

1. kafka特性:
-
高吞吐量、低延迟:kafka每秒可以处理几十万条消息,它的延迟最低只有几毫秒,每个topic可以分多个partition, consumer group 对partition进行consume操作。
-
可扩展性:kafka集群支持热扩展
-
持久性、可靠性:消息被持久化到本地磁盘,并且支持数据备份防止数据丢失
-
容错性:允许集群中节点失败(若副本数量为n,则允许n-1个节点失败)
-
高并发:支持数千个客户端同时读写
2. kafka性能
1、磁盘IO
在磁盘IO方能,kafka主要通过顺序写和缓存机制提高性能
2、网络IO
在网络IO方面,kafka主要通过缓存机制和消息压缩机制提高性能
3. kafka文件存储机制
消息发送时都被发送到一个topic,其本质就是一个目录,而topic由是由一些Partition组成,Partition是一个Queue的结构,每个Partition中的消息都是有序的,生产的消息被不断追加到Partition上,其中的每一个消息都被赋予了一个唯一的offset值。
每一个分区中都会有一个或者多个段(segment)结构。一个段结构包含两种类型的文件:.index后缀的索引文件和.log后缀的数据文件。前一个index文件记录了消息在整个topic中的序号以及消息在log文件中的偏移位置(offset),通过这两个信息,kafka可以再后一个log文件中找到这条消息的真实内容
Kafka集群会保存所有的消息,不管消息有没有被消费;我们可以设定消息的过期时间,只有过期的数据才会被自动清除以释放磁盘空间。比如我们设置消息过期时间为2天,那么这2天内的所有消息都会被保存到集群中,数据只有超过了两天才会被清除。
Kafka只维护在Partition中的offset值,因为这个offsite标识着这个partition的message消费到哪条了。Consumer每消费一个消息,offset就会加1。其实消息的状态完全是由Consumer控制的,Consumer可以跟踪和重设这个offset值,这样的话Consumer就可以读取任意位置的消息。
4. kafka高性能的原因
1、单位数量相同的消息将分发到存在于多个Broker服务节点上的多个Partition中,并利用每个Broker服务节点的计算资源进行独立处理。
2、在磁盘上进行的文件操作只有采用顺序读和顺序写才能做到高效的磁盘IO性能,kafka对索引index文件始终保证顺序读写:当在磁盘上记录一条消息时,始终在文件的末尾进行操作;当在磁盘上读取一条消息时,通过index顺序查找到消息的offset位置,再进行消息读取。后一种消息读取操作下,如果index文件过大,Kafka的磁盘操作就会耗费掉相当的时间。所以Kafak需要对index文件和log文件进行分段。
3、kafka对linux操作系统下Page Cache技术的应用,才是其高性能的最大保证。
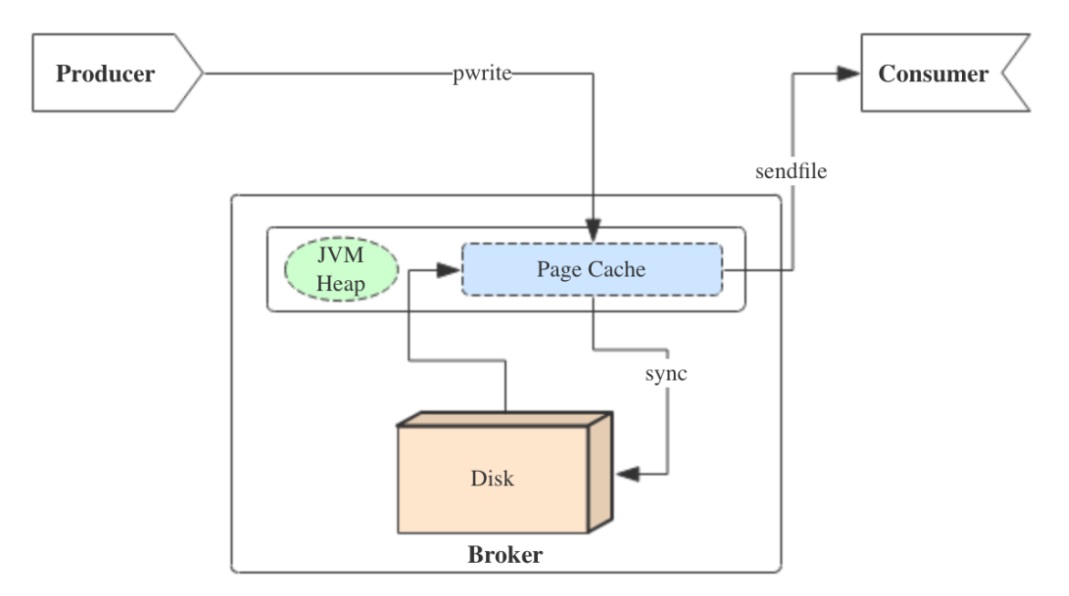
producer生产消息时,会使用pwrite()系统调用【对应到Java NIO中是FileChannel.write() API】按偏移量写入数据,并且都会先写入page cache里。consumer消费消息时,会使用sendfile()系统调用【对应FileChannel.transferTo() API】,零拷贝地将数据从page cache传输到broker的Socket buffer,再通过网络传输。
图中没有画出来的还有leader与follower之间的同步,这与consumer是同理的:只要follower处在ISR中,就也能够通过零拷贝机制将数据从leader所在的broker page cache传输到follower所在的broker。
同时,page cache中的数据会随着内核中flusher线程的调度以及对sync()/fsync()的调用写回到磁盘,就算进程崩溃,也不用担心数据丢失。另外,如果consumer要消费的消息不在page cache里,才会去磁盘读取,并且会顺便预读出一些相邻的块放入page cache,以方便下一次读取。
由此我们可以得出重要的结论:如果Kafka producer的生产速率与consumer的消费速率相差不大,那么就能几乎只靠对broker page cache的读写完成整个生产-消费过程,磁盘访问非常少。并且Kafka持久化消息到各个topic的partition文件时,是只追加的顺序写,充分利用了磁盘顺序访问快的特性,效率高。
