Druid:通过 Kafka 加载流数据
**## 开始
本教程演示了如何使用 Druid 的 Kafka indexing 服务从 Kafka 流中加载数据至 Druid。
在本教程中,我们假设你已经按照 quickstart 文档中使用micro-quickstart单机配置所描述的下载了 Druid,并在本机运行了 Druid。你不需要加载任何数据。
下载并启动 Kafka
Apache Kafka是一种高吞吐量消息总线,可与 Druid 很好地配合使用。在本教程中,我们将使用 Kafka 2.1.0。在终端运行下面命令下载 Kafka:
curl -O https://archive.apache.org/dist/kafka/2.1.0/kafka_2.12-2.1.0.tgz
tar -xzf kafka_2.12-2.1.0.tgz
cd kafka_2.12-2.1.0
在终端运行下面命令启动 kafka broker:
./bin/kafka-server-start.sh config/server.properties
运行下面命令创建名为wikipedia的 topic,我们将向其发送数据:
./bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic wikipedia
向 Kafka 加载数据
为wikipedia topic 启动一个 kafka producer,并发送数据。
在 Druid 目录下,运行下面命令:
cd quickstart/tutorial
gunzip -c wikiticker-2015-09-12-sampled.json.gz > wikiticker-2015-09-12-sampled.json
在 Kafka 目录下运行下面命令,将{PATH_TO_DRUID}替换成你的 Kafka 路径:
export KAFKA_OPTS="-Dfile.encoding=UTF-8"
./bin/kafka-console-producer.sh --broker-list localhost:9092 --topic wikipedia < {PATH_TO_DRUID}/quickstart/tutorial/wikiticker-2015-09-12-sampled.json
上面命令会向 kakfa 的wikiapedia topic 发送 events。之后,我们将使用 Druid 的 Kafka indexing 服务从 Kafka topic 中提取数据。
通过 data loader 加载数据
导航至 localhost:8080 并单击控制台顶部的Load data。
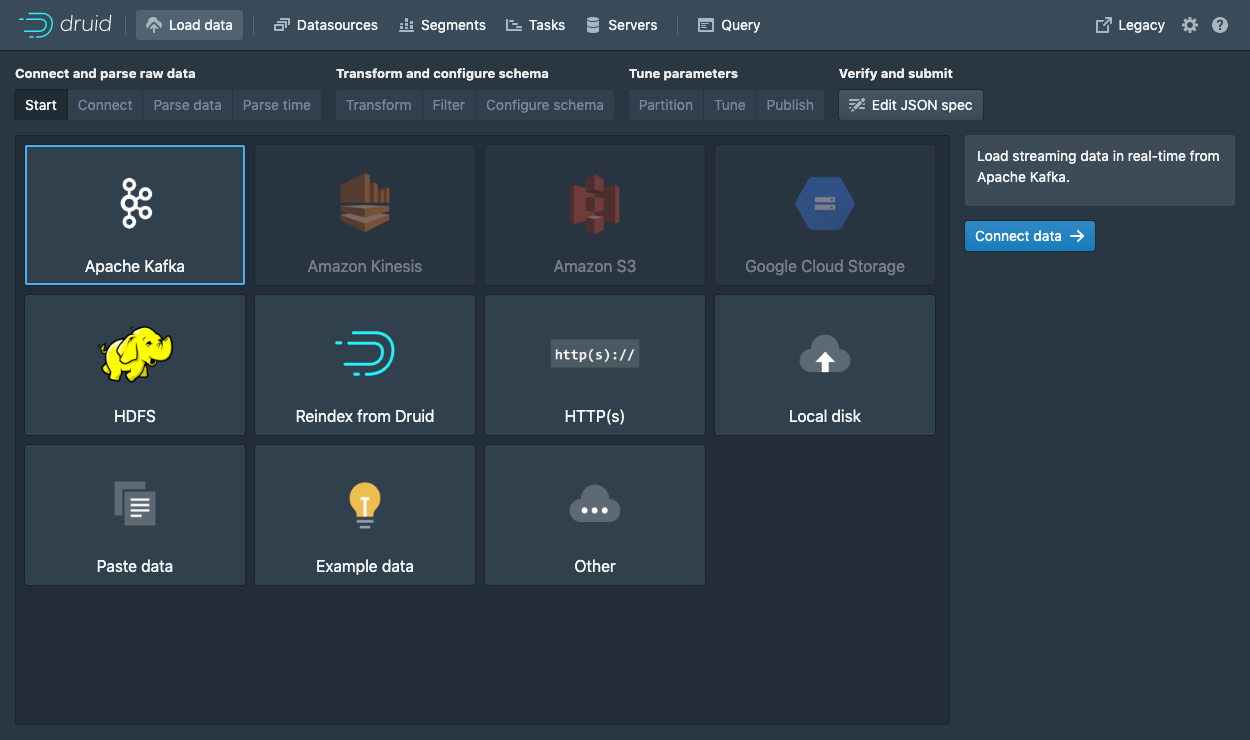
选择 Apache Kafka 并单击 Connect data.
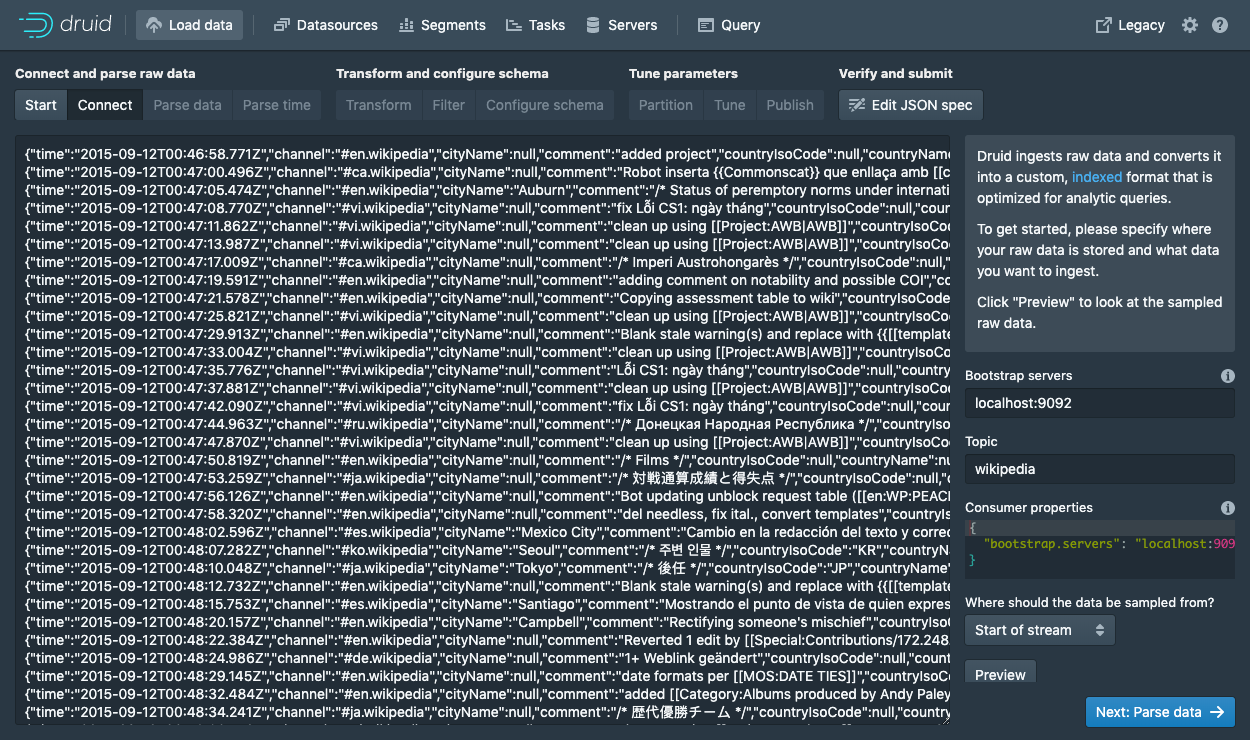
输入 bootstrap:localhost:9092和 topic:wikipedia。
单击Preview并确定你看到的数据正确。
找到数据后,可以单击"Next: Parse data"进入下一步。
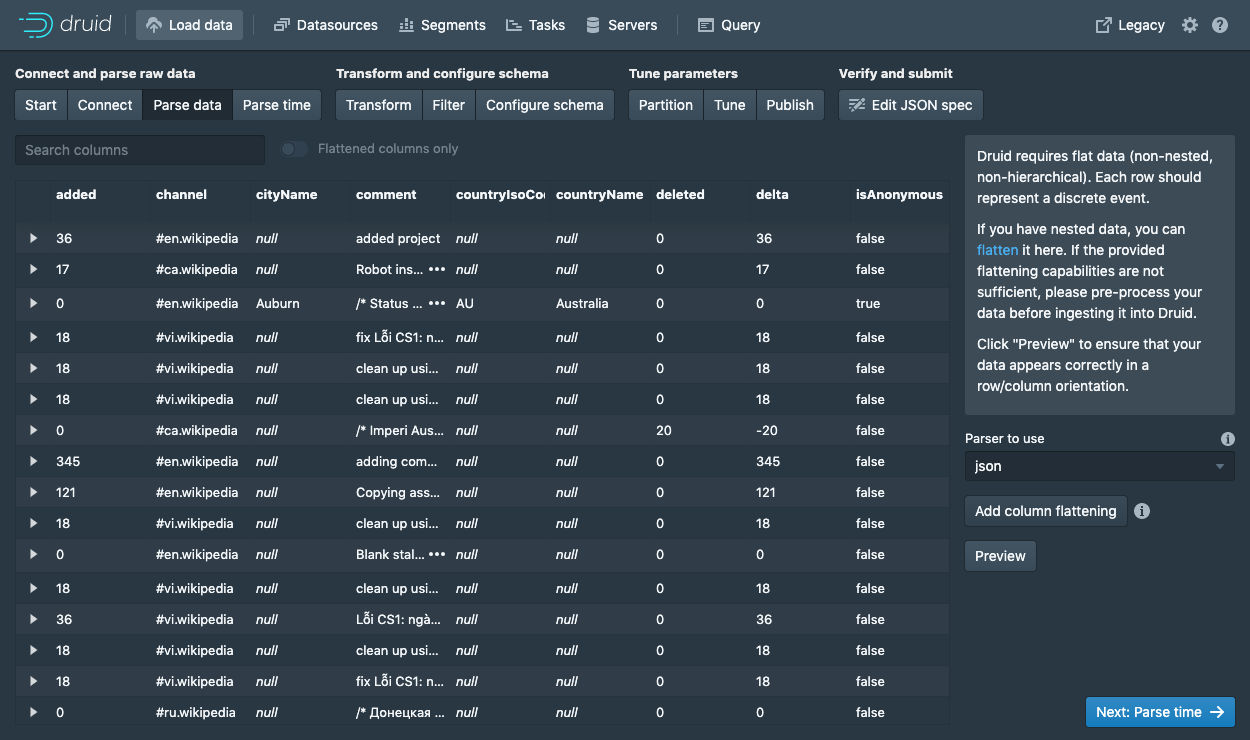
data loader 会尝试自动选择正确的数据解析器。在本示例中,将选择json解析器。你可以尝试选择其他解析器,看看 Druid 是如何解析数据的。
选择json解析器,点击Next: Parse time进入下一步,来确定 timestamp 列。
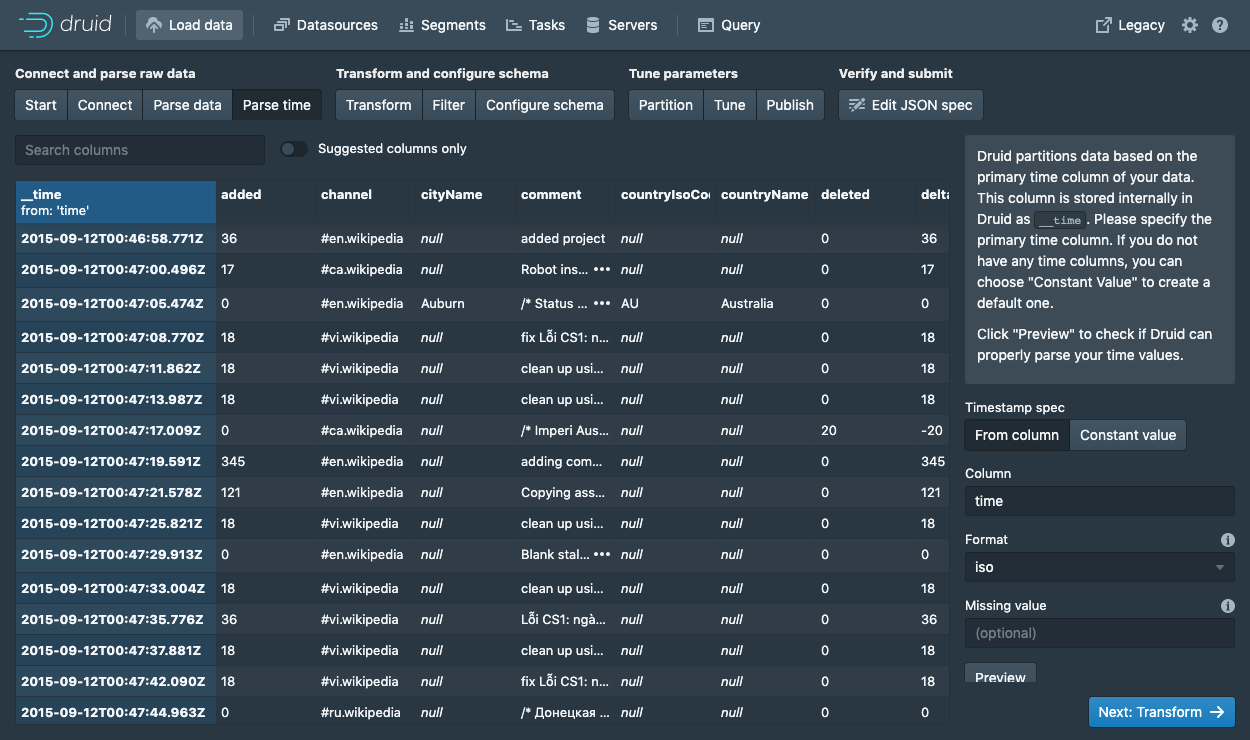
Druid 需要一个主 timestamp 列(内部将存储在__time 列)。如果你的数据中没有 timestamp 列,选择Constant value。在我们的示例中,将选择time列,因为它是数据之中唯一可以作为主时间列的候选者。
单击Next: ...两次以跳过Transform和Filter步骤。
您无需在这些步骤中输入任何内容,因为应用提取数据的时间变换和过滤器不在本教程范围内。
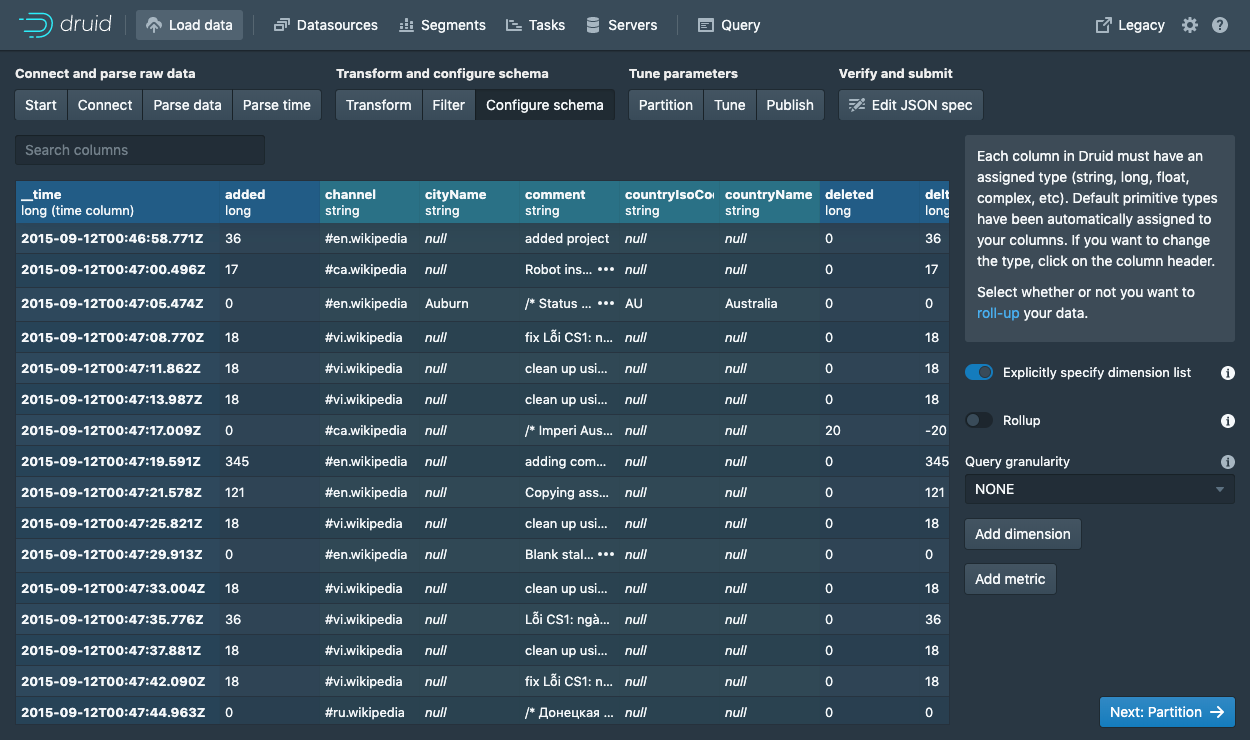
在Configure schema步骤中,你可以配置哪些维度和指标可以摄入 Druid。这是数据被摄入 Druid 后呈现的样子。由于我们的数据集比较小,点击Rollup开关关闭 rollup 功能。
对 schema 配置满意后,单击Next进入Partition步骤,以调整数据至 segment 的分区。
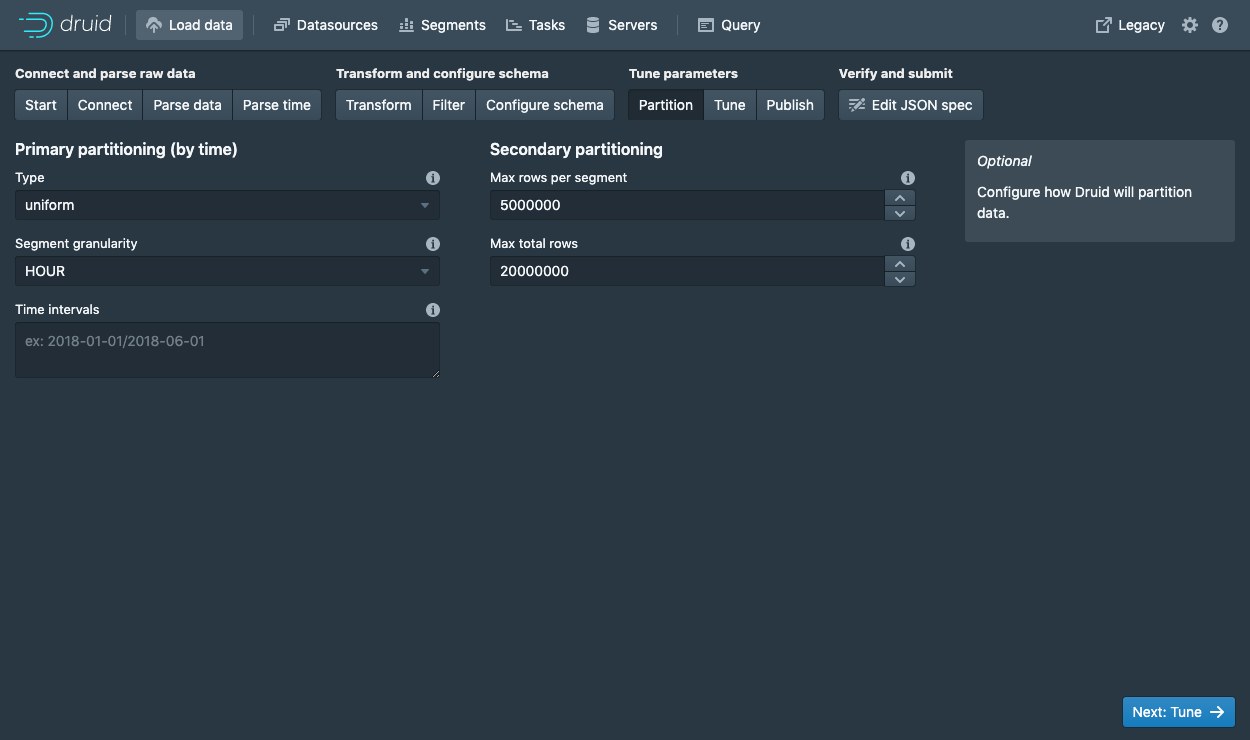
在这里,您可以调整如何在 Druid 中将数据拆分为多个段。由于这是一个很小的数据集,因此在此步骤中无需进行任何调整。
单击Tune步骤后,进入发布步骤。
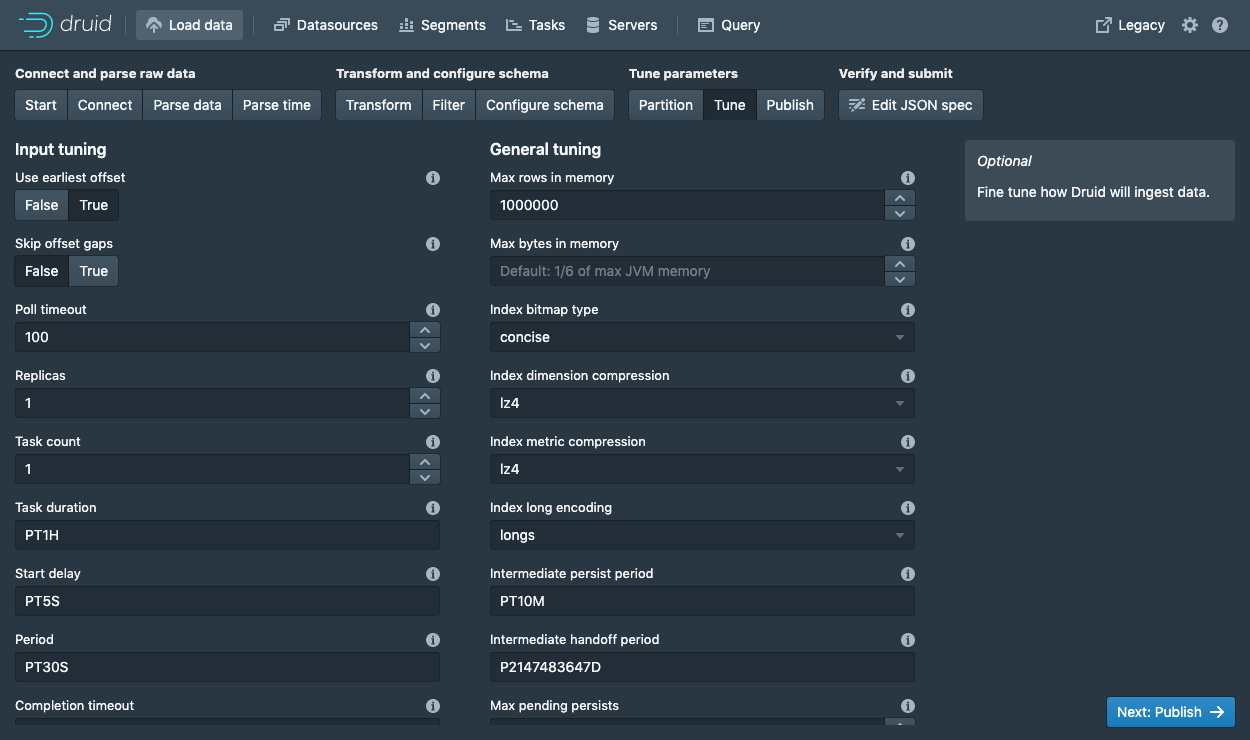
在Publish步骤中,我们可以指定 Druid 中的数据源名称。我们将此数据源命名为wikipedia。最后,单击Next以查看 spec。
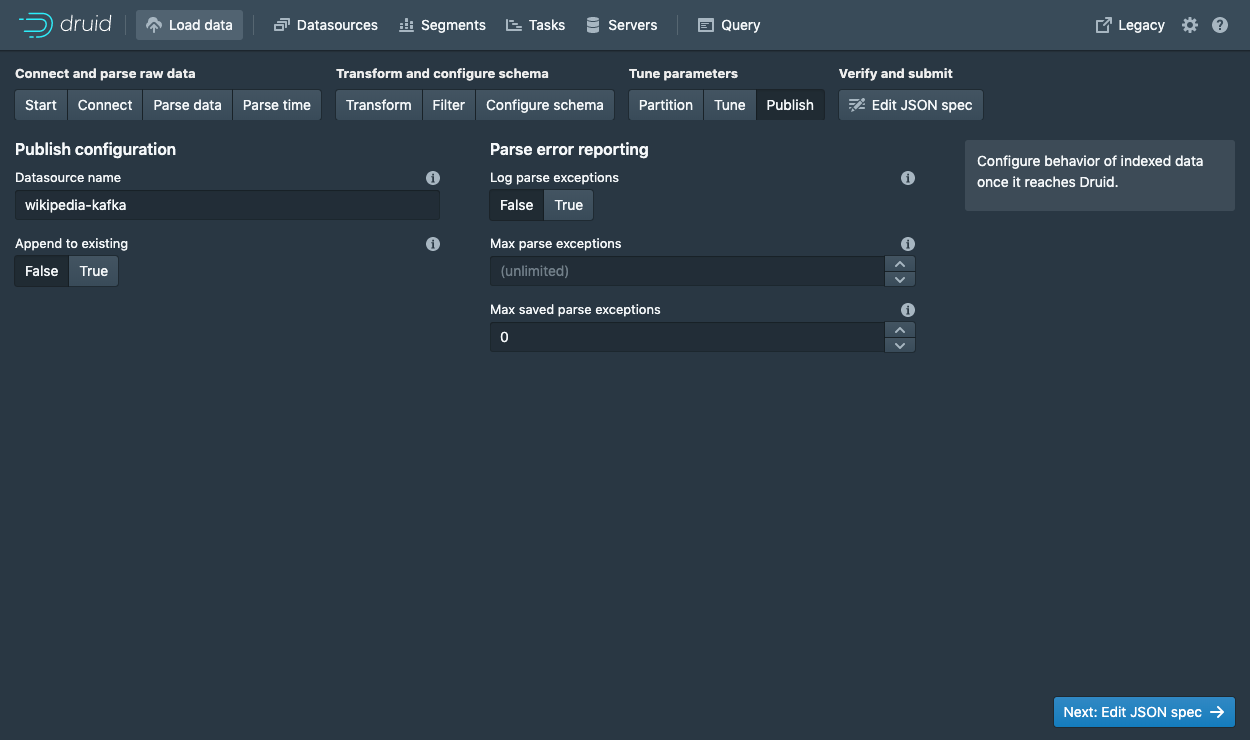
这是你构建的 spec。尝试随意返回并在之前的步骤中进行更改,以查看变动将如何更新 spec。同样,你也可以直接编辑 spec,并在前面的步骤中看到它。
对 spec 满意后,点击Submit创建摄取任务。
你将进入任务视图,重点关注新创建的任务。任务视图设置为自动刷新,等待任务成功。
当一项任务成功完成时,意味着它建立了一个或多个 segment,这些 segment 将由数据服务器接收。
Datasources从标题导航到视图。
等待直到你的数据源(wikipedia)出现。加载 segment 时可能需要几秒钟。
一旦看到绿色(完全可用)圆圈,就可以查询数据源。此时,你可以转到Query视图以对数据源运行 SQL 查询。
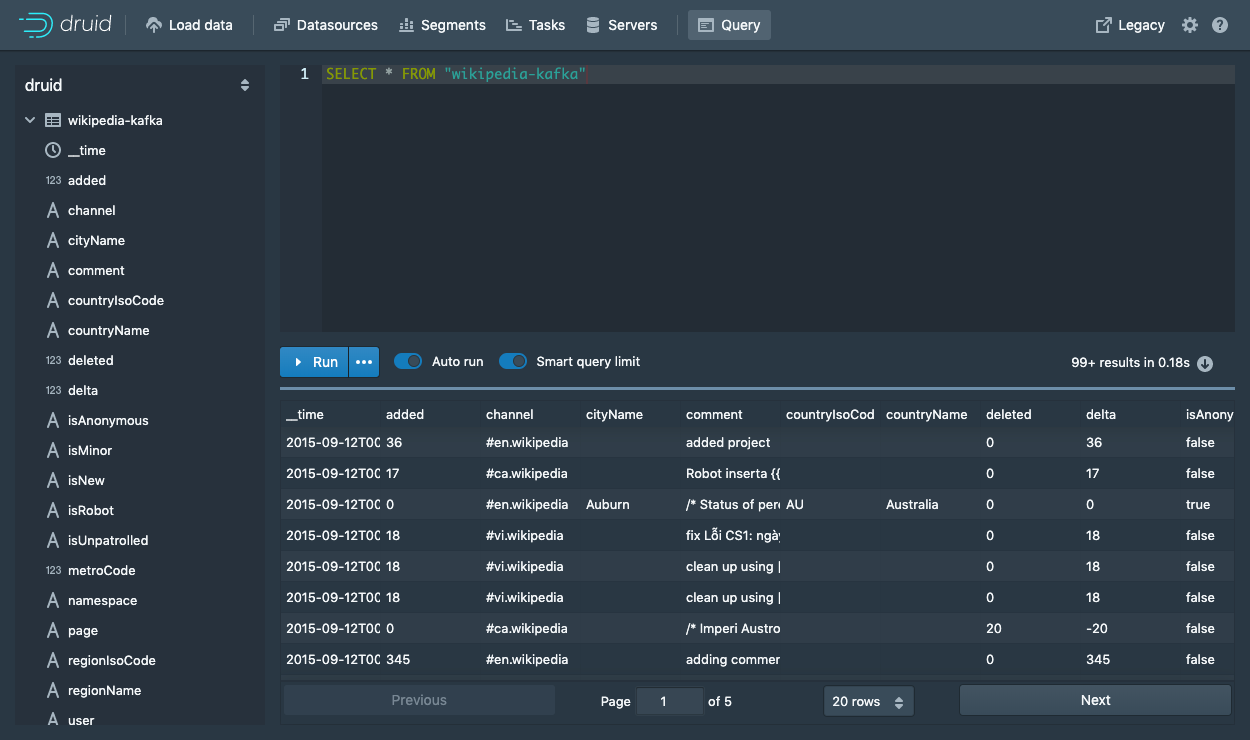
运行SELECT * FROM "wikipedia"查询以查看结果。
通过控制台提交 supervisor
在控制台中,单击Submit supervisor打开提交 supervisor 窗口。
粘贴以下 spec 并点击提交:
{
"type": "kafka",
"spec" : {
"dataSchema": {
"dataSource": "wikipedia",
"timestampSpec": {
"column": "time",
"format": "auto"
},
"dimensionsSpec": {
"dimensions": [
"channel",
"cityName",
"comment",
"countryIsoCode",
"countryName",
"isAnonymous",
"isMinor",
"isNew",
"isRobot",
"isUnpatrolled",
"metroCode",
"namespace",
"page",
"regionIsoCode",
"regionName",
"user",
{ "name": "added", "type": "long" },
{ "name": "deleted", "type": "long" },
{ "name": "delta", "type": "long" }
]
},
"metricsSpec" : [],
"granularitySpec": {
"type": "uniform",
"segmentGranularity": "DAY",
"queryGranularity": "NONE",
"rollup": false
}
},
"tuningConfig": {
"type": "kafka",
"reportParseExceptions": false
},
"ioConfig": {
"topic": "wikipedia",
"inputFormat": {
"type": "json"
},
"replicas": 2,
"taskDuration": "PT10M",
"completionTimeout": "PT20M",
"consumerProperties": {
"bootstrap.servers": "localhost:9092"
}
}
}
}
这将启动 supervisor,并分化出 task 监听数据流入。
直接提交 supervisor
为了直接启动服务,我们需要在 Druid 包根目录下运行下面命令提交一个 supervisor spec 给 Druid overlord:
curl -XPOST -H'Content-Type: application/json' -d @quickstart/tutorial/wikipedia-kafka-supervisor.json http://localhost:8081/druid/indexer/v1/supervisor
如果 supervisor 成功创建,你将得到一个包含 supervisor ID 的响应。在我们的示例中,将返回{"id":"wikipedia"}。
你可以在控制台中查看当前 supervisor 和 tasks: http://localhost:8888/unified-console.html#tasks.
查询数据
当数据发送给 Kafka stream 后,立刻就可以查询数据。
本文翻译自 Druid 官方文档
请关注我们。一起学习 Druid 知识。

**

 浙公网安备 33010602011771号
浙公网安备 33010602011771号