

【论文理解】Human-level control through deep reinforcement learning(DQN)
Human-level control through deep reinforcement learning
PS:(结合论文Playing Atari with Deep Reinforcement Learning)
1. 论文背景
本文主要解决如何在高维度输入情况下进行增强学习Reinforcement Learning。比如打Atari游戏中,如何让机器学会控制目标使得游戏得分最多。
传统的办法:①Handcrafted特征,即人工提取特征(比如在游戏中用背景建模方式提取目标位置);②使用线性的价值方程或者策略来表征。由于人工提取特征的鲁棒性不够,传统方法的性能主要取决于特征提取的好坏;另外线性的价值方程不能很好得模拟现实中的非线性。
本文提出来的Deep-Q-Network可以很好解决以上问题,即 CNN + Q-Learning = Deep Q Network具体是将卷积神经网络和Q Learning结合在一起。卷积神经网络的输入是原始图像数据(作为状态)输出则为每个动作对应的价值Value Function来估计未来的反馈Reward。即使用CNN来拟合最优的动作估值函数(optimal action-value function)。
2. 论文原理
论文的主要方法流程:
1)对图片预处理
l 对图片编码的时候,图片像素取要被编码的图片像素和前一帧图像像素的最大值,这是为了消除flickering现象。
l 取RGB图片的灰度值,并且resize到84*84,取4帧(k=4鲁棒性最好)图像为输入。
2)模型架构
以往的求Q值的方法中使用了历史信息和动作作为输入,这导致了每个动作都会有一个Q值要计算,计算效率不高;该论文只有state作为输入,输出为每个动作对应的Q值的估计,这样在计算某个状态下的不同动作的Q值的时候,只需要计算一次网络的forward即可。模型如下

图 Deep-Q-Network
3)模型的细节
l 以往的方法对不同的游戏使用各不同的模型,该论文只用一种模型(基于少量的先验知识,比如输入图片,游戏动作种类,游戏生命数量等)训练,说明该论文模型的普适性好。
l 不同游戏的reward被归一化,正的为1,负的为-1,其他为0。这样做可以限制误差的比例并且可以使用统一的训练速度来训练不同的游戏。
l 因为训练的数据量大,并且冗余度高或者说重复性高,因此使用RMSProp算法进行训练, 梯度下降一看方向,二看步长,这里用Divide the gradient by a running average of its recent magnitude。通过引入一个衰减系数ϵ,让reward每回合都衰减一定比例。ϵ-greedy 策略让ϵ前1百万次线性地从1下降到0.1,然后保持在0.1不变。这样一开始的时候对Q值的更新采用随机搜索,后面慢慢使用最优的方法。这种方法很好的解决了深度学习中过早结束的问题,适合处理非平稳目标,但是引入了新的参数衰减系数ρ,依然依赖于全局学习速率。
l 对所有游戏跳四帧,理由是不大影响结果的情况下,计算效率更高。
4)评估策略
每个游戏玩30次,每次5分钟,然后和相同环境下人类相比得出结果。
5)具体算法
该论文把打游戏视为智能体agent通过一系列的action,observation,reward和环境(这里指Atari模拟器)进行交互。模拟器内部的状态不被agent获得,agent只能获取游戏画面以及相应的得分。显而易见的是现阶段的状态不仅仅是取决于当前游戏画面,也取决于之前的状态和动作。Agent可以通过这些来学会如何打游戏,即如何选取当前的动作使得未来的效益得分最高。

由此可以用SGD等梯度下降法解决。
特点是model-free,因为并没有固定明确的 ;同时也是off-policy,ϵ-greedy 策略让ϵ前1百万次线性地从1下降到0.1,然后保持在0.1不变。衰减参数为ϵ和选取动作参数为1-ϵ。这样一开始的时候对Q值的更新采用随机搜索,后面慢慢使用最优的方法。
6)训练Q-Network
训练的困难在于在使用s非线性函数拟合时很容易不稳定以致于发散。 原因主要是数据的相关性太强导致小的权值更新会导致policy策略大的变化。解决办法①experience replay,随机选取部分数据,目的是减少连续的帧的相关性以及使得Q更新更平滑,并且提高效率,还能使得训练不陷入局部最优;②固定θ 目标Q值周期性更新(target value action),而非每帧都更新,目的是减少目标和q值的相关性。
具体算法基本流程

l 初始化replay memory D,用来存储N个训练的样本
随机初始化action-value
function 的Q 卷积神经网络参数θ
初始化目标action-value function的卷积神经网络Q~,其参数θ~等于Q的参数θ
l 训练分成M个episode(即M场游戏),每个episode训练T次。每一次新的episode都要初始化state,并且做图像预处理,得到4 * 84 * 84的视频帧。
① 在每一次episode的单次训练中,当概率ϵ很小的时候,则选择一个随机的动作 ,或者根据当前的状态输入到当前的网络中计算出每个动作的Q值,选择Q值最大的一个动作,即最优动作。
② 使用以上动作得到相应的reward以及下一个image, 则下一个状态就往前再处理4帧的图像,得到新的网络输入。存储(上一个状态,动作,reward,下一个状态)转化数据到replay memory D中 (最多存N个,多的会覆盖原先的数据)。
③ 从replay memory D中随机选取一个存储的转化数据(上一个状态,动作,reward,下一个状态)来训练网络 。计算当前状态的目标action-value: 如果下一个状态游戏结束,那么action-value就是得到的reward;如果游戏没有结束,那么就将下一个处理好的状态输入到网络,得到target网络参数(不一定更新)。
④ 然后计算当前状态和动作下的Q值,将当前处理好的状态输入到网络,选择对应的动作的Q值。根据loss function通过SGD来更新参数Q中的参数。 每C次iteration后更新target网络的参数为当前的参数。(Fixed Target Q-network)
3. 论文结果
1)NIPS2013:
将算法应用到Atari2600游戏中,在测试的7个游戏中6个超过了以前的方法并且好几个超过人类的水平。
NATURE:
将算法应用到Atari2600游戏中,其中49个游戏水平超过人类,主要是改变是因为Fixed target Q-network。
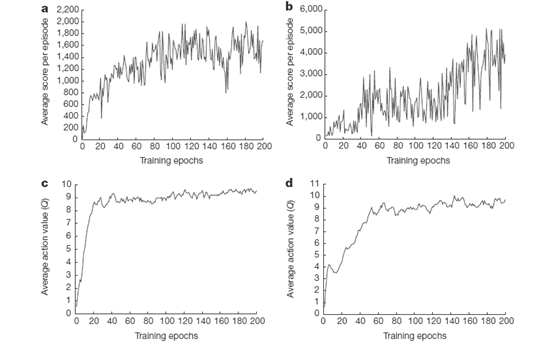
2)下图可以看出来训练的时候reward以及reward的预测的波动很大,很小的权值改变都可能导致得分以及策略输出的剧烈变化。 另外平均Q值的变化却是稳定的,原因在于每次的Target计算都是使用Q的最大值。
3)使用t-SNE算法来可视化高维数据,展示DQN最后一个隐藏层,以Square Enix Limited为例,说明了相似的state会放在接近的位置。有时候可能state不相似,但期望的reward相近(论文中图的下半部分)。得出的结论就是DQN网络能够从高维的原始输入中学习支持可适应规则的表征。
4. 论文总结以及未来工作
本文采用DQN的方式来解决高维图像输入下游戏操控的问题。
DQN的优点有如下:
1)算法普适性较强,一样的网络可以学习不同的游戏(针对于不同的Atari游戏)
2)采用端到端的训练方式,无需人工提取Feature,用CNN代替handcrafted特征。采用固定长度的历史数据,比如4帧图像作为一个状态输入。解决深度学习输入长度必须固定的问题。
3)通过不断的测试训练,使用reward来构造标签,可以实时生成无尽的样本用于有监督训练(Supervised Learning)
4)通过experience replay的方法来解决相关性及非静态分布问题。即建立一个经验池,把每次的经验都存起来,要训练的时候就随机的拿出一个样本来训练。
5)动作的选择采用常规的ϵ-greedy policy。 就是小概率选择随机动作,大概率选择最优动作。
DQN的缺点有如下:
1)由于输入的状态是短时的,所以只适用于处理只需短时记忆的问题,无法处理需要长时间经验的问题。
2)使用CNN来训练不一定能够收敛,需要对网络的参数进行精良的设置才行。(比如我现在项目做目标检测,使用在imagenet训练过的模型作为作为前置网络初始化参数,这使得CNN使得收敛不是太难,而该论文是从无到有手动配置CNN的。另外Loss函数比较复杂。)
3)因为物理内存有限,只存储N个经验在经验池里,这个方法的局限性就是这个经验池并没有区分重要的转移transition,总是覆盖最新的transition。
4)输入图片的像素还很低,如何扩展到以后复杂的游戏。
改进方向:
1)使用LSTM或者RNN 来增强网络记忆性。
2)改进Q-Learning的算法提高网络收敛能力。
3)使用优先的经验进行训练以改进性能。即有引导的经验池;物理上增加存储数据的容量D。
4)寻找生物学上的启发。
5)CNN模型结构的变化需要研究,比如研究全连接层是否可以被替换,以及一些在其它深度学习网络中训练的trick是否可以在这里使用。
posted on 2017-08-30 15:11 WegZumHimmel 阅读(1485) 评论(0) 编辑 收藏 举报

