

对于当今的数据集来说,动不动就上G的大小,市面的软件大多不支持,所以需要自己写一个。
常见的txt文本行形式存储的时候也不过是行数多些而已,可以考虑只观测部分行的方式,基于这个思路可以搞一个大数据的浏览工具。
贴图:
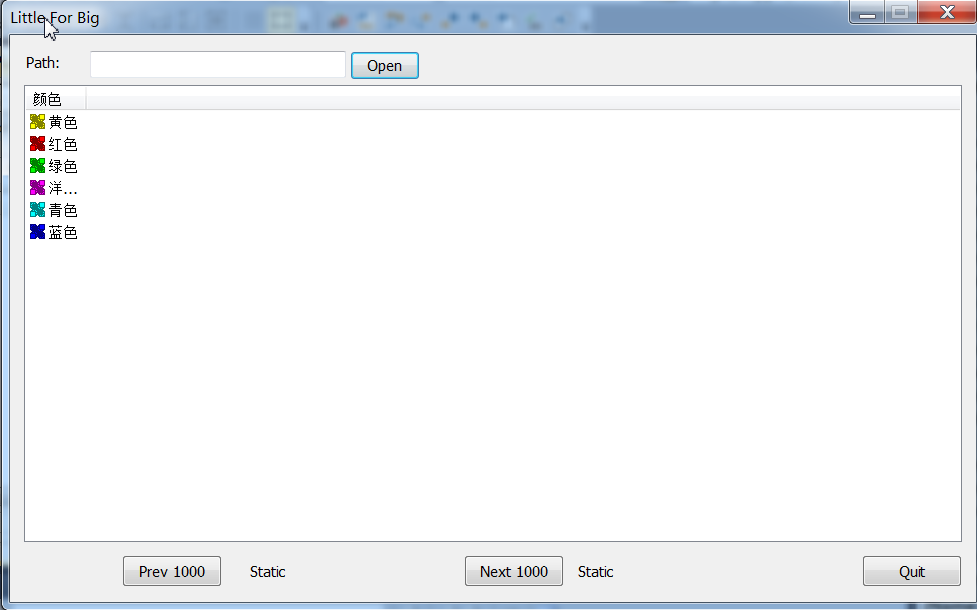
内部的原理很简单,就是先记录下文件的每行的末尾坐标,然后存起来,到需要的时候直接seek到位置然后读取。
这样的思路在z400的工作站10G文件几秒就打开了。
VC做的10G在win7 64位系统下几乎卡死,还未研究。但是1G左右的文件差不多几秒也能打开。
我用的list,如果换成editor的话几乎可以实现文本的处理。
git源码:https://github.com/watergao/A-Little-in-Big-text-file
喜欢的打赏我吧:
支付宝

微信


 浙公网安备 33010602011771号
浙公网安备 33010602011771号