
Redis知识点总结
1. redis内存淘汰机制
redis 提供6种数据淘汰策略:
volatile-lru:从已设置过期时间的数据集(server.db[i].expires)中挑选最近最少使用的数据淘汰
volatile-ttl:从已设置过期时间的数据集(server.db[i].expires)中挑选将要过期的数据淘汰
volatile-random:从已设置过期时间的数据集(server.db[i].expires)中任意选择数据淘汰
allkeys-lru:当内存不足以容纳新写入数据时,在键空间中,移除最近最少使用的key(这个是最常用的)
allkeys-random:从数据集(server.db[i].dict)中任意选择数据淘汰
no-eviction:禁止驱逐数据,也就是说当内存不足以容纳新写入数据时,新写入操作会报错。这个应该没人使用吧!
2. redis持久化机制
redis提供2种持久化机制:
快照(RDB):Redis可以通过创建快照来获得存储在内存里面的数据在某个时间点上的副本
优点:
RDB是一个紧凑压缩的二进制文件,非常适合用于备份,全量复制等场景,Redis加载RDB回复数据远远快于AOF方式
缺点:
RDB方式数据没办法做到实时持久化/秒级持久化,因为bgsave每次运行都要执行fork操作创建子进程,属于重量级操作,频繁执行成本过高
针对RDB不适合实时持久化的问题,Redis提供了AOF持久化方式来解决
只追加文件(AOF):以独立日志的方式记录每次写命令,重启时再重新执行AOF文件中命令达到回复数据的目的。AOF的主要作用是解决了数据持久化的实时性
流程:
所有的写入命令会追加到aof_buf(缓冲区)中
AOF缓冲区根据对应的策略向硬盘做同步操作
随着AOF文件越来越大,需要定期对AOF文件进行重写,达到压缩的目的
当redis服务重启时,可以加载AOF文件进行数据恢复
本质上一个是保存数据一个是保存指令,类似于mysql主从复制的基于行复制和基于指令复制
3. 常见的删除策略
定时删除:创建一个定时器,定时删除。CPU不友好,内存友好
惰性删除:只有在查询的时候查到key过期了才删除。cpu友好,内存不友好
定期删除:每过一段时间,就会检查删除掉过期的key。折中操作
4. 缓存穿透&缓存雪崩&缓存击穿
缓存穿透:
查询一个一定不存在的数据,由于缓存是不命中时被动写的,并且处于容错考虑,如果从存储层查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到存储层去查询,失去了缓存的意义
解决办法:
布隆过滤器:将所有可能存在的数据哈希到一个足够大的bitmap中,一个一定不存在的数据会被这个bitmap拦截掉,从而避免了对底层存储系统的查询压力
如果一个查询返回的数据为空,我们仍然把这个空结果进行缓存,单它的过期时间会很短,最长不超过五分钟
缓存雪崩:
设置缓存时采用了相同的过期时间,导致缓存在某一时刻同时失效,请求全部转发到db,db瞬间压力过重雪崩
解决办法:
事前:尽量保证整个 redis 集群的高可用性,发现机器宕机尽快补上。选择合适的内存淘汰策略,比如在原有的失效时间上增加一个随机值
事中:本地ehcache缓存 + hystrix限流&降级,避免MySQL崩掉
事后:利用 redis 持久化机制保存的数据尽快恢复缓存
缓存击穿:
和缓存雪崩类似,但是这里针对的是某一个热点key缓存,如果缓存在某个时间点过期时,正好有对这个key的大量并发请求,那可能会把db压垮
解决方法:
使用setnx加锁
提前使用互斥锁
不过期
资源隔离组件hystrix
5. redis架构模式
redis提供4中架构模式
单机版:
优点:简单
缺点:内存容量有限,处理能力有限,无法高可用
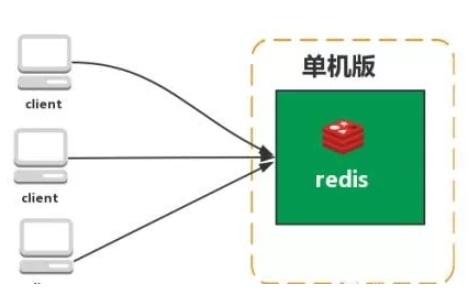
主从复制:类似于kafka中的leader和slave
优点:master/slave数据相同,降低master读压力
缺点:没有降低master写压力,无法高可用
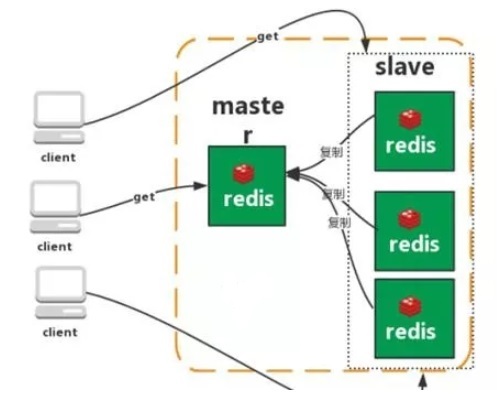
哨兵模式:
Redis sentinel 是一个分布式系统中监控 redis 主从服务器,并在主服务器下线时自动进行故障转移。其中三个特性:
监控(Monitoring): Sentinel 会不断地检查你的主服务器和从服务器是否运作正常。
提醒(Notification): 当被监控的某个 Redis 服务器出现问题时, Sentinel 可以通过 API 向管理员或者其他应用程序发送通知。
自动故障迁移(Automatic failover): 当一个主服务器不能正常工作时, Sentinel 会开始一次自动故障迁移操作。
本质上类似于集成了zookeeper的kafka,通过哨兵充当中间管理人身份
哨兵如何判断节点故障:每隔1秒发送ping命令做心跳检测,没有有效回复即做失败判定,对于主节点,多个哨兵都认为有问题才判定失败
优点:保证高可用,监控各个节点,自动故障迁移。
缺点:没有降低 master 写压力
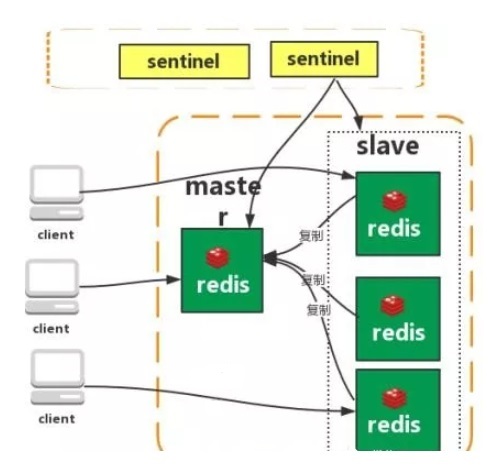
集群模式:
Redis-Cluster采用无中心结构,每个节点保存数据和整个集群状态,每个节点都和其他所有节点连接。
Redis哈希槽的概念
一个 Redis Cluster包含16384(0~16383)个哈希槽,存储在Redis Cluster中的所有键都会被映射到这些slot中,集群中的每个键都属于这16384个哈希槽中的一个,集群使用公式slot=CRC16(key)/16384来计算key属于哪个槽,其中CRC16(key)语句用于计算key的CRC16 校验和。一个hash slot中会有很多key和value,insert数据时会根据上面的简单算法来决定你的key应该存在哪个分区,每个分区里有很多key。本质上和hashmap的底层数据结构类似
优点:
无中心架构(不存在哪个节点影响性能瓶颈);
数据按照slot存储分布在多个节点,节点间数据共享,可动态调整数据分布;
redis集群的键空间被分割为16384个hash槽(slot),集群的最大节点数量也是16384个;
高可用性,部分节点不可用时,集群仍可用。通过增加 Slave 做备份数据副本;
实现故障自动 failover,节点之间通过 gossip 协议交换状态信息,用投票机制完成 Slave到 Master 的角色提升
缺点:
资源隔离性较差,容易出现相互影响的情况;
数据通过异步复制,不保证数据的强一致性,这意味着在实际中集群在特定条件下可能会丢失写操作
5. redis加锁机制
INCR:
加锁思路:key不存在,那么key的值会先被初始化为0,然后再执行INCR操作进行加1;其他用户在执行INCR操作进行加1时,如果返回的数大于1,说明这个锁正在被使用当中
SETNX:
加锁思路:如果key不存在,将key设置为value;如果key已存在,则SETNX不做任何动作
SET:
加锁思路:与SETNX不同的是默认设置了key的过期时间,也就是锁的过期时间,避免了上面两种锁需要手动设置锁过期时间导致违背原子性的问题
加锁的问题:
redis发现锁失败后使用循环请求去获取锁,循环请求的过程中加入睡眠功能,等待几毫秒再执行循环,避免出现抢锁
6. redis实现消息队列
使用list这种双端链表实现,lpop,lpush,rpop,rpush,还可以使用publish和subscribe实现消息的发布与订阅

 浙公网安备 33010602011771号
浙公网安备 33010602011771号