【译】用jQuery 处理XML-- DOM(文本对象模型)简介
用jQuery 处理XML--浏览器中的XML与JavaScript
来自IBM Developer Works
DOM(文本对象模型)简介
在正式开始介绍jQuery处理XML前我们来了解一些必备的基础知识。
DOM是HTML或者XML结构的一种展现形式,通过编程对DOM进行修改可以达到修改HTML/XML的目的。这部分使用一段简单的HTML文档并配合几个简单的例子来展示使用JavaScript对DOM上各节点的遍历和操作。
JavaScript中操作DOM
JavaScript中提供了一套完备的方法来获取,遍历,操作DOM。这里不详述,只是通过简单的例子来说明如何对操作。
后面的例子都基于以下HTML片段:
Listing 1. A simple HTML document
|
<!DOCTYPE html> <html> <head> <title>This is the page Title</title> </head> <body class="signed-out"> <div id="header"> <ul id="nav"> <li><a href="/home" class="home">Home</a></li> <li><a href="/about" class="about">About</a></li> <li><a href="/auth" class="auth">Sign In</a></li> </ul> </div> <div id="article"> <h1>A Plain DOM</h1> <h2>An sample <b>HTML</b> document.</h2> <div id="section"></div> </div> </body> </html> |
清单1中,id为header的Div中包含了一些导航链接,为了在JavaScript中取得这个id为header的Div,可以像清单2中的代码这样:
Listing 2. Getting a DOM element by id
|
<script type="text/javascript"> var article = document.getElementById("article"); </script> |
getElementById()是JavaScript中获取DOM元素最快的方法。元素的id属性可以让浏览器直接在众多DOM元素中找到它,因为id是唯一的。但由于当DOM中有重复的id时,浏览器并不会报错,并且微软的IE还把元素的name属性也当id来处理,所以在编写HTML代码时你要注意避免使用重复的id。
另一种获取DOM元素的方法为getElementsByTagName()。这个方法对于处理XML来说很重要,因为在XML中不那么容易会有id属性。清单3展示了getElementsByTagName()的使用,用它来获取H1节点。
Listing 3. Getting a set of elements by tag name
|
<script type="text/javascript"> var headers = document.getElementsByTagName("h1"); // returns array of H1 elements alert(headers[0].innerHTML); // alerts inner html of the first H1 tag: "A Plain DOM" </script> |
这里注意两点有趣的地方。第一点是getElementsByTagName() 返回的是一个数组(包含所给元素名的所有元素组成的一个数组)。因为本例中只有一个H1元素,所以可以通过访问[0]下标来获取该元素。但这种方法是不保险的。因为页面中可能不存在H1元素,那么妳通过下标[0]就返回不到任何东西,然后浏览器可能会报错。 所以在使用获得的一个元素的属性(或方法时),最好先检查这个元素是否存在并且成功取到了。
第二,妳可能注意到了innerHTML 这个属性。顾名思义,通过它可以访问一个元素的内容,本例中则是H1中的文本。如果H1中还包含了其它元素的话,那么返回的这个文本中也包含这些元素。如清单4所展示的那样。
Listing 4. Using innerHTML to retrieve value with HTML elements
|
<script type="text/javascript"> var subheaders = document.getElementsByTagName("h2"); // returns array of H1 elements alert(subheaders[0].innerHTML); // "An sample <b>HTML</b> document." </script> |
除了innerHTML外,浏览器还提供一个只返回元素的文本内容的方法。但这个方法在IE中叫做innerText 然而在其他浏览器中又叫做textContent 。所以为了写出跨浏览器通用的代码,妳可以需要像清单5这样操作。
Listing 5. Using innerText and textContent properties across different browsers
|
<script type="text/javascript"> var headers = document.getElementsByTagName("h1"); // returns array of H1 elements var headerText = headers[0].textContent || headers[0].innerText; </script> |
这样,如果textContent 有返回值的话, headerText 变量就获取它,否则获取innerText 返回的值。一个更明智的做法是把这些有浏览器差异的地方都写一个方法来处理,jQuery已经包装了这些方法。
上文提供的HTML代码片段中包含了一个"Sign in"的连接,假设用户已经通过某种方式登陆了,我们想把这个"Sign in" 改掉显示成"Sign out"。在先前的例子中,通过使用innerHTML来得到元素的内容,现在也可以用它来设置元素的内容。清单6展示了这个特性。
Listing 6. Updating the innerHTML value of a DOM node
|
<script type="text/javascript"> var authElem = document.getElementById("auth"); // returns single element authElem.innerHTML = "Sign Out"; // Updates element contents </script> |
除了更新已有的节点内容外,还可以创建全新的元素然后附加到已有的DOM元素上去(见清单7)。
Listing 7. Creating and injecting a new DOM node
|
<script type="text/javascript"> var ulElems = document.getElementsByTagName("ul"); // returns array of UL elements var ul = ulElems[0]; // get the first element (in this case, the only one)
var li = document.createElement("li"); // create a new list item element var text = document.createTextNode("List Item Text"); // create a text node
li.appendChild(text); // append text node to li node (still not added to DOM) ul.appendChild(li); // append new list node to UL, which inserts it into DOM </script> |
正如上面代码所示,妳可以看到getElementById()和getElementsByTagName()经常是通过document来调用,这意味着方法是在document上面执行。妳当然也可以让方法在其他元素上执行,从而缩小找到目标需要的范围。这样的方法调用始终假设妳所想到获取的目标元素是妳所调用方法那个元素的子元素。记住这点因为在后面用jQuery处理XML时也是同样的道理。
从DOM移除元素也是小事一桩。首先是获取这个元素,然后通过它的父元素来调用移除方法。(见清单8)。(关于parentNode 及相关属性将在下面会介绍)
Listing 8. Removing an element from the DOM
|
<script type="text/javascript"> var firstList = document.getElementsByTagName("ul")[0]; firstList.parentNode.removeChild(firstList); </script> |
现在让我们来进行属性的设置及属性的移除。通过使用setAttribute() 和 getAttribute() 来实现(见清单9)。
Listing 9. Setting and removing an element attribute
|
<script type="text/javascript"> var firstUL = document.getElementsByTagName("ul")[0]; firstUL.setAttribute("class", "collapsed"); firstUL.getAttribute("class"); // returns "collapsed" </script> |
JavaScript 中遍历DOM元素
除了获取和处理DOM元素外,JavaScript学提供了一套完备的用来遍历DOM节点的方法。在之前的例子里妳已经看到过parentNode 这个方法的使用了。给定一个DOM元素后,妳就可以得到它周围的一些元素。
Listing 10. JavaScript's DOM traversal properties
|
firstChild //获取第一个子节点 lastChild //获取最后一个子节点 nextSibling //获取下一下兄妹节点 parentNode //获取父节点 previousSibling //获取前一个兄妹节点 |
更多关于节点属性的信息请移步这里。
DOM节点间的这些相邻关系在HTML中就像清单11所展示的那个样子。
Listing 11. Relationship of related DOM elements
|
<parent_node> <previous_sibling/> <node> <first_child/> ... <last_child/> </node> <next_sibling/> </parent_node> |
最后我们来考虑一下展示了这些层级关系的树状图,见图1。一个给定的节点比如图中的"NODE",往上是父节点,处于同一层的包括了它的前一个和后一个兄妹节点。一个节点可以包含一个或多个子节点(其中就包括了第一个子节点firstChild 和最后一个子节点lastChild )。
Figure 1. Tree representation of adjacent nodes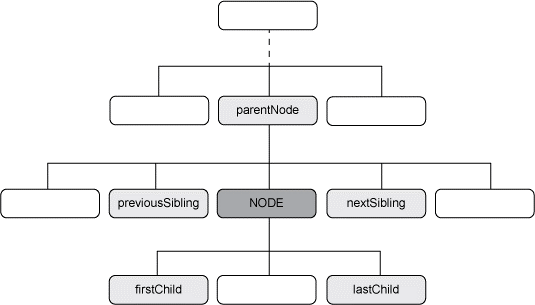
当我产创建一个用来从给定起点遍历DOM元素的方法时,这些元素间的层级关系就变得非常有用(见清单12的例子)。在处理XML也会用到相似的方法。
Listing 12. JavaScript function for traversing the DOM
|
<script type="text/javascript"> function traverseDOM(node, fn){ fn(node); // execute passed function on current node node = node.firstChild; // get node's child while (node){ // if child exists traverseDOM(node, fn); // recursively call the passed function on it node = node.nextSibling; // set node to its next sibling } }
// example: adds "visited" attribute set to "true" to every node in DOM traverseDOM(document, function(curNode){ if (curNode.nodeType==="3"){ // setAttribute() only exists on an ELEMENT_NODE // add HTML5 friendly attribute (with data- prefix) curNode.setAttribute("data-visited", "true"); } }); </script> |
到这里,妳应该已经熟悉HTML中遍历和处理各元素了。下一节当中将展示如何将同样的方法应用到XML的处理上。
 CC BY-NC-SA 署名-非商业性使用-相同方式共享
CC BY-NC-SA 署名-非商业性使用-相同方式共享

 浙公网安备 33010602011771号
浙公网安备 33010602011771号