【机器学习】数值分析01——绪论及误差分析
数值分析——绪论及误差分析
全文目录
数值分析的作用及其学习工具使用
数值分析方法是在解决科学研究和实践中遇到的各种奇怪复杂问题时,构建一种简单的数学物理模型来进行研究,最终得到我们需要的解。例如对于一个无法求得原函数的积分,我们可以用足够多的曲边梯形面积和进行求解。或者对于一个高次方程,我们也无法直接求得它的零点,那么这个时候,我们建立对应的数值分析模型时非常有必要的。
数值分析常用工具
对于本系列课程,建议读者对包括但不限于以下三种语言有一定的了解:C#、Matlab、Python ,本系列文章将用以下三种语言对其中涉及的算法进行Coding和解析。同时推荐安装以下库及应用程序:
应用程序:
- Visual Studio Code:当今最强大的支持拓展的编辑器,适合各种语言的开发工作。强力建议安装。
- Visual Studio 2022:宇宙第一IDE,微软出品的最强开发套件,配合C#如虎添翼事半功倍,建议使用C#的同学们安装
- Pycharm:JB公司出品的Python IDE,适合于大型Python项目开发使用。如果只是写写小算法小程序,此软件过于庞大,吃性能。
- Matlab:科学计算、建模第一开发工具,其中各种库可以有效的支撑你的需求,非常强大的一款工具软件,但是软件收费且非专业人员许多功能用不上
- Octave:你可以理解为一个开源免费的Matlab,没有了商业用途的各种工具库,只留下了最基础的一些科学计算和Matlab语言,在科学计算方面非常不错,吴恩达在机器学习教程中也使用这款工具,推荐使用。
- GeoGebra全家桶:科学计算、2、3D绘图最好用的工具之一。
库及SDK:
- .NET 6(C#):微软最新的开发框架,性能速度以及语法已经达到了前几名的位置,单论语言执行速度效率已经在前几名,支持U3d,web、ML等各种开发。单独拎出来是因为微软旗下库版本众多,这里推荐最新的.NET6
- MathNet.Numerics:C#.NET上最强大的科学计算工具,在nuget中可以进行下载。
- NPlot:C#.NET上一个优秀的绘图工具库
- Numpy:python上一个优秀的科学计算库
- Matplotlib:python上用于函数、数据等绘图的工具库。
数值分析的具体实例(多项式简化求值)
对于一个复杂多项式的计算,我们往往需要花费巨大的人力逐次计算,比如求:
最最直接的方法就是进行计算
我们计算了10次的乘法,同时还计算了四次加减法运算,这实在是太复杂了,那么我们试着取优化一下,倘若我将\(a=\frac{1}{2}\times\frac{1}{2}\)记录一下,那么式子就可以变成
这样,我们包含计算a在内大概需要计算7次乘法,四次加减法运算。很明显我们减少了不少的计算步骤,那么继续试试是否又其他的做法?
通过这个变换(称为霍纳方法、嵌套乘法),我们只需要进行4次乘法和4次加法,计算的时候从内往外计算。一般而言,任意一个n次多项式都可以通过n次乘法和n次加法求得。
这个例子展示了科学计算的主题特征,简单计算的速度总是比复杂的计算快得多,同一个问题当我们采取不同的方法时可能可以有效的提升我们的效率和速度。这也是为什么数值分析(计算方法)显得尤为重要的原因。
计算机数值误差产生机理
计算机的数值存储方式
这里我们直接对计算机数值存储方式进行讲解而不作过多的展开。详细的内容可以参考我《.NET Guide》—— 基本数据类型及其存储方式 #5.2
计算机误差产生原因
数值分析是一门建立在计算机计算的基础上的学科,我们需要详细解释一下在计算机中,是什么导致了误差的出现。首先抛出一个问题,为什么计算机会存在精度问题?或者换句话说,任何非0、5结尾的小数在计算机中都不是一个精确值?
上述问题是一个非常有建设意义的问题,我们知道计算机时使用二进制进行数据的运算和存储的,那么根据二进制的计算法则,浮点数的二进制表示应当是\(\sum i*2^{-n},i \in \{0,1 \},n \in N^+\),根据这个式子不难看出对于二进制而言,并不能用有限的位数表示所有的浮点数。举个浅显的例子,例如十进制数\((\frac{1}{3})_{10}=0.\dot{3}\),无论我们怎么写都无法用有限的十进制位数写出准确的数值,只能通过近似的值进行描述,当我们采用三进制数,我们就能用有限小数 \((0.1)_3\) 进行描述。
因此对于二进制存储信息的计算机来说,数据的存储位数总是有限度的,我们不可能准确的表述每一个浮点数,于是,对于那些无法表示的数值,我们只能采取近似的手段进行拟合,误差就出现了。
误差
误差限与精度
首先我们给出这样一个定义,设\(x^*\)是某量的一个精确值,而 \(x\) 是此量的近似值,那么我们将 \(e = |x^*-x|\) 定义为值的 绝对误差,也就是误差。
不过在工程实践中,我们往往是不知道实际值\(x^*\)的,同时误差e也并不是已知量,我们只能设法在计算过程中采取某些手段,对误差进行一个估计。这个估计是一个区间范围,那么给出下面条件
若上式成立,我们则给出了\(x-\epsilon\leq x^*\leq x+\epsilon,x\in[x-\epsilon,x+\epsilon]\),于是我们称\(\epsilon\)为绝对误差限,又称为精度。它描绘了我们近似值与绝对值的相似程度,给出了误差的最大值。
通常,在同一范围或数量级内,误差限越小,也就是我们的数据越精确。当逾越这条线的时候,绝对误差限就显得心有余而力不足了。例如数字的近似值是9999,精确值是10000,它的误差限是1;若近似值是9,精确值是10,误差限也是1,很明显前者的拟合效果要好于后者。我们称前者是99.99%的吻合度,而后者的吻合度是90%。
上述式子很明显是因为比较的数量级不同而导致的,为了更好的描述,我们采用相对误差及相对误差限进行描述。相对误差定义为\(e_r=\frac{e}{x^*}=1-\frac{x}{x^*}\),根据量纲的计算法则,很明显相对误差区别于绝对误差的地方就在于相对误差是一个无量纲常量,通常也采用百分比作为表示。
与绝对误差一样,我们通常无法直接得出\(e_r\)的值,精确值往往也是未知的,同样的,我们使用相对误差限去给出一个区间估计。
这里我们可以给出任意数值的误差估计方法,如下式所示:
设有精确值\(x^*_1\),估计值\(x_1\),构造函数\(y=f(x),f(x_1)\)在\(x^*_1\)处Taylor展开得:
同时我们知道估计值和精确值的差即为误差\(e(x_1)\),且为无穷小量,那么上述式子化为
因此我们得出了误差的一个分析式,\((\frac{df}{dx_1})^*\)则称为绝对误差增长因子,表示误差经过运算\(f\)后变化的速率或倍数。
同时给出相对误差估计推导:
同样的,\(\frac{x_1^*}{f(x_1^*)}(\frac{df}{dx_1})^*\)则称为相对误差增长因子,表示误差经过运算\(f\)后变化的速率或倍数。
更一般的,给出任意函数的误差分析式:
模型误差
模型误差往往是建模过程中,忽略了那些影响细微的次要因素,最终在要求精度的情况下,出现了模型的误差。例如我们初高中学过的公式\(G=mg\),我们往往会有一句g取9.8N/kg,数学模型描述就为\(G=9.8m\),这里的g就是一个近似值,而我们知道重力加速度在不同的地方是会受到高度、海拔、地壳密度分布等等因素影响的,由于我们的重力加速度取了近似值,因此这个模型也是一个近似模型,而这里必然会产生误差,由于近似模型导致的误差我们就称为模型误差。
观测误差
观测误差往往是因为数据的来源受到主观因素的影响,假设我有一个绝对精准的弹簧式重力计,我们用它去测量物体重量的时候必须通过肉眼去读取仪器上的刻度数字,在这里我们因读数不准产生的误差就是观测误差。或者同上面的质量和重量的方程中,假设我们知道了G,通过计算得出了质量m,它与实际质量的差值就是观测误差。
截断误差
截断误差在计算机和生活中是一个常见误差。我们在进行大笔金钱交易的时候往往会讨价还价,最常见的还价就是“抹零头”,284元的饭钱讲价成280元,这就是一种截断。计算机因数据溢出而直接抹去首尾的数据时,也是一种截断,只是这种更多视为一种错误,而不是误差。
如果你对高等数学了解一些,那必然知道泰勒展开式是一个无穷级数,我们常常采用带拉格朗日或皮亚诺余项去描述误差,这个误差也是因为我们只取了有限的项而导致了数据的不精确。
例如下列展开:
因为我们只采用前n项作为计算,实际的误差(拉格朗日余项)就为
舍入误差
这是平时可能用到最多的一种误差形式了,四舍五入就是一种常见的舍入误差。计算机默认就是使用舍入误差去处理误差的。只不过计算机由于是二进制的原因,因此它只要是1就向上进1。采用舍入误差有一个特性就是你的误差绝对不会超过区间的一半。
有效数字缺失
有效数字是指数字位数里第一个非零值到最后的数字,例如0.001就具有一位有效数字。那么我们为什么需要去讨论有效数字这个问题呢?事实上,仔细想想,如果说我现在需要计算\(\sqrt{9.01}-3\),\(\sqrt{9.01}\)大约是3.0016662,假定我们的计算机只能存储三位有效数字,上述式子的差异却需要在第四位有效数字的时候才取到,那么\(\sqrt{9.01}-3=3-3=0.00\),我们最终得到的数据连一位有效数字都没有,而实际上我们需要存储的是\(1.67\times 10^{-3}\)即可获得更为精确的数字,同样是三位有效数字,0的答案就是我们的有效数字缺失。那么如何去避免这个问题呢?
我们如果做下列变换
这样就避免了在减法过程使得我们早早的丢失了有效数据。
再举一个例子,有下列式子
如果高等数学底子好的朋友们应该一眼就能看出这两个式子是相等的,结果应当是0.5,但是计算机会老老实实的去计算这些数据,先从分子的减法开始计算,如果x足够的小,那么\(1-cosx\)最终会因为有效数字过于靠后以至于计算机无法保存到有效数字从而使得\(E_1=0\)。
如下图所示,当x越发减小,对整个式子结果的改变就越大:
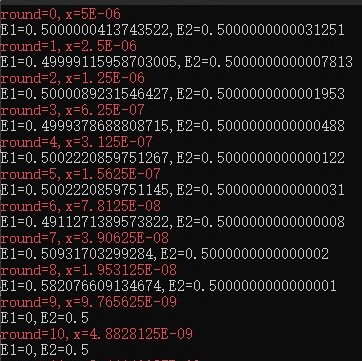
这不是我们希望的结果,于是我们进行恒等变形:
通过这个变换,巧妙的利用了消去可能导致有效位数缺失的减法操作。
误差的产生和避免
我们的模型误差、观测误差属于不可抗力导致的误差,我们只能尽可能去优化模型和提高精度,但是往往付出了极大代价却收获甚微。我们对于误差的避免更多是采取减少在计算过程中产生的截断和舍入误差,尽可能避免有效数字的缺失导致的数据丢失。
一般而言,这些误差产生通常是因为:
- 两个相近的数字进行减法导致了有效数字的缺失,例如刚才讲到的第一个例子,因此实际计算时我们应当避免过于接近的数字进行减法,如果无法避免,则通过平方和一类的公式进行升阶扩大处理。
- 临界数(接近数据存储最大值)先做了加法,例如如果计算机只能存储3位数字,若不考虑符号位,以无符号数进行计算,最大值应当是7,那么7+2-3=6很显然是能在计算机存储下的,但计算机按着顺序计算时会先计算7+2=9=0b1001,最高位将会被丢弃,最终却得到了7+2=1的答案,显然是不对的,如果调整成先做减法则不会有这个问题。
- 过于繁杂的计算步骤,当计算步骤过多的时候,每一次运算都会产生舍入误差,这些误差将会在后续不断的传播累计,最后影响结果。同时如果计算不稳定(经常出现舍入操作,例如每一次计算的尾数都大于4),也会导致误差过大。我们需要设计好计算简单,同时每一次舍入操作得到的舍和入都是相同结果(例如每次尾数都小于5)
- 极限状态下的误差扩大化,例如我们的估计值和真实值很接近,或者运算中有趋近于0的数字产生,往往就会导致有效位数的缺失,我们最好采用泰勒展开、和差化积,利用三角、对指数函数的运算法则对其进行处理,从而避免误差的继续累计。
- 绝对值过小的数字做除数,事实上误差有如下公式成立:\(e(\frac{x}{y})\approx\frac{ye_x+xe_y}{y^2}\),若y过小,则会导致误差成平方倍扩大。因此我们也需要避免这种情况,最简便的方法就是通过放大分子分母,使得其分母可以尽可能多的保留下有效数字
误差的传播
和的绝对误差即误差的和
由此可以看出,我们传入的数据在进行加法运算时,误差大约和各个近似值的代数和是差不多的。因此我们可以得出结论:初始输入的近似值对于求和运算的影响时并不大的。
差的绝对误差相对而言较难估计,但是差的相对误差与我们的初始值关系是非常大的,就好比我们上文提到的,过于接近的数相减的时候,往往容易导致有效数字的严重缺失。因此我们尽可能要避免差的运算。
从这个式子也能看出如果输入的初始近似值过于接近,一旦做差,分母就会急剧的趋近0,使得整体的误差变大。
算数中积的误差公式为:
事实上我们换个角度,积在某种意义上就是一个累加的过程,因此误差的累计传播规律也类似于和的规律,积的相对误差积累是一个累加过程,但是对于绝对误差而言,积很受大数的乘法影响,例如估计值是0.9,精确值是1,当他们各自乘一百倍后,相对误差因为只有一项,故没有什么变化,但是绝对误差却从0.1放大到了10。所以如果在需要避免绝对误差的情况之下,我们要尽可能的去避免大数去直接乘一个近似值。
商的误差就可以类比减法的误差,直接给出我们的证明推论:
不难看出,商的相对误差就是被除数和除数的相对误差的差,乘法在某种意义上也是除法,因此乘法中存在的问题在除法中也必定存在。乘法如果乘数过大会导致绝对误差过大,那么乘数取倒数就成为了除法,也就是说除法中要尽可能避免过小的数作为除数,这样才能最大的保护数据的准确性。
乘方、开方带来的误差和乘除法类似,这里不再过多赘述,直接给出我们的公式:
综上所述,我们知晓了初始数据误差对于计算结果的影响,而前文提到的误差增长因子能很好的反映处计算结果和原始数据误差变化的情况及计算结果对于初始值的敏感程度。如果初始近似值变动而计算结果变化很小的时候,说明该计算是良态的。如果初始的近似值轻微扰动,但是结果变化极大的时候,则说明我们的计算是敏感的,病态的。
算法设计的稳定性与病态条件
病态问题
我们刚分析完了我们的算法的敏感、病态的理论,这里我以一个例子来展示病态函数是如何影响我们的结果的。
我们直接利用前文提到的泰勒展开误差估计公式计算,接下去分析:
这就说明当初始输入了一个相对误差在1%的初始值的时候,经过函数计算,函数值的相对误差会放大99倍。
在我们初始的扰动只有0.9的情况,经过计算后的值却扩大到了10倍,按着相对误差的计算,也就是10%的扰动带来了1000%的函数变化。因此我们称这个函数早x=99附近是一个病态的函数。
因此我们在分析问题的时候,要额外注意问题是否是良态的。
计算的稳定性
计算的稳定性主要体现在当处理同一问题的时候,选用不同的计算方法或算法,往往对结果有着显著的区别。例如下面这个例子:
这个题目大家一看,惊呼:真是简单,直接将\(a_0\)套进递推式,直接就能解出来了。但结果恰恰出乎你的预料。如果你利用题中给出的公式进行计算,会得出一个极端奇怪的答案,往往你还不自知错误所在。我们尝试分析一下。
得出错误结论的原因很显然是因为\(a_0=0.1823\)发生了舍入误差,如果我们取六位有效数字,我们舍去了0.000022左右的大小,误差会随着计算式不断累积,如下
我们可以发现,误差是呈现指数函数的形式进行增长的,我们可以算算到了第十项误差已经达到了原始误差的9,765,625倍,大概我们多算了214的样子,这显然是无法接受的答案,并且当你写出算法没有第十项的参考数值的时候,你会无法意识到自己的错误所在,因为你的算法逻辑完全正确,但你的错误恰恰发生在了最难注意到的误差之上。
那我们如何取解决这个问题呢?很显然对于这个递推而言,误差永远呈现指数函数形式进行变化。如果我们期许指数函数缩小,那么我们能不能试着把指数函数的底数换成一个绝对值小于1的数字呢?
答案显然是可以的,如果我们将原有递推式更改为以下这种情况:
我只是反过来求解前一项,我们从后往前进行计算,那么,误差分析式就变成了
很显然我们的误差项\(\epsilon\)已经是一次比一次更小,呈现指数函数的缩小状态,这样得出的值很明显是要精确于前者的,最终的误差也不会超过0.000022。
通过这个例子我们可以发现,实际上对于同一个问题,采用的算法、分析的思路不同,带来的结果却天差地别。对于第一种解法,我们称为不稳定的算法,它会导致我们失真。第二种解法,我们的误差逐步在缩小,说明我们的算法是稳定的算法。
刚刚介绍的是因为算法不同的误差扩大化问题,还有另一种情况就是因为犯了我们之前说过的大数吃小数的问题。如题
通过因式分解我们很容易知道答案是\(x_1=10^9,x_2=1\),但当我们利用求根公式\(\frac{-b\pm\sqrt{\Delta}}{2a}\),我们能解出第一个更大解,但是当我们解第二个解的时候,由于\(-b-\sqrt{\Delta}\)在我们计算机的字长不够时,会产生极为严重的截断误差,最终会得出一个等于0的解,很显然时不对的,这里犯了我们之前提到的大数和小数加减法的时候,往往会导致一些数据的丢失,因此我们转变思路,如果利用韦达定理:
不仅极为有效的减少了计算量,也不会再次出现刚才提到的问题了。
因此对于保持算法稳定性的原则就是,我们既要防止数字由于数量级相差过大,从而导致较小的数字丧失其计算作用;也要防止数字过于接近,使得有效数字缺失,产生不可避免的误差。更需要注意的就是我们的算法中产生的误差,应当是越来越小且收敛的。
练习题
-
已知对数\(lga\)的绝对误差限为\(0.5\times 10^{-n}\),求相对误差限
-
如何使得\((\frac{1-cosx}{x},x>>1),ln(30-\sqrt{30^2-1})\)计算更精确
-
设\(f(x)=x^2-\frac{log_{2}x}{x},x=4.1\pm0.05\),若以\(u=f(4.1)\)作为近似值,请问u能有几位有效数字
-
用电表测得一个电阻两端电压和电流为\(V=220\pm 2V,I=10\pm 0.1A,求阻值R和相对、绝对误差。\)(PS:欧姆定律\(R=\frac{V}{I}\))
-
找到方程\(x^2+9^{12}x=3\)的根
Reference
《数值分析》(原书第二版) —— Timothy Sauer
《数值计算方法》(清华大学出版社) —— 吕同富等
About Me
作 者:WarrenRyan
出 处:https://www.cnblogs.com/WarrenRyan/
本文对应视频:BiliBili【机器学习】数值分析之绪论及误差分析
关于作者:热爱数学、热爱机器学习,喜欢弹钢琴的不知名小菜鸡。
版权声明:本文版权归作者所有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接。若需商用,则必须联系作者获得授权。
特此声明:所有评论和私信都会在第一时间回复。也欢迎园子的大大们指正错误,共同进步。或者直接私信我
声援博主:如果您觉得文章对您有帮助,可以点击文章右下角【推荐】一下。您的鼓励是作者坚持原创和持续写作的最大动力!
博主一些其他平台:
微信公众号:寤言不寐
QQ群:236996657
BiBili——小陈的学习记录
Github——StevenEco
BiBili——记录学习的小陈(计算机考研纪实)
掘金——小陈的学习记录
知乎——小陈的学习记录
联系方式
社交媒体联系二维码:

本文来自博客园,作者:WarrenRyan,转载请注明原文链接:https://www.cnblogs.com/WarrenRyan/p/15866688.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号