寒假作业2/2
| 这个作业属于哪个课程 | 2021春软工实践|W班 (福州大学) |
|---|---|
| 这个作业的要求在哪里 | 寒假作业2/2 |
| 这个作业的目标 | 任务一:阅读《构建之法》并提问 任务二:完成词频统计个人作业 |
| 其他参考文献 | 无 |
任务一:阅读《构建之法》并提问
一、基本要求
1.我看到这段文字(2.5 散伙阶段 有些团队过不了磨合这一道门坎, 退化到 “散伙阶段” - 有些名存实亡的 “团队” 就剩下一两个人干活, 其他人在打酱油, 并且还抱怨其他伙伴不重视他们。 这些情况在我们学生项目中是不是很常见呢?)。有这个问题(该如何避免团队从磨合阶段进入到散伙阶段?),我查了资料,有这些说法(1.谈好规则,定好规则。2.包容忍让。3.增强团队凝聚力)。但是根据我的实践,我得到了这些经验(一个团队中难免会有人划水,即使已经分配好了任务,制定好了规则,也会出现就几个人在努力搬砖的情况)。我的困惑是(如何使一个团队中的每个人各施其职,能融洽的交流配合,共同完成项目的构建)。
2.我看到这段文字(在《现代软件工程》 这门课里, 同学们不能穿新鞋, 走老路 - 学习了很多新技术, 新的开发模式, 新的团队管理方法, 却做一个毫无新意, 没人使用, 演示后就扔掉的东西 例如: 虚拟的学籍管理系统, 图书馆管理系统…)。 我们要做实用并且创新的项目。 那我们怎么才能想出靠谱的想法, 然后有条理地说服别人? 在宿舍里睡觉, 聚餐, 喝酒, 搞头脑风暴?),有这个问题(我们如何想出一个具有新意,而且具有使用价值的软件?),我查了资料,有这些说法(1.通过问卷调研用户的需求。2.跟用户面谈,了解用户需求)。根据我的实践,我得到了这些经验,虽然用过问卷可以收集到用户的需求,但是各个用户的需求不一样,而且用户的需求不一定有实现的价值。但我还是不太懂,我的困惑是(在接下来的团队作业中,该如何设计一个具有新意而且有价值的软件,而不是为了应付作业)。
3.我看到这段文字(1990年代, 韦尔奇注意到核磁共振机器的通道特别狭窄, 在长达几十分钟的检查过程中, 病人常常有得了幽闭恐惧症的感觉。 杰克做过类似的检查, 深有体会。他问, 能不能把通道做得大一些? 专家说那样会降低扫描成像的质量。)有这个问题(我们在用户的体验和质量不能得兼的情况下,我们该如何进行权衡?)。经过我的实践,得到的经验是,在之前的项目中,在限时的情况下,如果花时间去改善用户体验,有可能会导致代码的质量下降。我的困惑是(在接下来的项目中,如果为了提高用户的体验则要花更多的时间去设计界面,同时扩展新功能,但是在有限的时间中,这会影响到软件的质量,这该如何选择)。
4.我看到了这段文字(谁不喜欢创新呢? 然而细细想来, 创新就是做和以前不一样的事, 并不是所有的人都喜欢“不一样“。 当你提出一个创新的想法时, 你会得到什么回答呢? 下面是一些:This will never work、No one will want this等),有了这个问题(如果我有一个创新的想法(比如下学期的团队作业我想做+个校园闲置物品交易平台),要如何跟我的团队沟通使他们相信这个想法具有可行性)。根据我的实践,大多数创新的想法总会被团队以各种理由否决,即使想法具有可行性但是团队也会因为怕麻烦而否决。我的困惑是(每个人都有创新的想法,但是要如何确定想法的可行性以及协调一整个团队去尝试实现这个想法)。
5.我看到了这段文字(那一个刚入行的初级软件工程师如何成长呢? 我认为成长有下面几种:1. 知识: 对具体技术的掌握, 动手能力2. 经验: 对问题领域的知识和经验的积累 (例如: 对于医疗行业的了解, 对于金融行业的了解)。3. 通用的软件设计思想, 软件工程思想的提高4. 职业技能 (区别于技术技能)职业技能包括: 自我管理的能力; 表达和交流的能力; 与人合作的能力; 把任务按质按量完成的执行力; 这些能力在IT 行业和其它行业都很重要。)我有了这个问题(作为刚入行的软件工程师,我们将如何高效率地提高我们的能力?),根据我的实践,我在学习各种框架的时候,通过不断的编码,提供了我编程的能力以及使我对框架的结构有了更深刻的理解。我的困惑是(虽然通过学习各种框架可以提高编程能力与编程思维,但是总觉得效率不太高,该采取什么方法才能高效率的进行学习,提高能力)。
6.我看了这段文字(每人在各自独立设计、实现软件的过程中不免要犯这样那样的错误。在结对编程中,因为有随时的复审和交流,程序各方面的质量取决于一对程序员中各方面水平较高的那一位。这样,程序中的错误就会少得多,程序的初始质量会高很多,这样会省下很多以后修改、测试的时间。具体地说,结对编程有如下的好处:(1)在开发层次,结对编程能提供更好的设计质量和代码质量,两人合作能有更强的解决问题的能力。(2)对开发人员自身来说,结对工作能带来更多的信心,高质量的产出能带来更高的满足感。(3)在心理上, 当有另一个人在你身边和你紧密配合, 做同样一件事情的时候, 你不好意思开小差, 也不好意思糊弄。(4)在企业管理层次上,结对能更有效地交流,相互学习和传递经验,能更好地处理人员流动。因为一个人的知识已经被其他人共享。总之,如果运用得当,结对编程能得到更高的投入产出比),有了这个问题(在接下来的团队编程中,采取结对的编程模式是否具有可行性,是否能减少开发时间和提高代码质量,比如两个人做ui,两个人做前端,两个人做后端,一个人架构等),根据我的实践,在之前的上机课中,与同学讨论会有效的减少bug,但是会花费更多的时间,在有限的时间里这样反而利大于弊,所以我打算在这学期的团队作业中尝试采取结对编程的方法。我的困惑是(对于一个团队来说,是单人开发的收益高还是结对开发的收益高)
二、附加题
马化腾称,当初创业的时候,要做到3万用户,于是一个一个的去学校拉用户,但是按照这样的方法,想要达到3万用户的目标至少要两年的时间,这么久的话公司就死掉了。后来做出不同的项目就一个接一个的卖掉。不停地去网上推广,后来用户数量上来了,但是聊天的人很少,马化腾就自己和别人各种聊天,有时候还要换头像,假扮成女生在社区内聊天,就为了显得社区内很热闹。马化腾也表示当时自己不敢写总经理的职位,因为总经理不能出来自己干活,只能写是技术工程师。
见解:创业是一件艰苦和劳累的事,往往不但要花费大量经历,还要投入大量时间,要有坚强的意志以及坚定的决心。马化腾曾经想把QQ卖掉,但是还是咬牙坚持了下来,才成就了中国使用的人最多的社交软件。
任务二:WordCount编程
Github项目地址
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 5 | 3 |
| • Estimate | • 估计这个任务需要多少时间 | 5 | 3 |
| Development | 开发 | 245 | 331 |
| • Analysis | • 需求分析 (包括学习新技术) | 10 | 12 |
| • Design Spec | • 生成设计文档 | 15 | 15 |
| • Design Review | • 设计复审 | 5 | 3 |
| • Coding Standard | • 代码规范 (为目前的开发制定合适的规范) | 15 | 24 |
| • Design | • 具体设计 | 10 | 12 |
| • Coding | • 具体编码 | 120 | 155 |
| • Code Review | • 代码复审 | 10 | 10 |
| • Test | • 测试(自我测试,修改代码,提交修改) | 60 | 100 |
| Reporting | 报告 | 30 | 43 |
| • Test Repor | • 测试报告 | 15 | 21 |
| • Size Measurement | • 计算工作量 | 10 | 12 |
| • Postmortem & Process Improvement Plan | • 事后总结, 并提出过程改进计划 | 5 | 10 |
| 合计 | 280 | 377 |
解题思路描述
当看到题目的第一个想法就是,这是一个命令行程序,而且要进行文件读写,所以要用args[ ]传入输入文件和输出文件。然后,接下来就是去实现题目要求的功能,功能设计中最主要的部分应该是字符的过滤(过滤掉非法字符)和拼接(将合法字符拼接成单词)。再者,就是选择文件的Reader和Writer。因为主要是字符的处理,我选用能能进行单个字符处理的Reader和Writer。查询资料的话我用的主要是CSDN和博客园。
代码规范制定链接
设计与实现过程
首先,设计了Lib类和WordCount类这两个类和10个函数,Lib类中有许多接口的实现,WordCount类是主类,调用Lib类的接口来完成所有功能。
wordsCount()和wordNum()会调用isValidChar()和isValidChars()来判断是否为有效的单词,isValidChars()会调用isNum()来判断单词前四个字母是否为数字
以下为接口的设计
//打开文件
public static Reader openInputFile(String fileName) {...}
//关闭文件
public static BufferedWriter openOutputFile(String fileName) throws IOException {...}
//统计字符数,空格,水平制表符,换行符,均算字符
public static int charactersCount(String inputFile, String outputFile) throws IOException {...}
//统计单词总数,至少以4个英文字母开头,跟上字母数字符号,单词以分隔符分割,不区分大小写
public static int wordsCount(String inputFile, String outputFile) throws IOException {...}
//统计行数,任何包含非空白字符的行,都需要统计。
public static int linesCount(String inputFile, String outputFile) throws IOException {...}
//统计单词的出现次数(对应输出接下来10行),最终只输出频率最高的10个。
public static Map wordNum(String inputFile, String outputFile) throws IOException {...}
//打印出频率前十的单词
public static void printWords(Map<String, Integer> map, Writer writer) throws IOException {...}
//判断是否为有效的字符
public static boolean isValidChar(int temp) {...}
//判断是否为有效的单词
public static boolean isValidChars(char[] chars) {...}
//判断是否为数字
public static boolean isNum(int temp) {...}
运行结果
characters: 148998191
words: 10031861
lines: 10000000
middle: 15624
part: 15619
color: 15528
full: 15528
card: 4184
body: 4176
shirt: 4173
style: 4170
wing: 4168
cream: 4165
这个测试的input.txt用的是宿舍群中的大文件,用于测试大文件是否会发生异常以及运行的时间,测试数据的构建思路主要是通过随机数生成大量的单词并输出到input.txt中。
主要的函数有四个:
-
统计字符数:由于read会读出每一个字符,所以用read可以方便的读出所有字符。同时在这里没有用openOutputFile(),是为了保证每次打开文件的时候可以先清空之前文件的内容再追加。
while ((temp = reader.read()) != -1) { num++; } -
统计单词总数:用了isValidChar()来判断是否为有效字符(数字,英文字母),不是则被过滤掉。同时用isValidChars()来判断是否为有效的单词(至少以四个英文字母开头)。
while ((temp = reader.read()) != -1) { while (isValidChar(temp)) {//将所有有效字符拼接成字符串 word += (char) temp; temp = reader.read(); } while (!isValidChar(temp) && temp != -1) {//去除所有空白字符和分隔符 temp = reader.read(); } char[] chars = word.toCharArray(); if (isValidChars(chars)) {//如果单词合法,则单词总数++ num++; } word = "" + (char) temp;//将读取到的最后一个字符(下个单词首字母)加到下一个单词 } -
统计行数:要求中只计算有效行,所以我用一个Line来保存每一行,如果这一行去除掉空白字符之后为空String,则不会被计数。
while ((temp = reader.read()) != -1) { while (temp != -1 && (char) temp != '\n') { if ((char) temp != ' ' && (char) temp != '\t' && (char) temp != '\r' && (char) temp != '\n') {//去除掉空白字符 line += (char) temp; } temp = reader.read(); } if (line != "") {//如果行非空,num++ num++; } line = "";//清空字符串 } -
统计出现频率前十的单词:首先判断出所有的单词,然后将单词转成小写,并且放入Map中,再将Map转化为Set进行排序,最后再调用printWords()打印出频率前十的单词。
if (isValidChars(chars)) {//如果单词合法,则单词总数++ if (words.get(word) == null) {//如果map中没有 words.put(word, Integer.valueOf(1)); } else { words.put(word, Integer.valueOf(words.get(word).intValue() + 1)); } }Map<String, Integer> result = words.entrySet().stream() .sorted(new Comparator<Map.Entry<String, Integer>>() {//对Map进行排序 @Override public int compare(Map.Entry<String, Integer> o1, Map.Entry<String, Integer> o2) { if (o1.getValue().equals(o2.getValue())) { return o1.getKey().compareTo(o2.getKey()); } else { return o2.getValue().compareTo(o1.getValue()); } } }) .collect(Collectors.toMap(Map.Entry::getKey, Map.Entry::getValue, (oldValue, newValue) -> oldValue, LinkedHashMap::new));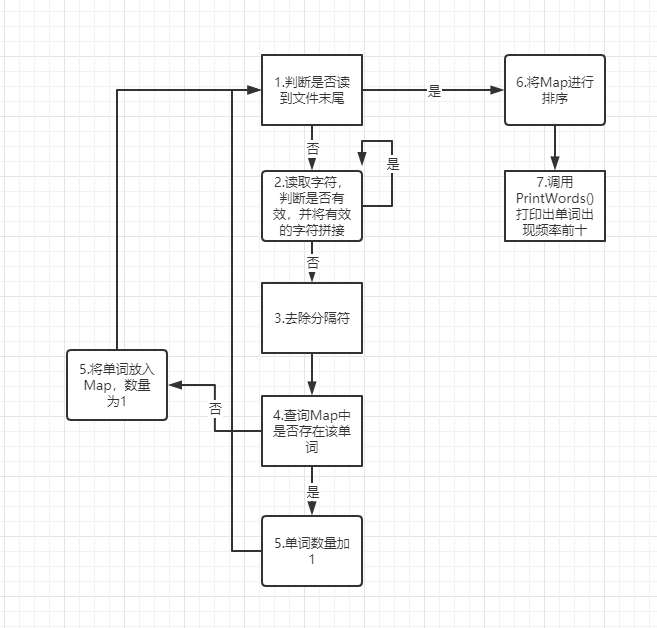
性能改进
仔细想了想这个程序可以优化时间的地方好像不多,我进行优化的地方是**
1.把Map转为Set进行排序,使用了stream()节约了一点时间
Steam有以下好处:
- Stream不存储元素
- Stream不会修改数据源,而是会产生一个修改后的Stream对象,进而链式调用
- Stream的执行具有延迟特性
因此可以使得对集合对象的操作更加高效和遍历。
Map<String, Integer> result = words.entrySet().stream()
.sorted(new Comparator<Map.Entry<String, Integer>>() {//对Map进行排序
@Override
public int compare(Map.Entry<String, Integer> o1, Map.Entry<String, Integer> o2) {
if (o1.getValue().equals(o2.getValue())) {
return o1.getKey().compareTo(o2.getKey());
} else {
return o2.getValue().compareTo(o1.getValue());
}
}
})
.collect(Collectors.toMap(Map.Entry::getKey, Map.Entry::getValue,
(oldValue, newValue) -> oldValue, LinkedHashMap::new));
使用stream处理6万个单词花费的时间:

使用普通的Map排序处理6万个单词花费的时间:

2.用BufferedWriter代替FileWriter
public static BufferedWriter openOutputFile(String fileName) throws IOException {
BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(new FileOutputStream(new File(fileName),true),"utf-8"));
return bw;
}
FileWriter每次调用write()方法,就会调用一次OutputStreamWriter中的write()方法
而BufferedWriter只有在缓冲区满了才会调用OutputStreamWriter中的write()方法
在大量写入文件的时候write()的执行次数和所花费时间会有巨大差别
但是在该案例中只输出13行,效果不明显
单元测试
单元测试的代码
@org.junit.jupiter.api.Test
void wordNum() throws IOException {
String inputFile = "C:\\Users\\WWJ20\\IdeaProjects\\WordCount\\src\\input.txt";
String outputFile = "C:\\Users\\WWJ20\\IdeaProjects\\WordCount\\src\\output.txt";
Lib.wordNum(inputFile, outputFile);
}
-
单元测试的函数主要是通过固定的绝对路径访问文件(因为main函数中是通过命令行输入文件路径的),然后在单元测试函数中调用Lib类中的该方法
-
构造测试数据的思路主要想的是这几个方面
- 无效的单词:故意构建无效的单词看是否会被跳过,在这里我使用了手动构建错误情况并输入input.txt
- 多个分隔符:在两个单词之间加入大量的分隔符看是否出现异常,在这里我也是手动构建错误
- 大量数据:通过大文件输入大量的数据,判断是否会发生异常,在这里我使用了宿舍群众142MB的input.txt测试结果
-
单元测试得到的测试覆盖率截图
-
charactersCount()

-
wordsCount()
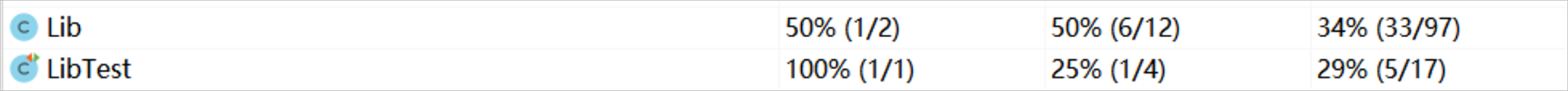
-
lineCounts()

-
wordNum()

-
-
如何优化覆盖率?
- 方法体尽量小,一入一出,不要使用变量传递。
- 文件数据等测试,加快速度可以一次性加入内存跑。
- 尽量避免使用三目运算符,多IF条件判断,可以使用枚举+工厂类来规避,减少单元测试编写难度。
异常处理说明
-
如果输入文件不存在
try { reader = new InputStreamReader(new FileInputStream(file)); } catch (FileNotFoundException e) { e.printStackTrace(); System.out.println("文件不存在"); }
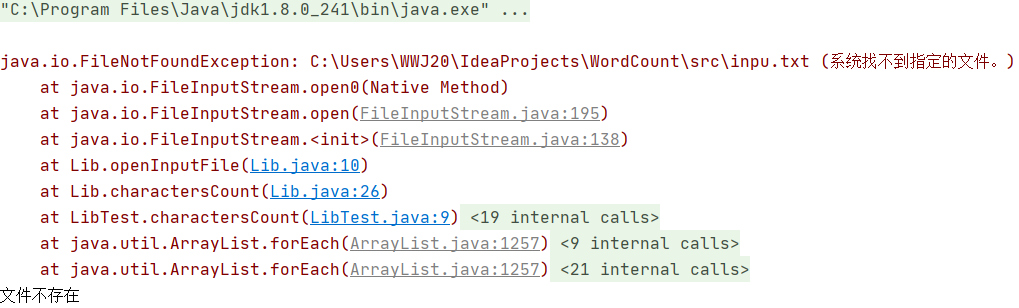
console会打印出文件不存在
-
如果输出文件不存在
系统会自动创建输出文件
-
如果输入文件中有错误信息
程序会过滤错误的信息
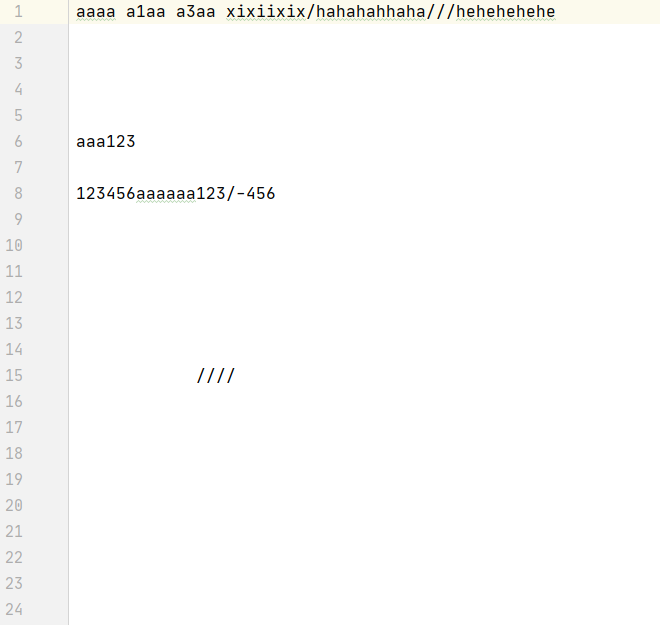

心路历程与收获
这次的作业让我们了解了如何使用github发布项目和控制版本,同时也让我们了解了一个代码从无到有的规范流程。同时我们也制定了自己的代码规范,以后写代码都将按照代码规范来,使得自己的代码清晰有条理。这次的代码总体来说难度不高,但是帮助我们规范了写代码的习惯,这对我们以后的编程有着莫大的帮助。

