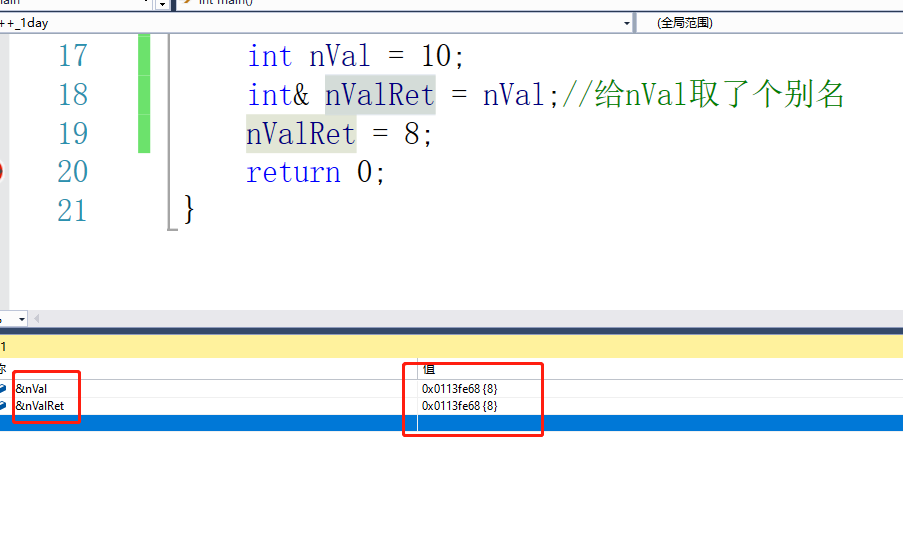
可以看到操作的是同一块内存区域。
那么为什么可以使用引用解决空指针和野指针问题呢?
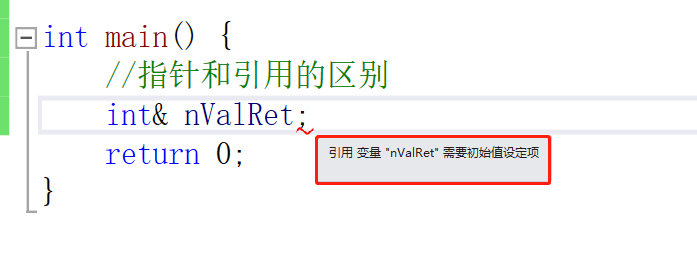
我们可以发现引用必须有初始值,所以就不存在野指针,空指针了
我们的指针还有多级指针,那么我们的引用是否存在多级引用呢?
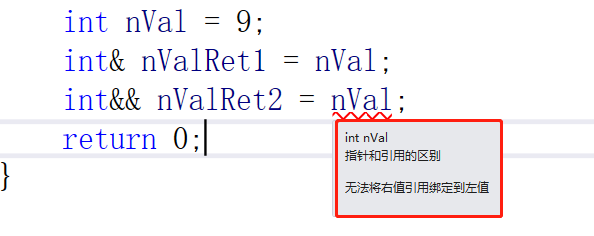
我们的引用是不存在多级引用的。
引用是可以引用所有的类型的,但是引用只能引用相同类型的变量
demo1【指针类型引用】:
#include <iostream>
using namespace std;
int main() {
char ch = 'A';
char* p = &ch;
char*& p1 = p;
char ch1 = 'B';
p1 = &ch1;
cout << ch1 << endl;
return 0;
}
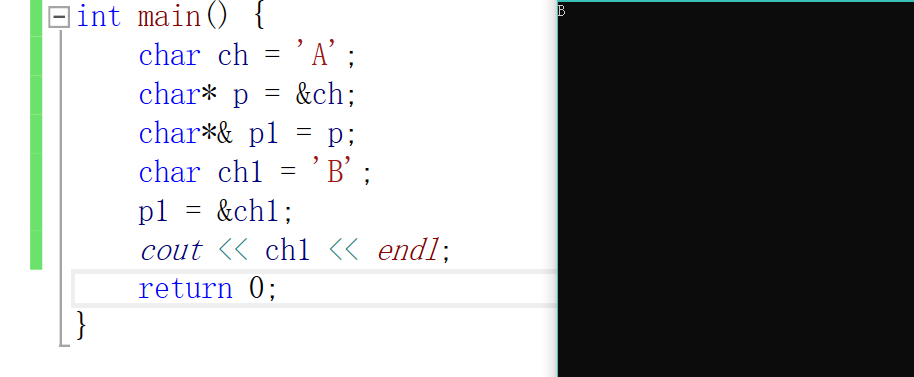
这里修改的是指针p的值。
demo2【自定义类型引用】:
#include <iostream>
using namespace std;
struct tagTest
{
int m_nVal;
float m_fVal;
};
int main() {
tagTest tag1{3,3.2f};
tagTest& tRef = tag1;
tRef.m_nVal = 65;
return 0;
}
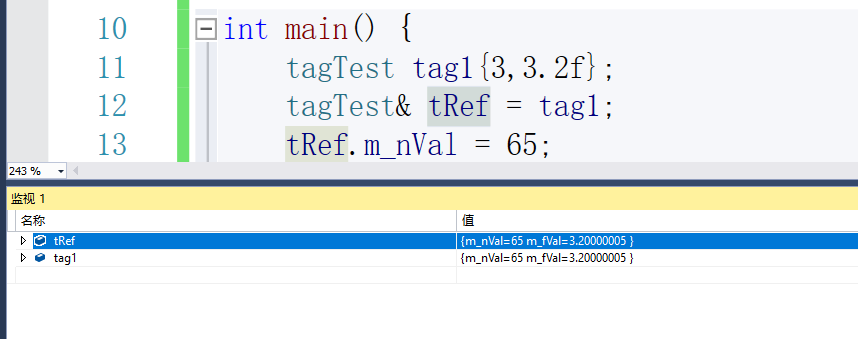
下面我们来讨论一下就是在上面Swap函数传参到底传了个什么进去
我们在Swap函数中下断点,通过nTmp来定位函数栈
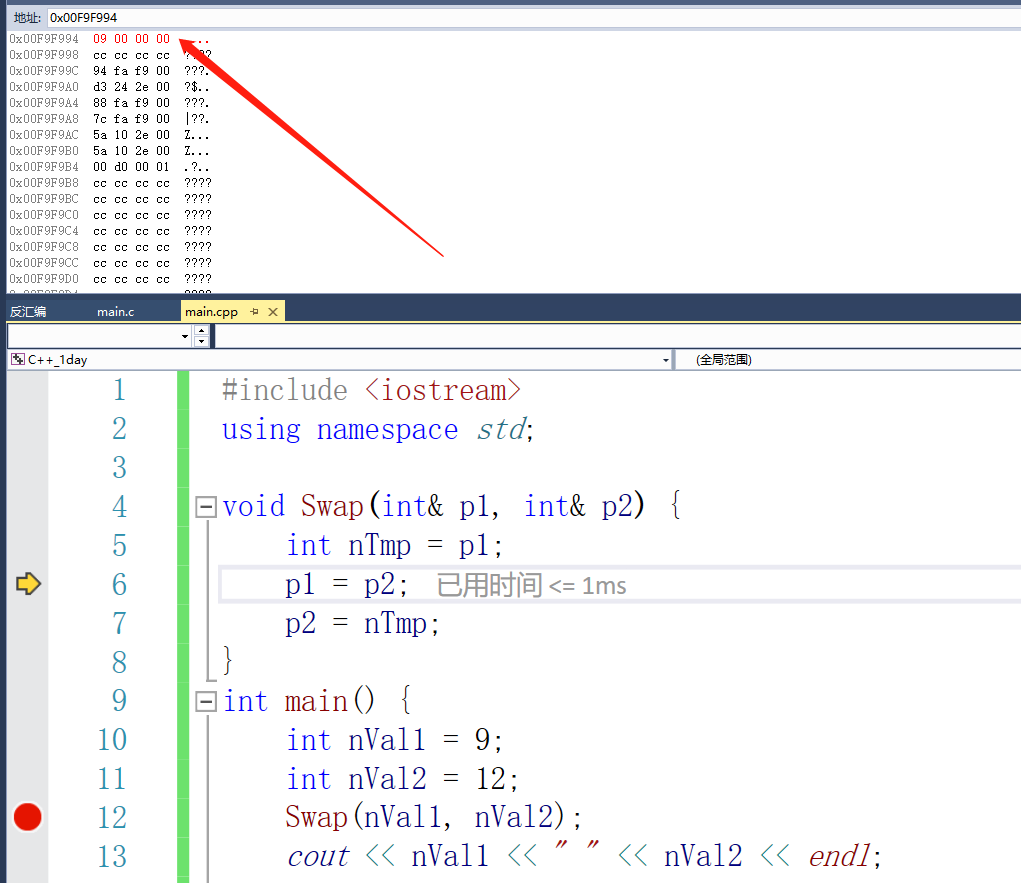
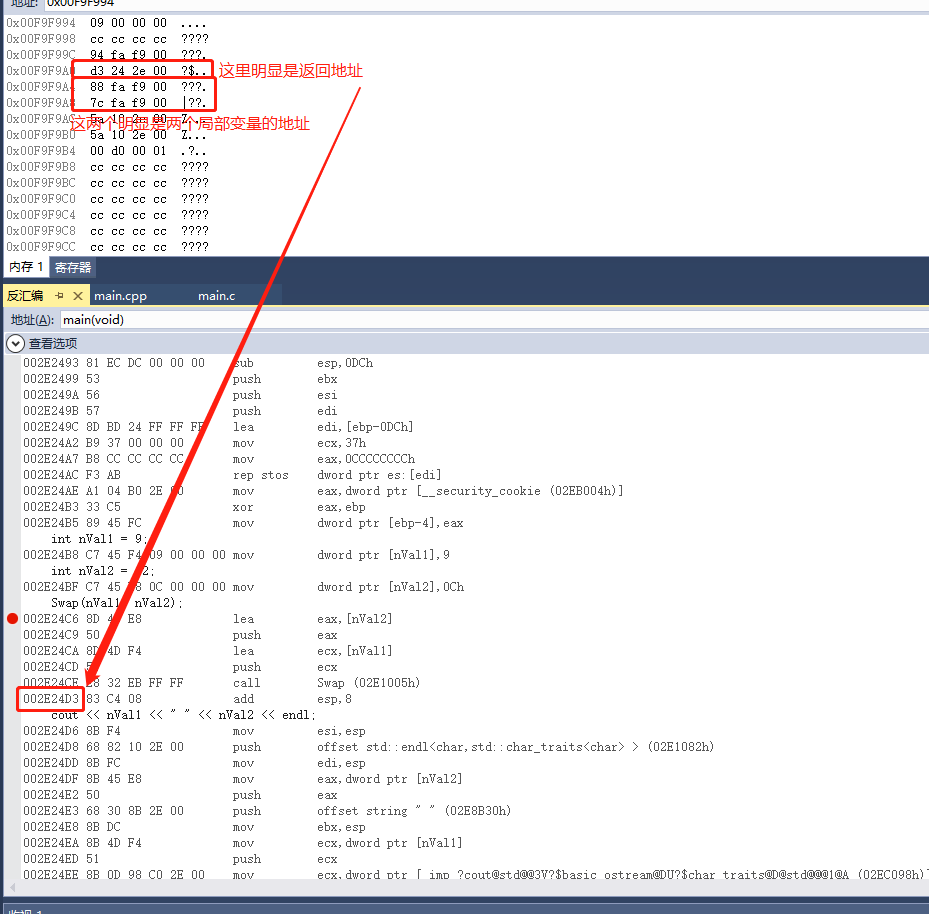
我们再次调试过来加上对行参的监视
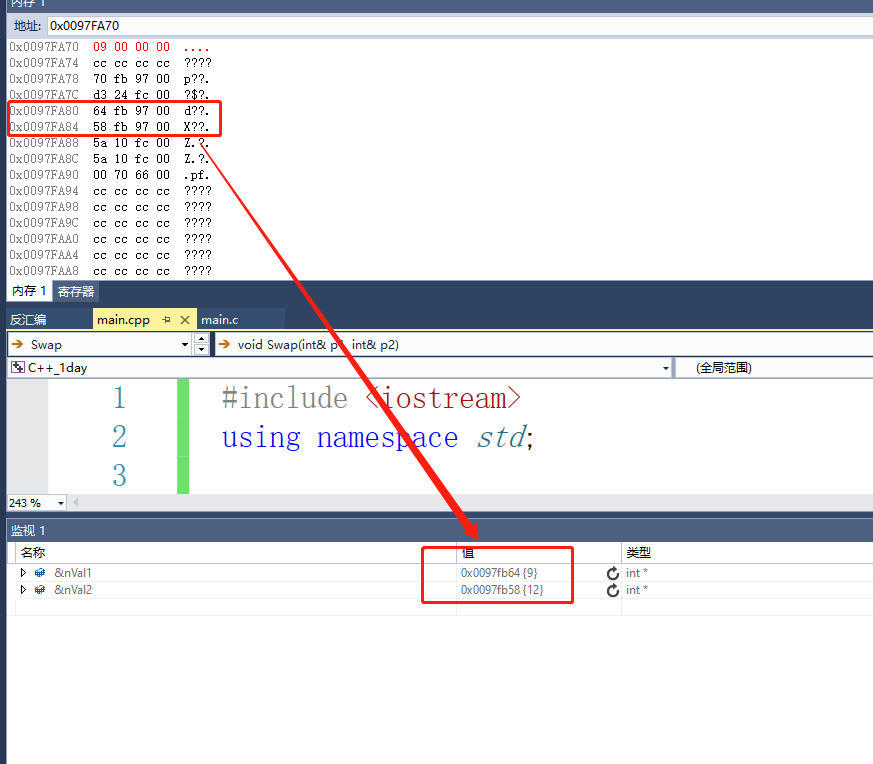
我们可以发现这两个栈地址是这两个参数的地址
那么引用的原理:编译器在处理引用的时候,内部仍然是使用指针在操作,他只是在语法层面上限制了空指针,野指针的出现。
而且引用是不可以修改引用的变量的:
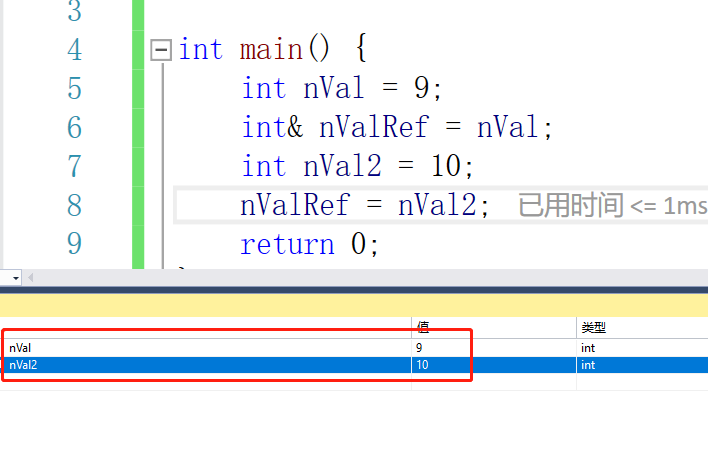
当我们单步往下走就会发现这样的情况

他并没有修改引用的变量,而是做了一个赋值操作。所以说引用是不可以修改引用的变量的
默认参
我们先来模拟一个打招呼的函数
#include <iostream>
using namespace std;
void SayHi(const char* szName,const char* szHi) {
cout << szName << "打招呼说: " << szHi << endl;
}
int main() {
SayHi("小黄","Hello");
SayHi("小红", "Hello");
SayHi("小蓝", "Hello");
SayHi("小绿", "Hello");
SayHi("小紫", "Hello");
SayHi("小白", "Hello");
return 0;
}
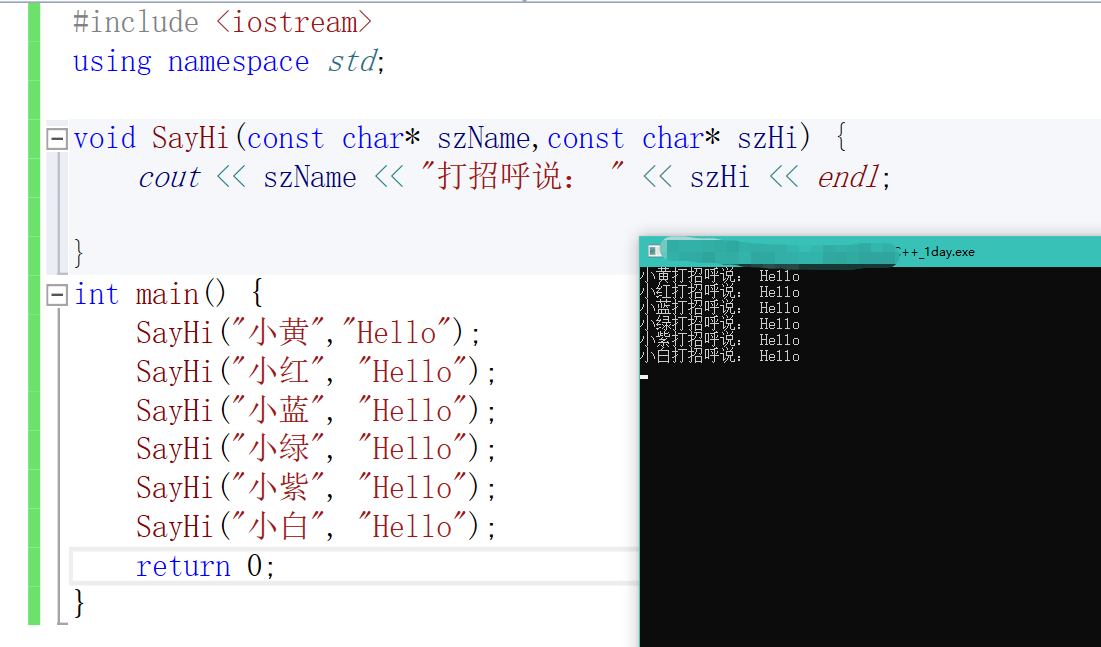
写完这个我们就可以来看问题了,这些人打招呼的内容是一样的,相当于我们一直在写重复的东西。
在C语言中,我们来解决这个问题可以用define来做
#include <stdio.h>
#define SAYHI(name) SayHi(name,"Hello")
void SayHi(const char* szName, const char* szHi) {
printf("%s打招呼说: %s\r\n", szName, szHi);
}
int main() {
SAYHI("小黄");
SAYHI("小红");
SAYHI("小蓝");
SAYHI("小绿");
SAYHI("小紫");
SAYHI("小白");
SayHi("大白", "你好");
return 0;
}
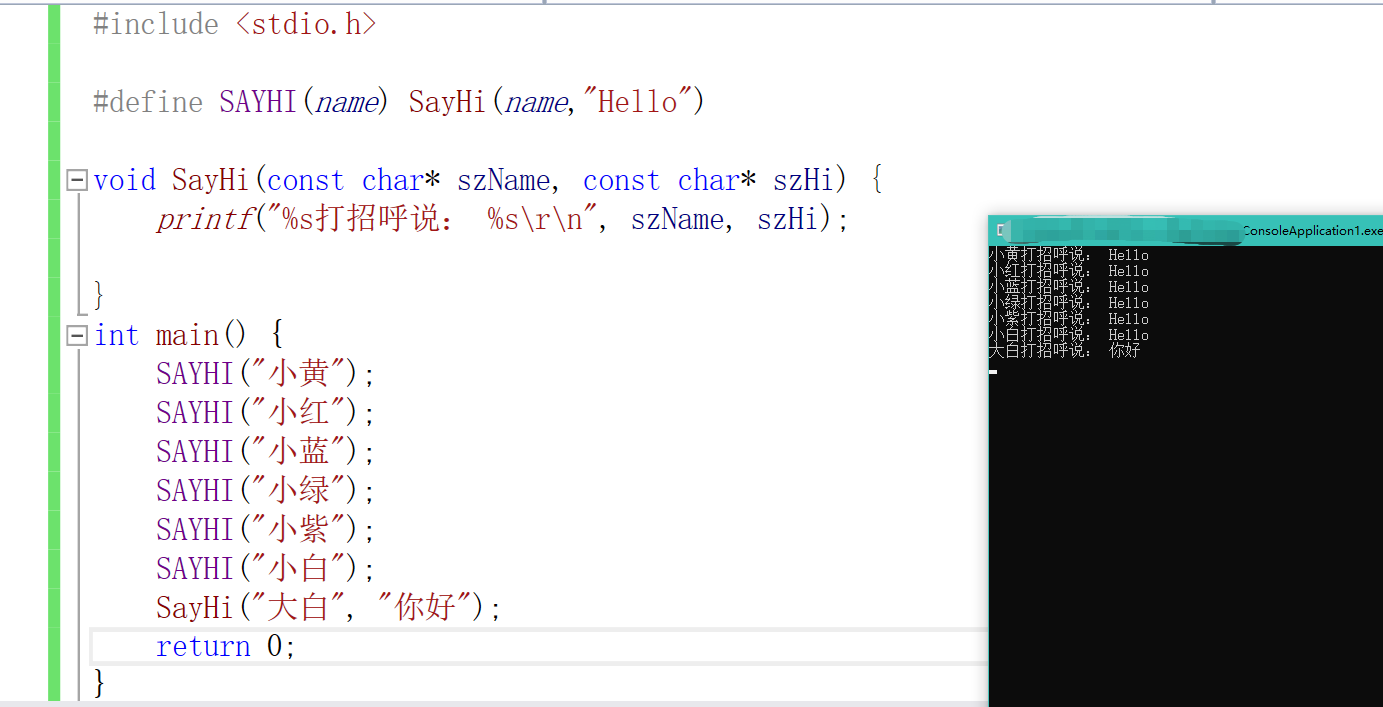
虽然这种方式可以在一定程度上解决重复写参数的问题,但是代码的可读性非常差,为了解决这个问题,C++提出了默认参数,给行参一个默认参数
#include <iostream>
using namespace std;
void SayHi(const char* szName,const char* szHi="Hello") {
cout << szName << "打招呼说: " << szHi << endl;
}
int main() {
SayHi("小黄");
SayHi("小红");
SayHi("小蓝");
SayHi("小绿");
SayHi("小紫");
SayHi("小白");
SayHi("大白", "你好");
return 0;
}
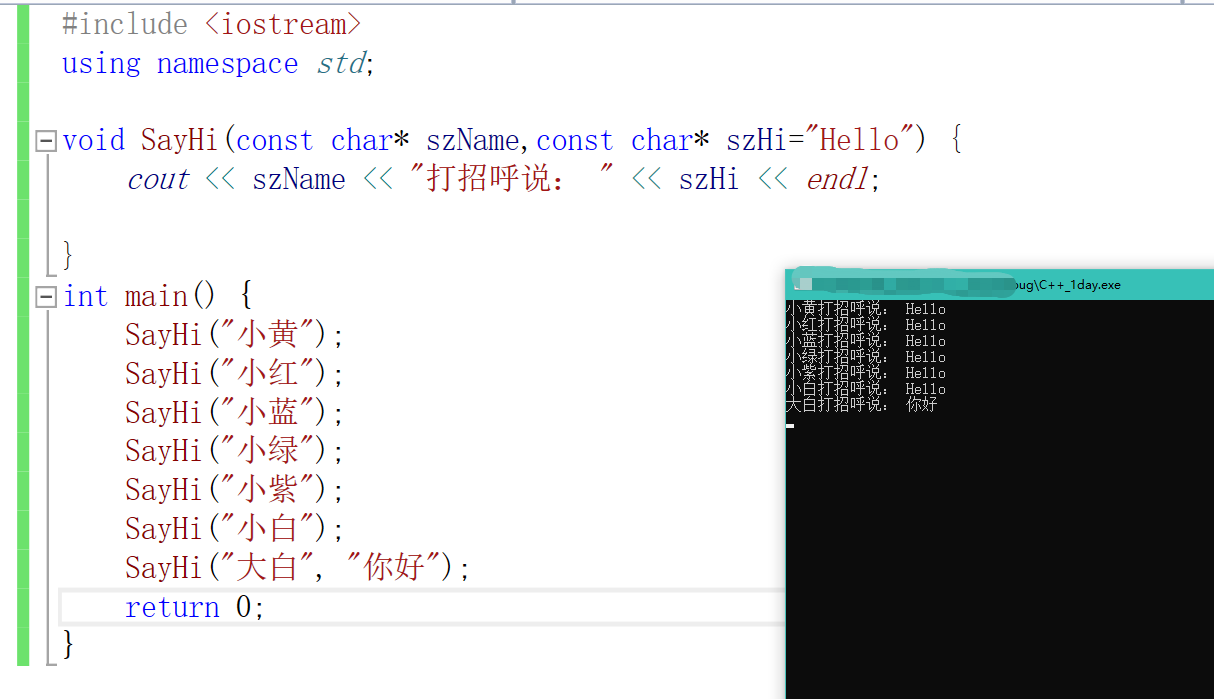
当调用函数的时候,如果没有提供实参,则使用默认参
当调用函数的时候,如果提供实参,则使用实参
默认参规则:
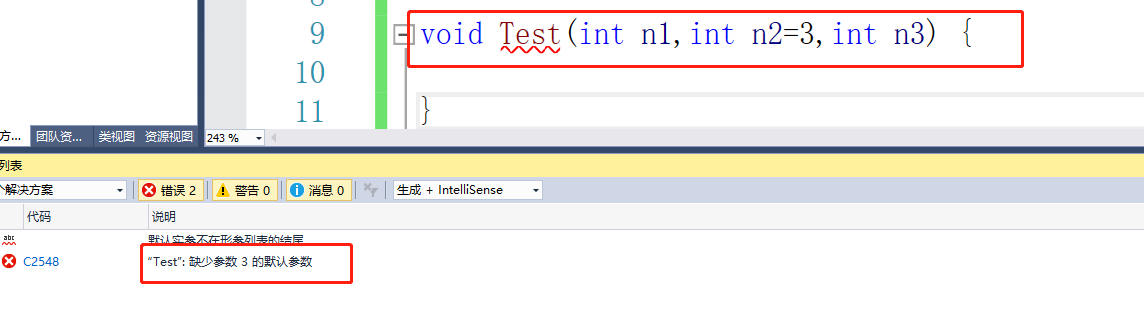
我们的默认参只能从右向左填写,不能隔着写
那我们来思考一下为什么非要从右向左填写呢,而且中间还不可以间断?
假设说我们有这么一个函数:
void Test(int n1,int n2=3,int n3=7,int n4) {
}
那么我们在调用的时候:Test(1,2,3);,那这个参数应该怎么分配呢?
编译器就无法判断,所以语法就规定不允许这样写。
在我们的标准开发过程中,声明和定义都是分开的,那么我们现在来试一下,新建一个头文件和一个代码文件
test.h
#pragma once
void Test(int nVal = 1);
test.cpp
#include "test.h"
void Test(int nVal = 1) {
}
我们去包含一下这个头文件来使用
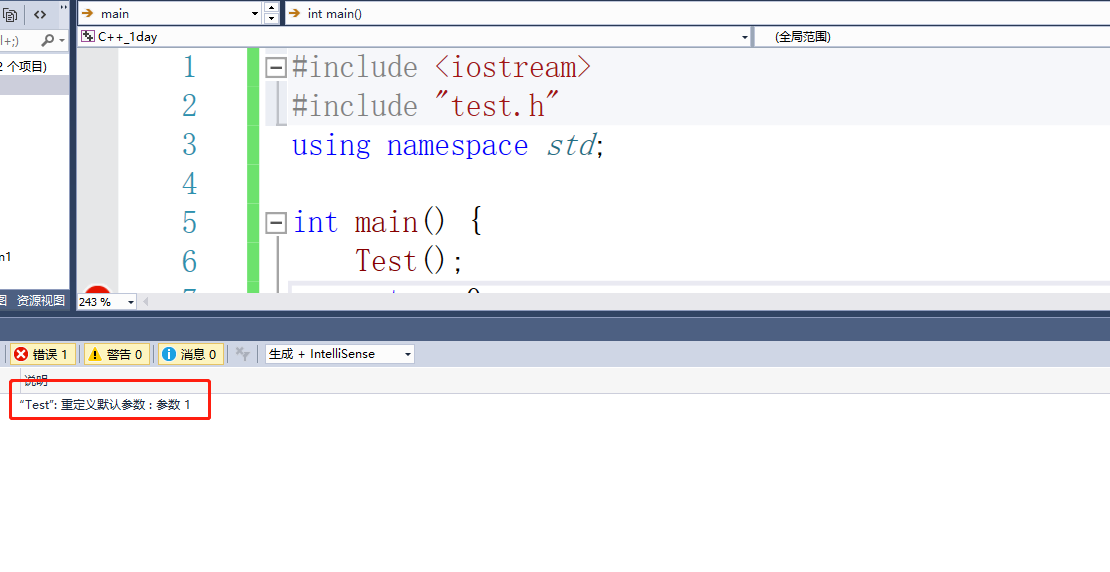
这里会报一个错误:错误 C2572 “Test”: 重定义默认参数 : 参数 1
说明我们的默认参重定义了,也就是声明和实现不能都设置默认参,我们只能将实现部分的代码修改为:
#include "test.h"
void Test(int nVal) {
}
即可,我们不能修改声明的头文件。
命名空间
命名空间也是对C语言的改进,他是来解决C语言中的命名冲突问题。
创建一个命名空间:
namespace xixi {
}
在这个作用域里,可以做全局作用域可以做的事情
namespace xixi {
int g_nVal = 9;//定义变量
void test() {//定义函数
cout << "Hello" << endl;
}
struct tagTest//定义结构体
{
int m_nVal;
float m_fVal;
};
typedef void(*PFN)();//typedef定义函数指针
}
我们来使用xixi这个命名空间
第一种用法:using namespace xixi;,这个语句表示把xixi这个命名空间里面的东西拉到当前作用域
第二种用法:
xixi::test();
xixi::tagTest t{3,4.2f};
cout << xixi::g_nVal << " " <<t.m_fVal << endl;
第三种用法:
using xixi::g_nVal;
using xixi::test;
int main() {
test();
tagTest t{3,4.2f};
cout << g_nVal << " " <<t.m_fVal << endl;
return 0;
}
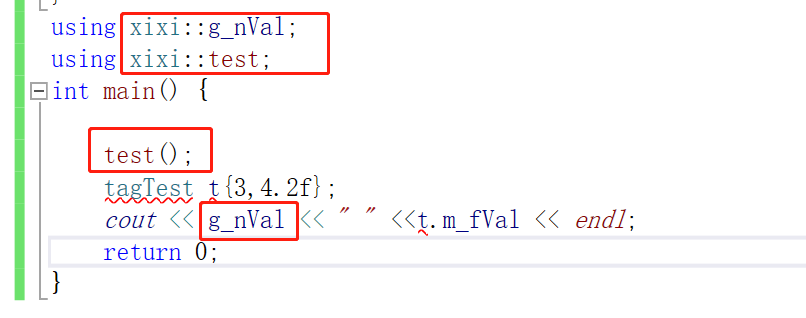
这种是把xixi中的单个内容拉到当前作用域,这种用法用的不是很多。
在做项目的时候,很少会把所有的代码都写到一个c文件或者cpp文件中,我们这个模块肯定会涉及很多文件,他们都在同一个命名空间下,所以C++的命名空间提供了一个叫命名空间拆分的方法
tset.h
#pragma once
#include <iostream>
using namespace std;
void Test(int nVal = 1);
namespace xixi {
int g_nVal = 9;
void test() {
cout << "Hello" << endl;
}
}
main.cpp
#include <iostream>
#include "test.h"
using namespace std;
using namespace xixi;
namespace xixi {
struct tagTest
{
int m_nVal;
float m_fVal;
};
typedef void(*PFN)();
}
int main() {
cout << g_nVal;
return 0;
}
这样我们就可以把这个命名空间组合起来使用了,这就是一家人不在同一个地方工作,但是永远还是一家人
这个命名空间还可以进行嵌套使用
namespace xixi {
namespace xixiInner {
int g_nVal = 10;
}
struct tagTest
{
int m_nVal;
float m_fVal;
};
typedef void(*PFN)();
}
这个作用域在使用的时候就需要using两个命名空间
using namespace xixi;
using namespace xixiInner;
int main() {
cout << g_nVal << endl;
return 0;
}
我们还可以给命名空间起一个别名
#include <iostream>
using namespace std;
namespace xixi {
int g_nVal = 10;
}
namespace xixi123 = xixi;
using namespace xixi123;
int main() {
cout << g_nVal << endl;
return 0;
}
踩个小坑:

我们来看这样一段代码:
#include <iostream>
using namespace std;
void Test() {
cout << "Test()" << endl;
}
namespace xixi {
void Test() {
cout << "xixi::Test()" << endl;
}
}
using namespace xixi;
int main() {
Test();
return 0;
}
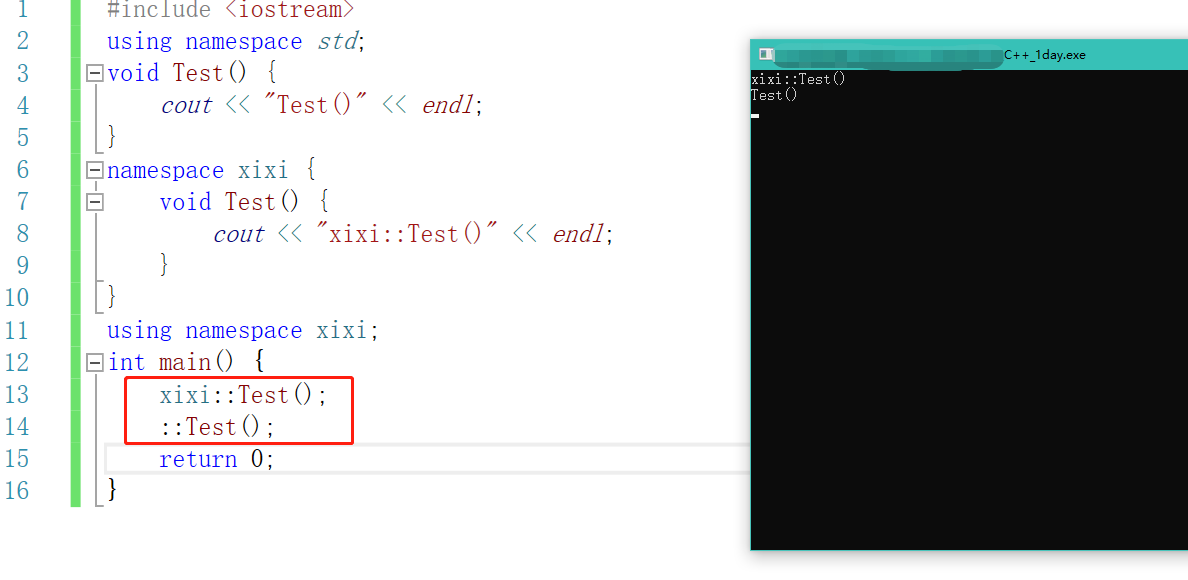
这里就会报错,因为编译器不知道调用谁,凡是让编译器做选择的操作都会报错。这时候我们应该怎么做呢?
xixi::Test();//调用命名空间中的Test
::Test();//调用全局作用域中的Test
函数重载
在C语言中,我们看这样一段代码
int Add(int n1, int n2) {
return n1 + n2;
}
float Add(float f1, float f2) {
return f1 + f2;
}
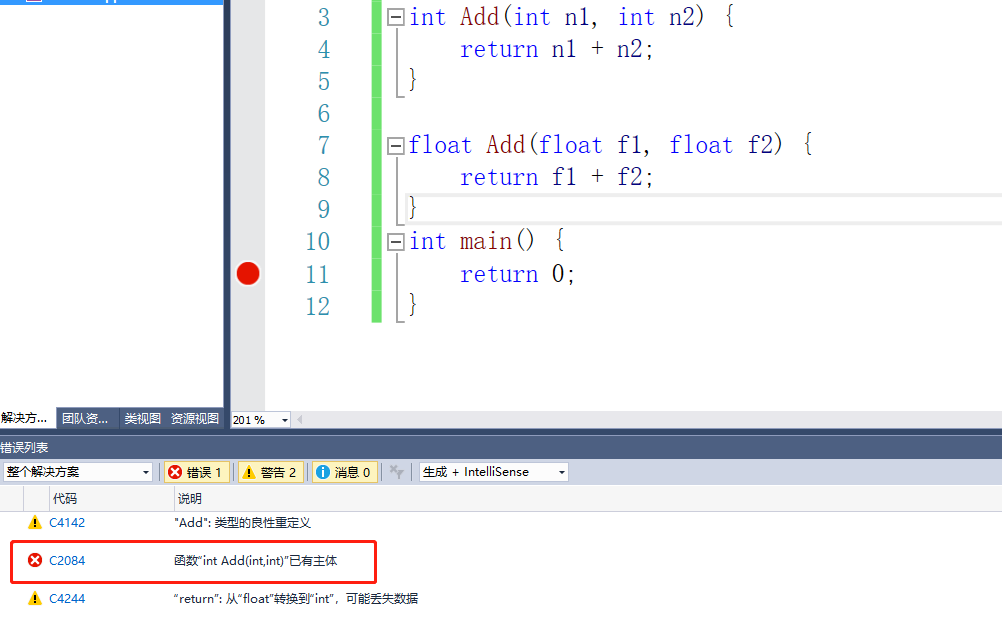
这里会报出函数重定义的错误,在C语言中函数名是不允许一样的。在C++中,引入了函数重载,允许函数重名。同样的代码我们放在cpp文件中就可以编译通过
cout << Add(3, 3) << endl;
cout << Add(3.1f, 3.2f) << endl;
使用也是没问题的
什么情况下可以构成重载呢?
我们一个函数是由:函数返回值类型,函数名,参数列表(参数类型,参数个数,参数位置),调用约定组成
我们的函数重载构成的条件:
- 同名函数
- 参数列表不同(类型、个数、位置,三个条件任意一个不同都会构成重载)
- 要注意仅仅是返回值不同是不可以构成重载的
- 仅仅调用约定不同也是不可以构成重载的
- 同作用域才可以构成重载
//作用域不同,不会构成重载
namespace xixi {
void Foo(char* szVal) {
cout << "xixi::Foo" << endl;
}
void Test() {
Foo(4);//这里会报错,因为找不到这样的函数定义
}
}
void Foo(int nVal) {
cout << "::Foo" << endl;
}
那么c++是怎么做到重载的呢?
我们把函数只定义不实现,让他报错出名称粉碎的名字:
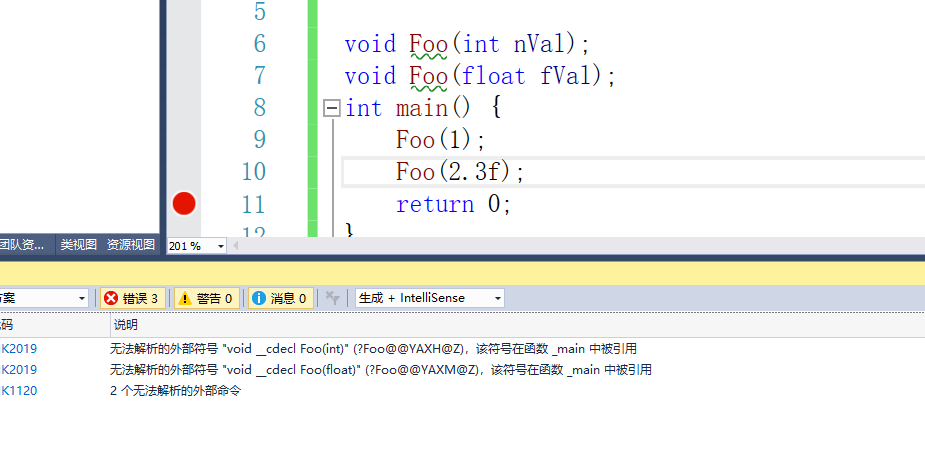
我们来使用工具还原一下这个粉碎后的名字
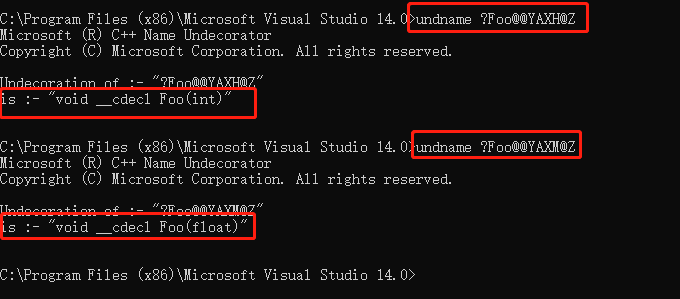
我们来看粉碎后的名称里面保存了返回值类型、调用约定、函数名和参数列表,所以c++在处理函数的时候,会对函数名进行名称粉碎就从而实现了重载。
那么为什么C语言不支持重载呢?因为C语言中并没有名称粉碎。导致函数名冲突
那么我们可以在cpp文件中调用.c的文件吗?
我们在test.c中对函数做实现,在main.cpp中做定义和调用
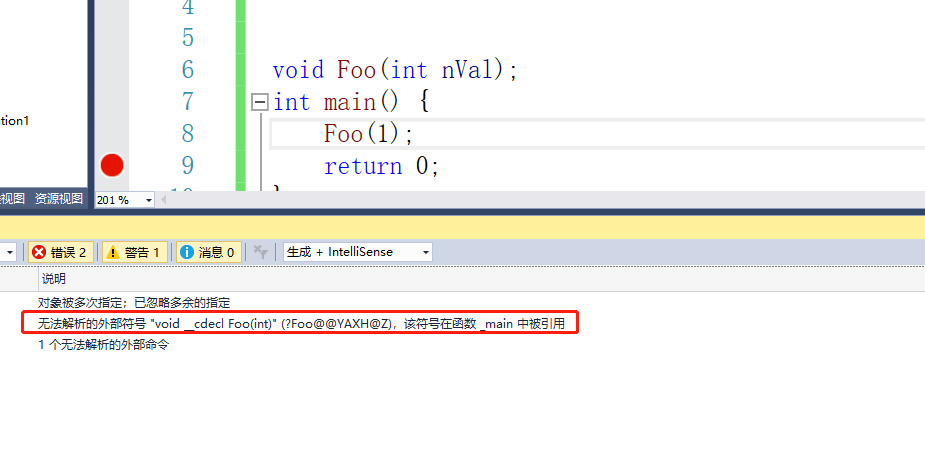
可以发现这里的报错,我们猜测是否是因为C++把函数名称粉碎才无法在.c中找到函数呢?
我们来使用extern "C" void Foo(int nVal);来声明函数,extern "C"是告诉编译器用C语言的规则来。然后我们就发现可以成功的进行编译运行了,可以调用到.c文件的函数实现中。
但是使用这种方法有一个副作用。
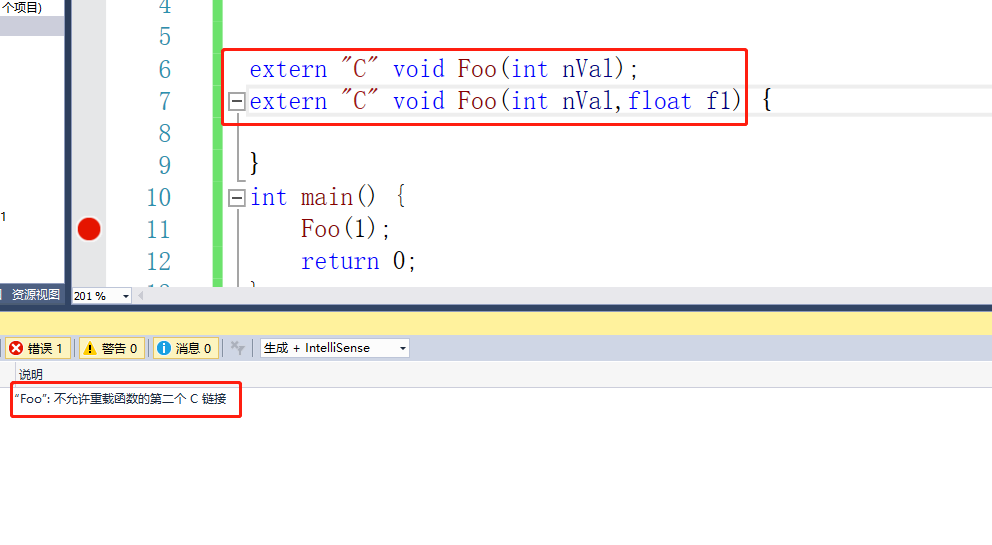
使用了extern "C"之后就不能进行函数重载了。
关于函数重载,还需要来讨论一个问题
void Foo(int n1) {
}
void Foo(float f1) {
}
int main() {
Foo(2.3);
return 0;
}
上面这段代码可以成功吗?
答案是不可以,因为调用Foo函数的参数是一个double类型,他可以强转int也可以强转float就造成了二义性,导致编译出错
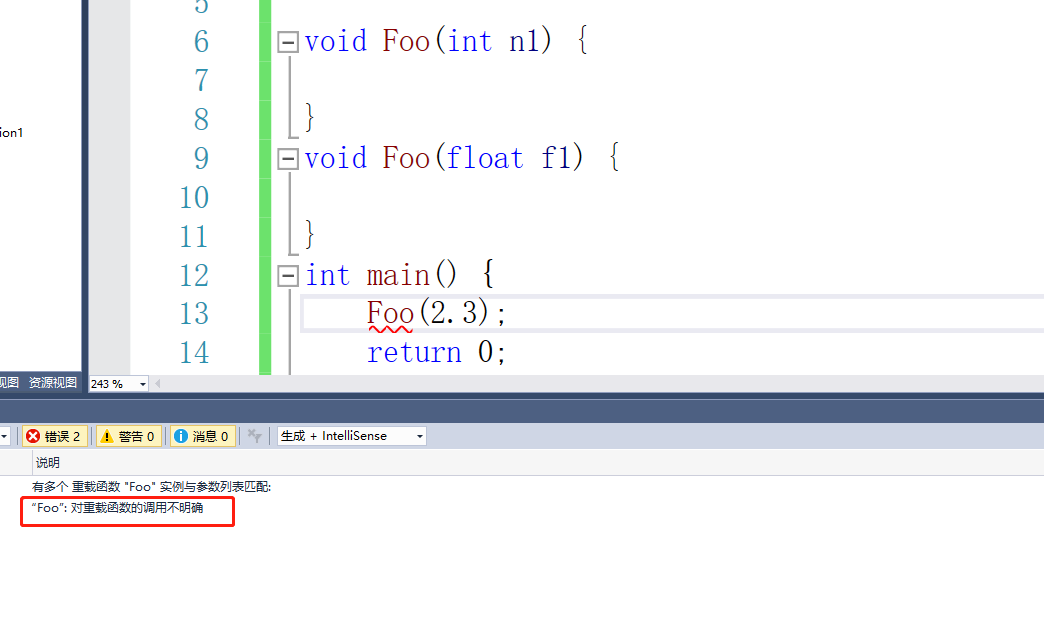
所以在我们调用重载的时候,要做到类型精确匹配(可以通过类型强转达到目的)
我们再来看这一段代码:
void Foo(int n1,float f1 = 1.2f) {
}
void Foo(int n1) {
}
int main() {
Foo(2);
return 0;
}
那么我们来看上面这段代码,有问题吗?
这个时候也是会出现二义性问题,他两个函数都符合所以就会出错。

所以默认参对函数重载也是有影响的。
内联
我们来写个比较函数
int Max(int n1, int n2) {
return n1 > n2 ? n1 : n2;
}
我在函数中使用了三元运算符,我们函数在创建的时候会有一些准备工作,那么我们思考一下在调用上面的比较函数的时候,是函数准备操作浪费时间还是执行比较浪费时间呢?
我们来回顾一下一个函数调用的过程:
- 参数入栈
- 返回地址入栈
- 调用函数(call)
- 分配栈空间(局部变量使用)
- 执行函数体
- 撤销栈空间
- 回到原函数
- 参数出栈
所以可以发现调用一个函数体很短的函数的效率是很低的,那我们怎么解决呢?
在C语言中是使用宏定义来解决这样的问题的:#define Max(x,y) (x>y?x:y)
但是我们知道宏没有类型检查也不方便调试,并且多次使用宏的话会导致程序体积增大。所以宏的缺点也很明显
C++为了解决这个问题,提出了内联。
inline int Max(int n1, int n2) {
return n1 > n2 ? n1 : n2;
}
内联函数:函数会想宏一样在调用点展开,同时会保留函数的类型检查。
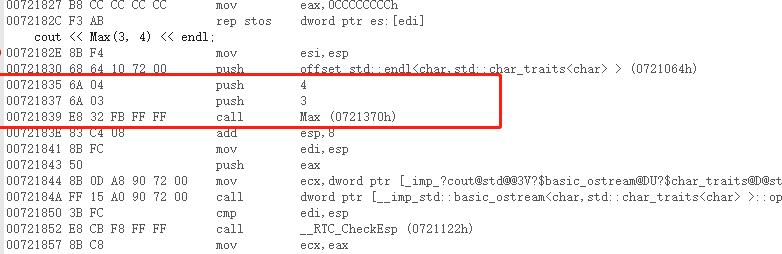
但是我们看反汇编并没有展开,依然是一个call,这是因为内联的debug版不会展开,只是为了方便调试,release是会展开的。

调整release之后就发现已经展开过了。
那所有的函数都可以被展开吗?
inline int Func(int nVal) {
if (nVal == 0)
{
return 0;
}
return nVal + Func(nVal - 1);
}
int main() {
cout << Func(8) << endl;
return 0;
}
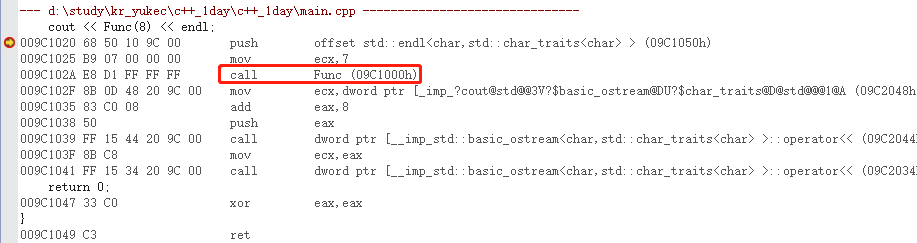
我们可以发现在Release下并没有展开,所以inline是建议编译器进行内联展开,但是是否能展开成功要看编译器了。
当我们将内联函数的声明和定义分开:
test.h
#pragma once
inline int Max(int n1,int n2);
test.cpp
#include "test.h"
inline int Max(int n1, int n2)
{
return n1 > n2 ? n1 : n2;
}
我们在main函数中进行调用,编译会发现报错

报错找不到实现,因为内联函数是文件作用域,出了那个文件就用不了了。所以一般我们就直接把内联函数的声明和实现都写到头文件中
test.h
#pragma once
inline int Max(int n1, int n2)
{
return n1 > n2 ? n1 : n2;
}
面向对象
面向对象的编程思想
四大核心概念:抽象、封装、继承、多态
抽象:
代码中会出现一些不通用的代码,也就是会变化的代码,我们的抽象就是把这些代码抽出来,让他变得可以复用。
举个例子就是我们要来写一个游戏,这个游戏一开始只需要鼠标键盘来操作,在下一个版本中需要改为手势操作。这时候我们是不是就需要把操作游戏的键盘鼠标修改为手势,过几天又要改成用脚操作。这时候就已经开始麻了。我们不管是键盘鼠标还是手势和脚,我们都可以理解为是一个输入,我们就把输入抽出来,给他一个设置选项让他来自己选。再加新需求只需要加选项和功能代码就好了
封装:
#include <iostream>
using namespace std;
#define NAMELEN 32
struct tagPlayer
{
char m_szName[NAMELEN];
int m_nX;
int m_nY;
};
tagPlayer g_player = {"GM",1,1};
int main() {
while (true) {
char chInput;
cin >> chInput;
switch (chInput)
{
case 'w':
g_player.m_nY++;
break;
case 'a':
g_player.m_nX--;
break;
case 's':
g_player.m_nY--;
break;
case 'd':
g_player.m_nX++;
break;
default:
break;
}
cout << "玩家:" << g_player.m_szName << " X: " << g_player.m_nX << " Y: " << g_player.m_nY << endl;
}
return 0;
}
这是一份刚学习编程的代码,看起来很烂,我们看看可以怎么修改这个代码呢?
- 我们在功能中直接访问了成员,如果我们成员变量名修改的时候,是不是就需要修改掉所有使用到这个成员变量的地方,当工程量较大的时候,就很难改了。
我们就可以把这些东西封装到一个函数中,让外面使用函数来访问,就需要写一个get和set方法,一个访问一个设置。
#include <iostream>
using namespace std;
#define NAMELEN 32
struct tagPlayer
{
char m_szName[NAMELEN];
int m_nX;
int m_nY;
};
tagPlayer g_player = {"GM",1,1};
inline void SetName(const char* szName) {
strcpy(g_player.m_szName,szName);
}
inline const char* GetName() {
return g_player.m_szName;
}
inline void SetY(int nY) {
g_player.m_nY = nY;
}
inline int GetY() {
return g_player.m_nY;
}
inline void SetX(int nX) {
g_player.m_nX = nX;
}
inline int GetX() {
return g_player.m_nX;
}
int main() {
while (true) {
char chInput;
cin >> chInput;
switch (chInput)
{
case 'w':
SetY(GetY()+1);
break;
case 'a':
SetX(GetX() - 1);
break;
case 's':
SetY(GetY() - 1);
break;
case 'd':
SetX(GetX() + 1);
break;
default:
break;
}
cout << "玩家:" << GetName() << " X: " << g_player.m_nX << " Y: " << g_player.m_nY << endl;
}
return 0;
}
这样封装起来是不是就好很多,需要修改成员变量的时候,只需要修改函数里面即可,这就叫做封装,但是呢这份代码依然有问题,因为他抽象失败了。假设现在我要再加一个玩家,但是这些所有的操作都是对应了g_player的玩家,所以代码根本不通用,导致抽象失败。我们再来修改一下
#include <iostream>
using namespace std;
#define NAMELEN 32
struct tagPlayer
{
char m_szName[NAMELEN];
int m_nX;
int m_nY;
};
tagPlayer g_players[] = {
{"GM",1,1} ,
{ "Xa",1,1 } ,
{ "Ba",1,1 } ,
{ "Wa",1,1 } ,
};
inline void SetName(tagPlayer* pPlaer, const char* szName) {
strcpy(pPlaer->m_szName,szName);
}
inline const char* GetName(tagPlayer* pPlaer) {
return pPlaer->m_szName;
}
inline void SetY(tagPlayer* pPlaer,int nY) {
pPlaer->m_nY = nY;
}
inline int GetY(tagPlayer* pPlaer) {
return pPlaer->m_nY;
}
inline void SetX(tagPlayer* pPlaer,int nX) {
pPlaer->m_nX = nX;
}
inline int GetX(tagPlayer* pPlaer) {
return pPlaer->m_nX;
}
int main() {
while (true) {
char chInput;
cin >> chInput;
switch (chInput)
{
case 'w':
for (auto& player:g_players)
{
SetY(&player,GetY(&player) + 1);
}
break;
case 'a':
for (auto& player : g_players)
{
SetX(&player,GetX(&player) - 1);
}
break;
case 's':
for (auto& player : g_players)
{
SetY(&player,GetY(&player) - 1);
}
break;
case 'd':
for (auto& player : g_players)
{
SetX(&player,GetX(&player) + 1);
}
break;
default:
break;
}
for (auto& player : g_players)
{
cout << "玩家:" << GetName(&player) << " X: " << GetX(&player) << " Y: " << GetY(&player) << endl;
}
}
return 0;
}
这样是不是就简单地抽象出来了。假设我们现在要在这个游戏中加入职业,那么怎么去进一步的抽象呢?这个大家可以思考一下。
类
虽然我们在前面做了简单地封装了,但是在其他地方调用成员还是会破坏掉封装性,所以我们引入了类来限制成员的访问
关键字:class
我们来定义一个类:
Point.h
#pragma once
class CPoint
{
int m_nX;
int m_nY;
};
接着我们在main.cpp中引用头文件并且实例化一个对象
#include <iostream>
#include "Point.h"
using namespace std;
int main()
{
CPoint pt;//实例化一个对象
return 0;
}
我们去访问一下这个对象的成员:pt.m_nX = 1;,这里我们会发现报错。无法访问 private 成员

通过这样我们可以做到防止破坏封装性的访问,强制让我们使用Get和Set函数去操作,那么我们来写这两个函数
Point.h
class CPoint
{
int m_nX;
int m_nY;
public:
int GetX() const { return m_nX; }
void SetX(int val) { this->m_nX = val; }
int GetY() const { return m_nY; }
void SetY(int val) { this->m_nY = val; }
};
这里的this是this指针,这个指针就是指向成员函数作用的对象,在成员函数执行的过程中,正是通过“this指针”才能找到对象所在的地址,因而也就能找到对象的所有非静态成员变量的地址。
这里把Get和Set设置为Public权限,使得可以通过对象访问到。那么我们再来修改一下程序
#include <iostream>
#include "Point.h"
using namespace std;
int main()
{
CPoint pt;
pt.SetY(1);
return 0;
}
这时候就会发现没有问题了。
我们刚才使用的public就是访问权限控制的关键字,在这里我们先说两个:public - 公有、private - 私有,公有的情况下我们可以从外部直接访问,但是私有就是不允许从外部访问,当我们一开始没有写控制关键字的时候,默认就是私有
我们来对比一下结构体和类:
#include <iostream>
using namespace std;
struct tagTest
{
int m_nVal;
};
class CTest
{
int m_nVal;
};
int main()
{
CTest ct;
tagTest t;
t.m_nVal = 0;
ct.m_nVal = 9;
return 0;
}
这时候我们会发现使用类的时候不能直接访问到,结构体默认是public,类默认是private。这个public和private在类和结构体中都是可以使用的,类和结构体唯一的区别就是默认属性不一样,这里只是C++的用法,在C语言中是不可以这样的
内存结构
我们来写一个结构体和类来对比一下:
struct tagTest
{
char m_ch;
int m_n;
char m_ary[5];
short m_sn;
__int64 m_n64;//64位成员
int m_n1;
};
class CTest{
char m_ch;
int m_n;
char m_ary[5];
short m_sn;
__int64 m_n64;//64位成员
int m_n1;
};
我们来分析一下在结构体中内存的排布,他们是会默认对齐的,默认对齐值是8。如果类型比对齐值小,按照类型对齐。
tagTest tt;
CTest ct;
cout << sizeof(tt) << endl;
cout << sizeof(ct) << endl;
发现这个两个结构体和类的大小都是32字节,那么内存排布是否是一样的?
// C++_day2.cpp : 定义控制台应用程序的入口点。
//
#include "stdafx.h"
#include <iostream>
using namespace std;
struct tagTest
{
char m_ch;
int m_n;
char m_ary[5];
short m_sn;
__int64 m_n64;
int m_n1;
};
class CTest{
public:
char m_ch;
int m_n;
char m_ary[5];
short m_sn;
__int64 m_n64;//64位成员
int m_n1;
};
int main()
{
tagTest tt;
CTest ct;
cout << sizeof(tt) << endl;
cout << sizeof(ct) << endl;
tt.m_ch = 0x11;
tt.m_n = 0x22222222;
memset(tt.m_ary, 0x33, sizeof(tt.m_ary));
tt.m_sn = 0x4444;
tt.m_n64 = 0x5555555555555555;
tt.m_n1 = 0x66666666;
ct.m_ch = 0x11;
ct.m_n = 0x22222222;
memset(ct.m_ary, 0x33, sizeof(ct.m_ary));
ct.m_sn = 0x4444;
ct.m_n64 = 0x5555555555555555;
ct.m_n1 = 0x66666666;
return 0;
}
下断点调试一下,使用两个内存窗口观察ct和tt
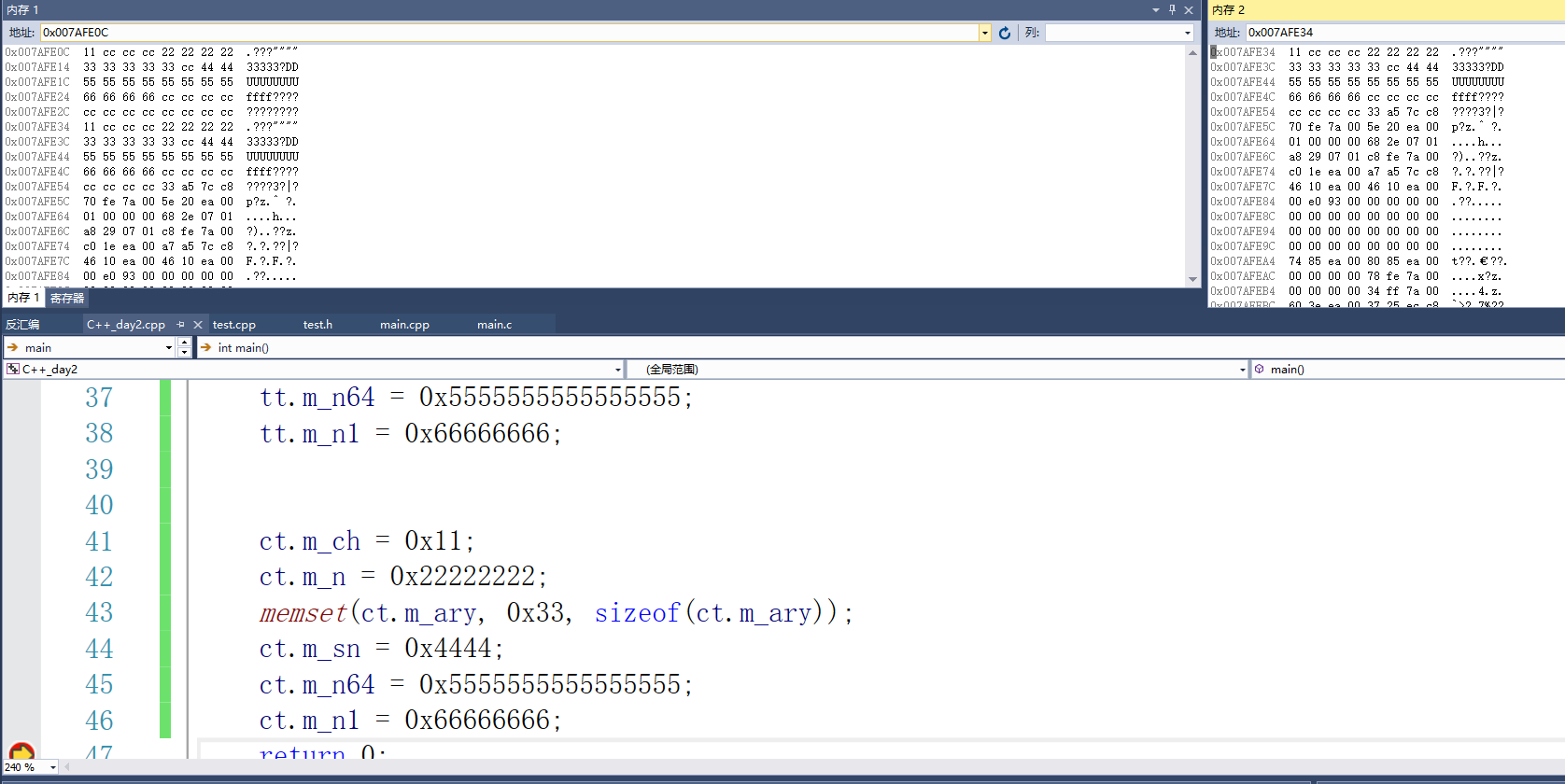
我们发现C++的类和C语言的结构体的成员在内存中的布局规则是一致的(在学习多态之前)
this指针
#include <iostream>
using namespace std;
class CTest{
public:
void SetVal(int nVal) {
m_nVal = nVal;
}
private:
int m_nVal;
};
int main()
{
CTest t;
cout << sizeof(t) << endl;
return 0;
}
我们会发现输出的只有四个字节,只有成员,没有成员函数,那我们的成员函数去哪了呢?
我们来思考一下,对于不同的对象,成员是独享的还是共享的呢?很明显是独有的。但是对成员函数呢?是独有还是共享的?
我们来调用一下看看两个对象是否是调用了同样地址的成员函数
int main()
{
CTest t;
t.SetVal(0x87654321);
CTest t1;
t1.SetVal(0x88888888);
return 0;
}
我们分别对两次调用的地方下断点,然后去单步调试看一下地址。
第一次调用:00C416D0

第二次调用:00C416D0
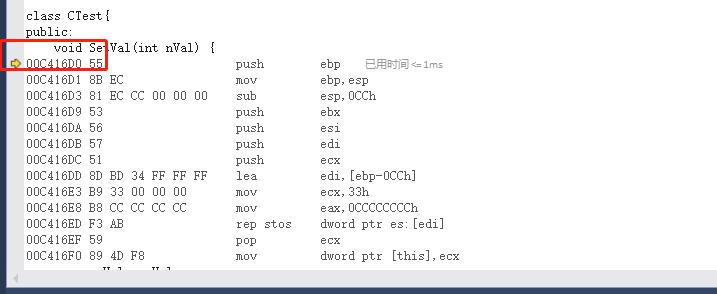
我们可以发现地址是同一个,那么证明不同的对象,数据成员是独有的,成员函数是共享的。
那么新的问题是,我们执行t.SetVal(0x87654321);的时候,是把0x87654321给了对象t的成员,那SetVal怎么知道我们给的是哪个m_nVal呢?
这个东西就叫做this指针,它里面存储了对象的首地址
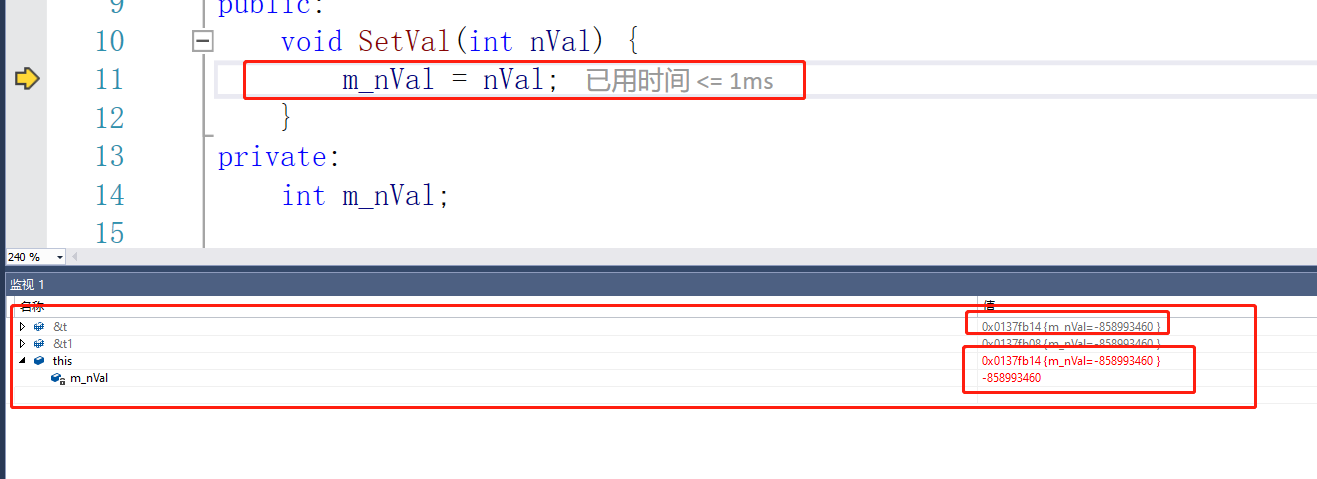
用this指针来区别对象。
编译调用成员函数的时候,会默认传入this指针,this指针指向了调用函数的对象的首地址。
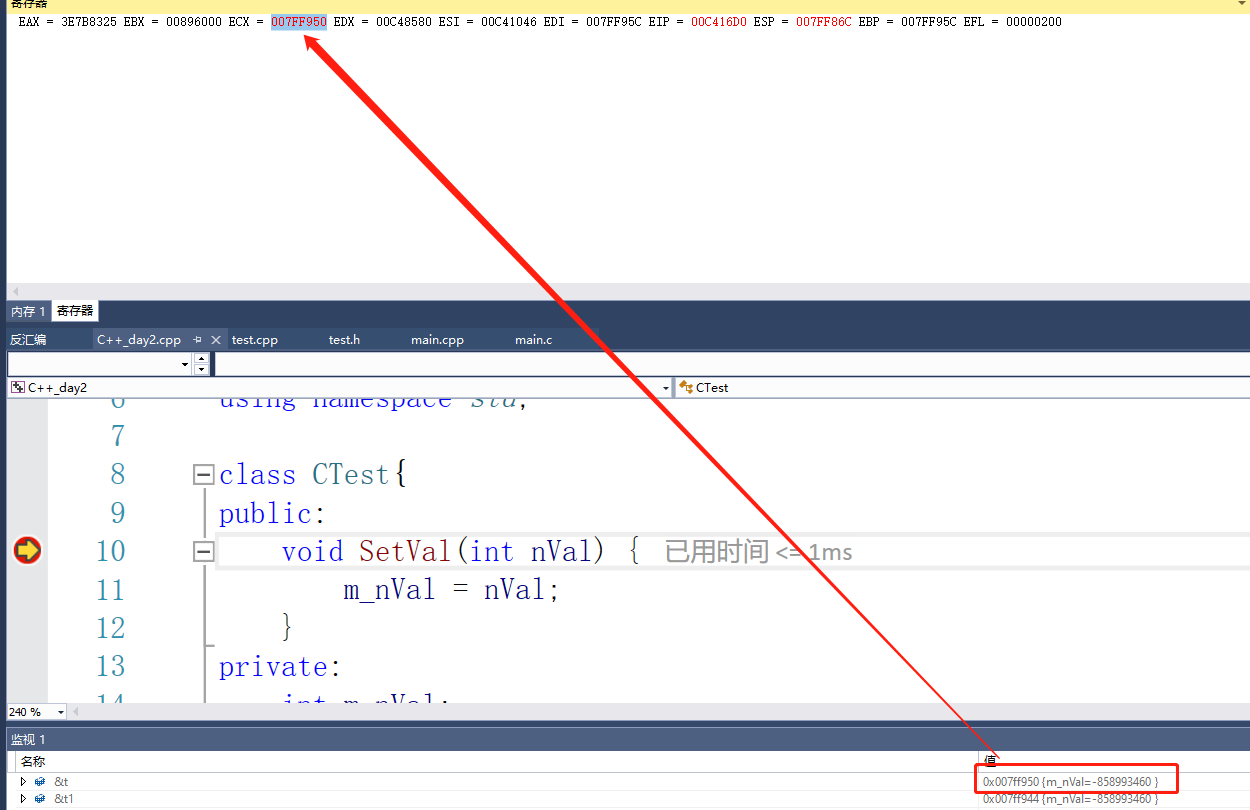
而且this指针是通过ecx寄存器传入的。这里使用的调用约定是__thiscall

这种调用约定是成员独有的,它只能用在成员函数上面,其他的是无法使用这种调用约定的。如果我们把它的调用约定修改了呢?
void __cdecl SetVal(int nVal) {
m_nVal = nVal;
}
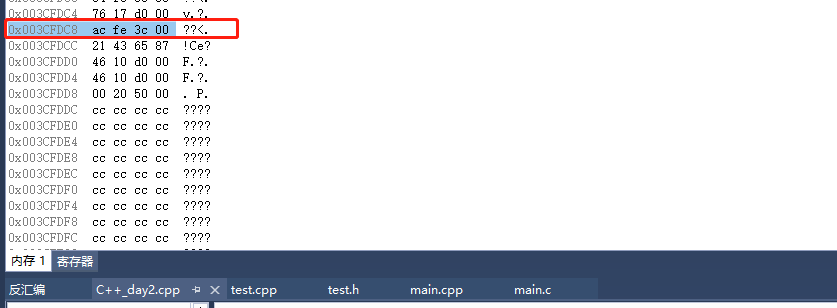
这时候参数和返回地址之间就多出来了一个this指针,传参方式就发生了改变,其他的__stdcall等等也都是可以的。
也就是说成员函数的调用约定是可以修改的,但是不建议修改。
这时候有一个新问题,我们的this可以修改吗?
this = nullptr;,这里就报错了。

我们来看一下this指针的类型。
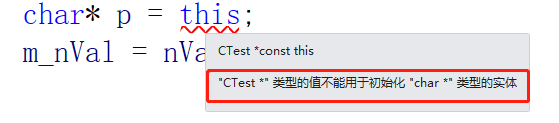
CTest* const this这种修饰方式:指针本身不能被修改,但是指针指向的内容可以被修改,this不能被修改,但是this指向的成员可以被修改。
但是我们非要去修改this指针有办法吗?
我们取消地址随机化,先拿到t的this指针地址,我们把成员函数修改为__cdecl,让this指针通过栈传入,然后*(&nVal - 1) = 0x0019fee8;把所有传入的this指针都指向t,这样我们修改t1的时候其实还是在修改t。
我们来测试一下
构造函数和析构函数
我们来做一个动态分配内存的类。
#include <iostream>
using namespace std;
class CBuff {
public:
void SetData(const char* pData, int nCount)
{
m_nCount = nCount;
m_pBuffer = (char*)malloc(m_nCount);
memcpy(m_pBuffer,pData,m_nCount);
}
const char* GetData() {
return m_pBuffer;
}
private:
char* m_pBuffer;
int m_nCount;
};
int main()
{
CBuff buf;
buf.SetData("hello", 6);
cout << buf.GetData() << endl;
return 0;
}
这里如果连续setData两次呢?
buf.SetData("hello", 6);
buf.SetData("world", 6);
这里是不是申请了两次内存,第一次申请的内存没有释放掉。
我们加上释放:
if (m_pBuffer != nullptr)
{
free(m_pBuffer);
m_pBuffer = nullptr;
m_nCount = 0;
}
这样加上判断还会有问题吗?
Debug版本默认会把栈上的数据初始化位0xCCCCCCCC,所以我们的判断根本就是无效的。本质上来说是我们CBuff类缺少一个初始化函数。
我们就需要给它加一个初始化的函数:
bool Init() {
m_pBuffer = nullptr;
m_nCount = 0;
return true;
}
那我们是不是需要再写一个清理所有资源的函数。
void UnInit() {
if (m_pBuffer != nullptr)
{
free(m_pBuffer);
m_pBuffer = nullptr;
m_nCount = 0;
}
}
这样就比较完美了
我们现在是手动实现了初始化函数,缺点很明显,需要手动,容易忘记,而且可能会多次调用初始化,那怎么来做到自动调用初始化和清理呢?
所以引入了构造和析构函数来解决这个问题。
构造函数(初始化函数):函数名和类名相同,没有返回值,可以有参数,可以带默认参,可以重载
CBuff(const char* pData = nullptr, int nCount = 0) {
if (pData == nullptr)
{
m_pBuffer = nullptr;
m_nCount = 0;
}
else
{
m_nCount = nCount;
m_pBuffer = (char*)malloc(m_nCount);
memcpy(m_pBuffer, pData, m_nCount);
}
}
CBuff(int nVal) {
m_pBuffer = nullptr;
m_nCount = 0;
m_nVal = nVal;
}
析构函数(反初始化函数):函数名和类名相同,前面加~,无参无返回值,不能重载。
~CBuff() {
if (m_pBuffer != nullptr)
{
free(m_pBuffer);
m_pBuffer = nullptr;
m_nCount = 0;
}
}
我们的析构函数是在对象被销毁后调用的。
如何去手动调用构造函数和析构函数呢?
buf.CBuff::CBuff("test",5);//手动调用构造函数
buf.~CBuff();//手动调用析构函数
构造和析构函数可以手动调用,但是一般不推荐手动调用。
构造的花式调用方式:
CBuff buf0;
CBuff buf1("Hello", 6);
CBuff buf2 = 4;
CBuff buf3 = { 7 };
CBuff buf4 = { "hh",3 };
CBuff buf5{ "66",3 };
new和delete
我们在堆里实例化一个对象该怎么做呢?
CBuff* pBuf = (CBuff*)malloc(sizeof(CBuff));,我们确实可以通过malloc去创建,但是这里malloc去申请的时候并没有调用构造函数。那么我们只能手动的来做这一系列操作
CBuff* pBuf = (CBuff*)malloc(sizeof(CBuff));
pBuf->CBuff::CBuff();
pBuf->~CBuff();
free(pBuf);
为了修正这个问题,C++提供了new和delete
CBuff* pBuf = new CBuff(0x87654321);
delete pBuf;
这里的new相当于是申请了一块堆,然后调用了构造函数。
这里的delete相当于调用了析构函数,然后释放了内存。
如果我们需要一下子申请5个这样的对象呢?
CBuff* pBufAry = new CBuff[5];,这样就会调用五次构造
delete[] pBufAry;,我们释放多个对象的时候使用delete[]。

那他是怎么知道我们这有5个对象要被delete掉呢?

这里说明他在new的时候把数组的个数也存进去了。
如果我们不用delete[]而是使用delete会出现什么样的结果?
这里会出现崩溃,释放堆内存失败了。
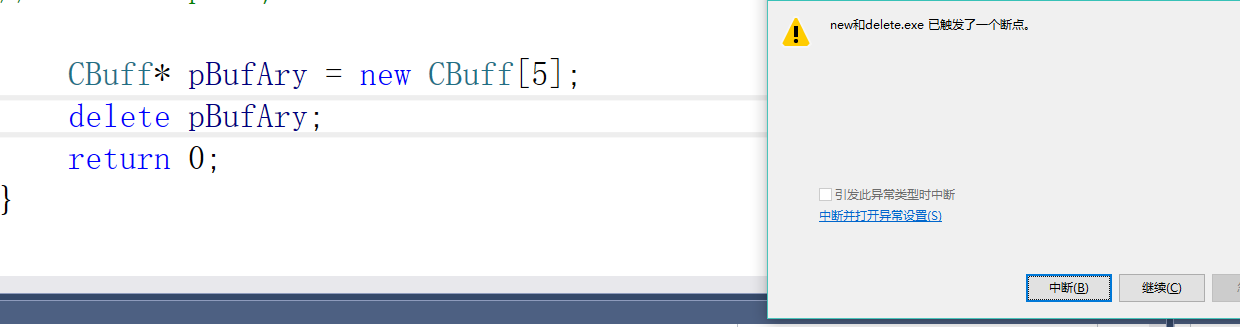
我们来看一下为什么会出现这种情况:
在new的时候,他会在对象数组的前面放一个数值,对于这一块堆来说,他的真正起始地址在fd后面,如果把数值后面当做起始地址,那么在释放堆得时候会读取配置信息,往前面读取四个字节的配置,读错了就产生了崩溃。
如果是因为这个问题的话,那么我们把地址-4是不是就可以读到正确的地址了呢?
delete (CBuff*)((int*)pBufAry-1);
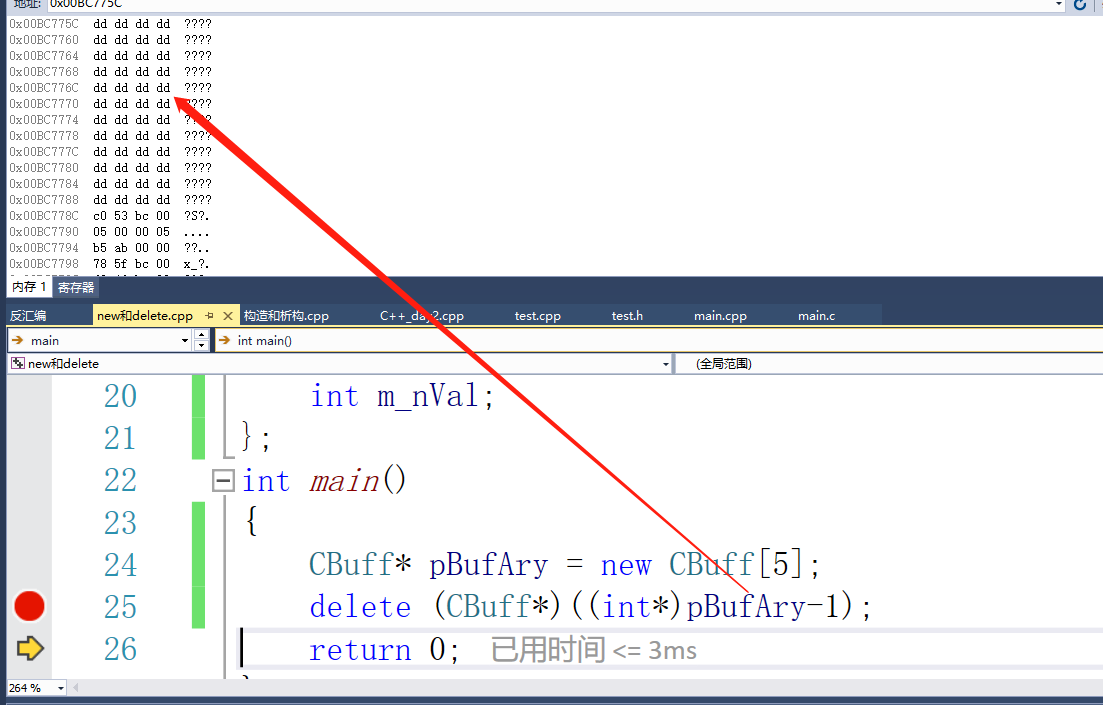
可以看的到堆内存被成功地释放了。
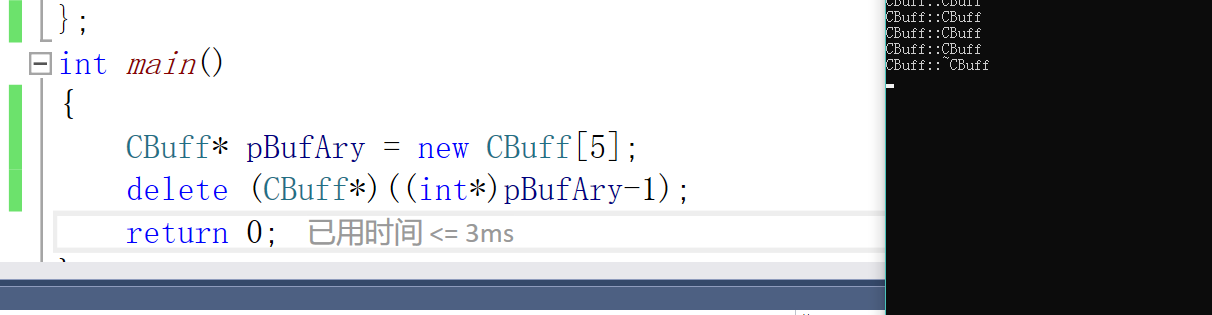
但是他却只调用了一次析构函数,那么我们能不能有这种操作,我们把堆空间前面的计数值给修改掉,会不会析构的次数也会更改
(*((int*)pBufAry - 1))--;我们来让这个数值减一。

果然就少析构一次了.
所以我们需要注意:在实际使用的过程中,两两配对使用,new和delete配对使用,new[]和delete[]配对使用。
拷贝构造和CMyString
拷贝构造
我们先把之前的一个类复制一个,我们直接用之前写过的类:
class CBuff {
public:
CBuff(const char* pData = nullptr, int nCount = 0) {
if (pData == nullptr)
{
m_pBuffer = nullptr;
m_nCount = 0;
}
else
{
m_nCount = nCount;
m_pBuffer = (char*)malloc(m_nCount);
memcpy(m_pBuffer, pData, m_nCount);
}
}
~CBuff() {
if (m_pBuffer != nullptr)
{
free(m_pBuffer);
m_pBuffer = nullptr;
m_nCount = 0;
}
}
void SetData(const char* pData, int nCount)
{
if (m_pBuffer != nullptr)
{
free(m_pBuffer);
m_pBuffer = nullptr;
m_nCount = 0;
}
m_nCount = nCount;
m_pBuffer = (char*)malloc(m_nCount);
memcpy(m_pBuffer, pData, m_nCount);
}
const char* GetData() {
return m_pBuffer;
}
private:
char* m_pBuffer;
int m_nCount;
};
我们来写一个函数
void Test(CBuff bufArg) {
cout << bufArg.GetData() << endl;
}
然后我们在main函数调用
CBuff buf("Hello",6);
Test(buf);
这里是可以编译通过的,但是执行是会崩溃的。
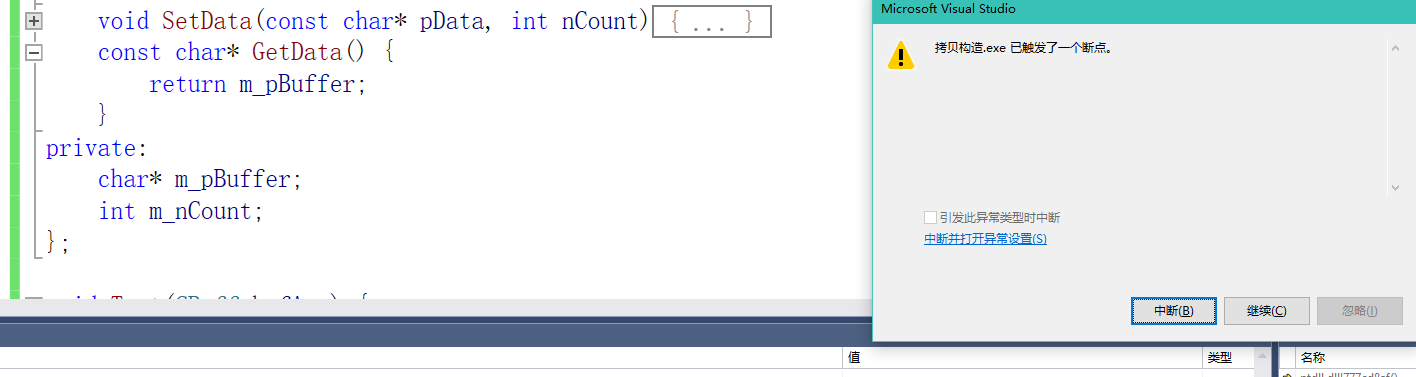
这里我们来单步调试看一下为什么会产生崩溃。
我们发现在Test函数结束的时候,调用了析构函数,但是在程序return 0的时候还是会调用一次析构,导致了对同一块内存的两次释放
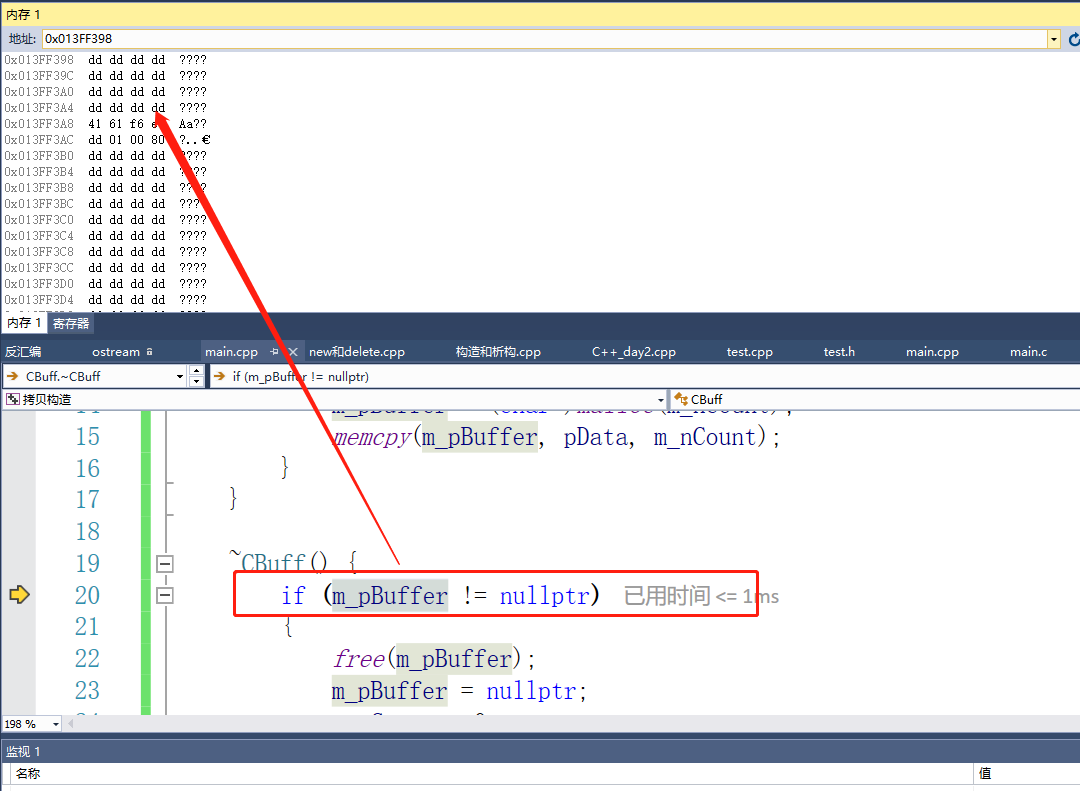
为什么会这样呢?我们发现在调用Test把buf传过去的时候并没有再一次调用析构,相当于是在做值拷贝。也就是直接把buf的内存地址拷贝给了bufArg。也就是这两个指针指向了同一个地址,当Test函数调用完,回去调用bufArg的析构,从而顺手把buf给摧毁。导致了return 0去调用释放的时候产生了二次释放。
那么我们该怎么去解决这个问题呢?
第一个方法:我们可以使用引用的方法
void Test(CBuff& bufArg) {
cout << bufArg.GetData() << endl;
}
第二个方法:使用拷贝构造
CBuff(const CBuff& buf) {
cout << "CBuff(const CBuff& buf)" << endl;
}
这就是一个拷贝构造的原型,我们来在拷贝构造函数里面实现一个深拷贝。
CBuff(const CBuff& buf) {
cout << "CBuff(const CBuff& buf)" << endl;
//深拷贝
m_nCount = buf.m_nCount;
m_pBuffer = (char*)malloc(buf.m_nCount);
memcpy(m_pBuffer, buf.m_pBuffer, m_nCount);
}
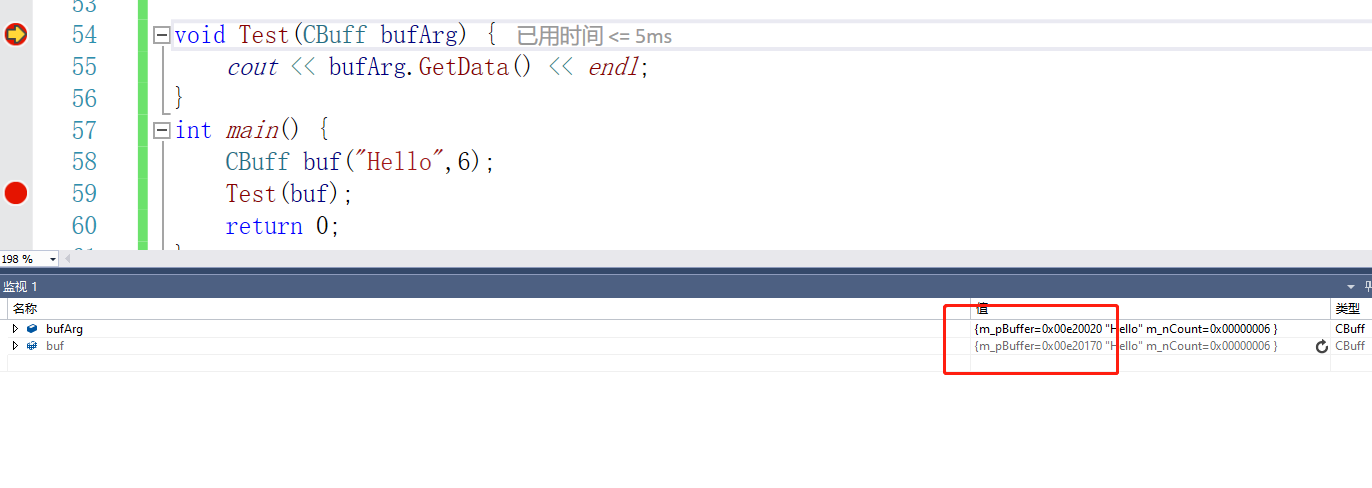
然后我们再来跑就不会崩溃了。
我们来总结一下:
- 当我们没有实现拷贝构造的时候,编译器会默认生成一个拷贝构造,其功能就是一个内存拷贝(浅拷贝)
- 当有拷贝构造的时候就调用拷贝构造
- 拷贝构造常见的出现时机:
3.1 类对象传参 Test(buf);
3.2 定义一个类对象 CBuff buf0(buf);
3.3 类对象作为返回值 return buf; - 无名对象(临时对象)
4.1 类对象作为返回值
4.2 直接创建一个无名对象CBuff()
4.3 以行为结束执行析构(;结束)
那么我们现在来看一个东西:Test(CBuff("66",3));它会调用几次构造几次析构呢?
这里只会调用一次构造一次析构。是不是很离谱。
正常来说确实应该是两次构造两次析构,但是编译器把它优化掉了,直接拿无名对象的参数去构造形参。换了编译器可能就不会优化了。
CMyString
我们平时使用字符串的时候是这样的:char* szBuff = "hello";这样对字符串的操作非常不方便,为了可以增删改,我们往往还需要去把它放到一个数组里面char* szArr = new char[16];,然后再去strcpy,这样使用起来还是很不方便,因为长度是固定的,像拼接一段还要考虑长度是否够用。
为了方便我们去操作字符串,我们去写一个CMyString,把定长数组改成变长。
我们对于字符串的操作一般会有什么呢?
- 字符串初始化大小
- 字符串拼接
- 字符串查找
- 字符串替换
- 字符串拷贝
- 获取字符串长度
- 提取子串
- 字符串分割【不太好做,需要用到数据结构的知识】
- 去除空白字符
细分:
查找:正向查找、反向查找
提取子串:左侧提取、右侧提取、中间提取
格式化字符串
我们开始创建项目并且添加第一个类,我们右键项目可以直接添加类
我们先把函数声明都写出来
MyString.h
#pragma once
class CMyString
{
public:
CMyString();
CMyString(const char* szStr);//有参构造
CMyString(const CMyString& szStr);//拷贝构造
~CMyString();
//获取字符串长度
int GetStringLen();
//拼接
void Append(const char* szStr);
void Append(const CMyString& str);
//查找:找不到返回-1,找到了返回索引
int Find(const char* szStr);
int Find(const CMyString& str);
int ReverseFind(const char* szStr);
int ReverseFind(const CMyString& str);
//替换 - 把src替换成dest
void Replace(const char* szSrc,const char* szDest);
void Replace(const CMyString& strSrc, const CMyString& strDest);
//指定位置替换
void Replace(int nIdxBegin, const char* szSrc, const char* szDest);
void Replace(int nIdxBegin,const CMyString& strSrc, const CMyString& strDest);
//拷贝
void Copy(const char* szStr);
void Copy(const CMyString& str);
//提取子串:左侧提取、右侧提取、中间提取
CMyString Mid(int nIdx,int nLen);//从索引nIdx开始提取nLen个字节为新的字符串
CMyString Left(int nLen);//从字符串左侧开始提取nLen个字节为新的字符串
CMyString Right(int nLen);//从字符串右侧开始提取nLen个字节为新的字符串
//分割
//去除空白字符
void Strip();//去除空格、tab、回车
//格式化
void Format(const char* szFmt, ...);
const char* GetString();
private:
char* m_pStrBuff;//指向字符串的缓冲区
int m_nBuffLen;//缓冲区的大小[Capacity]
int m_nStrLen;//缓冲区中字符串的大小
};
我们这里就简单实现几个接口,其他的大家自己来实现。
首先默认构造函数,我们来直接置空
CMyString::CMyString()
{
m_pStrBuff = nullptr;
m_nBuffLen = 0;
m_nStrLen = 0;
}
我们来写这个重载的构造函数,初始化数据
CMyString::CMyString(const char* szStr)
{
m_nStrLen = strlen(szStr);//存的是字符串的长度
m_nBuffLen = m_nStrLen + 1;//缓冲区需要存储\0,所以要在字符串长度的基础上+1
m_pStrBuff = new char[m_nBuffLen];
strcpy(m_pStrBuff, szStr);
}
然后实现拷贝构造:
CMyString::CMyString(const CMyString& szStr)
{
m_nBuffLen = szStr.m_nBuffLen;
m_nStrLen = szStr.m_nStrLen;
m_pStrBuff = new char[m_nBuffLen];
strcpy(m_pStrBuff, szStr.m_pStrBuff);
}
我们发现这个拷贝构造和前面的有参构造很像,这就导致我们的代码重用率很低,所以我们来封装一个函数。
我们在头文件中定义:
private:
void SetStr(const char* szStr);
然后实现一下它。
void CMyString::SetStr(const char* szStr)
{
m_nStrLen = strlen(szStr);//存的是字符串的长度
m_nBuffLen = m_nStrLen + 1;//缓冲区需要存储\0,所以要在字符串长度的基础上+1
m_pStrBuff = new char[m_nBuffLen];
strcpy(m_pStrBuff, szStr);
}
那么我们刚才的两处构造就可以修改掉了
CMyString::CMyString(const char* szStr)
{
SetStr(szStr);
}
CMyString::CMyString(const CMyString& szStr)
{
SetStr(szStr.m_pStrBuff);
}
然后完善一下析构函数
CMyString::~CMyString()
{
if (m_pStrBuff!=nullptr)
{
delete[] m_pStrBuff;
m_pStrBuff = nullptr;
m_nBuffLen = 0;
m_nStrLen = 0;
}
}
我们来调用一下看看效果
#include <iostream>
#include "MyString.h"
using namespace std;
int main() {
CMyString str;
CMyString str1("Hello world");
CMyString str2(str1);
CMyString str3(str);
return 0;
}
运行崩溃了。我们需要去设置字符串的函数里面做个检查
void CMyString::SetStr(const char* szStr)
{
if (szStr == nullptr)
{
m_pStrBuff = nullptr;
m_nBuffLen = 0;
m_nStrLen = 0;
}
else
{
m_nStrLen = strlen(szStr);//存的是字符串的长度
m_nBuffLen = m_nStrLen + 1;//缓冲区需要存储\0,所以要在字符串长度的基础上+1
m_pStrBuff = new char[m_nBuffLen];
strcpy(m_pStrBuff, szStr);
}
}
那这样的话,我们的默认构造函数可以修改为:
CMyString::CMyString()
{
SetStr(nullptr);
}
我们修改好之后再次运行看看发现没有问题
CMyString str;
CMyString str1("Hello world");
CMyString str2(str1);
CMyString str3(str);
cout << "str1 : " << str1.GetString() << " len : " << str1.GetStringLen() << endl;
cout << "str2 : " << str2.GetString() << " len : " << str2.GetStringLen() << endl;

现在已经没什么问题了,我们继续往下写功能。
void CMyString::Append(const char* szStr)
{
//判断缓冲区是否足够放下拼接后的字符串
//申请新的缓冲区,拼接字符串
int nCatStrlen = strlen(szStr) + m_nStrLen + 1;
if (nCatStrlen > m_nBuffLen)
{
//缓冲区过小不足以存放新的字符串
char* pNewBuff = new char[nCatStrlen];
strcpy(pNewBuff, m_pStrBuff);
strcat(pNewBuff, szStr);
//释放原来的缓冲区
Clear();
//成员赋新值
m_pStrBuff = pNewBuff;
m_nBuffLen = nCatStrlen;
m_nStrLen = nCatStrlen - 1;
pNewBuff = nullptr;
}
else {
//缓冲区足够存放新的字符串
strcat(m_pStrBuff, szStr);
m_nStrLen = nCatStrlen - 1;
}
}
void CMyString::Append(const CMyString& str)
{
Append(str.m_pStrBuff);
}
我们来测试一下
#include <iostream>
#include "MyString.h"
using namespace std;
int main() {
CMyString str("hello");
CMyString str1("world");
str.Append(" ");
str.Append(str1);
cout << str.GetString() << endl;
return 0;
}
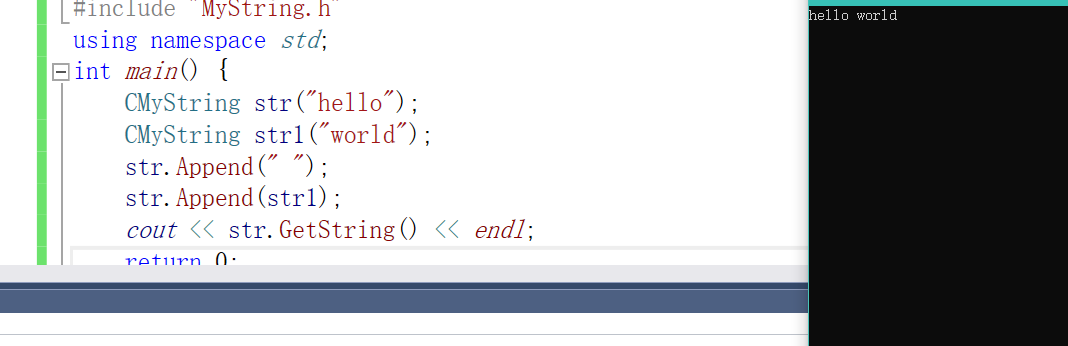
我这里实现了append的操作之后其他的由大家自己来写
CMyString& CMyString::Append(const char* szStr)
{
//判断缓冲区是否足够放下拼接后的字符串
//申请新的缓冲区,拼接字符串
int nCatStrlen = strlen(szStr) + m_nStrLen + 1;
if (nCatStrlen > m_nBuffLen)
{
//缓冲区过小不足以存放新的字符串
char* pNewBuff = new char[nCatStrlen];
strcpy(pNewBuff, m_pStrBuff);
strcat(pNewBuff, szStr);
//释放原来的缓冲区
Clear();
//成员赋新值
m_pStrBuff = pNewBuff;
m_nBuffLen = nCatStrlen;
m_nStrLen = nCatStrlen - 1;
pNewBuff = nullptr;
}
else {
//缓冲区足够存放新的字符串
strcat(m_pStrBuff, szStr);
m_nStrLen = nCatStrlen - 1;
}
return *this;
}
CMyString& CMyString::Append(const CMyString& str)
{
return Append(str.m_pStrBuff);
}
常成员函数
我们来看一份代码
#include <iostream>
using namespace std;
class CFoo
{
public:
int GetVal() {
return m_nVal;
}
void SetVal(int nVal) {
m_nVal = nVal;
}
private:
int m_nVal;
};
void Test(const CFoo& fObj)
{
cout << fObj.GetVal() << endl;
}
int main()
{
CFoo fObj;
fObj.SetVal(10);
Test(fObj);
return 0;
}
这里编译报错了,我们看看是为什么

cout << fObj.GetVal() << endl;这里报错了,但是为什么会报错呢?我们调用GetVal并不会对CFoo的对象进行修改,那为什么会让我们编译失败呢?
如果我们把对象定义为:const CFoo& fObj,那么我们this指针应该是const CFoo* const this,所以才会报错,但是从逻辑来讲,我们调用GetVal应该是合理的。
为了修复这个bug,c++提供了一种叫常成员的方法
int GetVal() const {
return m_nVal;
}
然后代码就编译通过了。
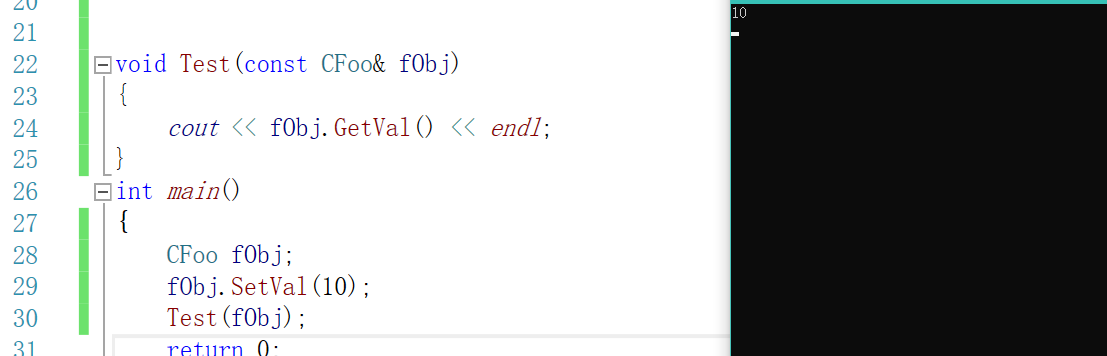
那我们加了这个const之后,编译器做了什么才让我们编译通过了呢?
我们刚才对象是:const CFoo* const this,但是成员函数是:CFoo* const this,肯定没办法传过去,我们在成员函数后面加了const,让成员函数也成了const CFoo* const this,所以可以成功调用了。
我们让vs报错,看一下我们的说法是否是正确的

可以看到我们的说法是没有问题的。那么我们就不可以通过GetVal函数来修改成员值了。
总结一下常成员:
- 将this指针的类型改为:
const type* const this - 常成员函数内部不能修改其成员,不能调用非常成员函数【语法上的限制】,语法上的限制是可以突破的:
*(int*)&this->m_nVal = 18;
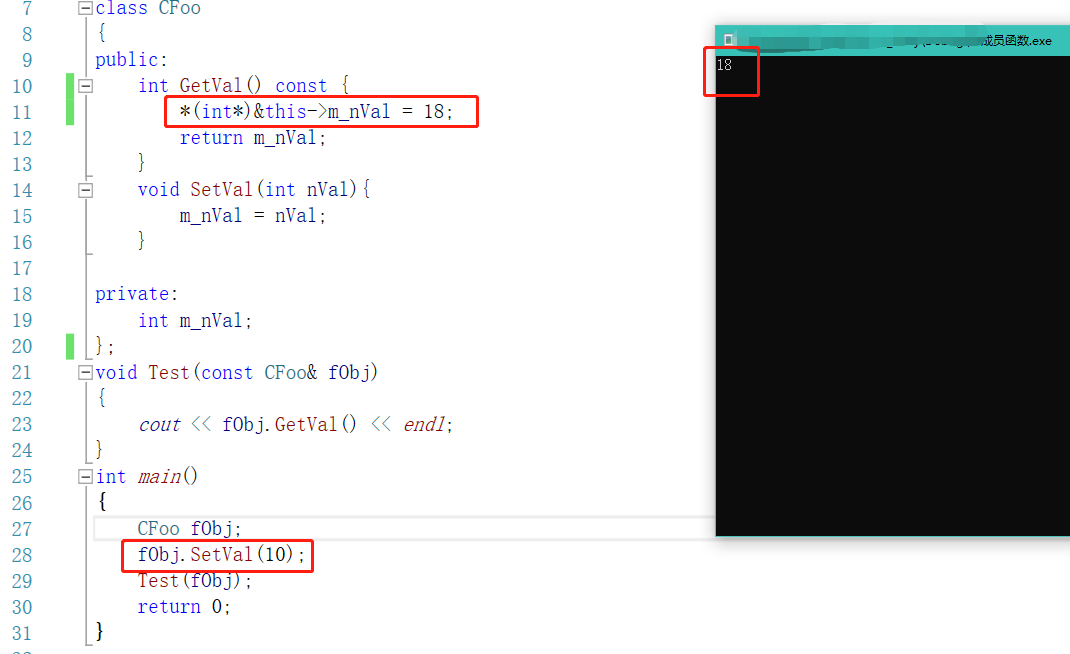
或者可以:
CFoo* p = (CFoo*)this;
p->m_nVal = 12;
- 一般都用在get类的成员函数中。
也是可以修改的
初始化列表
在早期c++版本中不允许在类中这样定义常成员:const int m_nVal = 8;,所以c++提供了一个初始化列表的语法
#include <iostream>
using namespace std;
class CFoo
{
public:
CFoo(int nVal) :m_nVal(nVal)
{
}
const int m_nVal;
};
int main() {
CFoo foo(10);
cout << foo.m_nVal << endl;
return 0;
}
非const成员也是可以用这种方法来初始化的。它还可以给类对象成员赋值
#include <iostream>
using namespace std;
class CFoo1 {
public:
CFoo1(int nVal) :m_nVal(nVal)
{
}
const int m_nVal;
};
class CFoo
{
public:
CFoo(int nVal,int nValF1) :m_nVal(nVal), m_foo(nValF1)
{
}
const int m_nVal;
CFoo1 m_foo;
};
int main() {
CFoo foo(10,20);
cout << foo.m_nVal << endl;
cout << foo.m_foo.m_nVal << endl;
return 0;
}

所以是初始化列表先修改还是构造函数体内先修改呢?
#include <iostream>
using namespace std;
class CFoo1 {
public:
CFoo1(int nVal) :m_nVal(nVal)
{
}
const int m_nVal;
};
class CFoo
{
public:
CFoo(int nVal,int nValF1,int nVal2) :m_nVal(nVal), m_foo(nValF1), m_nVal2(nVal2)
{
m_nVal2 = 20;
}
const int m_nVal;
int m_nVal2;
CFoo1 m_foo;
};
int main() {
CFoo foo(10,20,30);
cout << foo.m_nVal << endl;
cout << foo.m_foo.m_nVal << endl;
cout << foo.m_nVal2 << endl;
return 0;
}

所以可以看出来是初始化列表先初始化,然后才会进入构造函数体内
刚才我们还在里面写了一个类对象的初始化列表,那么是CFoo的构造体先进还是CFoo1的构造体先进呢?
我们在两个构造函数中加入打印函数。

可以看到是先进入的CFoo1.
因为CFoo1不构造的话,CFoo不能进行构造,因为我们CFoo构造的函数体内可能会用到CFoo1的成员,所以要先构造成员最后构造自己。
那么析构也是这样吗?
#include <iostream>
using namespace std;
class CFoo1 {
public:
CFoo1(int nVal) :m_nVal(nVal)
{
cout << "Come on CFoo1 " << endl;
}
~CFoo1() {
cout << "Come on ~CFoo1 " << endl;
}
const int m_nVal;
};
class CFoo
{
public:
CFoo(int nVal,int nValF1,int nVal2) :m_nVal(nVal), m_foo(nValF1), m_nVal2(nVal2)
{
cout << "Come on CFoo " << endl;
m_nVal2 = 20;
}
~CFoo() {
cout << "Come on ~CFoo " << endl;
}
const int m_nVal;
int m_nVal2;
CFoo1 m_foo;
};
int main() {
CFoo foo(10,20,30);
cout << foo.m_nVal << endl;
cout << foo.m_foo.m_nVal << endl;
cout << foo.m_nVal2 << endl;
return 0;
}

如果在CFoo的析构里面去操作成员,这样是可以做的,如果成员先析构了,就不能进行操作了。所以要先析构CFoo再去析构CFoo1
有多个对象成员,按照定义的顺序影响,先定义的先构造。【Visutal Studio是这样,换一个编译器可能就不是这样了】
静态成员
设计初衷:它是为了改变C语言中全局变量的滥用。
我们来定义一个静态成员:
class CFoo
{
public:
static int m_nVal;
};
我们来设置一下这个成员的值:
int main()
{
CFoo foo;
foo.m_nVal = 9;
return 0;
}
然后编译就直接报错了

根据错误:无法解析的外部符号 "public: static int CFoo::m_nVal" (?m_nVal@CFoo@@2HA),这里如果是一个函数,那就是因为声明了,但是没有定义。但是这个变量为什么这样报错呢?
根据报错来看,编译器在找这个东西的实现。也就是说静态成员的声明和实现是分开的。
// 静态成员.cpp : 定义控制台应用程序的入口点。
//
#include "stdafx.h"
#include <iostream>
using namespace std;
class CFoo
{
public:
static int m_nVal;
};
int CFoo::m_nVal = 0;
int main()
{
CFoo foo;
foo.m_nVal = 9;
return 0;
}
静态数据成员在实现的时候不需要加static。
我们来sizeof一下这个对象,看一下这个对象的大小

这里怎么会只有一个字节呢?
我们去看一下这个类对象的内存会发现,这个静态成员压根没在类对象的内存中,那么他会在哪呢?
我们来取消掉程序的随机基址
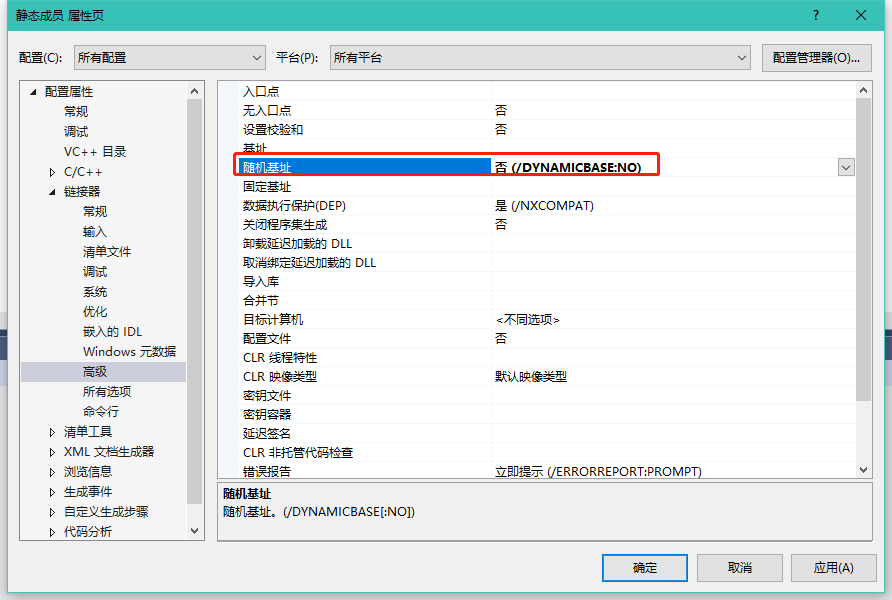
然后写一个全局变量来观察他们两个的地址。

如果是在栈上应该是19开头的,都是40开头的应该在全局数据区。
所以静态数据成员有独立的内存放在全局数据区内。
那这个静态数据成员的生命周期应该是多久呢?
我们再加一个类,然后写个构造和析构来验证他什么时候会调用析构
// 静态成员.cpp : 定义控制台应用程序的入口点。
//
#include "stdafx.h"
#include <iostream>
using namespace std;
class CTest
{
public:
CTest() {
cout << "CTest" << endl;
}
~CTest() {
cout << "~CTest" << endl;
}
};
class CFoo
{
public:
static int m_nVal;
static CTest ct;
};
int g_nVal = 1;
int CFoo::m_nVal = 0;
CTest CFoo::ct;
int main()
{
CFoo foo;
foo.m_nVal = 9;
cout << sizeof(foo) << endl;
return 0;
}

我们从main函数开始调试,发现他是到return 0;之后才会调用析构,也就是说他的生命周期和这个对象的声明周期没有关系,他和全局变量的生命周期是一样的。
那么静态成员是属于类对象还是属于这个类?
我们再去实例化一个对象,我们去看看两个对象的静态数据成员地址是不是一样的。

所以静态成员是属于类的,所有对象共享。
所以我们一般都是通过类名来直接访问的:CFoo::m_nVal = 10;
我们继续来讨论一个问题,我们一般情况下数据成员都是私有的,但是外面还是需要访问的,我们就需要使用Get和Set方法。
#include <iostream>
using namespace std;
class CFoo
{
private:
static int m_nVal;
public:
int GetVal() { return m_nVal; }
void SetVal(int val) { m_nVal = val; }
};
int CFoo::m_nVal = 12;
int main()
{
CFoo foo;
cout << foo.GetVal() << endl;
return 0;
}
我们这样肯定还是可以访问的,但是静态成员是共享的,但是我们这样是通过这个对象去访问的,完全不是一个静态成员的样子。我们在这必须有对象才能访问。
那么我们可以这样去调用((CFoo*)0)->GetVal();
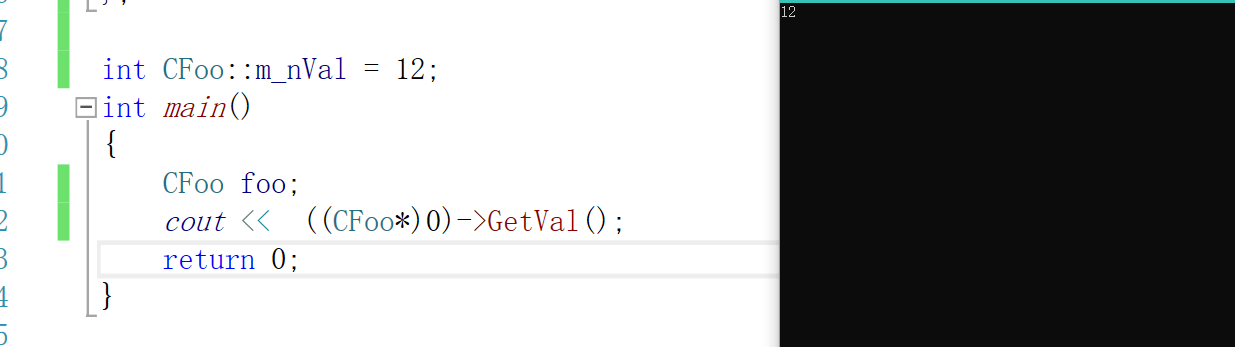
但是这样看起来会不会很奇怪呢?
C++为了让我们看起来不是很奇怪,它还可以写静态成员函数
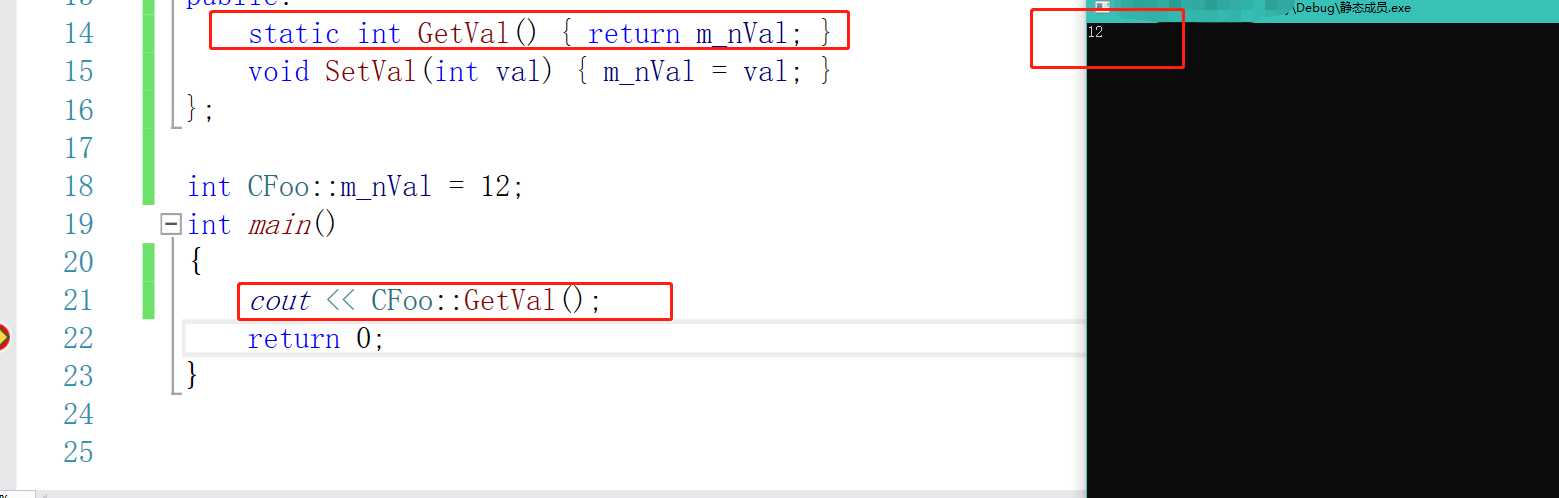
我们的静态成员函数也是属于类的,可以通过类名直接调用。而且静态成员函数是没有this指针的。因为是通过类来访问的,不是通过对象的。哪怕你是通过对象访问过来的也没有this指针
友元
#include <iostream>
using namespace std;
class CFoo
{
private:
int m_nVal;
public:
int GetVal() const { return m_nVal; }
void SetVal(int val) { m_nVal = val; }
//友元函数
friend int main();
};
int main()
{
return 0;
}
这里我们在CFoo类中声明了一个友元,也就是main函数,他可以对这个类做一些过分的事情。
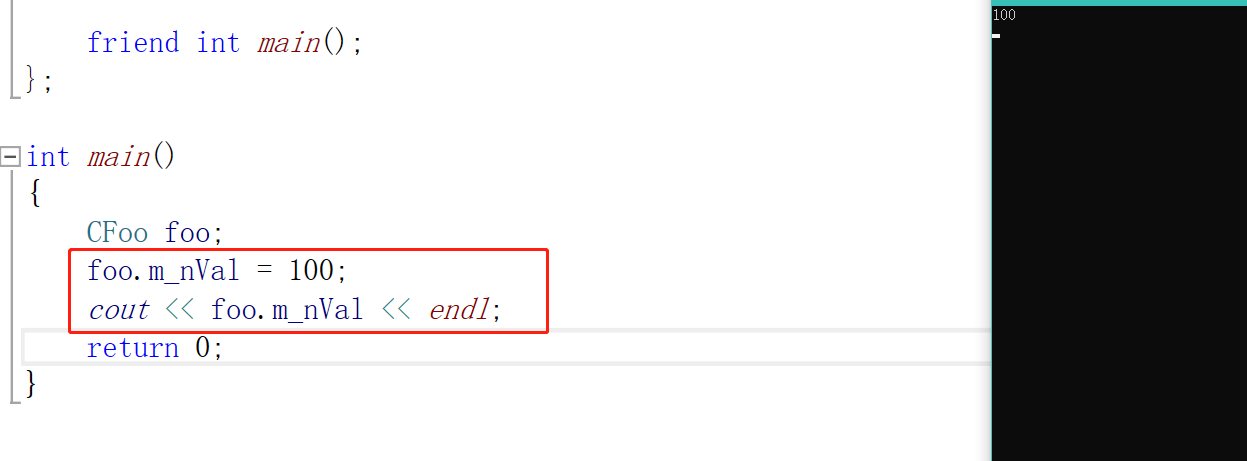
他可以直接在类外访问我们类的私有成员,使用友元就会破坏封装性。
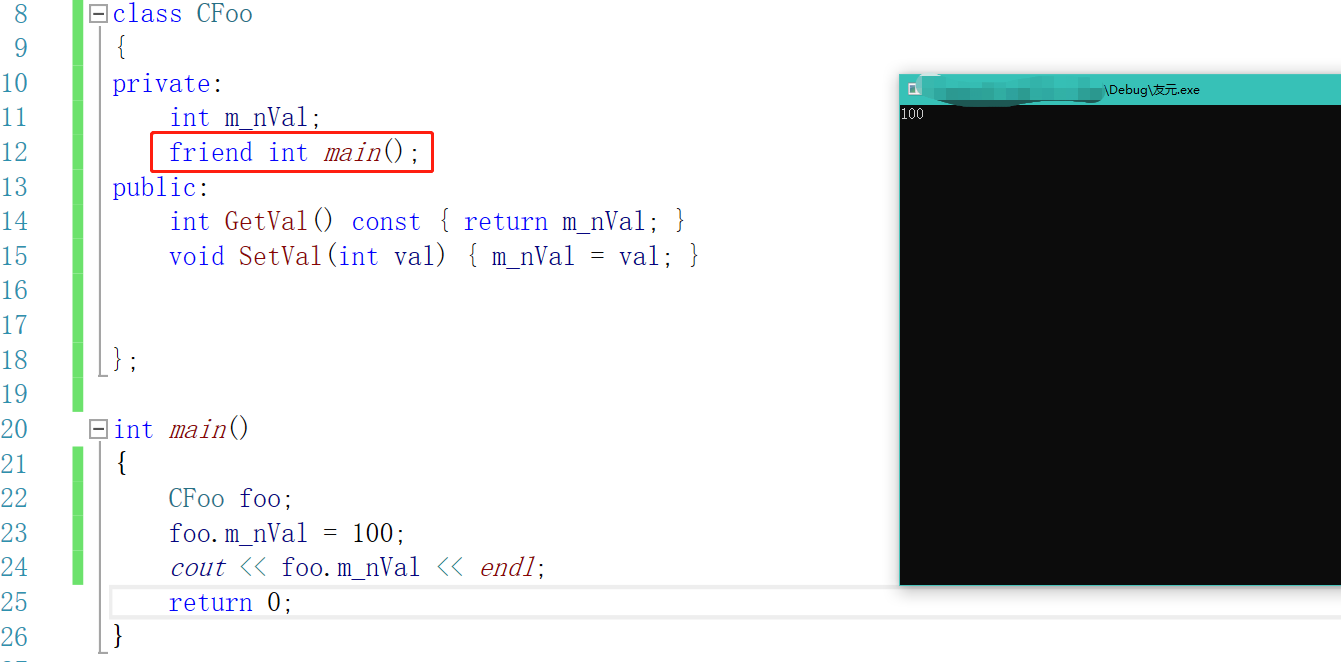
我们把它修改为私有属性,可以看到他是不会受到访问控制标号的影响的。
我们现在的做法是在类里面声明,在类外面定义。同样他也可以在类里面定义:
class CFoo
{
private:
int m_nVal;
friend int main();
friend void Test() {
CFoo foo;
foo.m_nVal = 18;
}
public:
int GetVal() const { return m_nVal; }
void SetVal(int val) { m_nVal = val; }
};
那么我们怎么调用这个Test函数呢?
这个友元函数属于全局函数,需要我们在外部进行声明之后才可以使用。
#include <iostream>
using namespace std;
void Test();
class CFoo
{
private:
int m_nVal;
friend int main();
friend void Test() {
CFoo foo;
foo.m_nVal = 18;
cout << foo.m_nVal << endl;
}
public:
int GetVal() const { return m_nVal; }
void SetVal(int val) { m_nVal = val; }
};
int main()
{
CFoo foo;
foo.m_nVal = 100;
cout << foo.m_nVal << endl;
Test();
return 0;
}
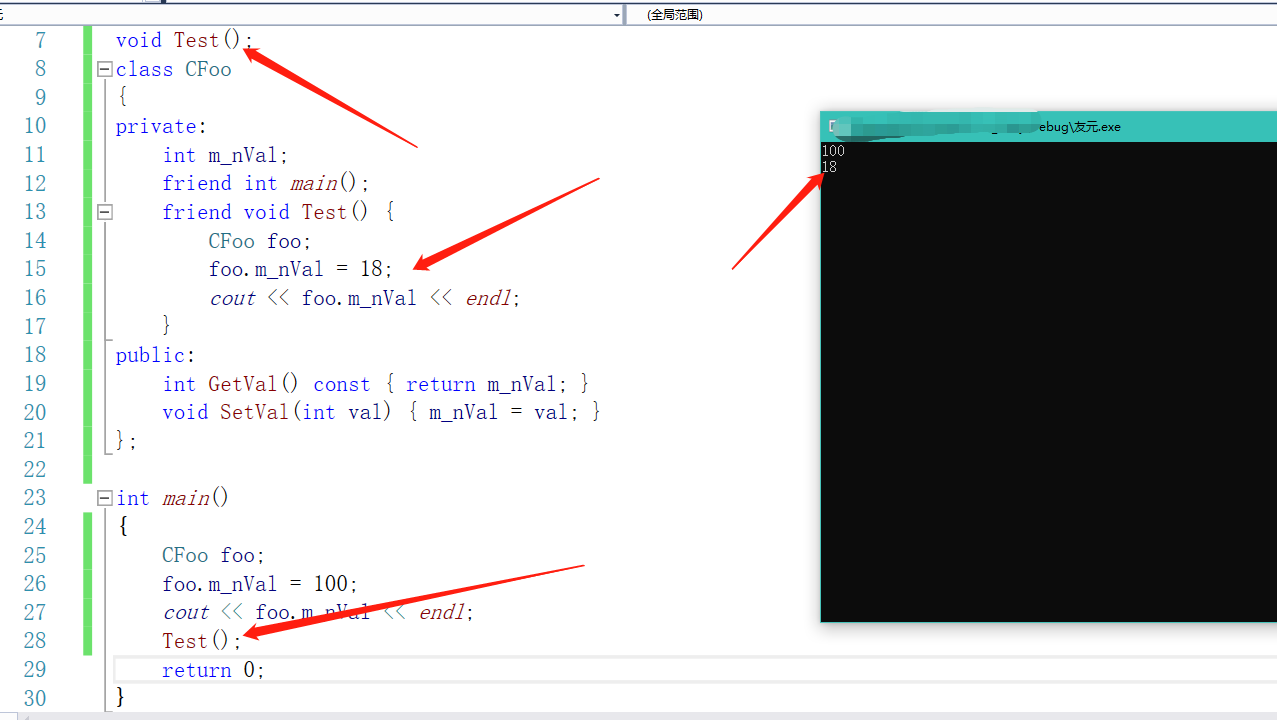
所以我们的友元函数可以定义在类外面,也可以定义在类里面(仍然是全局函数,但是需要在类外面声明)
他不光可以声明某个函数是友元函数,它还可以告诉编译器某个类的成员函数是我的朋友
#include <iostream>
using namespace std;
void Test();
class CFoo
{
private:
int m_nVal;
friend int main();
friend void Test() {
CFoo foo;
foo.m_nVal = 18;
cout << foo.m_nVal << endl;
}
//友元成员函数
friend void CTest::Test1();
public:
int GetVal() const { return m_nVal; }
void SetVal(int val) { m_nVal = val; }
};
class CTest
{
public:
void Test1() {
CFoo foo;
foo.m_nVal = 9;
}
};
int main()
{
CFoo foo;
foo.m_nVal = 100;
cout << foo.m_nVal << endl;
Test();
return 0;
}
这样看似没有问题,但是编译会报错

是CFoo里面不认识CTest,如果把CTest放在上面的话,那么又不认识CFoo了那应该怎么解决这个问题呢?我们可以做一个前项声明:class CFoo;
但是出现了新的错误。
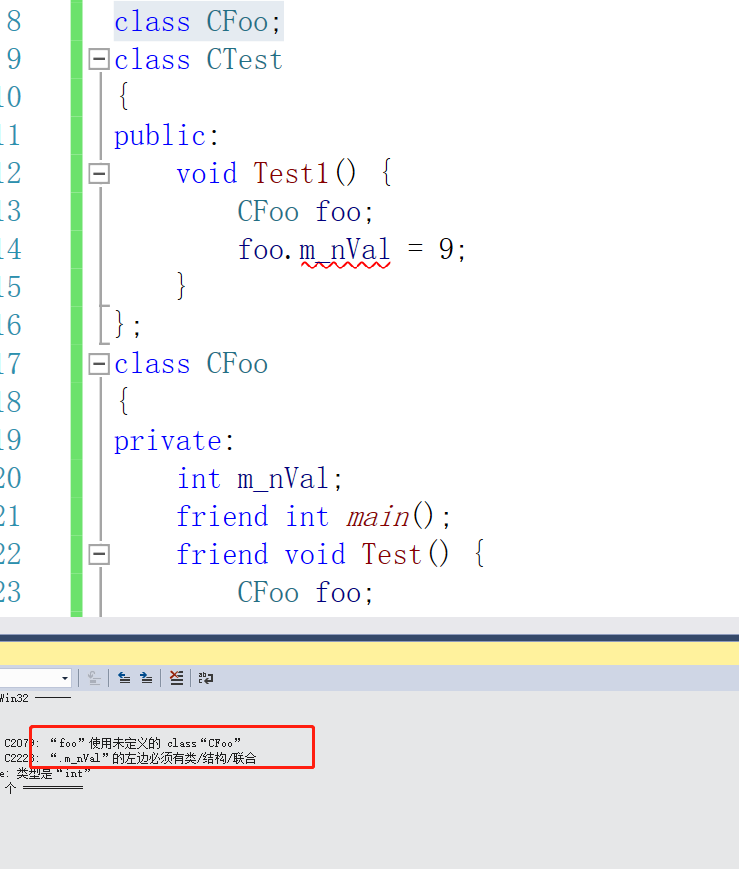
“foo”使用未定义的 class“CFoo”他这里的这个错误意味着可以找到CFoo了,但是他报了一个未定义。也就是它只是找到了名字,但是没有找到实现,所以这个前项声明也是没用的。
那我们把CTest类中的Test1成员函数的声明和实现分开呢?
#include <iostream>
using namespace std;
void Test();
class CTest
{
public:
void Test1();
};
class CFoo
{
private:
int m_nVal;
friend int main();
friend void Test() {
CFoo foo;
foo.m_nVal = 18;
cout << foo.m_nVal << endl;
}
//友元成员函数
friend void CTest::Test1();
public:
int GetVal() const { return m_nVal; }
void SetVal(int val) { m_nVal = val; }
};
void CTest::Test1(){
CFoo foo;
foo.m_nVal = 9;
cout << foo.m_nVal << endl;
}

我们来打印看一下,完全没有问题。
我们还可以来声明一个友元类。
friend class CTest;
这样我们的所有成员函数都可以访问到CFoo里面了
class CTest
{
public:
void Test1();
void Test2();
void Test3();
void Test4();
};
void CTest::Test1(){
CFoo foo;
foo.m_nVal = 9;
cout << foo.m_nVal << endl;
}
void CTest::Test2() {
CFoo foo;
foo.m_nVal = 9;
cout << foo.m_nVal << endl;
}
void CTest::Test3() {
CFoo foo;
foo.m_nVal = 9;
cout << foo.m_nVal << endl;
}
void CTest::Test4() {
CFoo foo;
foo.m_nVal = 9;
cout << foo.m_nVal << endl;
}
引用计数
引用计数的使用和深拷贝与浅拷贝离不开,所以我们来复习一下这个知识点。
我们先把之前讲过的一个CBuff复制过来
class CBuff {
public:
CBuff(const char* pData = nullptr, int nCount = 0) {
if (pData == nullptr)
{
m_pBuffer = nullptr;
m_nCount = 0;
}
else
{
m_nCount = nCount;
m_pBuffer = (char*)malloc(m_nCount);
memcpy(m_pBuffer, pData, m_nCount);
}
}
~CBuff() {
if (m_pBuffer != nullptr)
{
free(m_pBuffer);
m_pBuffer = nullptr;
m_nCount = 0;
}
}
void SetData(const char* pData, int nCount)
{
if (m_pBuffer != nullptr)
{
free(m_pBuffer);
m_pBuffer = nullptr;
m_nCount = 0;
}
m_nCount = nCount;
m_pBuffer = (char*)malloc(m_nCount);
memcpy(m_pBuffer, pData, m_nCount);
}
const char* GetData() {
return m_pBuffer;
}
CBuff(const CBuff& obj) {
m_pBuffer = obj.m_pBuffer;
m_nCount = obj.m_nCount;
}
private:
char* m_pBuffer;
int m_nCount;
};
我们去看一下新加入一个拷贝构造,我们在里面的实现是内存拷贝,相当于是默认的拷贝构造,是一种浅拷贝。他碰到浅拷贝就会出问题。我们来看一下危害到底在哪。
int main()
{
CBuff buf("hello",6);
CBuff buf0(buf);
return 0;
}
我们断在return 0;的位置,F11跟进去看析构。
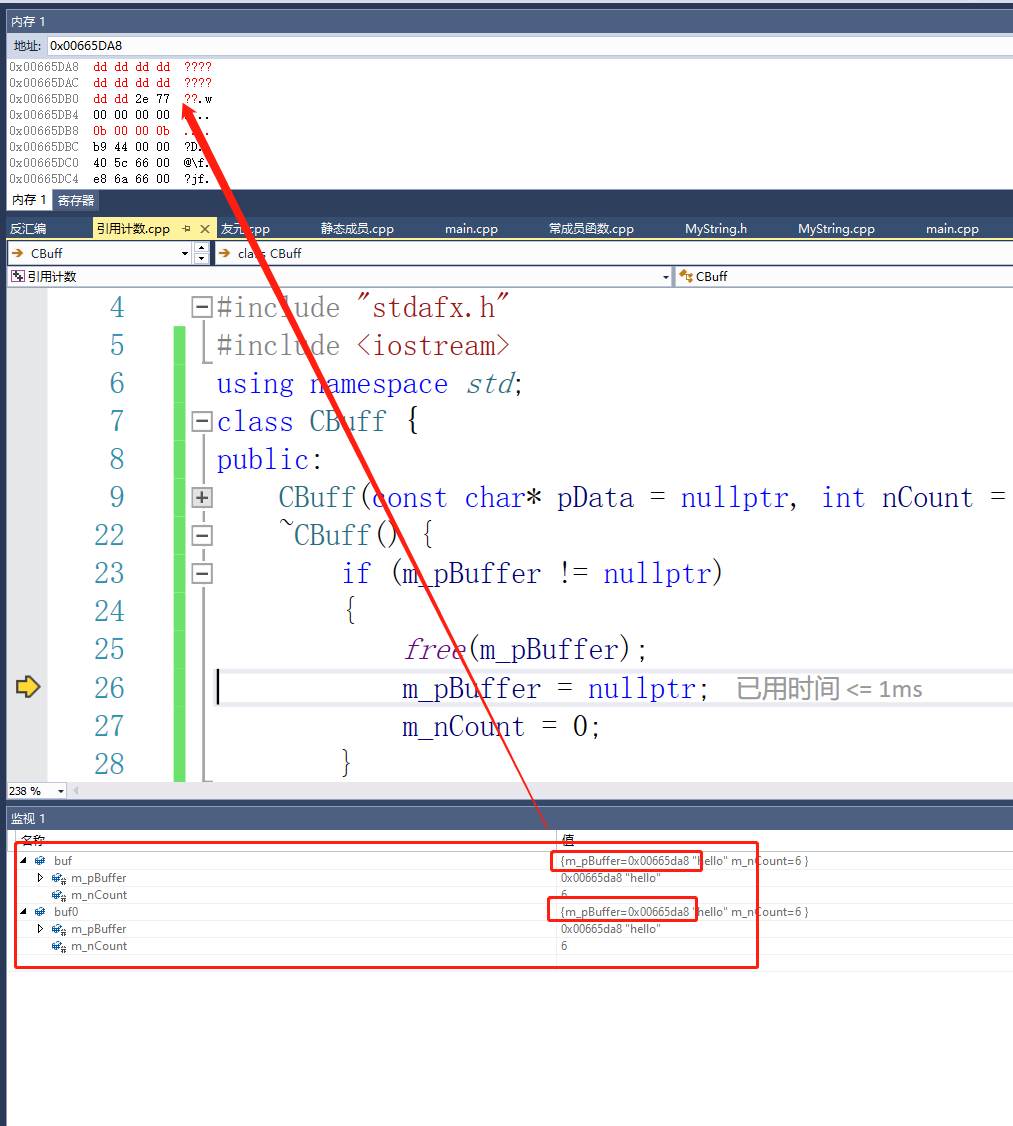
我们可以看到第一次是析构buf0,这时候已经把内存给释放掉了。
然后第二次去释放buf的时候
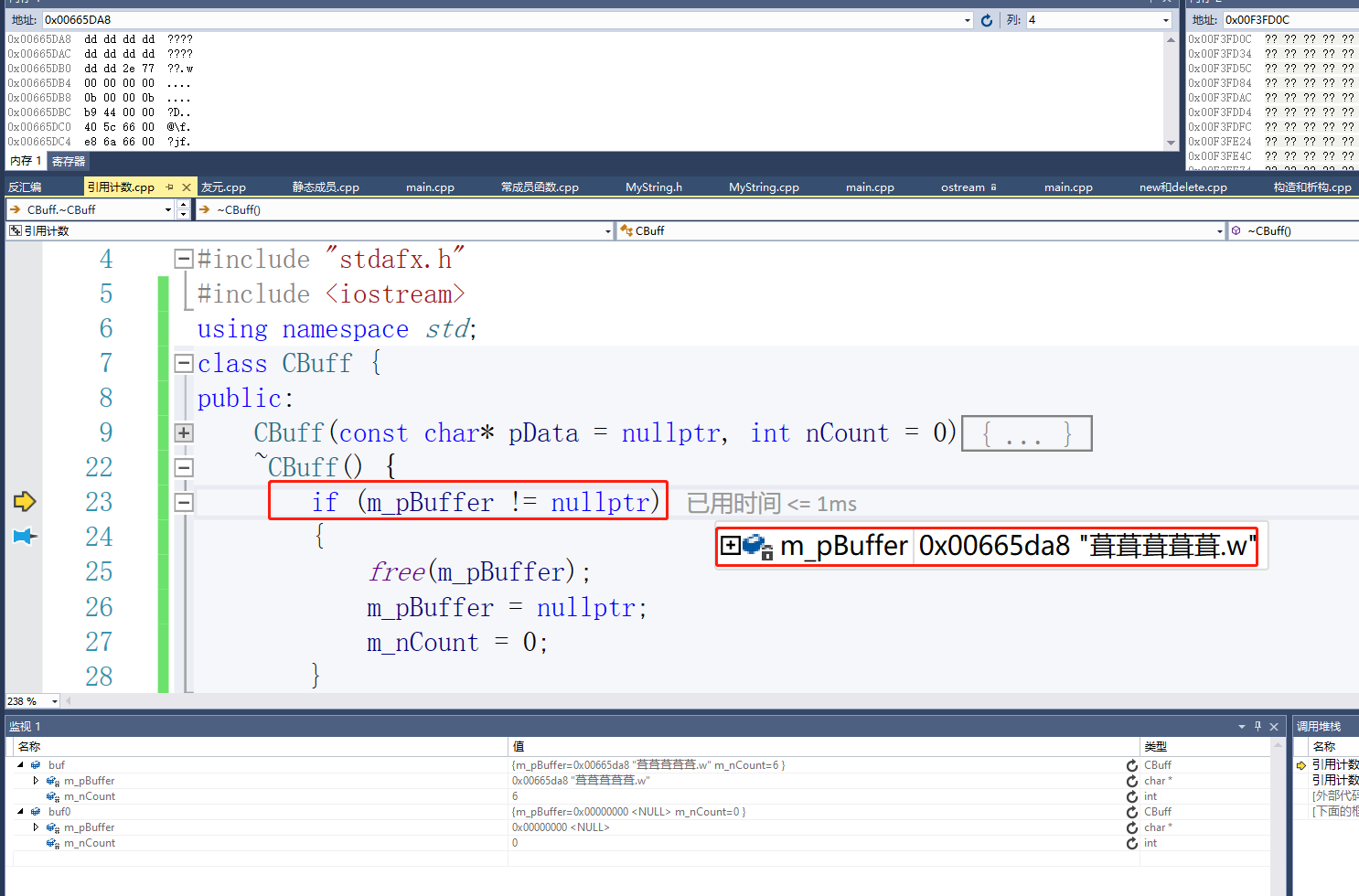
堆一块内存的两次释放就会触发崩溃。
所以浅拷贝会造成多次释放。
那么我们来做一个深拷贝
CBuff(const CBuff& obj) {
m_pBuffer = nullptr;
m_nCount = 0;
SetData(obj.m_pBuffer, obj.m_nCount);
}
我们再来调试一下。
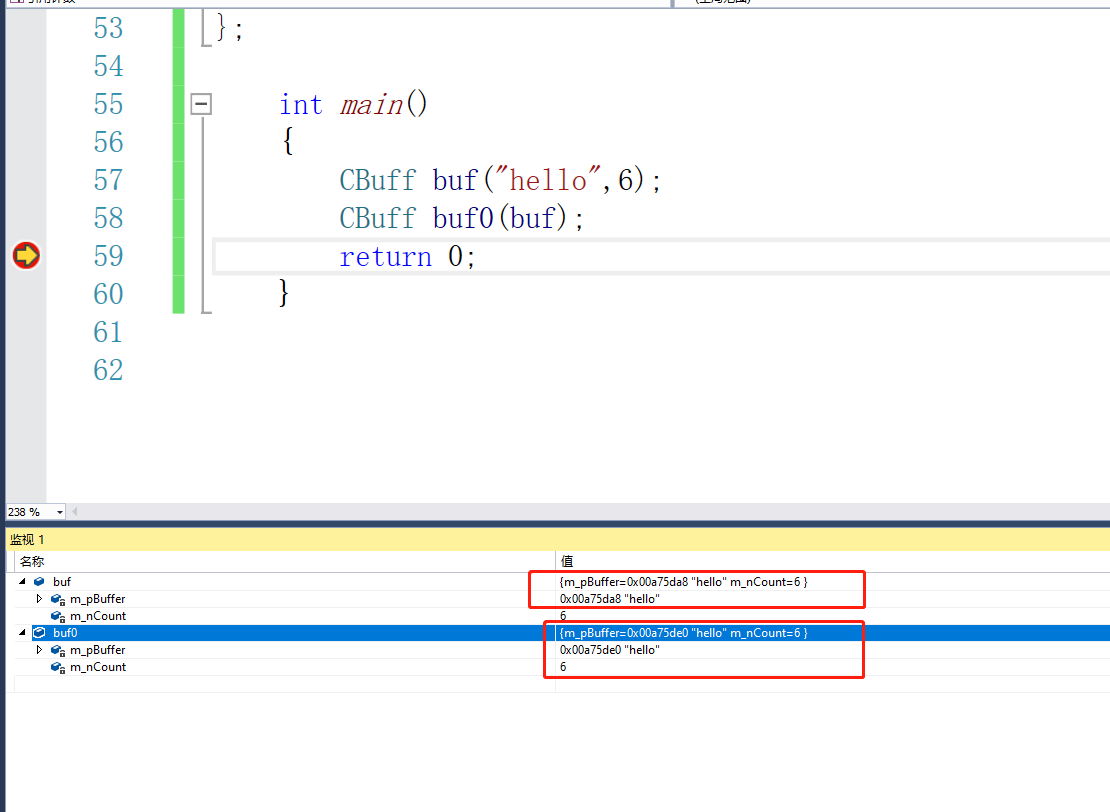
我们看到已经不再是同一块内存了。

所以走两次析构也是不会有问题的。
如果有这样一种情况呢?
我们这个程序新建了100个buf,里面存储的全都是:"Hello",那么我们这里是深拷贝,相当于我们要申请一百个堆存储了"Hello",大家有没有感觉这种存放方式有问题呢?
这样就造成了大量的内存浪费。所以对比起来就是:
浅拷贝 -- 重复释放,省内存,效率高。
深拷贝 -- 不会重复释放,内存浪费,效率低。
我们再来看一个浅拷贝的坑:
我们写一个修改的函数。
void SetChar(int nOff,char ch) {
if (nOff > m_nCount)
{
return;
}
m_pBuffer[nOff] = ch;
}
我们来试试。我们把buf0的第三个改成大写A。buf0.SetChar(3, 'A');
当我们是浅拷贝的时候:
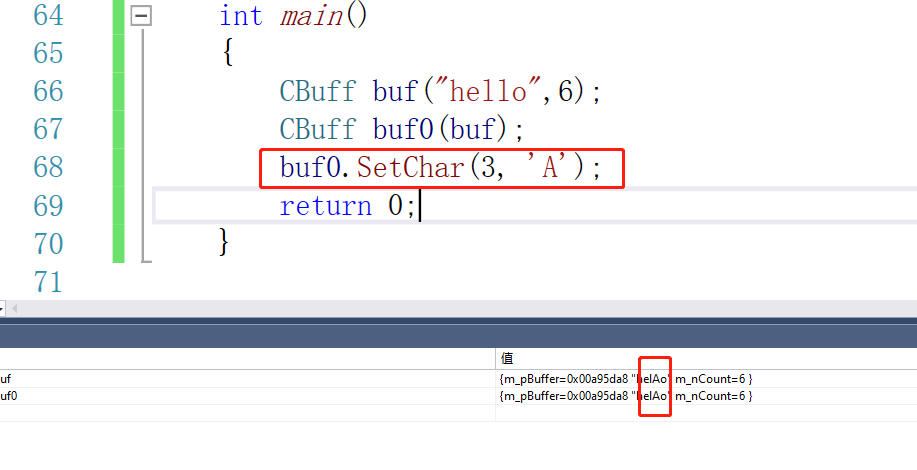
都会被修改。仅仅使用标记的方式无法解决浅拷贝的问题。
我们可以在一开始拷贝的时候,我们就用浅拷贝,接着如果某一个对象要对这块内存做修改,我们给这个对象分配一块新的内存,把原来的内容搬过去,让他去修改新的内存。这个样子的话,就只会影响自己的内容而不会影响别的对象的内容。
这种思路叫做写时拷贝,也就是当某个对象做修改的时候,单独给它分配内存,修改在新的内存中修改。
void SetChar(int nOff,char ch) {
//写时拷贝
char* pNewBuffer = new char[m_nCount];
memcpy(pNewBuffer,m_pBuffer,m_nCount);
m_pBuffer = pNewBuffer;
m_pBuffer[nOff] = ch;
}
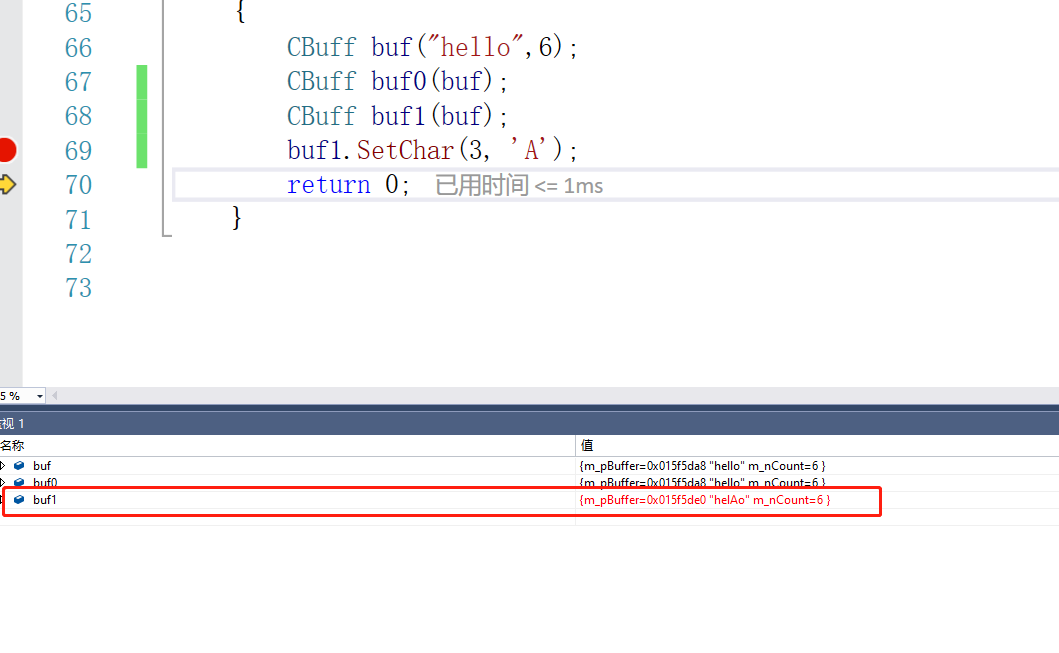
其实这里buf和buf0还是存在重复释放的问题,浅拷贝的问题他都有。那么如何来解决这个问题呢?
这里我们就需要引入引用计数的概念,需要有一个东西告诉对象能不能来释放这个堆内存。
就像教室下课关灯一样,肯定是最后一个走的人关掉,每进来一个学生计数器加一,走一个减一,最后一个关灯。
我们需要把计数器放到类里面做成员。问题是当某个对象销毁的时候,需要通知其他对象计数器减一,但是做不到。
如果把计数器放到静态成员里面。看似很完美,但是我们想一下,我们依次创建三个对象,现在计数器是3,如果buffer1对堆内存进行了修改就创建了一块新的内存。那么计数器的值就修改了。但是buffer1是不是也有一块内存了,如果再来一个对象指向了buffer1.这个时候buffer1是不是也需要一个引用计数呢?如果有十个这样的情况,我们就有十个静态成员呢?我们就无法确定有多少静态成员了。所以写时拷贝会申请新的内存,新的内存也需要引用计数,因为无法估算有多少个新内存,所以无法确定静态成员的数量。
那么我们可以把计数器放到堆里,每块堆分配一个计数器。这个思路是比较合理的。我们用代码实现一下。
// 引用计数.cpp : 定义控制台应用程序的入口点。
//
#include "stdafx.h"
#include <iostream>
using namespace std;
class CBuff {
public:
CBuff(const char* pData = nullptr, int nCount = 0) {
if (pData == nullptr)
{
m_pBuffer = nullptr;
m_nCount = 0;
m_pRefCount = 0;
}
else
{
AllocNewBuff(pData, nCount);
}
}
~CBuff() {
ReleaseBuff();
}
void SetChar(int nOff,char ch) {
//写时拷贝
char* pNewBuffer = new char[m_nCount];
int* pNewRefCount = new int;
memcpy(pNewBuffer,m_pBuffer,m_nCount);
//原来的引用计数减一
(*m_pRefCount)--;
//新的引用计数增加
m_pRefCount = pNewRefCount;
(*m_pRefCount) = 1;
m_pBuffer = pNewBuffer;
m_pBuffer[nOff] = ch;
}
void SetData(const char* pData, int nCount)
{
//释放之前的内存
ReleaseBuff();
//申请新内存
AllocNewBuff(pData,nCount);
}
const char* GetData() {
return m_pBuffer;
}
CBuff(const CBuff& obj) {
m_pBuffer = obj.m_pBuffer;
m_pRefCount = obj.m_pRefCount;
m_nCount = obj.m_nCount;
(*m_pRefCount)++;
}
private:
void ReleaseBuff() {
--(*m_pRefCount);//引用计数器的值减少
if (m_pBuffer != nullptr && (*m_pRefCount) == 0)
{
delete[] m_pBuffer;
delete[] m_pRefCount;
m_pRefCount = nullptr;
m_pBuffer = nullptr;
m_nCount = 0;
}
}
void AllocNewBuff(const char* pData,int nCount) {
m_nCount = nCount;
m_pBuffer = new char[m_nCount];
m_pRefCount = new int;
memcpy(m_pBuffer, pData, m_nCount);
*m_pRefCount = 1;
}
private:
char* m_pBuffer;
int m_nCount;
int* m_pRefCount;//每块堆分配一个引用计数
};
int main()
{
CBuff buf("hello", 6);
CBuff buf0(buf);
CBuff buf1(buf0);
buf1.SetChar(3, 'A');
CBuff buf2(buf1);
return 0;
}
这样看似没有问题了,但是我们来这样测试 其实是有bug的。
int main()
{
CBuff buf("Hello",6);
buf.SetChar(1, 'p');
return 0;
}
我们去SetChar下断点看一下可以发现

新拷贝过去的释放了,但是老的内存没有释放。
我们修改一下SetChar函数
void SetChar(int nOff,char ch) {
if (nOff > m_nCount)
{
return;
}
//创建个临时缓冲区
CBuff buf(m_pBuffer,m_nCount);
ReleaseBuff();
AllocNewBuff(buf.m_pBuffer, buf.m_nCount);
m_pBuffer[nOff] = ch;
}
继承
继承是为了解决代码重用的问题。
如果是C语言,看下面一个例子:
struct tagPoint
{
int m_nX;
int m_nY;
};
int main() {
tagPoint pt1 = { 1,2 };
tagPoint pt2 = { 2,2 };
tagPoint pt3 = { 3 ,2 };
tagPoint pt4 = { 4,2 };
tagPoint pt5 = { 5,2 };
printf("point x : %d y : %d\r\n", pt1.m_nX, pt1.m_nY);
printf("point x : %d y : %d\r\n", pt2.m_nX, pt2.m_nY);
printf("point x : %d y : %d\r\n", pt3.m_nX, pt3.m_nY);
printf("point x : %d y : %d\r\n", pt4.m_nX, pt4.m_nY);
printf("point x : %d y : %d\r\n", pt5.m_nX, pt5.m_nY);
return 0;
}
这里突出了一个点,就是代码非常不通用。如果我们不想用printf了,要换成cout,那我们就都需要改。那我们怎么把它通用呢?在C语言中我们的解决方案是写成函数:
void ShowPoint(tagPoint* pPt) {
printf("point x : %d y : %d\r\n", pPt->m_nX, pPt->m_nY);
}
int main() {
tagPoint pt1 = { 1,2 };
tagPoint pt2 = { 2,2 };
tagPoint pt3 = { 3 ,2 };
tagPoint pt4 = { 4,2 };
tagPoint pt5 = { 5,2 };
ShowPoint(&pt1);
ShowPoint(&pt2);
ShowPoint(&pt3);
ShowPoint(&pt4);
ShowPoint(&pt5);
return 0;
}
这是在C语言中解决代码重用的办法。那么如果我们现在改需求,改成三维坐标,那么结构体需要加一个成员。我们就可以用初始化和反初始化。如果又要改回去,就有要改很多东西。
那么我们就可以定义两个结构,相关操作再来一遍,这样我们很多代码还是很不通用。我们其实可以在3D操作里面加入2D结构体
#include <iostream>
using namespace std;
struct tagPoint
{
int m_nX;
int m_nY;
};
struct tag3DPoint
{
tagPoint m_pt2D;
int m_nZ;
};
void ShowPoint(tagPoint* pPt) {
printf("point x : %d y : %d\r\n", pPt->m_nX, pPt->m_nY);
}
void Show3DPoint(tag3DPoint* pPt) {
ShowPoint(&pPt->m_pt2D);
printf("z : %d\r\n",pPt->m_nZ);
}
bool g_bFlag2d = true;
int main() {
tag3DPoint pt1 = { 1,2 };
tag3DPoint pt2 = { 2,2 };
tag3DPoint pt3 = { 3 ,2 };
tag3DPoint pt4 = { 4,2 };
tag3DPoint pt5 = { 5,2 };
if (g_bFlag2d)
{
ShowPoint((tagPoint*)&pt1);
ShowPoint((tagPoint*)&pt2);
ShowPoint((tagPoint*)&pt3);
ShowPoint((tagPoint*)&pt4);
ShowPoint((tagPoint*)&pt5);
}
else {
Show3DPoint(&pt1);
Show3DPoint(&pt2);
Show3DPoint(&pt3);
Show3DPoint(&pt4);
Show3DPoint(&pt5);
}
return 0;
}
我们封装这一套代码可以写成这样,高端一点甚至可以玩条件编译。上面是C语言实现代码重用的简单展示,我们现在来设计一个游戏。我们来设计结构
struct tagWarrior //战士
{
int m_nAttack; //攻击力
int m_nBlood; //血量
int m_nArmor; //护甲
int m_nMagicResistance; //魔抗
int m_nAnger; //怒气
};
void InitWarrior(tagWarrior* pWarrior, int nAttack, int nBlood, int nArmor, int nMR, int nAnger)
{
pWarrior->m_nAttack = nAttack;
pWarrior->m_nBlood = nBlood;
pWarrior->m_nArmor = nArmor;
pWarrior->m_nMagicResistance = nMR;
pWarrior->m_nAnger = nAnger;
}
int main() {
tagWarrior warr;
InitWarrior(&warr,100,1000,122,122,0);
return 0;
}
我们再来设计一个法师
struct tagMage //法师
{
int m_nMaAttack; //法术攻击力
int m_nBlood; //血量
int m_nArmor; //护甲
int m_nMagicResistance; //魔抗
int m_nMana; //法力值
};
接下来还有刺客,ADC等等。除了结构还有init函数,还有get和set函数,还有相关计算。这些很多东西其实是通用的,我们一直在写重复的代码。
我们可以把所有人共有的结构抽出来
struct tagHero
{
int m_nBlood; //血量
int m_nArmor; //护甲
int m_nMagicResistance; //魔抗
};
void InitHero(tagHero* ptagHero, int nBlood, int nArmor, int nMR)
{
ptagHero->m_nBlood = nBlood;
ptagHero->m_nArmor = nArmor;
ptagHero->m_nMagicResistance = nMR;
}
struct tagWarrior //战士
{
tagHero m_hero;
int m_nAttack; //攻击力
int m_nAnger; //怒气
};
void InitWarrior(tagWarrior* pWarrior,int nAttack, int nBlood, int nArmor, int nMR,int nAnger)
{
InitHero((tagHero*)pWarrior,nBlood,nArmor,nMR);
pWarrior->m_nAttack = nAttack;
pWarrior->m_nAnger = nAnger;
}
struct tagMage //法师
{
tagHero m_hero;
int m_nMaAttack; //法术攻击力
int m_nMana; //法力值
};
void InitMage(tagMage* pMage, int nMaAttack, int nBlood, int nArmor, int nMR, int nMana)
{
InitHero((tagHero*)pMage, nBlood, nArmor, nMR);
pMage->m_nMaAttack = nMaAttack;
pMage->m_nMana = nMana;
}
我们后面去设计新的英雄的结构体,很多重复的东西就不用写了。我们用C++该怎么写呢?
我们先做出两个类
class CHero
{
public:
CHero(int nBlood, int nArmor, int nMR) {
SetBlood(nBlood);
SetArmor(nArmor);
SetMagicResistance(nMR);
}
int GetBlood() const { return m_nBlood; }
void SetBlood(int val) { m_nBlood = val; }
int GetArmor() const { return m_nArmor; }
void SetArmor(int val) { m_nArmor = val; }
int GetMagicResistance() const { return m_nMagicResistance; }
void SetMagicResistance(int val) { m_nMagicResistance = val; }
private:
int m_nBlood; //血量
int m_nArmor; //护甲
int m_nMagicResistance; //魔抗
};
class CWarrior //战士
{
public:
CWarrior(int nAttack, int nBlood, int nArmor, int nMR, int nAnger) {
SetAttack(nAttack);
SetAnger(nAnger);
}
int GetAttack() const { return m_nAttack; }
void SetAttack(int val) { m_nAttack = val; }
int GetAnger() const { return m_nAnger; }
void SetAnger(int val) { m_nAnger = val; }
private:
int m_nAttack; //攻击力
int m_nAnger; //怒气
};
这时候我们的战士想调用获得血量的函数是调用不了的,因为这两个类没有任何关系。
我们的战士想要用到英雄里面的东西,只需要直接写class CWarrior:public CHero,我们还需要在战士类中写一个初始化列表
class CWarrior:public CHero //战士
{
public:
CWarrior(int nAttack, int nBlood, int nArmor, int nMR, int nAnger):CHero(nBlood, nArmor, nMR) {
SetAttack(nAttack);
SetAnger(nAnger);
}
int GetAttack() const { return m_nAttack; }
void SetAttack(int val) { m_nAttack = val; }
int GetAnger() const { return m_nAnger; }
void SetAnger(int val) { m_nAnger = val; }
private:
int m_nAttack; //攻击力
int m_nAnger; //怒气
};
我们去使用一下:

如果我们写法师的话,只需要实现法师自己的东西就好了,其他的从英雄类继承过来即可。
继承的称呼
class A {
};
class B :public A {
};
这个叫做B继承A,比如父亲死了,他可以把自己的东西传给自己的子女,子女就继承了父亲的东西。
一种叫做B继承A,A(父类、parent)、B(子类、child)
另一种叫做A派生出B,A(基类、base)、B(派生类、derive)
公有继承的权限问题
class A {
public:
A(int nA):m_nValA(nA){
}
int GetValA() const { return m_nValA; }
void SetValA(int val) { m_nValA = val; }
private:
int m_nValA;
};
class B :public A {
public:
B(int nValA,int nB) :A(nValA),m_nValB(nB) {
}
int GetValB() const { return m_nValB; }
void SetValA(int valB) { m_nValB = valB; }
private:
int m_nValB;
};
我们先写好两个类,我们B继承了A,那么B是否能访问A所有的成员呢?
void Test() {
SetValA(10);
}
这里不会有问题,也就是说子类可以访问父类的公有成员。
b.m_nValA;:无法访问 private 成员(在“A”类中声明)
也就是子类无法访问父类的私有成员。
我们再去试试protected的。发现是可以的。
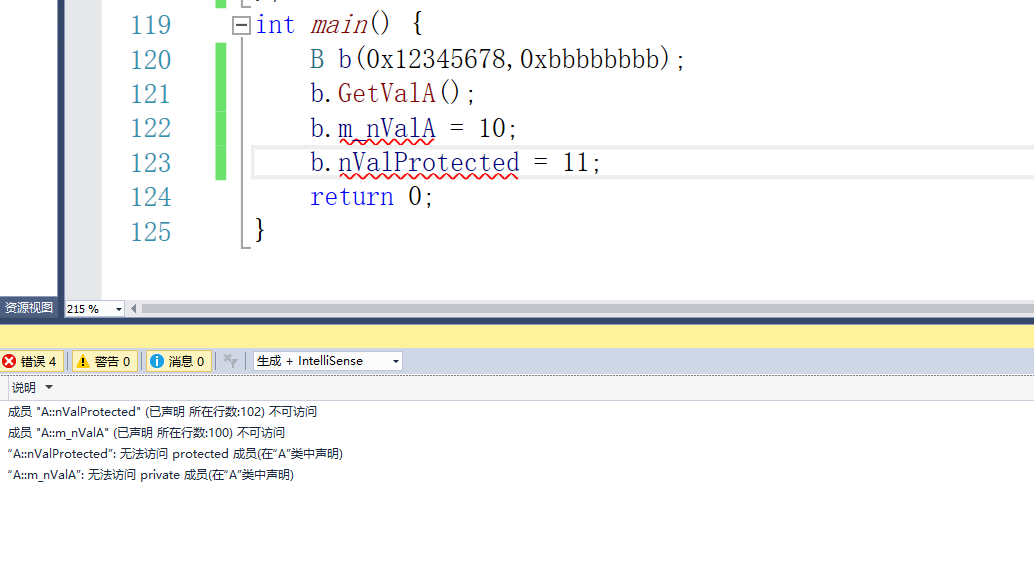
| 父类 | 子类是否能访问 | 类外是否可以访问 |
|---|---|---|
| public | YES | YES |
| private | NO | NO |
| protected | YES | NO |
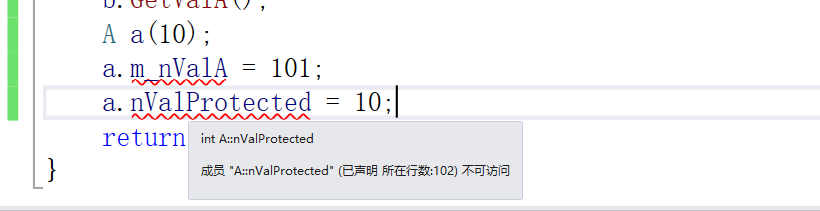
我们这个父类都无法在类外使用protected,所以这个protected就是给子类的类内使用的。
私有继承和保护继承
没有任何意义,正经写代码没人会这么整。非要试试呢,自己可以去试试。
继承中构造和析构的顺序
我们分别在两个类中写上构造和析构。
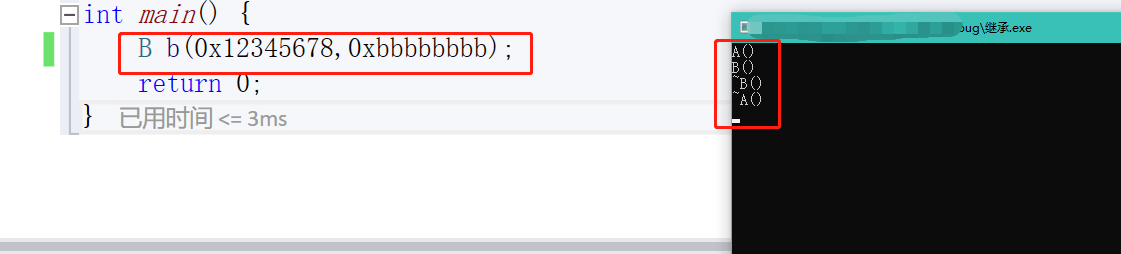
是父类先构造,然后子类再构造,析构的时候是先子类再父类。
如果有类对象成员呢?
class CFoo
{
public:
CFoo() { cout << "CFoo() " << endl; }
~CFoo() { cout << "~CFoo() " << endl; }
private:
};
class A {
public:
A(int nA) :m_nValA(nA) {
cout << "A() " << endl;
}
~A() {
cout << "~A() " << endl;
}
int GetValA() const { return m_nValA; }
void SetValA(int val) { m_nValA = val; }
private:
int m_nValA;
protected:
int nValProtected;
};
class B :public A {
public:
B(int nValA, int nB) :A(nValA), m_nValB(nB) {
cout << "B() " << endl;
}
~B() {
cout << "~B() " << endl;
}
int GetValB() const { return m_nValB; }
void SetValA(int valB) { m_nValB = valB; }
void Test() {
SetValA(10);
nValProtected = 8;
}
CFoo m_foo;
private:
int m_nValB;
};
int main() {
B b(0x12345678,0xbbbbbbbb);
return 0;
}
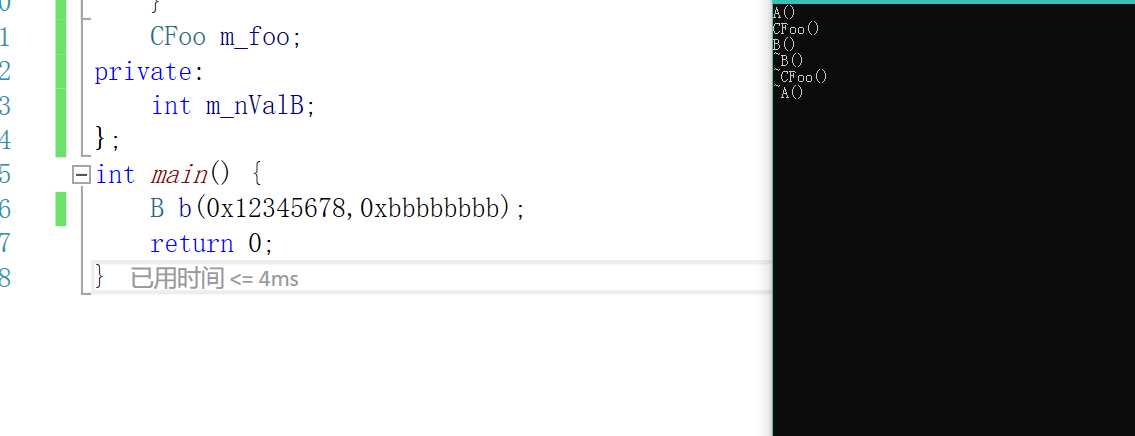
A先构造,然后CFoo再构造,最后再是B
B先析构,然后CFoo再析构,最后再是A
总结就是:
构造:先父类,再成员,再子类
析构:先子类,再成员,再父类
数据隐藏
我们再来看一个问题:
class A {
public:
void Test() {
}
int m_nValA;
};
class B :public A {
public:
void Test0() {
m_nValA = 99;
}
int m_nValA;
};
B中有一个和A同名的成员,那么在Test0中访问的是谁呢?

可以看到修改的是子类中的。如果我们B中有一个和A重名的函数呢?
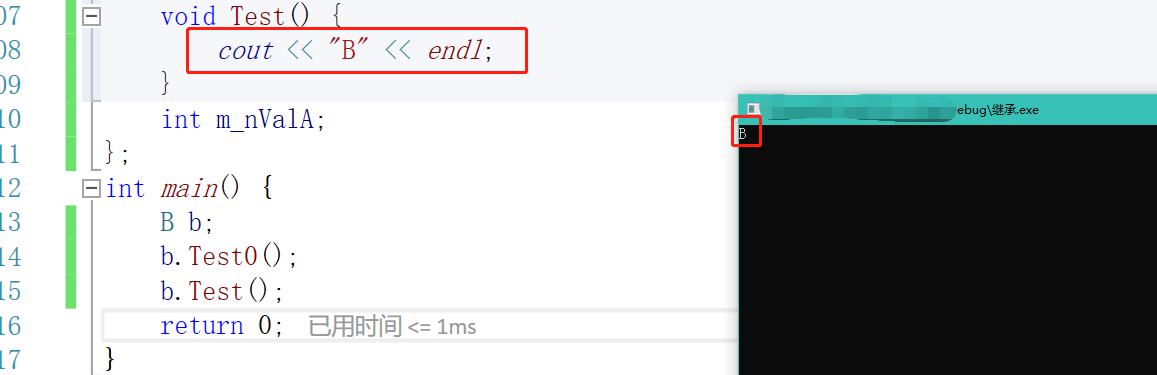
可以看出来是访问的B。
当子类内含有和父类同名的成员时,只会访问子类的。
但是如果我们就是想调用父类的呢?
在子类中调用:父类名::成员名
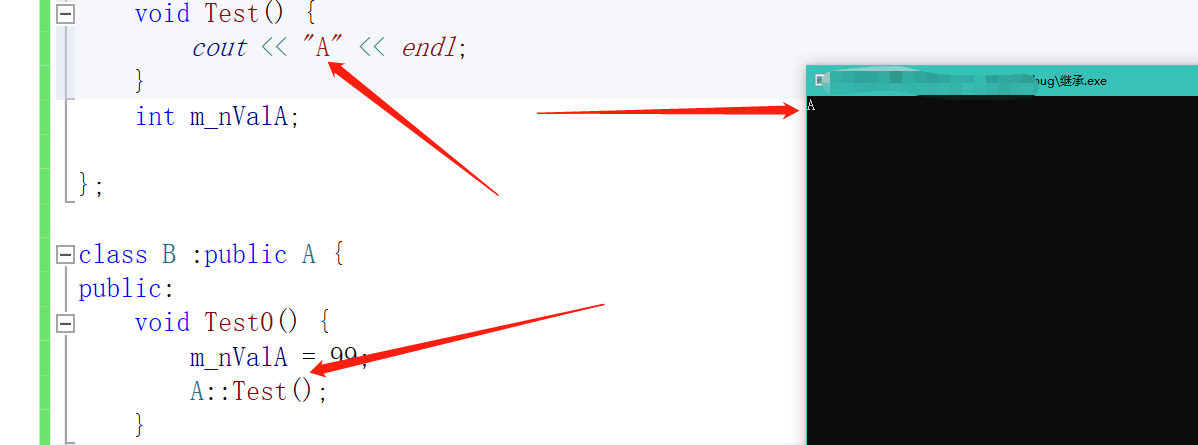
在类外调用:父类名::成员名

继承中的内存排布
class A {
public:
A(int nA) :m_nValA(nA) {
}
private:
int m_nValA;
};
class B :public A {
public:
B(int nValA, int nB) :A(nValA), m_nValB(nB) {
}
private:
int m_nValB;
};
我们去内存里面看一下他们这个是什么情况
我们之前是知道B只有一个数据成员,就是四个字节,但是现在加了继承,我们去sizeof他一下看看是多少个字节

这里看到是八个字节,另外的四个字节是什么呢?我们来看一下内存。
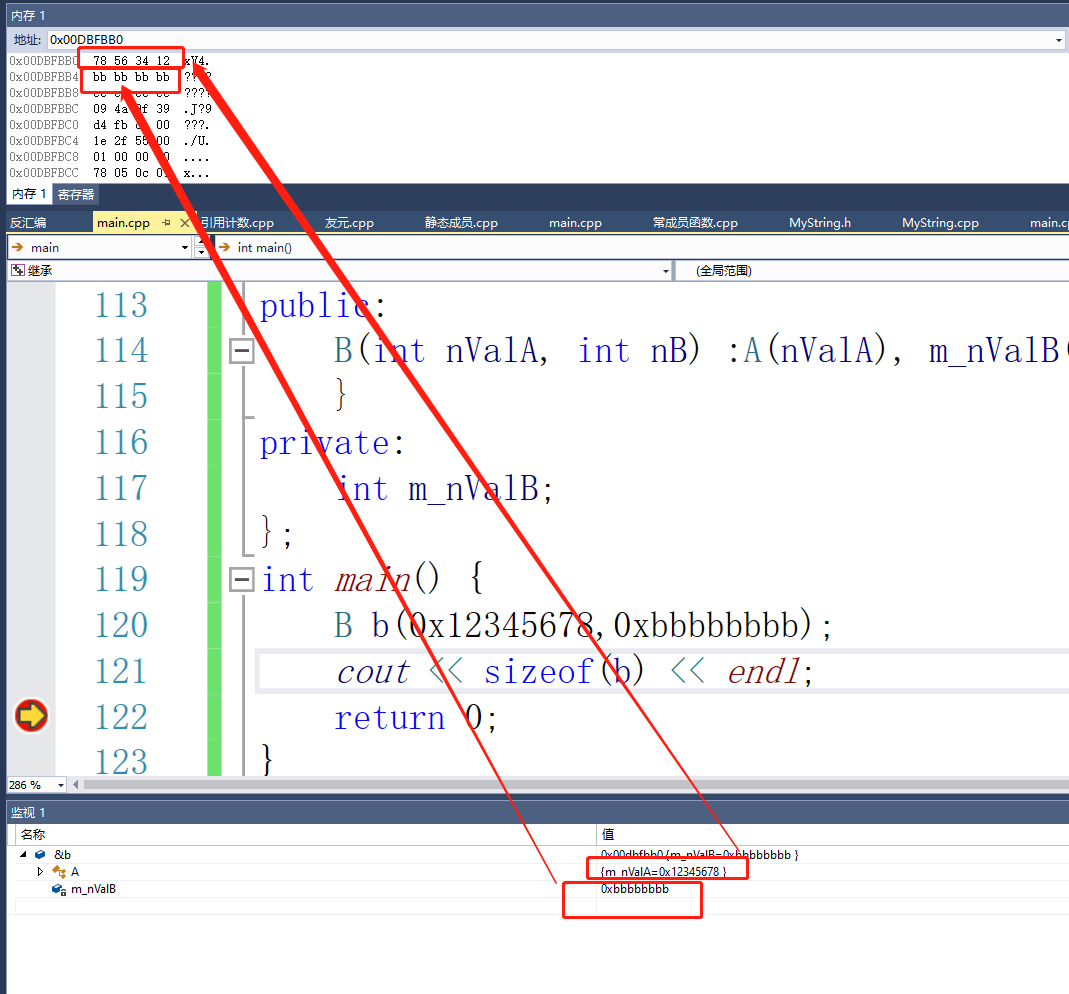
从内存上看,是B把A的数据都继承过来了。但是通过内存我们可以发现子类无法访问父类的私有成员其实是语法限制,我们来突破一下这个语法限制。
*(int*)&b = 0x66666666;
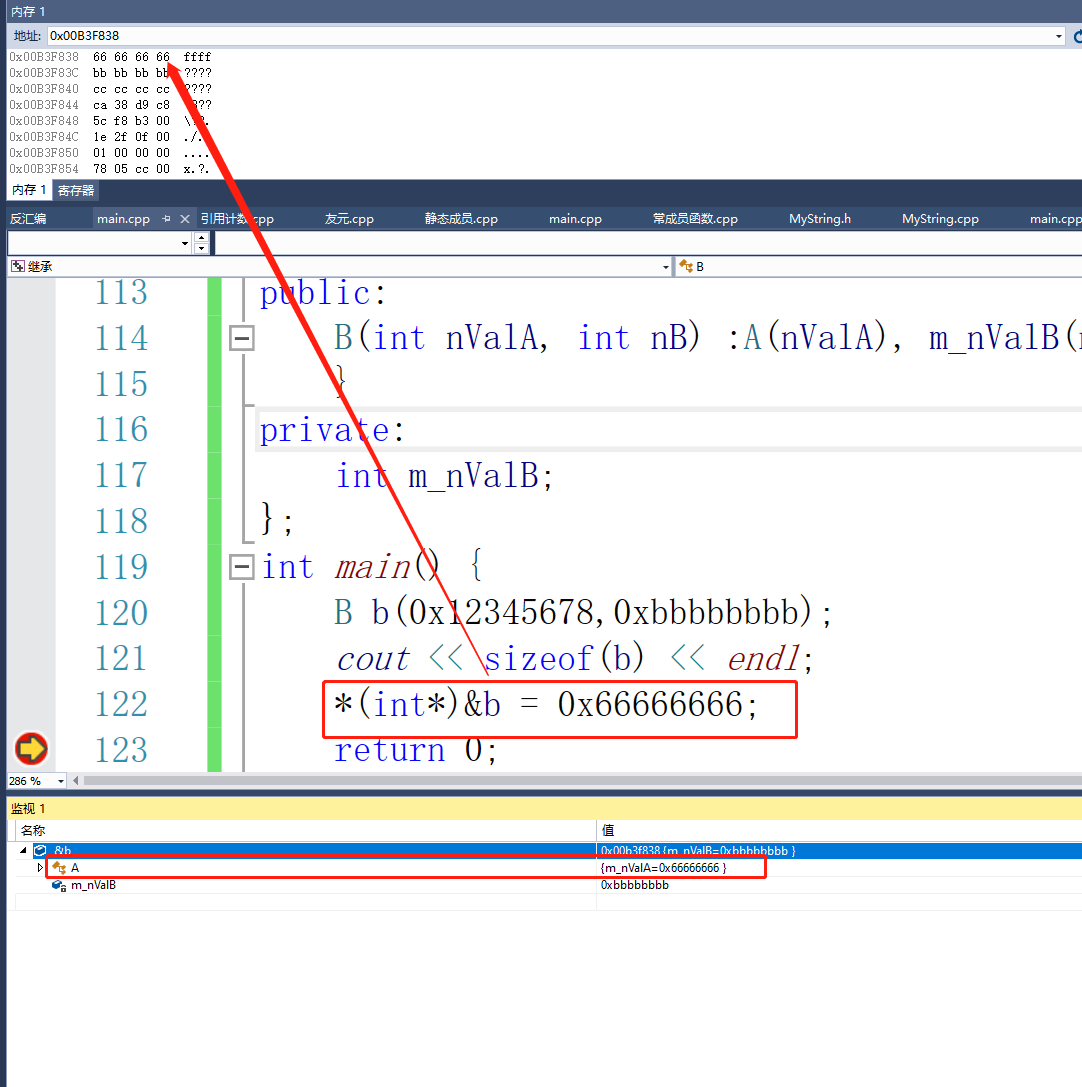
我们就通过子类修改了父类的私有成员了。
如果子类中有类对象成员要怎么排布呢?
class CFoo
{
private:
int m_nValCFoo = 0x12341234;
};
class A {
public:
A(int nA) :m_nValA(nA) {
}
private:
int m_nValA;
};
class B :public A {
public:
B(int nValA, int nB) :A(nValA), m_nValB(nB) {
}
private:
CFoo m_foo;
int m_nValB;
};

可以看到是先父类,再成员,最后子类。
B b(0x12345678, 0xbbbbbbbb);
A* p = &b;
A a(0xaaaaaaaa);
B* pB = (B*)&a;
这样的代码存在什么隐患吗?
首先父类指针指向子类对象是没有问题的,但是子类指针指向父类对象的话,如果去访问子类中的成员,在父类中是不存在的,就会出现问题。
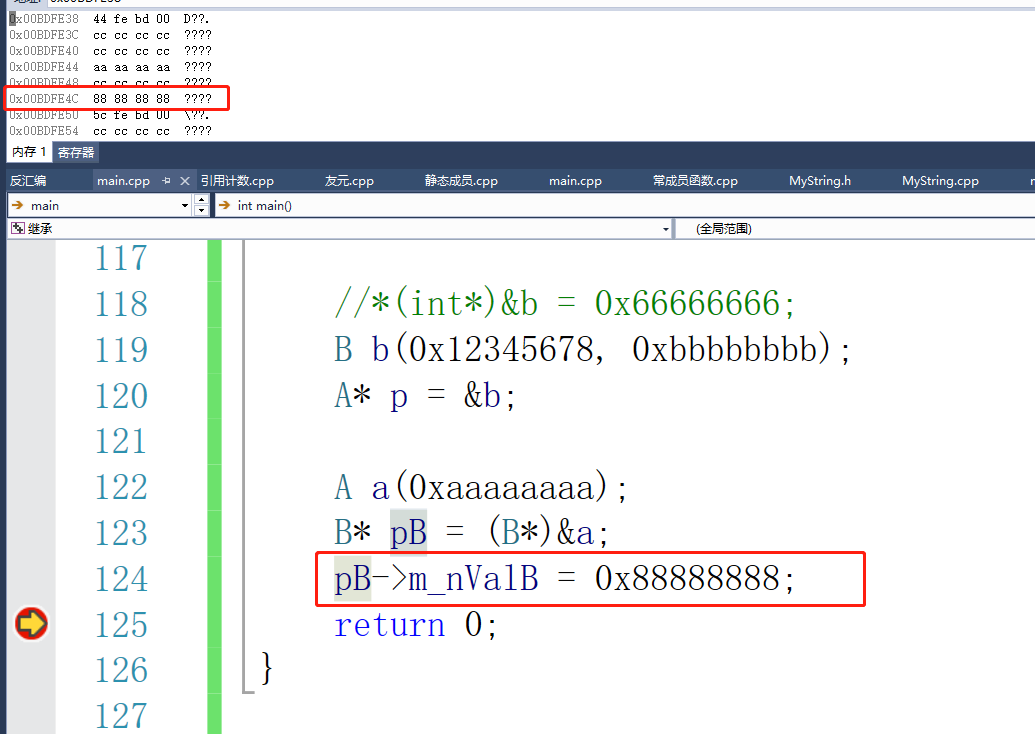
这里操作了并不属于对象的地址,是很不安全的。会造成访问越界。
注意:
子类转父类指针是安全的。
父类指针转自类是不安全的。
多态(虚函数)
他也是为了解决代码重用问题。
我们来写代码看一下。
class CHero {
public:
void UseSkills(int nSkill){
switch (nSkill)
{
case 0:
cout << "平A" << endl;
break;
case 1:
cout << "回城" << endl;
break;
default:
break;
}
}
};
class CWarrior:public CHero
{
public:
void UseSkills(int nSkill) {
switch (nSkill)
{
case 0:
cout << "平A" << endl;
break;
case 1:
cout << "回城" << endl;
break;
case 2:
cout << "千手如来掌" << endl;
break;
case 3:
cout << "葵花宝典" << endl;
break;
case 4:
cout << "独孤九剑" << endl;
break;
default:
break;
}
}
};
class CMage :public CHero
{
public:
void UseSkills(int nSkill) {
switch (nSkill)
{
case 0:
cout << "平A" << endl;
break;
case 1:
cout << "回城" << endl;
break;
case 2:
cout << "北冥神功" << endl;
break;
case 3:
cout << "火遁:豪火球之术" << endl;
break;
case 4:
cout << "百步穿肠散" << endl;
break;
default:
break;
}
}
};
我们先来定义几个类,再来写个操作界面
int main() {
//生成英雄
cout << "请选择要产生的英雄:[1]-战士 [2]-法师" << endl;
CHero* aryHeros[2] = { nullptr };
for (auto& pHero : aryHeros)
{
int nIdx = 0;
cin >> nIdx;
switch (nIdx)
{
case 1:
pHero = new CWarrior;
break;
case 2:
pHero = new CMage;
break;
default:
break;
}
}
//释放技能
cout << "请选择要释放的技能:[0-4]" << endl;
while (true)
{
cout << "请选择要释放的技能:[0-4] " << endl;
int nSkill = 0;
cin >> nSkill;
for (auto& pHero : aryHeros)
{
pHero->UseSkills(nSkill);
}
}
return 0;
}
我们会发现只能释放父类的技能,因为aryHeros是父类,父类指针指向子类对象不能调用子类对象成员。我们应该怎么来解决这个问题呢?
我们来引入一个东西:成员函数指针。
// 成员函数指针.cpp : 定义控制台应用程序的入口点。
//
#include "stdafx.h"
#include <iostream>
using namespace std;
class A
{
public:
void Test() {
cout << "A" << endl;
}
};
typedef void(*PFN_TEST)();
int main()
{
PFN_TEST pfn = A::Test;
return 0;
}
我们来看一下编译的结果:error C3867: “A::Test”: 非标准语法;请使用 "&" 来创建指向成员的指针
那么我们来加一个&来看看,报出了:error C2440: “初始化”: 无法从“void (__thiscall A::* )(void)”转换为“PFN_TEST”
根据报错继续修改:
typedef void(__thiscall A::*PFN_TEST)();
那么我们怎么来调用呢?
int main()
{
PFN_TEST pfn = &A::Test;
A a;
(a.*pfn)();
return 0;
}
如果现在是个指针要怎么调用么?
A* pA = &a;
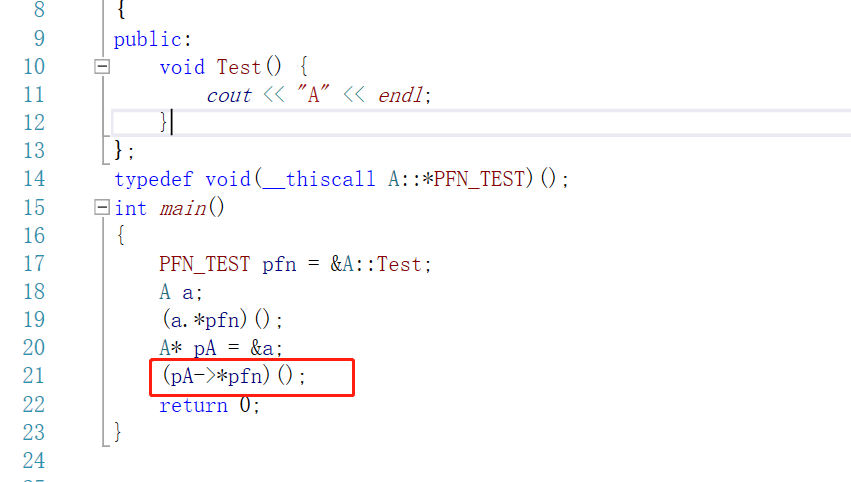
(pA->*pfn)();
这就是两种成员函数指针的调用方式。
这时候我们来看点幺蛾子。
我们能不能把一个基类的成员函数赋值给子类的成员函数指针呢?
#include <iostream>
using namespace std;
class B{
public:
void Test0() {
cout << "B::Test0" << endl;
}
};
class A:public B
{
public:
void Test() {
cout << "A::Test" << endl;
}
};
typedef void(__thiscall B::*PFN_TEST0)();
typedef void(__thiscall A::*PFN_TEST)();
int main()
{
PFN_TEST pfnATest = &B::Test0;
return 0;
}
PFN_TEST pfnATest = &B::Test0;//父类成员函数赋值给子类成员函数指针 安全的,因为是子类来调用,内存都可以访问到
PFN_TEST0 pfnBTest0 = (PFN_TEST0)&A::Test;//子类成员函数赋值给父类成员函数指针 不安全,因为是父类来调用,无法访问子类成员内存,造成访问越界
而且我们的语法不支持任何形式的将成员函数指针转换成一般函数指针,但是我们可以迂回操作一下。
PFN pfn = (PFN)*(int*)&pfnBTest0;
这段代码的意思是把:pfnBTest0这个函数指针的内存强转成int*,然后取出来值再转成PFN,但是没有什么意义,不要使用。这里只是为了跟编译器过两招。
我们来回到那个游戏代码,我们来定义一个成员函数指针:typedef void(CHero::*PFN_HERO_USESKILLS)();,然后在父类里面提供一个成员函数指针。
class CHero {
public:
void UseSkills(int nSkill){
switch (nSkill)
{
case 0:
cout << "平A" << endl;
break;
case 1:
cout << "回城" << endl;
break;
default:
break;
}
}
PFN_HERO_USESKILLS m_pfnHeroUseSkills;
};
那么什么时候对他进行赋值呢?
父类直接在构造函数中初始化。
class CHero;
typedef void(CHero::*PFN_HERO_USESKILLS)(int);
class CHero {
public:
CHero() { m_pfnHeroUseSkills = &CHero::UseSkills; }
void UseSkills(int nSkill){
switch (nSkill)
{
case 0:
cout << "平A" << endl;
break;
case 1:
cout << "回城" << endl;
break;
default:
break;
}
}
PFN_HERO_USESKILLS m_pfnHeroUseSkills;
};
这里修改函数指针是因为UseSkills有参数,要与其匹配,其他两个同理,强转一下即可,例如:CWarrior() { m_pfnHeroUseSkills = (PFN_HERO_USESKILLS)&CWarrior::UseSkills; }
那么我们怎么调用他呢?
(pHero->*(pHero->m_pfnHeroUseSkills))(nSkill);
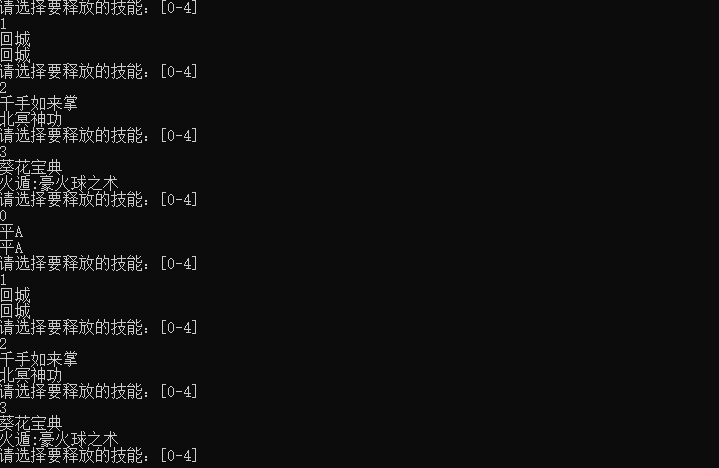
现在我们的程序就没有问题了。
多态是不关心子类对象的类型,调用属于其自己的成员函数。
我们再来加点东西,加个台词的函数
如果有很多成员函数,那就需要很多成员函数指针。能不能少些一点呢?

