第四章 - C++ 函数
第四章 - C++ 函数
4.1 函数初识
4.1.1 函数的作用
模块化程序设计的思想
将复杂问题,分解为若干稍简单部分
每个部分对应一个模块
模块化程序设计的原则
按照子结构/功能之间联系疏密程度进行分解
每个模块完成一定的子问题求解
按照“自顶向下、逐步求精”的原则进行
函数是能完成某一独立功能的子程序,即程序模块,是 C++ 程序的构成基础 —程序由一个个函数组成
函数也是类的方法的实现手段。
函数的作用:实现系统中按功能分解的各小任务,实现类对象的方法。
为什么要用函数?
分而治之,便于分工编写,分阶段调试
软件重用,避免代码重复,可重用已有的函数来构造新的程序
易于查错和修改,便于程序调试和验证正确性
方便扩展,便于对代码进行维护和扩展
……
在C和C++中,函数是程序的重要组成部分,每个程序都必须且只有一个主函数(main函数)。通常使用不同函数,用来实现各种功能。解题的过程就是调用和执行一系列函数的过程。“函数”这个名词是从英文function翻译过来的,其实function的原意是“功能”。所以,一个函数就是一个功能。
由于一个程序的功能过多,如果把代码都写在main函数里,这样就会造成一些无用的资源浪费等。这时候为了便于规划、组织编程和调试,一般把一个大的程序划分为若干个程序模块(程序文件),每个模块实现一部分功能。在程序进行编译时,以程序文件模块为编译单位,即分别通过编译后,才进行连接,把各模块的目标文件以及系统文件连接在一起形成可执行文件。
【实例-1】 : 输出以下结果:
****************************************
Welcome to C++!
****************************************
这个可以使用三个cout语句来完成,但是两排星号是一样的,就可以把两排星号定义在一个函数里。
#include <iostream>
using namespace std;
// 定义空类型的 printstar 函数,代表本函数没有返回值
void printstar(){
cout<<"****************************************"<<endl;
}
// 定义 print_message 函数,括号内的void表示没有参数,调用时不需要给参数,也可以省写
void print_message(void){
cout<<"\t Welcome to C++!"<<endl;
}
int main() {
// 调用 printstar函数
printstar();
// 调用 print_message 函数
print_message();
// 调用 printstar函数
printstar();
return 0;
}
程序的执行是从main函数开始的,调用其他函数后流程回到main函数,在main函数中结束整个程序运行。mian函数是有系统调用的。
所有的函数在定义时是互相独立的。一个函数并不从属另一个函数,函数不能嵌套定义,也就是不能在定义一个函数的过程又定义另一个函数,也不能把函数定义部分写到主函数内。
main函数可以调用其他函数,函数之间也可以互相调用,但是不能调用main函数。
【实例-2】 : 使用函数实现求两个值的最大值。
#include <iostream>
using namespace std;
int main() {
int max(int x ,int y);
int a,b,c;
cout<<"请输入两个数(中间使用空格分隔):"<<endl;
cin>>a>>b;
// a = 11;
// b = 12;
c = max(a,b);
cout<<"最大值为:"<<c<<endl;
return 0;
}
int max(int x ,int y){
int z;
if (x>y)z=x;
else z = y;
return z;
}
在上面程序中我们定义了一个max函数,但是max定义在主函数后的,这个时候我们就需要在主函数内对调用函数进行声明。如何声明?只需要将函数定义的首部写在函数内即可 int max(int x ,int y); ,且应声明在调用函数之前,通常我们会把声明放在最前面,或者将函数写在前面。
同时在这里定义了一个int类型的函数,代表定义的函数是有类型的,函数执行完之后会有一个返回值抛出,且这个返回值为int类型,所以在调用的时候就需要有一个变量接收这个返回值。
在定义main函数中,在括号内含有两个变量,这两个变量叫做参数,同样调用的时候也给了两个值,这里涉及到函数调用、实际参数与形式参数,后面章节会介绍。
4.1.2 函数的分类
从使用的角度上来说我们可以把函数分为:系统函数(库函数,内置函数)、自定义函数。
在C++中,由编译系统提供的函数,例如:三角函数sin,求平方根函数sqrt等。这些都是系统的内置函数,当我们需要使用的时候只需要在文件开头加上相应的头文件即可。
从函数的形式,可分为有参函数与无参函数。
- 有参函数
在调用函数时,需要给出参数。在主函数和被调用函数之间有数据传递。也就是说,主调函数将数据传给被调用函数使用。被调用函数可以带回函数值供主调函数使用,也可以不带回返回值(此时的函数类型为void)。
- 无参数函数
调用函数时不必给出参数。在调用无参函数时,主调函数并不将数值传给被调用函数,一般用来执行一组固定的操作。
4.2 定义函数
4.2.1 函数的定义形式
1. 定义无参函数
定义无参函数的一般形式:
类型名 函数名([void])
{
声明部分
执行语句
}
定义函数时,需要使用类型标识符指定函数的类型,级函数带回来的值的类型。
【实例 - 3】
#include <iostream>
using namespace std;
// 定义一个欢迎语句
void print_hello(void){
cout<<"欢迎您的到来!"<<endl;
}
int main() {
// 调用函数
print_hello();
return 0;
}
在C语言中,定义无参数函数时函数首部的括号内可以不写void,C++中同样保留了这一写法,但是为了程序的可读性,建议不省略void。
2. 定义有参函数
定义有参数函数一般形式:
类型名 函数名(形式参数表列)
{
声明部分
执行语句
}
以上面max函数为例:
int max(int x,int y){ // 函数首部,函数值为整型,有两个整型形参
int z; // 函数体中的声明部分
z = x > y ? x : y; // 将x和y中的大者的值赋给整型变量z
return (z); // 将z的值作为函数值返回调用点
}
在定义有参函数时,在括号内定义形式参数,在调用时,调用者需给出实际参数。
3. 函数声明
函数声明会告诉编译器函数名称及如何调用函数。函数的实际主体可以单独定义。
函数声明包括以下几个部分:
return_type function_name( parameter list );
// 返回类型(return_type):一个函数可以返回一个值。return_type 是函数返回的值的数据类型。有些函数执行所需的操作而不返回值,在这种情况下,return_type 是关键字 void。
// 函数名称(function_name):这是函数的实际名称。函数名和参数列表一起构成了函数签名。
// 参数(parameter list):参数就像是占位符。当函数被调用时,您向参数传递一个值,这个值被称为实际参数。参数列表包括函数参数的类型、顺序、数量。参数是可选的,也就是说,函数可能不包含参数。
针对上面定义的函数 max(),以下是函数声明:
int max(int num1, int num2);
在函数声明中,参数的名称并不重要,只有参数的类型是必需的,因此下面也是有效的声明:
int max(int, int);
当您在一个源文件中定义函数且在另一个文件中调用函数时,函数声明是必需的。在这种情况下,您应该在调用函数的文件顶部声明函数。
4.2.2 函数的参数
在调用函数是,大多数情况下,函数是带参数的。主调函数和被调函数之间有数据传递关系。
在定义函数时函数名后面括号中的变量名称为 形式参数(formal parameter,简称形参),在主调函数中调用一个函数时,函数名后面括号中的参数成为 实际参数 (actual parameter,简称实参)。
【实例 - 5】 : 还是以求两个整数中的大者,用函数调用实现。
#include <iostream>
using namespace std;
// 定义有参数函数max
int max(int x ,int y){
int z;
z = x>y?x:y;
return (z);
}
int main() {
int a,b,c;
cout<<"请输入两个数(中间使用空格分隔):"<<endl;
cin>>a>>b;
c = max(a,b); // 调用max函数,给定实参为a,b。函数值赋给c
cout<<"最大值为:"<<c<<endl;
return 0;
}
上面 int max(int x ,int y) 定义了一个max函数和指定了两个形参x,y及其类型。在主函数内 c = max(a,b); 调用函数语句,调用时后面给了a,b两个实参。
a和b是main函数中定义的变量,而x和y是函数max中的形式参数。在调用函数,使两个函数中的数据发生联系。
函数在调用会按照形式参数的顺序,将实际参数传给形式参数。最后执行结束遇到return,会将z返回给调用者。
形参与实参说明:
- 在定义函数时指定的形参,在未出现函数调用时,他们并不占内存中的存储单元,因此称它们为形式参数或虚拟参数,表示他们并不是实际存在的数据,只有在发生函数调用时,形参才被分配内存单元,以便接收从实参传来的数据。在调用结束后,形参所占的内存单元也被释放。
- 实参可以是常量、变量或表达式(表达式要求有确定的值)。以便调用时实参的值赋给形参。
- 在定义函数时,必须在函数首部指定形参的类型。
- 实参与形参的类型应相同或赋值兼容。如上面求最大值的例子,实参与形参都是为正向。如果不一样实参是float(如:3.5)传到形参中,形参(int)会进行转换(转换成3),这里要注意字符型与整型可以互相通用
- 实参变量对形参变量的数据传递是“值传递”,是单向传递,只由实参传给形参,不能由形参传给实参。
在调用函数时,编译系统临时会给形参分配存储单元,实参单元与形参单元是不同的单元。
在调用结束后,形参单元被释放,实参单元仍保留并维持原值。因此,在执行一个被调用函数时,形参的值如果发生改变,并不会改变主调函数中实参的值。
4.2.3 函数的返回值
函数最后的 return 是干嘛的?
如果我们想通过函数的调用使主调函数得到一个确定的函数这,这就是函数的返回值,需要使用return来实现。
【实例 - 6】
计算 1+2+3+....+n 的和。
#include <iostream>
using namespace std;
int sum(int n){
int s;
for(int i = 1;i<= n;++i){
s += i;
}
return s;
}
int main(){
int n, s = 0;
cout << "输入一个正整数: ";
cin >> n;
s = sum(n);
cout << "Sum = " << s;
return 0;
}
在上面例子中通过 return 实现了返回求和的值,并将值返回给了调用者。如果需要从函数中获取一个或多个值,那么函数体内必须包含 return 语句。如果不需要返回值可以没有return语句。
注意点:
-
return语句后的括号是可有可没有的,
return s;或return (s);。 -
return语句的返回内容也可以是一个表达式,例如:
return x>y?x:y;。简单的函数可以使用一个语句解决。 -
这里要特备说明一下关于函数返回值的类型,返回值的类型要与定义函数时,函数首部所指定的类型一致。如若出现返回值与定义的类型不一致,函数还是会以定义的类型为准,将返回值进行类型转换后返回。
4.3 函数的调用
4.3.1 函数的调用方式
所谓函数调用(Function Call),就是使用已经定义好的函数。函数调用的一般形式为:
functionName(param1, param2, param3 ...);
functionName 是函数名称,param1, param2, param3 ...是实参列表。实参可以是常数、变量、表达式等,多个实参用逗号,分隔。注意这里括号不可以省略。实参与形参的个数应相等,类型应匹配。实参与形参按照顺序对应,一对一传递数据。
函数表达式
函数出现在一个表达式中,这是要求函数待会一个确定的值以参加表达式的运算。c = 2*max(a,b);
函数作为参数
一个函数可以作为参进行传递,这个时候是将函数的返回值作为实参。
m = max(a,sqrt(b))
4.3.2 函数的声明与函数原型
1、 函数声明
在一个函数中调用另一函数(即被调用函数)需要具备哪些条件呢?
-
首先被调用的函数必须是已经存在的函数(是库函数或者是用户自己定义的闭数)。但光有这一条件还不够。
-
如果使用库函数,还应该在本文件开头用
#include指令将有关头文件"包含"到本文件中来。
例如,前而已经用到过`include < cmath> ,其中cmath是个头文件。在cmath文件中包括了数学库函数所用到的-些宏定义信息和对函数的声明。如果不包含cmath文件,就无法使用数学库中的函数。
- 如果使用自定义的函数,而该函数与调用它的函数(即主调函数)在同一个程序单位中,且位置在主调函数之后。则必须在调用此函数之前对被调用的函数作声明。
所谓函数声明( declaration),就是在函数尚未定义的情况下,事先将该函数的有关信息通知编译系统,以便使编译能正常进行。
【实例 - 7】 : 向计算机输人两个整数,用 一个函数求出两数之和。
inelude < iosream >
using namespace std;
int main(){
float add(float x,float y);//对add函数作声明
float a,b,c;
cout<<"please enter a,b:";
cin >>a>>b;
c = add(a,b);
cout<<"sum ="<<c<<endl;
return 0;
}
//定义add函数
float add(float x,float y){
float z;
z = x + y;
return z;
}
上述例题中第四行 float add(float x,float y); 就是对add函数的声明部分。
注意:函数的定义与函数声明不是同一回事。
定义是指对函数功能的确立。包括指定函数类型、函数名、形参及其类型、函数体等,它是一个完整的、独立的函数单位。
而声明的作用则是把函数的名字、函数类型以及形参的个数、类型和顺序(不包括函数体)通知编译系统,以便在对包含函数调用的语句进行编译时。从程序中可以看到对函数的声明与函数定义中的第1行(函数首部)基本上是相同的,可以简单地照写已定义的函数的首部,再加一个分号 ,就成了对函数的声明。
其实,在函数声明中也可以不写形参名,而只写形参的类型,如
float add( float,foat);
以上的函数声明称为函数原型( function prolotype)。使用函数原型是C和C++的一个重要特点。
它的作用主要是:根据函数原型在程序编译阶段对调用函数的合法性进行全面检查。
实例中main函数的位置在add函数的前面,而在进行编译时是从上到下逐行进行的,如果没有对函数的声明,当编译到包含丽数调用的语句 C=add(a,b); 时,编译系统不知道add是不是函数名,也无法判断实参(a和b)的类型和个数是否正确,因而无法进行正确性的检查。
只有在运行时才会发现实参与形参的类型或个数不一致,出现运行错误。
但是在运行阶段发现错误并重新调试程序是比较麻烦的,工作量也较大。应当在编译阶段尽可能多地发现错误,随之纠正错误。现在我们在函数调用之前用函数原型对函数作了声明,因此编译系统记下了所需调用的函数的有关信息,在对“c= dd(a,b);"进行编译时就“有章可循"了。编译系统根据函数的原型对函数的调用的合法性进行全面的检查。如果发现与丽数原型不匹配的函数调用就报告编译出错。它属于语法错误。用户根据屏幕显示的出错信息很容易发现和纠正错误。
函数原型的一一般形式为
-
函数类型 函数名(参数类型1,参数类型2……);
-
函数类型 函数名(参数类型1,参数名1, 参数类型2,参数2……);
第(1)种形式是基本的形式。为了便于阅读程序,也允许在函数原型中加上参数名,就成了第(2)种形式。但编译系统并不检在参数名。因此参数名是什么都无所谓。上面程序中的声明也可以写成
float add( floal a, float b);//参数名不用x.y,而用a,b效果完全相同。
应当保证函数原型与函数首部写法上的一致,即函数类型、函数名、参数个数、参数类型和参数顺序必须相同。在函数调用时函数名实参类型和实参个数应与函数原型一致。
说明:
-
前面已说明:如果被调用函数的定义出现在主调函数之前,可以不必加以声明。
因为编译系统已经事先知道了已定义的函数类型,会根据函教首部提供的信息对函数的调用作正确性检查。有的读者自然会想:编程序时把函数定义都写在调用之前,把main函数写在最后,就可以不必对函数作声明了,不是省事吗?
但是这会对程序员提出较高的要求,在比较复杂的程序中,他必须周密考虑和正确安排各函数的顺序,稍有疏息,就会出错。而且,当一个程序包含许多个函数时,阅读程序的人要十分耐心地逐一仔细阅读各个被调用函数,直到最后才看到主函数,这样的程序可读性较差。
有经验的程序员人员一般都把main函教写在最前面,这样对整个程序的结构和作用一日了然,然后再具体了解各函数的细节。此外,用函数原型来声明函教,还能减少编写程序时可能出现的错误。由于函数声明的位置与函数调用语句的位置比较近,因此在写程序时便于就近参照函数原型来书写函数,不易出错。所以应该养成对所有用到的函数作声明的习惯。这是保证程序正确性和可读性的重要环节。 -
函数声明的位置可以在调用函数所在的函数中,也可以在函数之外。如果函数声明放在函数外部,在所有函数定义之前(这就是对函数的外部声明),则在各个主调函数中不必对所有调用的函数再做什么对所调用的画教再作声明。
例如:
char letter(char,char); // 对函数的外部声明,作用域是整个文件
float f(float,float); // 对函数的外部声明,作用域是整个文件
int i(float,float); // 对函数的外部声明,作用域是整个文件
int main(){
··· // 在main函数中不必对它所调用的函数做出声明
}
// 定义letter函数
char letter(char,char){
···
}
// 定义f函数
float f(float,float){
···
}
// 定义i函数
int i(float,float){
···
}
如果一个函数被多个函数所调用,用这种方法比较好,不必在每个主调函数中重复声明。
4.4 函数的嵌套调用与递归
4.4.1 函数的嵌套调用
在C++中不允许对函数做嵌套定义,在一个函数中不能不能定义另外一个函数。
但是可以嵌套调用函数,意思是在一个函数中可以调用另外一个函数。要注意,调用函数之前,需要对每一个调用的函数做出声明(除非定义在前,调用在后)。
【实例 - 8】 :定义一个函数max_4来实现从4个数中找出最大值。
#include <iostream>
using namespace std;
int main() {
int max_4(int a,int b,int c,int d); // max_4声明
int a,b,c,d,max;
printf("请输入4个数字:");
scanf("%d %d %d %d",&a,&b,&c,&d);
max = max_4(a,b,c,d); // 调用max_4,并传4个值
printf("最大值是:%d",max);
return 0;
}
// 定义max_4函数
int max_4(int a,int b,int c,int d){
int max(int x,int y); // 声明max函数
int m;
m = max(a,b); // 从a,b中得到最大值
m = max(m,c); // 从a,b,c中找到最大值
m = max(m,d); // 从a,b,c,d中找到最大值
return m;
}
// 定义max函数
int max(int x,int y){
// 求两个值中的最大值
if (x>y){
return x;
}
else{
return y;
}
}
上面例题中,在函数max_4中调用了max函数,这就是嵌套调用。嵌套调用中先声明,这里在主函数中没有调用max函数,所以在主函数中不需要声明max函数,同时也可以在全局进行声明。
max_4函数执行过程是这样的:第l次调用max函数得到的函数值是a和b中的大者,把它赋给变量m,第2次调用max(m,c)得到m和c的大者,也就是a,b,c中的最大数,再把它赋给变量m。第3次调用max(m,d)得到m和d的大者,也就是a,b,c,d中的最大数,再把它赋给变量m。这是-种递推方法,先求出两个数的大者;再以此为基础求出3个数的大者;再以此为基础求出4个数的大者。m的值一次一次次地变化,直到实现最终要求。
4.4.2 函数的递归调用
在调用一个函数的过程中又出现直接或间接地调用该函数本身,成为函数的递归调用。
int f(int x){
int y,z;
z = f(y);
return (2*z);
}
递归的本质就是自己调用自己,包含递归调用的函数成为递归函数。
给大家讲给故事:从前有座山,山里有座庙,庙里有个老和尚在给小和尚讲故事,讲的什么呢?从前有座山,山里有座庙,庙里有个老和尚在给小和尚讲故事,讲的什么呢?从前有座山,山里有座庙,庙里有个老和尚在给小和尚讲故事,讲的什么呢?...
当然这里并不只是调用一次,每次调用都会进入到下一层,这样就形成了无终止的自身调用。为了规避这种无终止程序的出现我们就需要使用if语句来控制,限制次数,有终止的递归调用。
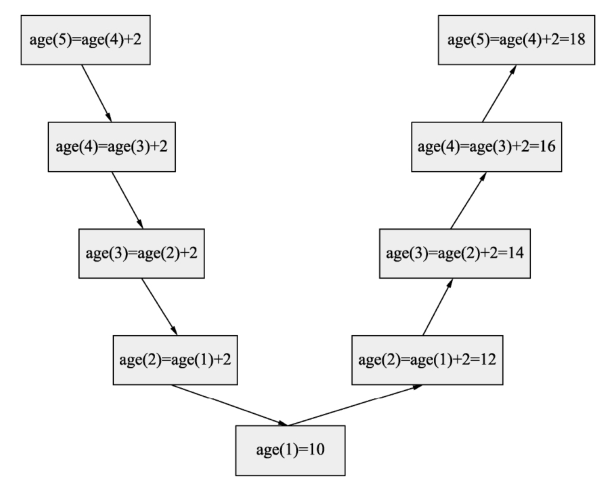
【实例 - 9】:求年龄
有5个人坐在一起,问第5个人多少岁?他说比第4个人大两岁。问第4个人岁数,他说比第三个人大两岁,问第3个人,又说比第2个人大两岁。问第2个人,说比第1个人大两岁,问第1个人,他说是10岁。请问第5个人多大?
age(5) = age(4) + 2
age(4) = age(3) + 2
age(3) = age(2) + 2
age(2) = age(1) + 2
age(1) = 10
// 所以这里可以得到
age(n) = 10 // n = 1
age(n) = age(n -1) + 2 // n > 1
#include<iostream>
using namespace std;
int age(int n); // 声明age函数
//主函数
int main(){
cout<<age(5)<<endl;
return 0;
}
// 定义求年龄的递归函数
int age(int n){
int c; // 定义c作为存放年龄的变量
if (n==1){ // 当n++1时,年龄为10
c = 10;
}else{
c = age(n-1) + 2; // 否则,此人年龄是前一个人年龄+2
}
return c; // 返回年龄值待会主函数
}

【实例 - 10】 用递归求阶乘 n!.
求n! ,1×2×3×4×5 ··· n。
n! = 1 // n = 0, 1
n! = n * (n - 1)! // n>1
#include <iostream>
using namespace std;
long fac(int);
int main(){
int n;
long y;
cout<<"请输入一个大于0的数:";
cin>>n;
y = fac(n);
cout<<n<<"!="<<y<<endl;
return 0;
}
long fac(int n){
long f;
if (n<0){
cout<<"错误"<<endl;
f = -1;
}else if(n == 0 || n == 1){
f = 1;
}else{
f = fac(n - 1)*n;
}
return f;
}
递归是一种经典的算法,许多问题既可以用非递归方法来解决,也可以用递归方法来解决。
在实现递归时,在时间和空间上的开销比较大,但符合人们的思路,程序容易理解。写递归的时候要考虑好递归的公式与递归结束条件(边界条件)。
4.5 内置函数
调用函数时需要一定的时间和空间开销;
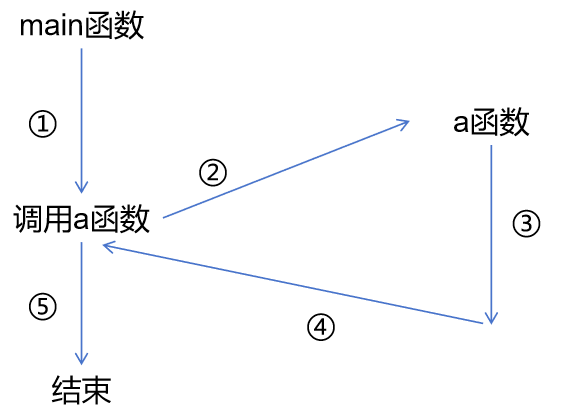
1、程序先执行函数调用之前的语句;
2、流程的控制转移到被调用函数的入口处,同时进行参数传递;
3、执行被调用函数中函数体的语句;
4、流程返回调用函数的下一条指令处,将函数返回值带回;
5、接着执行主调函数中未执行的语句。
这样就要求在转去被调函数之前,要记下当时执行的指令的地址,还要“保护现场”(记下当时有关的信息),以便在函数调用之后继续执行。在函数调用之后,流程返回到先前记下的地址处,并且根据记下的信息“恢复现场”,然后继续执行。
这些都要花费一定时间。如果有的函数需要频繁使用,则所用的时间会很长,从而降低程序的执行效率。有些使用程序对效率是有要求的,要求系统的相应时间短。这就希望尽量缩短时间的开销。
C++提供一种高效率的方法,即在编译时即在所调用函数的代码直接嵌入到主函数中,而不是将流程转出去。这样嵌入到主函数中的函数成为 内置函数(inline function),又称内嵌函数。或者内联函数。
指定内置函数的方法很简单,只需要在函数首行的左端加上一个关键字inline即可。
函数指定为内置函数。
#include <iostream>
using namespace std;
// 声明内置函数,注意左端有inline
inline int max(int,int,int);
int main(){
int i=10,j=20,k=30,m;
m = max(i,j,k);
cout <<"max="<<m<<endl;
return 0;
}
//定义max为内置函数
inline int max(int a,int b,int c) {
if (b > a)a = b;
if (c > a)a = c;
return c;
}
由于在定义函数时指定它为内置函数,因此编译系统在遇到函数调用“max(i,j,k)”时,就用max函数体的代码代替“max(i,k,j)”,同时将实参代替形参。这样程序第6行替换成了max函数中的程序。
注意:可以在声明函数和定义函数时同时写inline,也可以只在函数声明时加inline,而定义函数时不加inline。只要在调用该函数之前把inline的信息告知编译系统,编译系统就会在处理函数调用时按内置函数处理。
使用内置函数可以节省运行时间,但增加了目标程序的长度。假设要调用10次max函数,则在编译时先后10次将max的代码复制并插人main函数,这就增加了目标文件中main函数的长度。因此只将规模很小( 一般为5个语句以下)而使用频繁的函数(如定时采集数据的函数)声明为内置函数。在函数规模很小的情况下,函数调用的时间开销可能相当于甚至超过执行函数本身的时间,把它定义为内置函数,可大大减少程序运行时间。
内置函数中不能包括复杂的控制语句,如循环语句和switch语句。
应当说明:对函数作inline 声明,只是程序设计者对编译系统提出的一个建议,也就是说它是建议性的,而不是指令性的。并非一经指定为inline ,编译系统就必须这样做。编译系统会根据具体情况决定是否这样做。例如:对前面提到的包含循环语句和switch语句的函数或一个递归函数是无法进行代码置换的,又如一个1000行的函数,也不大可能在调用点展开。此时编译系统就会忽略inline声明,而按普通函数处理。
归纳起来,只有那些规模较小而又被频繁调用的简单函数,才适合于声明为inline函数。
4.6 函数的重载与模板
4.6.1 函数的重载
在编程时,一般是一个函数对应一种功能。但有时我们要实现的是同一类的功能,只是有些细节不同。例如:希望从3个数中找出其中的最大数,而每次求最大数时数据的类型不同,可能是3个整数3个双精度数或3个长整数。程序设计者会分别设计出3个不同名的函数,其函数原型为
int maxl(int a,intb, intc);//求3个整数中的最大数
double max2( double a,double b, doublec); //求3个双精度数中的最大数
long max3( long a, long b, long c);//求3个长整数中的最大数
以上3个函数的函数体是相同的。程序要根据不同的数据类型调用不同名的函数。如果在一个程序中这类情况较多,对程序编写者来说,要分别编写出功能相同而名字不同的函数,这是很不方便的。有人自然会想:能否不用3个函数名而用一个统一的函数名呢?
C++允许用同一函数名定义多个函数,而这些函数的参数个数和参数类型可以不相同。这就是函数的 重载(functionoverloading)。即对一个函数名重新赋予它新的含义,使一个函数名可以多用。所谓重载,其实就是“一物多用”。 以后可以看到,不仅函数可以重载,运算符也可以重载,例如,运算符“<<”和“>>”既可以作为位移运算符,又可以作为输出流中的插入运算符和输人流中的提取运算符。
求3个数中最大的数(分别考虑整数、双精度数、长整数的情况),用函数重载方法。
#include <iostream>
using namespace std;
int main() {
// 函数声明
int max(int a, int b, int c);
double max(double a, double b, double c);
long max(long a, long b, long c);
// 整数
int i1, i2, i3, i;
cin >> i1 >> i2 >> i3;
i = max(i1, i2, i3);
cout << "i_max=" << i << endl;
// 双精度数
double d1, d2, d3, d;
cin >> d1 >> d2 >> d3;
d = max(d1, d2, d3);
cout << "d_max=" << d << endl;
// 长整数
long l1, l2, l3, l;
cin >> l1 >> l2 >> l3;
l = max(l1, l2, l3);
cout << "l_max=" << l << endl;
}
// 定义求3个整数中的最大数的函数
int max(int a, int b, int c) {
if (b > a)a = b;
if (c > a)a = c;
return a;
}
// 定义求3个双精度数中的最大数的函数
double max(double a, double b, double c) {
if (b > a)a = b;
if (c > a)a = c;
return a;
}
// 定义求3个长整数中的最大数的函数
long max(long a, long b, long c) {
if (b > a)a = b;
if (c > a)a = c;
return a;
}
运行结果
185 -76 567
i_max=567
56.87 90.23 -3214.78
d_max=90.23
67854 -912456 673456
l_max=673456
用一个函数名 max 分别定义了3个函数。那么,在调用时怎样决定选哪个函数呢?
系统会根据调用函数时给出的信息去找与之匹配的函数。上面main函数3次调用max函数,而每次实参的类型不同,系统就根据实参的类型找到与之匹配的函数,然后调用该函数。
上面3个max函数的函数体是相同的,其实重载函数并不要求函数体相同,重载函数除了允许参数类型不同以外,还允许参数的个数不同。
编写一个程序,用来求两个整数或三个整数中的最大数。如果输入两个整数,程序就输出这两个整数中的最大值,如果输入3个整数,程序就输出这3个整数中的最大值。
#include<iostream>
using namespace std;
int main(){
int max(int a ,int b,int c); // 函数声明
int max(int a,int b); // 函数声明
int a = 8,b = -12,c = 27;
cout<<"max(a,b,c)="<<max(a,b,c)<<endl;
cout<<"max(a,b)="<<max(a,b)<<endl;
return 0;
}
int max(int a,int b,int c){
if (b>a)a=b;
if(c>a)a=c;
return a;
}
int max(int a,int b){
if (a>b) return a;
else return b;
}
运行结果
max(a,b,c)=27
max(a,b)=8
两次调用max函数的参数个数不同,系统就根据带参数的个数找到与之匹配的函数并调用它。
参数的个数和类型可以都不同。但不能只有函数的类型不同而参数的个数和类型相同,下面重载为不正确重载方式
int f(int);
long f(int);
void f(int);
在函数调用时都是统一形式,如 f(10)。编译系统无法判别应该调用哪一个函数。
重载函数的参数个数、参数类型或参数顺序三者中必须至少有一种不同。函数返回值类型可以相同也可以不同。
在使用重载函数时,同名函数的功能应当相同或相近,不要用一同函数名去实现完全不相干的功能(如求最大值和三角形面积),虽然程序也能运行,但可读性不好,易使人莫名其妙。
4.6.2 函数的模板
在函数重载中可以实现一个函数名多用,将实现相同的或类似的功能,函数用同一个函数名来定义。这样在调用同类函数时感到含义清楚,方法简单。但是在程序中仍要分开定义每个函数,在前面定义的max函数中函数体是完全相同的,只是形参的类型不同,也要分别定义。
那为了简化这个繁杂的过程,C++提供了函数模板(function template)。所谓函数模板,实际上是建立一个通用函数,其函数类型和形参类型不具体指定,用一个虚拟的类型来代表。 这个通用函数就成为函数模板。凡是函数体相同的函数都可以用这个模板来代替,不必定义多个函数,只需在模板中定义一次即可。在调用函数时系统会根据实参的类型来取代模板中的虚拟类型,从而实现不同函数的功能。
#include<iostream>
using namespace std;
template<typename T> // 模板声明,其中T为类型参数
// 定义一个通用函数,用T作为虚拟的类型名
T max(T a, T b, T c) {
if (b > a) a = b;
if (c > a)a = c;
return a;
}
int main() {
int i1 = 185, i2 = -76, i3 = 567, i;
double d1 = 56.87, d2 = 90.23, d3 = -3214.78, d;
long g1 = 67854, g2 = -912456, g3 = 673456, g;
i = max(i1, i2, i3); // 调用模板函数,此时T被int取代
d = max(d1, d2, d3); // 调用模板函数,此时T被double取代
g = max(g1, g2, g3); // 调用模板函数,此时T被long取代
cout << "i_max=" << i << endl;
cout << "d_max=" << d << endl;
cout << "g_max=" << g << endl;
return 0;
}
运行结果
i_max=567
d_max=90.23
g_max=673456
定义函数模板的一般形式为:
template <typename T> //通用函数定义
// 或者
template <class T> // 通用函数定义
template 含义是“模板”,尖括号中先写关键字 typename(或 class),后面跟一个类型参数 T ,这个类型参数实际上是一个虚拟的类型米鞥,表示模板中出现的T是一个类型名,但是现在并未指定它是哪一种具体的类型。在函数定义时用T来定义变量a,b,c,显然变量a,b,c的类型也是为确定的,要等到函数调用时根据实参的类型来确定T是什么类型。其实也可以不同T而用任何一个标识符,许多人习惯用T(T 是Type 的第一个字母),而且用大写与世纪的类型名相区别。
class和typename的作用相同个,都是表示“类型名”,二者可以相互转换。一起的C++程序都用class。typename 是不就钱才被加到标准C++中的,应为用class容易与C++中的类混淆,而用typename的含义很清楚,是类型名而不是类名。
4.7 变量的作用域
4.7.1 默认参数
在函数调用时形参从实参获取到值,因此实参的个数应与形参相同。当用同样的实参多次调用同一函数时,C++提供了简单的处理方法,给形参一个默认值,这样形参就不必一定要从实参取值了。
float area(float r = 6.5);
上述函数声明中,指定了r的默认值6.5,如果在调用次函数时,确认r的值为6.5,则可以不需要给出实参的值,如:area(); ,如果不想使用形参的默认值,可以通过实参另行赋值,如:area(7.5) 此时形参会重新取值。
这种方法比较灵活,可以简化程序,提高运行效率。
如果有多个形参,可以使每一个形参有一个默认值,也可以只对一部分形参指定默认值,另一部分形参不指定默认值。
如:求圆柱体体积的函数,形参h代表圆柱体的高,r为圆柱体半径,函数原型
float volume(float h,float r = 12.5); // 对形参r指定默认参数12.5
在调用时可以不给r的值,也可以给新的值,
volume(45.6) // 此时只对h做了赋值,r使用默认的值
volume(34.2,10.4) // 此时两个参数,是对h赋了值,同时也给r重新赋了值
实参与形参的结合是从左到右的顺序进行,第一个实参必然与第一个形参结合,第二个实参必然与第二个形参结合···
因此指定默认参数必须放在形参列表汇总的最右端(参数的最后),否则会报错。
void f1(float a,int b=0,int c,char d='a'); // 不正确
void f2(float a,int c,int b=0,char d='a'); // 正确
函数调用时,会将实参按顺序给形参,如果形参中设置了默认参数,当默认参数不在最后时,此时按照顺序位置上的实参会重新给形参赋值,这时形参很有可能会少一个。
f2(3.5,5,3,'x') // 形参的值全部从实参获得
f2(3.5,5,3) // 最后一个形参的值取默认值
f2(3.5,5) // 最后两个形参的值取默认值
在调用有默认参数的函数时,实参的个数可以与形参不同,实参未给定的,从形参的默认值获取。利用这一特性,可以使函数的使用更加灵活。
求2个数或3个数中的最大值。也可以不用重载函数,而改用带有默认的函数。
#include<bits/stdc++.h>
using namespace std;
int main(){
int max(int a,int b,int c=0);
int a,b,c;
cin>>a>>b>>c;
cout<<"max(a,b,c)="<<max(a,b,c)<<endl;
cout<<"max(a,b)="<<max(a,b)<<endl;
return 0;
}
int max(int a,int b,int c=0){
if(b>a)a=b;
if(c>a)a=c;
return a;
}
如果想从3个数中找大者,可以在调用时写成 max(a,b,c) 形式,如果只想从2个正整数中找大者,则可以写成 max(a,b) 形式,此时c自动去默认值0.
在使用带有默认参数的函数时要注意:
(1)如果函数的定义在函数调用之前,则应该在函数定义中给出默认值。如果函数的定义在函数调用之后,则在函数调用之前需要有函数声明,此时必须在函数声明中给出默认值,在函数定义时可以不给默认值。也就是说必须在函数调用之前将默认值的信息通知编译系统。由于编译从上到下逐行进行的,如果在函数调用之前未得到默认值信息,在编译到函数调用时,就会认为实参个数与形参个数不匹配而报错。
如果在声明函数时已对形参给出了默认值,而在定义函数时有队形参给出默认值,有的编译系统会给出“重复指定默认值”的报错信息,有的编译系统对此不报错,甚至允许在声明时和定义时给出的默认值不同,此时编译系统以先遇到的为准。由于函数声明在函数定义前,因此以声明时给出的默认值为准,而忽略定义函数给出的默认值。
#include<bits/stdc++.h>
using namespace std;
int main(){
int f(int a=234);
cout<<f()<<endl; // 此时调用会输出234
cout<<f(456)<<endl; // 此时会输出456
return 0;
}
int f(int a=123){
return a;
}
(2)一个函数不能既作为重载函数,又作为有莫人参数的函数。因为当调用函数时如果少些一个参数,系统无法判断是利用重载函数还是利用默认参数的函数,出现二义性,系统无法执行。
以上内置函数、函数的重载、函数模板、和有默认参数的函数在c语言中是没有的,是C++增加的。
4.7.2 局部变量
在一个程序中可以包括如果个源程序文件即文件模板,每个源程序文件又包含多个函数,在每个函数中以及在函数之外都可以定义变量。这样就会发生一个问题:在不同地方定义的变量是否都在程序的全部范围内有效?
每一个变量都有其有效的作用方位,这就是变量的作用域。在作用域意外是不能访问这些变量的。
在一个函数内部定义的变量是内部变量,它只能在本函数范围内有效,也就是说只要在本函数内才能使用它们,在函数意外是不能使用这些变量的。同样在复合语句中定义的变量只能在本复合语句范围内有效。这些内部变量称为 局部变量(local variable)
float f1(int a) { // 局部变量,可以在f1函数内使用
int b, c; // f1函数中的局部变量
}
char f2(int x, int y) {
int i, j;
}
int main() {
int m, n; // 在main函数里也是局部变量
{
int p, q; // 复合语句中只能在复合语句范围使用
}
return 0;
}
主函数main中定义的变量(m,n)也只能在主函数中有效,不会因为在主函数中定义而在整个文件或程序中有效。在主函数中也不能使用其他函数中定义的变量。
不同函数中可以使用同名的变量,它们代表不同的对象,互不干扰。例如:在函数中定义了变量b和c,如果在f2函数中也定义变量b和c,它们在不同的时间段中存在,在内存中站不同的单元,不会混淆。
可以在一个函数内的复合语句中定义变量,这些变量旨在本复合语句中有效,这种复合语句也称为分程序或程序块。
形式参数也是局部变量。f1函数中的形参a也只在f1函数中有效。其他函数不能调用。
在函数原型声明中出现的参数名,只在原型声明中的括号范围内有效,他并不是实际存在的变量,不能被引用,编译系统对函数声明中的变量名是忽略的,即是在调用函数时也没有为他们分配存储单元。
int max(int a,int b); // 函数声明中出现a,b
int max(int x,int y){ // 函数定义,形参是x,y
cout<<x<<y<<endl; // 合法,x,y在函数体中有效
cout<<a<<b<<endl; // 不合法,a,b在函数体中无效
}
4.7.3 全局变量
在函数内定义的变量是局部变量,而在函数之外定义的变量是外部变量,称为全局变量(global variable,也称全程变量)。全局变量的有效范围从定义变量的位置开始到本源文件结束。
#include<bits/stdc++.h>
using namespace std;
int p = 1,q = 6; // 全局变量p q 作用范围从这里到源文件最后
float f1(int a){
int b,c;
}
char c1,c2; // 全局变量c1,c2作用范围从这里到源文件最后
char f2(int x,int y){
int i,j;
}
int main() {
int m, n;
return 0;
}
p,q,c1,c2都是全局变量,但他们的作用范围不同,在main函数和f2函数中可以使用全局变量p,q,c1,c2,但是在函数f1中只能使用全局变量p,q,而不能使用c1,c2。
在一个函数中既可以使用本函数中定义的局部变量,也可以使用有效的全局变量。
说明:
(1)设全局变量的作用是增加了函数间数据联系的渠道。由于同一文件中的所有函数都能使用全局变量的值,因此如果在一个函数中改变了全局变量的值,就能影响到其他函数,使其他函数中引用的同名变量的值也同时改变,这相当于各个函数间有直接的传递通道。由于函数的调用只能带回一个返回值,因此有时可以利用全局变量增加函数间数据传递的渠道。如果在main函数中调用fl函数,而在执行fl函数过程中改变了全局变量a和b的值,则在调用结束后,在main函数中除了得到一个函数返回值外,还可以使用另外两个改变了值的全局变量。相当于向main函数传递了3个数据。
(2)建议不在必要时不要使用全局变量,因为:
① 全局变量在程序的全部执行过程中都占用存储单元,而不是仅在需要时才开辟单元。
② 它使函数的通用性降低了,因为在执行函数时要受到外部变量的影响。如果将一个函数移到另一个文件中,还要将有关的外部变量及其值一起移过去。但若该外部变量与其他文件的变量同名,就会出现问题,降低了程序的可靠性和通用性。在程序设计中,在划分模块时要求模块的内聚性强、与其他模块的耦合性弱。即模块的功能要单一(不要把许多互不相干的功能放到一个模块中),与其他模块的相互影响要尽量少,而用全局变量是不符合这个原则的。发的文宝代生发西玉面,
一般要求把程序中的函数做成一个封闭体,除了可以通过“实参--形参”的渠道与外界发生联系外,没有其他渠道。这样的程序移植性好,可读性强。
③ 使用全局变量过多,会降低程序的清晰性,人们往往难以清楚地判断出每个瞬时各个全局变量的值。在各个函数执行时都可能改变全局变量的值,程序容易出错。因此,要限制使用全局变量。
(3)如果在同一个源文件中,全局变量与局部变量同名,则在局部变量的作用范围内,全局变量被屏蔽,即它不起作用,此时可以使用局部变量。
变量的有效范围称为变量的作用域(scope)。归纳起来,变量有4种不同的作用域:文件作用域( file scope)、函数作用域( function scope)、块作用域( block scope )和函数原型作用域( function prototype scope)。文件作用域是全局的,其他三者是局部的。
除了变量之外,任何以标识符代表的实体(如函数数组、结构体、类等)都有作用域,概念与变量的作用域类似。
4.8 变量的存储类别
4.8.1 动态存储方式与静态存储方式
作用域是变量的一种属性,作用域是从空间的角度来分析,分为全局变量和局部变量。
变量还有另一个属性-存储期(storage duration,也称声明周期)。存储期是指变量在内存中的存在周期。这是从变量值存在的时间角度来分析的。存储期可以分为静态存储期(static storage duration)和动态存储期(dynamic storage duration)。这是由变量的静态存储方式和动态存储方式决定的。
所谓静态存储方式是指在程序运行期间,系统对变量分配固定的存储空间。而动态存储方式则是程序运行期间,系统对变量动态地分配存储空间。
先看一下内存中的供用户使用的存储空间的情况,存储空间可以分为3部分:程序区、静态存储区、动态存储区。
程序中所用的数据分别存放在静态存储区和动态存储区中。全局变量全部放在静态存储区中,在程序开始执行时给全局变量分配存储单元,程序执行完毕就释放这些空间。在程序执行过程中他们占据固定的存储单元,而不是动态地进行分配和释放。
在动态存储区中存放一下数据:
- 函数形式参数。在调用函数时给形参分配存储空间;
- 函数中定义的变量(未加static声明的局部变量);
- 函数调用时的现场保护和返回地址等。
对以上这些数据,在函数调用开始时分配动态存储空间,函数调用结束时释放这些空间。在程序执行过程中,这种分配和释放是动态的。如果在一个程序中两次调用同一函数,则要进行两次分配和释放,而两次分配给此函数中局部变量的存储空间地址可能是不同的。
如果在一个程序中包含如干个函数,每个函数中的局部变量的存储期并不等于整个程序的执行周期,它只是整个程序执行周期的一部分。根据函数调用的情况,系统对局部变量动态地分配和释放存储空间。
在C++中变量除了有数据类型的属性之外,还有存储类别(storage class)的属性。存储类别指的是数据在内存中存储的方法。存储方法分为静态存储和动态存储两类。存储类别有4种:自动的(auto)、静态的、寄存器的、外部的。根据变量的存储类别,可以知道变量的作用域和存储期。
4.8.2 自动变量
函数中的局部变量,如果不用关键字static加以声明,编译系统对它们是动态地分配内存空间。
函数形参和函数中定义的变量(包括在符合语句中定义的变量),都属于动态分配内存空间。在调用该函数时,系统给形参和函数中定义的变量分配存储空间,数据存储在动态存储区中。在函数调用结束时就自动释放这些空间。如果是在复合语句中定义的变量,则在变量定义时分配存储空间,在符合语句结束时自动释放空间。因此这类局部变量称为自动变量(auto variable)。
自动变量用关键字auto作为存储类别的声明。
int f(int a){ // 定义f函数,a为形参
auto int b,c=3; // 定义b和c为整型的自动变量
}
a是形参,b和c是在函数中定义的自动变量,对c赋初值3.执行完f函数后,自动释放a,b,c所占的存储单元。
存储类别auto和数据类型int的顺序任意。关键auto可以省略,如果不写,则系统会把变量默认为自动存储类别,它属于动态存储方式。程序中大多数变量属于自动变量。在函数中定义的变量都没有声明为auto,其实都默认指定自动变量。
// 在函数体中以下写法作用相同
auto int a;
int auto a;
int a;
4.8.3 用static声明静态局部变量
有时候希望函数中的局部变量的值在函数调用结束后不消失而保留原值,即其占用的存储单元不释放,在下一次该函数调用时,该变量保留上一次函数调用结束时的值。这时就应该指定该局部变量为静态局部变量(static local variable)。
#include<bits/stdc++.h>
using namespace std;
int f(int a){
auto int b = 0; // 自动变量
static int c = 3; // 静态局部变量
b = b + 1;
c = c +1;
return a+b+c;
}
int main(){
int a = 2,i;
for(i=0;i<3;i++){
cout<<f(a)<<" ";
}
cout<<endl;
return 0;
}
在第1次调用f函数时,b的初始值为0,c的初始值为3,第一次调用结束时,b的值为1,c的值为4,a+b+c的值为7。由于c是静态局部变量,在函数调用结束后,它并不释放,仍保留c等于4。在第2次调用f函数时,b的初始值为0,而次的初值为4(上次调用结束的值)。
| 调用次数 | 调用时初始值 | 调用结束时的值 | |||
| 自动变量b | 静态局部变量c | b | c | a+b+c | |
| 第1次 | 0 | 3 | 1 | 4 | 7 |
第2次 |
0 | 4 | 1 | 5 | 8 |
| 第3次 | 0 | 5 | 1 | 6 | 9 |
对静态局部变量的说明:
(1) 静态局部变量在静态存储区内分配存储单元。在程序整个运行期间都不释放。而自动变量(动态局部变量)属于动态存储类别,存储在动态存储区空间而不是静态存储区空间,函数调用结束后即释放。
(2) 对静态局部变量是在编译时赋初值的,即只赋初值一次,在程序运行时它已有初值。以后每次调用函数时不再重新赋初值而只保留上一次函数调用结束时的值。而对自动变量赋初值,不是在编译时进行的,而是在函数调用时进行的,每调用一次函数重新给一次初值,相当于执行一次赋值语句。
(3) 如果在定义局部变量时不赋初值的话,对静态局部变量来说,编译时自动赋初值0(对数值型变量)或空字符(对字符变量)。而对自动变量来说,如果不赋初值,则它的值是一个不确定的值。这是由于每次函数调用结束后存储单元已释放,下次调用时又重新另分配存储单元,而所分配的单元中的值是不确定的。
(4) 虽然静态局部变量在函数调用结束后仍然存在,但其他函数是不能引用它的,也就是说,在其他函数中它是“不可见”的。
在什么情况下需要用局部静态变量呢?
(1)需要保留函数上一次调用结束时的值。
例如可以用下面方法求n!。输出1 ~ 5的阶乘值(即1!,2!,3!,4!,5!)。
解题思路:采用递推的方法,先求出1!,再求2!,3!,4!,5!。用fac函数求阶乘值,第1次调用fac函数求得1!,保留这个值,在第2次调用fac函数时在这个值的基础上乘以2,得到2!,函数调用结束后仍保留此值,在第3次调用fac函数时在这个值的基础上再乘以3 ,得到3! ....其余类推。
#include<bits/stdc++.h>
using namespace std;
int fac(int);
int main() {
for (int i = 1; i <= 5; i++) {
cout << i << "!=" << fac(i) << endl;
}
return 0;
}
int fac(int n) {
static int f = 1;
f = f * n;
return f;
}
每次调用fac(i),就输出一个i同时保留这个i!的值,以便下次再乘(i+1)。
(2) 如果初始化后,变量只被引用而不改变其值,则这时用静态局部变量比较方便,以免每次调用时重新赋值。
但是用静态存储要多占内存(长期占用不释放,而不能像动态存储那样一个存储单元可先后供多个变量使用,节约内存),而且降低了程序的可读性,当调用次数多时汪汪弄不清静态局部变量的当前值是什么,所以如果不必要,不要使用静态局部变量。
4.8.4 用register声明寄存器变量
一般情况下,变量(包括静态存储方式和动态存储方式)的值是存放在内存中的。当程序中用到哪一个变量的值时,由控制器发出指令将内存中该变量的值送到CPU中的运算器。经过运算器进行运算,如果需要存数,再从运算器将数据送到内存存放。
如果有一些变量使用频繁(如:在一个函数中执行一万次循环,每次循环中都要引用某局部变量),则为存取变量的值要花不少时间。为提高执行效率,C++允许将局部变量的值放在CPU的寄存器中,需要时直接从寄存器取出参加运算,不必再到内存中去存取。由于寄存器的存取速度远高于对内存的存取速度,因此这样做可以提高执行效率。这种变量叫寄存器变量,用关键字register做声明,
int fac(){
register int i,f = 1;
for(i=1;i<=n;i++)f=f*i;
return f;
}
定义f和i是存放咋寄存器的局部变量,如果n的值大,则能节约许多执行时间。
在程序中定义寄存器变量对编译系统知识建议性而不是强制性的。当今的优化编译系统能够识别使用频繁的变量,从而自动地将这些变量放在寄存器中,而不需要程序设计者指定。因此在实际中不必用register来声明变量。这里只需要了解即可.
4.8.5 用extern声明外部变量
全局变量(外部变量)是在函数的外部定义的,他的作用域为从变量定义处开始,到本程序文件的末尾。在此作用域内,全局变量可以为本文件中各个函数所引用。编译时将全局变量分配在静态存储区。
有的时候需要使用 extern 来声明全局变量,以扩展全局变量的作用域。
1. 在文件捏声明全局变量
如果外部变量不在文件的开头定义,其有效的范围只限于定义的位置起到文件终了的位置止。如果在定义点之前的函数想引用该全局变量,则应该在引用之前用关键字 extern 对该变量作外部变量声明,表示该变量是一个将在下面定义的全局变量。有了此声明,就可以从声明的位置起,合法地引用该全局变量,这种声明称为提前引用声明。
用extern对外部变量作提前引用声明,以扩展程序文件中的作用域。
#include <iostream>
using namespace std;
int max(int, int); // 函数声明
int main() {
extern int a, b; // 对全局变量a,b作提前引用声明
cout << max(a, b) << endl;
return 0;
}
int a = 15, b = -7; // 定义全局变量a,b
int max(int x, int y) {
int z;
z = x > y ? x : y;
return z;
}
在main函数的后面定义了全局变量a,b,但由于全局变量定义的位置在函数main函数之后,因此如果没有提前引用声明,在main函数中是不能引用全局变量a和b的。
我们在main函数中使用extern对a,b作了提前引用声明,表示a,b是将在后面定义的变量。这样main函数中就可以合法地使用全局变量a和b了。如果不做extern声明,编译时会出错,系统认为a和b未经定义。一般都把全局变量的定义放在引用它的所有函数之前,这样可以避免在函数中多加一个extern声明。
2. 在多文件的程序中声明外部变量
一个C++程序可以由一个或多个源程序文件组成。如果程序只由一个源文件组成,使用外部变量的方法全面已经介绍。如果程序由多个源程序文件组成,那么在一个文件中想引用另一个文件中已定义的外部变量该如何做。
如果一个程序包含两个文件,在两个文件中都要用到同一个外部变量num,不能分别在两个文件中各自定义一个外部变量num,否则在进行程序的连接时会出现“重复定义”的错误。正确的做法是:在任一个文件中定义外部变量num,而在另一个文件中用extern对num作外部变量声明。即:extern int num; 。
编译系统由此知道num是一个一再别处定义的外部变量,它现在本文件中找有无外部变量num,如果有,则将其作用域扩展到本行开始,如果本文件中无此外部变量,则在程序连接时从其他文件中找有无外部变量num,如果有,则吧在另一个文件中定义的外部变量num的作用域扩展到本文件中,在本文件可以合法地引用该外部变量num。
// file1.cpp
#include <iostream>
#include "file2.cpp"
using namespace std;
int max(int, int); // 函数声明
extern int a, b; // 对全局变量a,b作提前引用声明
int main() {
cout << max(a, b) << endl;
return 0;
}
// file2.cpp
#include <iostream>
using namespace std;
int a = 15, b = -7; // 定义全局变量a,b
int max(int x, int y) {
int z;
z = x > y ? x : y;
return z;
}
在源程序文件file2.cpp中定义了整型变量a,b,并赋了初值。在file1.cpp中用extern声明外部变量a,b,未赋值。在编译连接成一个程序后,file2.cpp中a和b的作用域扩展到file1.cpp文件中,因此main函数中的cout语句输出的值为15。
注意: extern是用作变量声明,而不是变量定义。它只对一个已定义的外部变量做声明,以扩展其作用域。
用extern扩展全局变量的作用域,虽然能为程序设计带来方便,但应十分慎重,因为在执行一个文件中的函数时,可能会改变了该全局变量的值,从而会影响另一个文件中函数执行结果。
4.8.6 用static声明静态外部变量
在程序设计中希望某些外部变量只限于被本文件引用,而不能被其他文件引用。这时可以在定义外部变量时加上static声明。
static int a = 3;
当在文件中使用static声明了变量,即便在其他文件中使用extern声明,也不能使用。
这种加上static声明,只能用于本文件的外部变量(全局变量)成为静态外部变量,在程序设计中,常由若干人分别完成各个模块,各人可以独立的在其设计的文件中使用相同的全局变量而不相干。只需在每个文件中的全局变量前加上static。这就为程序的模块化、通用性提供了方便。如果知道其他文件不需要引用本文件的全局变量,可以对本文件中的全局变量都加上static,成为静态外部变量,以免被其他文件误用。
需要指出,不要误认为用static声明的外部变量才采用静态存储方式(存放在静态存储区中),而不加static的是动态存储区(存放在动态存储区)。实际上,两种形式的外部变量都用静态存储方式,只是作用范围不同而已,都是在编译时分配内存。
4.9 变量小结
4.9.1 变量属性小结
一个变量除了数据类型以外,还有三种属性:
(1) 存储类别:C++允许使用auto,static,register,extern 4种存储类别。
(2)作用域:指在程序中可以引用该变量的区域。
(3)存储期:指变量在内存的存储周期。
以上3中属性是联系的,程序设计者只能声明变量的存储类别,通过存储类别可以确定变量的作用域和存储期。
要注意存储类别的用法。auto,static,register 3种存储类别只能用于变量定义语句中,如:
auto char c; // 字符型自动变量,在函数内定义
static int a; // 静态局部整型变量或静态外部整型变量
register int d; // 整型寄存器变量,在函数内定义
extern int b; // 声明一个已定义的外部整型变量
说明:extern 只能用来声明已定义的外部变量,而不能用于变量的定义。只要看到extern,就可以判定这个变量声明,而不是定义变量的语句。
下面从不同角度分析它们之间的联系:
(1) 从作用域角度分,有局部变量和全局变量。他们采用的存储类别如下:
局部变量:
-
自动变量,即动态局部变量(离开函数,值就消失)
-
局部变量(离开函数,值仍保留)
-
寄存器变量(离开函数,值就消失)
-
形式参数(可以定义为自动变量或寄存器变量)
全局变量:
-
静态外部变量(只限本文件引用)
-
外部变量(即非静态的外部变量,允许其他文件引用)
(2) 从变量存储期(存在的时间)来区分,有动态存储和静态存储两种类型。静态存储是程序整个运行时间都存在,而动态存储则是在调用函数时临时分配单元。
动态存储:
-
自动变量(本函数内有效)
-
寄存器变量(本函数内有效)
-
形式参数
静态存储
-
静态局部变量(函数内有效)
-
静态外部变量(本文件内有效)
-
外部变量(其他文件可引用)
(3) 从变量值存放的位置来区分,可分为:
内存中静态存储区:
-
静态局部变量
-
静态外部变量(函数外部静态变量)
-
外部变量(可为其他文件引用)
内存中动态存储区:自动变量和形式参数
CPU中的寄存器:寄存器变量
(4) 关于作用域和存储期的概念。
从前面叙述可以知道,对一个变量的性质可以从两个方面分析,一是从变量的作用域,二是从变量值存在时间的长短,即存储期。前者是从空间的角度来看,后者是从时间的角度来看。二者有联系但不是同一回事。
如果一个变量在某个文件或函数范围内是有效的,则称该文件或函数为该变量的作用域,在此作用域内可以引用该变量,所以又称变量在此作用域内“可见”,这种性质又称为变量的可见性。
如果一个变量值在某一时刻是存在的,则认为这一时刻属于该变量的存储期,或称该变量在此时刻“存在”。以下是各个类型变量的作用域和存在性的情况。
| 变量存储类别 | 函数内 | 函数外 | ||
| 作用域(可见性) | 存在性 | 作用域(可见性) | 存在性 | |
|
自动变量和寄存器变量 |
√ | √ | × | × |
| 静态局部变量 | √ | √ | × | √ |
| 静态外部变量 | √ | √ | √(只限本文件) | √ |
| 外部变量 | √ | √ | √ | √ |
表中“√”表示“是”,“X”表示“否”。
可以看到自动变量和寄存器变量在函数内的可见性和存在性是一致的,即在函数执行期间,变量是存在的,且可以被引用。在丽数外的可见性和存在性也是一致的,即离开函数后,变量不存在,不能被引用。静态局部变量在函数外的可见性和存在性不一致,离开函数后,变量值存在,但不能被引用。静态外部变量和外部变量的可见性和存在性是一致的,在离开函数后变量值仍存在,且可被引用。
(5) static声明使变量采用静态存储方式,但它对局部变量和全局变量所起的作用不同。
对局部变量来说,static使变量由动态存储方式改变为静态存储方式。而对全局变量来说,它使变量局部化(局部于本文件),但仍为静态存储方式。从作用域角度看,凡有static声明的,其作用域都是局限的,或者是局限于本函数内(静态局部变量),或者局限于本文件内(静态外部变量)。
4.9.2 变量的声明和定义
在第2章中介绍了如何定义一个变量。 在本章中又介绍了如何对一个变量的存储类别作声明(如exterma;)。在C和C++中,关于定义与声明这两个名词的使用上始终存在着混淆。不仅许多初学者没有搞清楚,连不少介绍C和C++的教材和书籍也没有给出准确的介绍。
从第2章已经知道,一个函数一般由两部分组成: (1)声明部分;(2)执行语句。声明部分的作用是对有关的标识符(如变量、函数、结构体、共用体等)的属性进行说明。对于函数,声明和定义的区别是明显的,在第4.4.3节中已说明,函数的声明是函数的原型,而函数的定义是函数功能的确立。对函数的声明是可以放在声明部分中的,而函数的定义显然不在函数的声明部分范围内,它是一个文件中的独立模块。
对变量而言,声明与定义的关系稍微复杂些。在声明部分出现的变量有两种情况:一种是需要建立存储空间的(如int a; ):另一种是不需要建立存储空间的(如extern int a;)。前者称为定义性声明( defining declaration), 或简称为定义( definition)。后者称为引用性声明( referenceing declaration)。
int main(){
extern int a; // 这是声明不是定义。声明a是一个已定义的外部变量
}
int a; // 定义,定义a为整型外部变量
广义地说,声明包括定义,但并非所有的声明都是定义。对于“int a;"而言,它是定义性声明,既可说是声明,又可说是定义。而对于“extermn int a;"而言,它是声明而不是定义。一般为了叙述方便,把建立存储空间的声明称为定义,而把不需要建立存储空间的声明称为声明。显然这里指的声明是狭义的,即非定义性声明。例如:
4.10 内部函数和外部函数
函数本质上是全局的,因为一个函数要被另外的函数调用,但是,也可以指定函数只能被本文件调用,而不能被其他文件调用。根据函数能否被其他源文件调用,为内部函数和外部函数。
4.10.1 内部函数
如果一个函数只能被本文件中其他函数所调用,它称为内部函数。在定义内部函数时,在函数名和函数类型的前面加static。 函数首部的一般格式为
static 类型标识符函数名(形参表)
static int func(int a,int b)
内部函数又称静态(static)函数。使用内部函数,可以使函数只局限于所在文件。如果在不同的文件中有同名的内部函数,互不干扰。这样不同的人可以分别编写不同的函数,而不必担心所用函数名是否会与其他文件中的函数相同。通常把只能由同一文件使用的函数和外部变量放在一个文件中,在它们前面都冠以satic使之局部化,其他文件不能引用。
4.10.2 外部函数
(1) 在定义函数时,如果在函数首部的最左端冠以关键字extern,则表示此函数是外部函数,可供其他文件调用。
如函数首部可以写为
extern int func (inta, int b)
这样,函数func就可以为其他文件调用。如果在定义函数时省略extern则默认为外部函数。本书前面所用的函数都是外部函数。
(2) 在需要调用此函数的文件中用extern声明所用的函数是外部函数。
输入两个整数,要求输出将其中的大者。用外部函数实现。
// file1.cpp
#include <iostream>
#include "file2.cpp"
using namespace std;
int main() {
extern int max(int,int);
int a,b;
cin>>a>>b;
cout << max(a, b) << endl;
return 0;
}
// file2.cpp
#include <iostream>
using namespace std;
int max(int x, int y) {
int z;
z = x > y ? x : y;
return z;
}
整个程序由两个文件组成。每个文件包含一个函数。主函数是主控函数,在main函数中用extern声明在main函数中要用到的max函数是在其他文件中定义的外部函数。
在计算机上运行一个含多文件的程序时,需要建立一个项目文件(projectfile) ,在该项目文件中包含程序的各个文件。
通过此例可知:使用extern声明就能够在一个文件中调用其他文件中定义的函数,或者说把该函数的作用城扩展到本文件。extern 声明的形式就是在函数原型基础上加关键字extern。由于函数在本质上是外部的,在程序中经常要调用其他文件中的外部函数,为方便编程,C++允许在声明函数时省写extern。程序main 函数中的函数声明可写成
int max( int,int) ;
这就是我们多次用过的函数原型。由此可以进一步理解函数原型的作用。用函数原型能够把函数的作用域扩展到定义该函数的文件之外(不必使用extern)。 只要在使用该函数的每一个文件中包含该函数的函数原型即可。函数原型通知编译系统:该函数在本文件中稍后定义,或在另一文件中定义。
利用函数原型扩展函数作用域最常见的例子是#include指令的应用。在前面几章中曾多次使用过#include指令,并提到过:在#include指令所指定的头文件中包含有调用库函数时所需的信息。例如,在程序中需要调用sin函数,但三角函数并不是由用户在本文件中定义的,而是存放在数学函数库中的。按以上的介绍,必须在本文件中写出sin函数的原型,否则无法调用sin函数。sin 函数的原型是
double sin( double x);
本来应该由程序设计者在调用库函数时先从手册中查出所用的库函数的原型,并在程序中一一写出来,但这显然是麻烦而困难的。为减少程序设计者的困难,在头文件cmath中包括了所有数学函数的原型和其他有关信息,用户只须用以下#include指令:
#include < cmath >
即可。这时,在该文件中就能合法地调用各数据库函数了。
4.11 头文件
在前面见到的程序中都用#include指令包含指定的头文件。实际#include指令和头文件已成为源文件中不可缺少的成分。
4.11.1 头文件的内容
许多程序都要使用系统提供的库函数,而C++又规定在调用函数前必须对被调用的函数作原型声明,如果由用户来完成这些工作,是非常麻烦和枯燥的,而且容易遗漏和出错。现在,库函数的开发者把这些信息写在一个文件中,用户只须将该文件“包含”进来即可(如调用数学函数的,应包含cmath文件),这就大大简化了程序写一行#incude指令的作用相当于写几十行几百行甚至更多行的内容。这种常用在文件头部的被包含的文件称为“标题文件"或“头部文件"(“头文件”)。
头文件般包含以下几类内容:
(1)对类型的声明。包括第7章介绍的自定义类型和第8章介绍的类(class)的声明。
(2)函数声明。例如系统函数库包含了各类函数,在程序中要使用这些函数就要对之作函数声明。为方便用户,可以将同一类的函数声明集中在一个头文件中(如头文件cmath集中了数学函数的原型声明),用户只要包含了此头文件,就可以在程序中使用该类函数。应特别说明,函数的定义是不放在头文件中的,而是放在函数库中或单独编译成目标文件,在编译连接阶段与用户文件连接组成可执行文件。
(3)内置(inline)函数的定义。由于内置函数的代码是要插人用户程序中的,因此它应当与调用它的语句在同一文件中,而不能分别在不同的文件中。
(4)宏定义。用#define定义的符号常量和用const声明的常变量。
(5)全局变量定义。
(6)外部变量声明。如“entern int a;"。
(7)还可以根据需要包含其他头文件。
不同的头文件包括以上不同的信息提供给程序设计者使用,这样,程序设计者不用自己重复书写这些信息,只须用行#include 指令就把这些信息包含到本文件了,大大地提高了编程效率。由于有了#include指令,就可以把不同的文件组合在一起,形成一个文件。因此说,头文件是源文件之间的接口。
*4.16.2关于 C++标准库和头文件的形式
前面已说明,各种C++编译系统都提供了许多系统函数和宏定义,而对函数的声明则分别存放在不同的头文件中。如果调用某一个函数,就必须用#include指令将有关的头文件包含进来。C++的库除了保留C的大部分系统函数和宏定义外,还增加了预定义的模板和类。但是不同的编译系统的C++库的内容不完全相同,由各C++编译系统自行决定。新的C++标准把库的建设纳入标准,规范化了C++标准库。以便使C++程序能够在不同的C++平台上工作,便于互相移植。新的C++标准库中的头文件不再包括后缀.h,例如:
#include < string >
但为了使大批已有的C程序能继续使用,许多C++编译系统保留了C的头文件,如C++中提供的cmath头文件,其中第一个字母c表示它是继承标准C的头文件。也就是说,C++提供两种不同形式的头文件,由程序设计者选用。如:
#include < math.h > //C形式的头文件
#include < cmath > //C++形式的头文件
效果是一样的。建议尽量用符合C++标准的形式,即在包含C++头文件时一般不用后缀。如果用户自已编写头文件,可以用h作后缀。这样从#include指令中即可看出哪些头文件是属于C ++标准库的,哪些头文件是用户自编或别人提供的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号