消息队列 RabbitMQ
前言
什么是rabbitMQ
RabbitMQ 是一个由 Erlang 语言开发的 AMQP 的开源实现。一款基于AMQP协议的消息中间件,它能够在应用之间提供可靠的消息传输。在易用性,扩展性,高可用性上表现优秀。而且使用消息中间件利于应用之间的解耦,生产者(客户端)无需知道消费者(服务端)的存在。而且两端可以使用不同的语言编写,大大提供了灵活性。
AMQP :Advanced Message Queue,高级消息队列协议。它是应用层协议的一个开放标准,为面向消息的中间件设计,基于此协议的客户端与消息中间件可传递消息,并不受产品、开发语言等条件的限制。
RabbitMQ是由RabbitMQ Technologies Ltd开发并且提供商业支持的。该公司在2010年4月被SpringSource(VMWare的一个部门)收购。在2013年5月被并入Pivotal。其实VMWare,Pivotal和EMC本质上是一家的。不同的是VMWare是独立上市子公司,而Pivotal是整合了EMC的某些资源,现在并没有上市。
RabbitMQ的官网是http://www.rabbitmq.com
RabbitMQ 最初起源于金融系统,用于在分布式系统中存储转发消息,在易用性、扩展性、高可用性等方面表现不俗。具体特点包括:
-
可靠性(Reliability)
RabbitMQ 使用一些机制来保证可靠性,如持久化、传输确认、发布确认。 -
灵活的路由(Flexible Routing)
在消息进入队列之前,通过 Exchange 来路由消息的。对于典型的路由功能,RabbitMQ 已经提供了一些内置的 Exchange 来实现。针对更复杂的路由功能,可以将多个 Exchange 绑定在一起,也通过插件机制实现自己的 Exchange 。 -
消息集群(Clustering)
多个 RabbitMQ 服务器可以组成一个集群,形成一个逻辑 Broker 。 -
高可用(Highly Available Queues)
队列可以在集群中的机器上进行镜像,使得在部分节点出问题的情况下队列仍然可用。 -
多种协议(Multi-protocol)
RabbitMQ 支持多种消息队列协议,比如 STOMP、MQTT 等等。 -
多语言客户端(Many Clients)
RabbitMQ 几乎支持所有常用语言,比如 Java、.NET、Ruby 等等。 -
管理界面(Management UI)
RabbitMQ 提供了一个易用的用户界面,使得用户可以监控和管理消息 Broker 的许多方面。 -
跟踪机制(Tracing)
如果消息异常,RabbitMQ 提供了消息跟踪机制,使用者可以找出发生了什么。 -
插件机制(Plugin System)
RabbitMQ 提供了许多插件,来从多方面进行扩展,也可以编写自己的插件。
系统架构
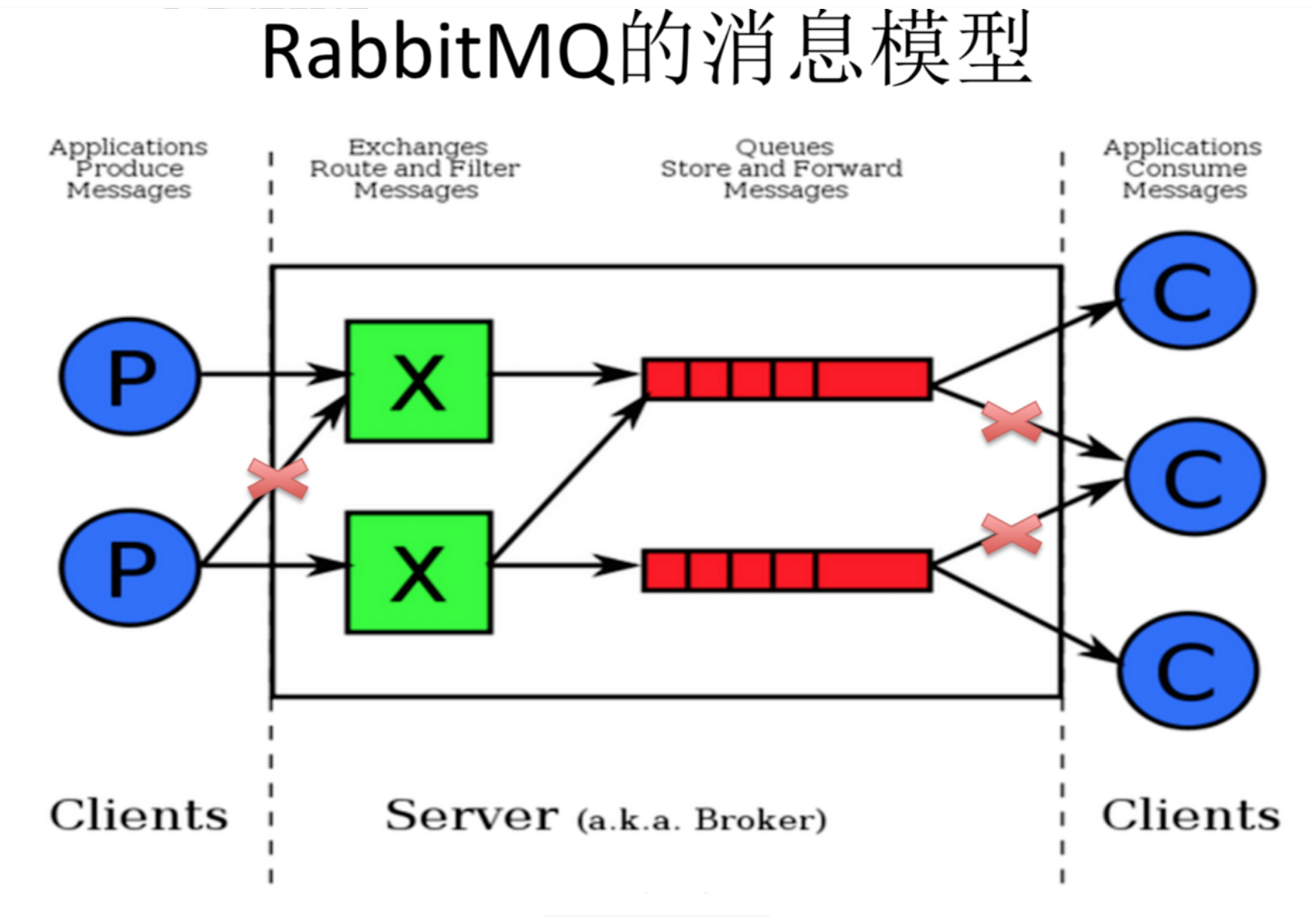
- 左侧 P 代表 生产者,也就是往 RabbitMQ 发消息的程序。
- 中间即是 RabbitMQ,其中包括了 交换机 和 队列。
- 右侧 C 代表 消费者,也就是往 RabbitMQ 拿消息的程序。
其中比较重要的概念,分别为:虚拟主机,交换机,和绑定。
- 虚拟主机vhost:一个虚拟主机持有一组交换机、队列和绑定。为什么需要多个虚拟主机呢?很简单,RabbitMQ当中,用户只能在虚拟主机的粒度进行权限控制。 因此,如果需要禁止A组访问B组的交换机/队列/绑定,必须为A和B分别创建一个虚拟主机。每一个RabbitMQ服务器都有一个默认的虚拟主机“/”。
- 交换机Exchange:Exchange 用于转发消息,但是它不会做存储 ,如果没有 Queue bind 到 Exchange 的话,它会直接丢弃掉 Producer 发送过来的消息。
- 这里有一个比较重要的概念:路由键 。消息到交换机的时候,交互机会转发到对应的队列中,那么究竟转发到哪个队列,就要根据该路由键。
- 绑定Binding:也就是交换机需要和队列相绑定,这其中如上图所示,是多对多的关系。
还有几个概念是上述图中没有标明的,那就是Connection(连接),Channel(通道,频道)。
Connection: 就是一个TCP的连接。Producer和Consumer都是通过TCP连接到RabbitMQ Server的。以后我们可以看到,程序的起始处就是建立这个TCP连接。
Channels: 虚拟连接。它建立在上述的TCP连接中。数据流动都是在Channel中进行的。也就是说,一般情况是程序起始建立TCP连接,第二步就是建立这个Channel。
Broker: 简单来说就是消息队列服务器实体。
Queue: 消息队列载体,每个消息都会被投入到一个或多个队列。
Routing Key: 路由关键字,exchange根据这个关键字进行消息投递。
producer: 消息生产者,就是投递消息的程序。
consumer: 消息消费者,就是接受消息的程序。
由Exchange,Queue,RoutingKey三个才能决定一个从Exchange到Queue的唯一的线路。
Exchange 类型
Exchange分发消息时根据类型的不同分发策略有区别,主要三种类型:direct、fanout、topic
direct
direct类型的Exchange路由规则也很简单,它会把消息路由到那些binding key与routing key完全匹配的Queue中。

以上图的配置为例,我们以routingKey=”error”发送消息到Exchange,则消息会路由到Queue1(amqp.gen-S9b…,这是由RabbitMQ自动生成的Queue名称)和Queue2(amqp.gen-Agl…);如果我们以routingKey=”info”或routingKey=”warning”来发送消息,则消息只会路由到Queue2。如果我们以其他routingKey发送消息,则消息不会路由到这两个Queue中。
fanout
fanout类型的Exchange路由规则非常简单,它会把所有发送到该Exchange的消息路由到所有与它绑定的Queue中。

上图中,生产者(P)发送到Exchange(X)的所有消息都会路由到图中的两个Queue,并最终被两个消费者(C1与C2)消费。
topic
前面讲到direct类型的Exchange路由规则是完全匹配binding key与routing key,但这种严格的匹配方式在很多情况下不能满足实际业务需求。topic类型的Exchange在匹配规则上进行了扩展,它与direct类型的Exchage相似,也是将消息路由到binding key与routing key相匹配的Queue中,但这里的匹配规则有些不同,它约定:
routing key为一个句点号“.”分隔的字符串(我们将被句点号“. ”分隔开的每一段独立的字符串称为一个单词),如“stock.usd.nyse”、“nyse.vmw”、“quick.orange.rabbit” binding key与routing key一样也是句点号“. ”分隔的字符串
binding key中可以存在两种特殊字符“*”与“#”,用于做模糊匹配,其中“*”用于匹配一个单词,“#”用于匹配多个单词(可以是零个)

以上图中的配置为例,routingKey=”quick.orange.rabbit”的消息会同时路由到Q1与Q2,routingKey=”lazy.orange.fox”的消息会路由到Q1,routingKey=”lazy.brown.fox”的消息会路由到Q2,routingKey=”lazy.pink.rabbit”的消息会路由到Q2(只会投递给Q2一次,虽然这个routingKey与Q2的两个bindingKey都匹配);routingKey=”quick.brown.fox”、routingKey=”orange”、routingKey=”quick.orange.male.rabbit”的消息将会被丢弃,因为它们没有匹配任何bindingKey。
RPC
MQ本身是基于异步的消息处理,前面的示例中所有的生产者(P)将消息发送到RabbitMQ后不会知道消费者(C)处理成功或者失败(甚至连有没有消费者来处理这条消息都不知道)。
但实际的应用场景中,我们很可能需要一些同步处理,需要同步等待服务端将我的消息处理完成后再进行下一步处理。这相当于RPC(Remote Procedure Call,远程过程调用)。
在RabbitMQ中也支持RPC。

RabbitMQ中实现RPC的机制是:
- 客户端发送请求(消息)时,在消息的属性(MessageProperties,在AMQP协议中定义了14中properties,这些属性会随着消息一起发送)中设置两个值replyTo(一个Queue名称,用于告诉服务器处理完成后将通知我的消息发送到这个Queue中)和correlationId(此次请求的标识号,服务器处理完成后需要将此属性返还,客户端将根据这个id了解哪条请求被成功执行了或执行失败)
- 服务器端收到消息并处理
- 服务器端处理完消息后,将生成一条应答消息到replyTo指定的Queue,同时带上correlationId属性
- 客户端之前已订阅replyTo指定的Queue,从中收到服务器的应答消息后,根据其中的correlationId属性分析哪条请求被执行了,根据执行结果进行后续业务处理
Callback queue 回调队列
一个客户端向服务器发送请求,服务器端处理请求后,将其处理结果保存在一个存储体中。而客户端为了获得处理结果,那么客户在向服务器发送请求时,同时发送一个回调队列地址reply_to。
Correlation id 关联标识
一个客户端可能会发送多个请求给服务器,当服务器处理完后,客户端无法辨别在回调队列中的响应具体和那个请求时对应的。为了处理这种情况,客户端在发送每个请求时,同时会附带一个独有correlation_id属性,这样客户端在回调队列中根据correlation_id字段的值就可以分辨此响应属于哪个请求。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号